机器学习:begging复习
非原创,代码来自葁sir
import numpy as np
import pandas as pd
from pandas import Series,DataFrame
import seaborn as sns
import matplotlib.pyplot as plt
%matplotlib inline
# 使用波士顿房价数据集进行实验
from sklearn.datasets import load_boston
# 导入bagging
from sklearn.ensemble import BaggingClassifier
# 取波士顿房价数据
boston = load_boston()
data = boston.data
target = boston.target
feature_names = boston.feature_names
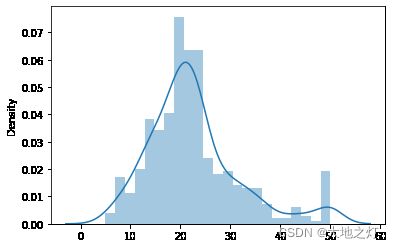
sns.distplot(target)
D:\software\anaconda\lib\site-packages\seaborn\distributions.py:2619: FutureWarning: `distplot` is a deprecated function and will be removed in a future version. Please adapt your code to use either `displot` (a figure-level function with similar flexibility) or `histplot` (an axes-level function for histograms).
warnings.warn(msg, FutureWarning)
# 回归?分类?
# 回归 -> 分类
y_mean = target.mean()
y_mean
22.532806324110677
# 构造y
y = pd.Series(target).map(lambda x:(x<= y_mean)*1).values
y
array([0, 1, 0, 0, 0, 0, 0, 0, 1, 1, 1, 1, 1, 1, 1, 1, 0, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 0, 0, 0, 0, 0, 0,
1, 1, 1, 1, 1, 1, 1, 1, 0, 0, 1, 0, 0, 0, 0, 1, 1, 1, 1, 0, 0, 0,
1, 1, 1, 1, 0, 1, 0, 0, 0, 1, 1, 1, 1, 1, 0, 0, 0, 0, 0, 0, 1, 1,
0, 0, 0, 1, 0, 0, 1, 0, 1, 0, 0, 0, 0, 0, 1, 1, 1, 1, 1, 1, 1, 1,
1, 0, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
0, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 1, 1, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 0, 1, 1, 1, 1, 0, 0, 0, 0, 0, 1, 0,
0, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 1,
1, 0, 1, 1, 0, 1, 0, 0, 0, 0, 0, 0, 1, 1, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 1, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1,
1, 0, 1, 0, 0, 0, 0, 0, 1, 0, 0, 1, 1, 0, 0, 1, 0, 0, 0, 0, 0, 0,
0, 1, 1, 1, 1, 1, 0, 1, 1, 1, 0, 1, 0, 0, 1, 1, 0, 0, 0, 1, 1, 0,
1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 0, 1, 0, 0, 1, 1, 0, 0, 0, 0, 0,
1, 0, 1, 1, 1, 1, 0, 0, 0, 1, 1, 1, 1, 0, 1, 0, 0, 0, 0, 0, 0, 1,
1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 0, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 0, 1, 0, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 0, 0, 1, 1, 1, 1, 1, 1, 0, 0, 0, 1,
1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 0, 0, 1, 1, 1, 1, 1, 1, 1, 0, 1, 1])
# 查看y的正负比
y.mean()
0.5869565217391305
# 构造X
X = data.copy()
X
array([[6.3200e-03, 1.8000e+01, 2.3100e+00, ..., 1.5300e+01, 3.9690e+02,
4.9800e+00],
[2.7310e-02, 0.0000e+00, 7.0700e+00, ..., 1.7800e+01, 3.9690e+02,
9.1400e+00],
[2.7290e-02, 0.0000e+00, 7.0700e+00, ..., 1.7800e+01, 3.9283e+02,
4.0300e+00],
...,
[6.0760e-02, 0.0000e+00, 1.1930e+01, ..., 2.1000e+01, 3.9690e+02,
5.6400e+00],
[1.0959e-01, 0.0000e+00, 1.1930e+01, ..., 2.1000e+01, 3.9345e+02,
6.4800e+00],
[4.7410e-02, 0.0000e+00, 1.1930e+01, ..., 2.1000e+01, 3.9690e+02,
7.8800e+00]])
from sklearn.model_selection import train_test_split
# 数据集切分
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=1)
# knn 决策树 LR
from sklearn.neighbors import KNeighborsClassifier
from sklearn.tree import DecisionTreeClassifier
from sklearn.linear_model import LogisticRegression
knn = KNeighborsClassifier()
knn.fit(X_train,y_train)
train_score = knn.score(X_train,y_train)
test_score = knn.score(X_test,y_test)
print('KNN train score:{} \ntest score:{}'.format(train_score,test_score))
KNN train score:0.8539603960396039
test score:0.7941176470588235
DT = DecisionTreeClassifier()
DT.fit(X_train,y_train)
train_score = DT.score(X_train,y_train)
test_score = DT.score(X_test,y_test)
print('DT train score:{} \ntest score:{}'.format(train_score,test_score))
DT train score:1.0
test score:0.8137254901960784
LR = LogisticRegression()
LR.fit(X_train,y_train)
train_score = LR.score(X_train,y_train)
test_score = LR.score(X_test,y_test)
print('LR train score:{} \ntest score:{}'.format(train_score,test_score))
LR train score:0.8935643564356436
test score:0.8431372549019608
D:\software\anaconda\lib\site-packages\sklearn\linear_model\_logistic.py:763: ConvergenceWarning: lbfgs failed to converge (status=1):
STOP: TOTAL NO. of ITERATIONS REACHED LIMIT.
Increase the number of iterations (max_iter) or scale the data as shown in:
https://scikit-learn.org/stable/modules/preprocessing.html
Please also refer to the documentation for alternative solver options:
https://scikit-learn.org/stable/modules/linear_model.html#logistic-regression
n_iter_i = _check_optimize_result(
集成学习
# 使用bagging + knn
# base_estimator 基学习器对象
# n_estimators 有多少个基学习器 理论上越多越好 (边际效益递减)
# max_samples 最大样本数量(随机采样) max_features 最大特征个数(随机采样) 也可以1.0
bc = BaggingClassifier(base_estimator=KNeighborsClassifier(),n_estimators=10)
bc.fit(X_train,y_train)
train_score = bc.score(X_train,y_train)
test_score = bc.score(X_test,y_test)
print('bc+knn train score:{} \ntest score:{}'.format(train_score,test_score))
bc+knn train score:0.8787128712871287
test score:0.7647058823529411
# 同理:使用bagging + LR
bc = BaggingClassifier(base_estimator=LogisticRegression(),n_estimators=10)
bc.fit(X_train,y_train)
train_score = bc.score(X_train,y_train)
test_score = bc.score(X_test,y_test)
print('bc+LR train score:{} \ntest score:{}'.format(train_score,test_score))
bc+LR train score:0.8985148514851485
test score:0.8333333333333334
D:\software\anaconda\lib\site-packages\sklearn\linear_model\_logistic.py:763: ConvergenceWarning: lbfgs failed to converge (status=1):
STOP: TOTAL NO. of ITERATIONS REACHED LIMIT.
Increase the number of iterations (max_iter) or scale the data as shown in:
https://scikit-learn.org/stable/modules/preprocessing.html
Please also refer to the documentation for alternative solver options:
https://scikit-learn.org/stable/modules/linear_model.html#logistic-regression
n_iter_i = _check_optimize_result(
D:\software\anaconda\lib\site-packages\sklearn\linear_model\_logistic.py:763: ConvergenceWarning: lbfgs failed to converge (status=1):
STOP: TOTAL NO. of ITERATIONS REACHED LIMIT.
Increase the number of iterations (max_iter) or scale the data as shown in:
https://scikit-learn.org/stable/modules/preprocessing.html
Please also refer to the documentation for alternative solver options:
https://scikit-learn.org/stable/modules/linear_model.html#logistic-regression
n_iter_i = _check_optimize_result(
D:\software\anaconda\lib\site-packages\sklearn\linear_model\_logistic.py:763: ConvergenceWarning: lbfgs failed to converge (status=1):
STOP: TOTAL NO. of ITERATIONS REACHED LIMIT.
Increase the number of iterations (max_iter) or scale the data as shown in:
https://scikit-learn.org/stable/modules/preprocessing.html
Please also refer to the documentation for alternative solver options:
https://scikit-learn.org/stable/modules/linear_model.html#logistic-regression
n_iter_i = _check_optimize_result(
D:\software\anaconda\lib\site-packages\sklearn\linear_model\_logistic.py:763: ConvergenceWarning: lbfgs failed to converge (status=1):
STOP: TOTAL NO. of ITERATIONS REACHED LIMIT.
Increase the number of iterations (max_iter) or scale the data as shown in:
https://scikit-learn.org/stable/modules/preprocessing.html
Please also refer to the documentation for alternative solver options:
https://scikit-learn.org/stable/modules/linear_model.html#logistic-regression
n_iter_i = _check_optimize_result(
D:\software\anaconda\lib\site-packages\sklearn\linear_model\_logistic.py:763: ConvergenceWarning: lbfgs failed to converge (status=1):
STOP: TOTAL NO. of ITERATIONS REACHED LIMIT.
Increase the number of iterations (max_iter) or scale the data as shown in:
https://scikit-learn.org/stable/modules/preprocessing.html
Please also refer to the documentation for alternative solver options:
https://scikit-learn.org/stable/modules/linear_model.html#logistic-regression
n_iter_i = _check_optimize_result(
D:\software\anaconda\lib\site-packages\sklearn\linear_model\_logistic.py:763: ConvergenceWarning: lbfgs failed to converge (status=1):
STOP: TOTAL NO. of ITERATIONS REACHED LIMIT.
Increase the number of iterations (max_iter) or scale the data as shown in:
https://scikit-learn.org/stable/modules/preprocessing.html
Please also refer to the documentation for alternative solver options:
https://scikit-learn.org/stable/modules/linear_model.html#logistic-regression
n_iter_i = _check_optimize_result(
D:\software\anaconda\lib\site-packages\sklearn\linear_model\_logistic.py:763: ConvergenceWarning: lbfgs failed to converge (status=1):
STOP: TOTAL NO. of ITERATIONS REACHED LIMIT.
Increase the number of iterations (max_iter) or scale the data as shown in:
https://scikit-learn.org/stable/modules/preprocessing.html
Please also refer to the documentation for alternative solver options:
https://scikit-learn.org/stable/modules/linear_model.html#logistic-regression
n_iter_i = _check_optimize_result(
D:\software\anaconda\lib\site-packages\sklearn\linear_model\_logistic.py:763: ConvergenceWarning: lbfgs failed to converge (status=1):
STOP: TOTAL NO. of ITERATIONS REACHED LIMIT.
Increase the number of iterations (max_iter) or scale the data as shown in:
https://scikit-learn.org/stable/modules/preprocessing.html
Please also refer to the documentation for alternative solver options:
https://scikit-learn.org/stable/modules/linear_model.html#logistic-regression
n_iter_i = _check_optimize_result(
D:\software\anaconda\lib\site-packages\sklearn\linear_model\_logistic.py:763: ConvergenceWarning: lbfgs failed to converge (status=1):
STOP: TOTAL NO. of ITERATIONS REACHED LIMIT.
Increase the number of iterations (max_iter) or scale the data as shown in:
https://scikit-learn.org/stable/modules/preprocessing.html
Please also refer to the documentation for alternative solver options:
https://scikit-learn.org/stable/modules/linear_model.html#logistic-regression
n_iter_i = _check_optimize_result(
D:\software\anaconda\lib\site-packages\sklearn\linear_model\_logistic.py:763: ConvergenceWarning: lbfgs failed to converge (status=1):
STOP: TOTAL NO. of ITERATIONS REACHED LIMIT.
Increase the number of iterations (max_iter) or scale the data as shown in:
https://scikit-learn.org/stable/modules/preprocessing.html
Please also refer to the documentation for alternative solver options:
https://scikit-learn.org/stable/modules/linear_model.html#logistic-regression
n_iter_i = _check_optimize_result(
#使用bagging + tree
# = RandomForest
from sklearn.ensemble import RandomForestClassifier
# user RandomForest
rfc = RandomForestClassifier()
rfc.fit(X_train,y_train)
train_score = rfc.score(X_train,y_train)
test_score = rfc.score(X_test,y_test)
print('rfc train score:{} \ntest score:{}'.format(train_score,test_score))
rfc train score:1.0
test score:0.8529411764705882
# 极限树 extra trees
from sklearn.ensemble import ExtraTreesClassifier
rfc = ExtraTreesClassifier()
rfc.fit(X_train,y_train)
train_score = rfc.score(X_train,y_train)
test_score = rfc.score(X_test,y_test)
print('extra trees train score:{} \ntest score:{}'.format(train_score,test_score))
extra trees train score:1.0
test score:0.8235294117647058
# 以极限树为例:查看所有的基学习器对象
rfc.estimators_
[ExtraTreeClassifier(random_state=673588125),
ExtraTreeClassifier(random_state=488071731),
ExtraTreeClassifier(random_state=1622278427),
ExtraTreeClassifier(random_state=1876490098),
ExtraTreeClassifier(random_state=241370813),
ExtraTreeClassifier(random_state=1743839097),
ExtraTreeClassifier(random_state=1232988859),
ExtraTreeClassifier(random_state=979843241),
ExtraTreeClassifier(random_state=1040519261),
ExtraTreeClassifier(random_state=1170314893),
ExtraTreeClassifier(random_state=1029919579),
ExtraTreeClassifier(random_state=472602064),
ExtraTreeClassifier(random_state=1428732310),
ExtraTreeClassifier(random_state=422890944),
ExtraTreeClassifier(random_state=1455121860),
ExtraTreeClassifier(random_state=1585543315),
ExtraTreeClassifier(random_state=1344848473),
ExtraTreeClassifier(random_state=150509904),
ExtraTreeClassifier(random_state=990863693),
ExtraTreeClassifier(random_state=1231906602),
ExtraTreeClassifier(random_state=369559350),
ExtraTreeClassifier(random_state=1871932752),
ExtraTreeClassifier(random_state=663018717),
ExtraTreeClassifier(random_state=17214297),
ExtraTreeClassifier(random_state=1315586773),
ExtraTreeClassifier(random_state=673936293),
ExtraTreeClassifier(random_state=184329578),
ExtraTreeClassifier(random_state=1556763587),
ExtraTreeClassifier(random_state=392343256),
ExtraTreeClassifier(random_state=1486472491),
ExtraTreeClassifier(random_state=1302768882),
ExtraTreeClassifier(random_state=1010242070),
ExtraTreeClassifier(random_state=1342772113),
ExtraTreeClassifier(random_state=950263756),
ExtraTreeClassifier(random_state=1350463287),
ExtraTreeClassifier(random_state=19134245),
ExtraTreeClassifier(random_state=988036893),
ExtraTreeClassifier(random_state=441119067),
ExtraTreeClassifier(random_state=838670824),
ExtraTreeClassifier(random_state=1796737857),
ExtraTreeClassifier(random_state=50710977),
ExtraTreeClassifier(random_state=1384131264),
ExtraTreeClassifier(random_state=985597036),
ExtraTreeClassifier(random_state=311865058),
ExtraTreeClassifier(random_state=665333497),
ExtraTreeClassifier(random_state=666693346),
ExtraTreeClassifier(random_state=387029410),
ExtraTreeClassifier(random_state=1910292169),
ExtraTreeClassifier(random_state=715291718),
ExtraTreeClassifier(random_state=939826385),
ExtraTreeClassifier(random_state=1789162498),
ExtraTreeClassifier(random_state=1442851372),
ExtraTreeClassifier(random_state=424160325),
ExtraTreeClassifier(random_state=828174978),
ExtraTreeClassifier(random_state=1209017795),
ExtraTreeClassifier(random_state=1385407473),
ExtraTreeClassifier(random_state=708789379),
ExtraTreeClassifier(random_state=1507634136),
ExtraTreeClassifier(random_state=1363320620),
ExtraTreeClassifier(random_state=608328498),
ExtraTreeClassifier(random_state=1783697985),
ExtraTreeClassifier(random_state=114943116),
ExtraTreeClassifier(random_state=1712726222),
ExtraTreeClassifier(random_state=1385646792),
ExtraTreeClassifier(random_state=1934880966),
ExtraTreeClassifier(random_state=2085696663),
ExtraTreeClassifier(random_state=1517431913),
ExtraTreeClassifier(random_state=1833220801),
ExtraTreeClassifier(random_state=1884050681),
ExtraTreeClassifier(random_state=997798596),
ExtraTreeClassifier(random_state=1278465467),
ExtraTreeClassifier(random_state=1071758490),
ExtraTreeClassifier(random_state=1038496683),
ExtraTreeClassifier(random_state=2125878969),
ExtraTreeClassifier(random_state=737515153),
ExtraTreeClassifier(random_state=231544061),
ExtraTreeClassifier(random_state=1235961821),
ExtraTreeClassifier(random_state=1134625303),
ExtraTreeClassifier(random_state=252212314),
ExtraTreeClassifier(random_state=829876405),
ExtraTreeClassifier(random_state=255476834),
ExtraTreeClassifier(random_state=1794344573),
ExtraTreeClassifier(random_state=1690130610),
ExtraTreeClassifier(random_state=44855735),
ExtraTreeClassifier(random_state=120122191),
ExtraTreeClassifier(random_state=572292737),
ExtraTreeClassifier(random_state=2013376145),
ExtraTreeClassifier(random_state=1764948964),
ExtraTreeClassifier(random_state=2069366834),
ExtraTreeClassifier(random_state=452698497),
ExtraTreeClassifier(random_state=1808295875),
ExtraTreeClassifier(random_state=1559875659),
ExtraTreeClassifier(random_state=628672983),
ExtraTreeClassifier(random_state=628915131),
ExtraTreeClassifier(random_state=548355594),
ExtraTreeClassifier(random_state=1199991344),
ExtraTreeClassifier(random_state=584863494),
ExtraTreeClassifier(random_state=545309444),
ExtraTreeClassifier(random_state=1163398698),
ExtraTreeClassifier(random_state=1059866034)]
深入研究一下随机森林
rfc = RandomForestClassifier(n_estimators=10) # 参数调整 树的数量 10 100 200 300 400
rfc.fit(X_train,y_train)
train_score = rfc.score(X_train,y_train)
test_score = rfc.score(X_test,y_test)
print('rfc train score:{} \ntest score:{}'.format(train_score,test_score))
rfc train score:0.9975247524752475
test score:0.8431372549019608
# 查看每一个随机森林的情况
trees = rfc.estimators_
from sklearn import tree
import graphviz
dot = tree.export_graphviz(trees[2]) # 从树列表中取第三个树的情况
graphviz.Source(dot)
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-AbrL4iFn-1650590368437)(output_27_0.svg)]
rfc.predict(X_test) # 预测
array([0, 0, 1, 1, 1, 1, 0, 1, 1, 0, 0, 0, 1, 1, 1, 1, 1, 0, 0, 1, 1, 1,
0, 0, 0, 1, 1, 1, 0, 1, 0, 1, 0, 1, 0, 1, 1, 0, 1, 0, 0, 1, 0, 1,
1, 1, 0, 1, 0, 1, 1, 1, 0, 1, 1, 0, 1, 0, 1, 0, 1, 0, 1, 1, 0, 0,
0, 0, 1, 1, 0, 1, 1, 1, 1, 1, 0, 0, 0, 0, 1, 1, 0, 1, 0, 0, 1, 0,
1, 1, 1, 0, 1, 1, 1, 1, 0, 0, 0, 1, 1, 1])
# 查看每一颗树投票第一个数据的情况 [少数服从多数]
for dt in rfc.estimators_:
print(dt.predict(X_test)[1])
0.0
1.0
0.0
1.0
0.0
0.0
1.0
0.0
0.0
0.0
# 特征重要性
rfc.feature_importances_
array([0.04870907, 0.01221739, 0.04984739, 0.00230753, 0.03824231,
0.12585426, 0.10040094, 0.03733726, 0.01598976, 0.04801519,
0.12284911, 0.04556374, 0.35266605])
特征重要性评估
from sklearn.datasets import fetch_olivetti_faces
faces = fetch_olivetti_faces()
faces.data
array([[0.30991736, 0.3677686 , 0.41735536, ..., 0.15289256, 0.16115703,
0.1570248 ],
[0.45454547, 0.47107437, 0.5123967 , ..., 0.15289256, 0.15289256,
0.15289256],
[0.3181818 , 0.40082645, 0.49173555, ..., 0.14049587, 0.14876033,
0.15289256],
...,
[0.5 , 0.53305787, 0.607438 , ..., 0.17768595, 0.14876033,
0.19008264],
[0.21487603, 0.21900827, 0.21900827, ..., 0.57438016, 0.59090906,
0.60330576],
[0.5165289 , 0.46280992, 0.28099173, ..., 0.35950413, 0.3553719 ,
0.38429752]], dtype=float32)
faces.target # 数字一样的是同一个人的脸
array([ 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 3, 3, 3, 3,
3, 3, 3, 3, 3, 3, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 5,
5, 5, 5, 5, 5, 5, 5, 5, 5, 6, 6, 6, 6, 6, 6, 6, 6,
6, 6, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 8, 8, 8, 8, 8,
8, 8, 8, 8, 8, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 10, 10,
10, 10, 10, 10, 10, 10, 10, 10, 11, 11, 11, 11, 11, 11, 11, 11, 11,
11, 12, 12, 12, 12, 12, 12, 12, 12, 12, 12, 13, 13, 13, 13, 13, 13,
13, 13, 13, 13, 14, 14, 14, 14, 14, 14, 14, 14, 14, 14, 15, 15, 15,
15, 15, 15, 15, 15, 15, 15, 16, 16, 16, 16, 16, 16, 16, 16, 16, 16,
17, 17, 17, 17, 17, 17, 17, 17, 17, 17, 18, 18, 18, 18, 18, 18, 18,
18, 18, 18, 19, 19, 19, 19, 19, 19, 19, 19, 19, 19, 20, 20, 20, 20,
20, 20, 20, 20, 20, 20, 21, 21, 21, 21, 21, 21, 21, 21, 21, 21, 22,
22, 22, 22, 22, 22, 22, 22, 22, 22, 23, 23, 23, 23, 23, 23, 23, 23,
23, 23, 24, 24, 24, 24, 24, 24, 24, 24, 24, 24, 25, 25, 25, 25, 25,
25, 25, 25, 25, 25, 26, 26, 26, 26, 26, 26, 26, 26, 26, 26, 27, 27,
27, 27, 27, 27, 27, 27, 27, 27, 28, 28, 28, 28, 28, 28, 28, 28, 28,
28, 29, 29, 29, 29, 29, 29, 29, 29, 29, 29, 30, 30, 30, 30, 30, 30,
30, 30, 30, 30, 31, 31, 31, 31, 31, 31, 31, 31, 31, 31, 32, 32, 32,
32, 32, 32, 32, 32, 32, 32, 33, 33, 33, 33, 33, 33, 33, 33, 33, 33,
34, 34, 34, 34, 34, 34, 34, 34, 34, 34, 35, 35, 35, 35, 35, 35, 35,
35, 35, 35, 36, 36, 36, 36, 36, 36, 36, 36, 36, 36, 37, 37, 37, 37,
37, 37, 37, 37, 37, 37, 38, 38, 38, 38, 38, 38, 38, 38, 38, 38, 39,
39, 39, 39, 39, 39, 39, 39, 39, 39])
X = faces.data[:50]
y = faces.target[:50]
X.shape
(50, 4096)
y.shape
(50,)
64*64
4096
# 使用随机森林和极限树进行拟合
# 查看各个算法的特征重要性
rfc = RandomForestClassifier(max_features=64)
etc = ExtraTreesClassifier(max_features=64)
rfc.fit(X,y)
RandomForestClassifier(max_features=64)
etc.fit(X,y)
ExtraTreesClassifier(max_features=64)
plt.imshow(etc.feature_importances_.reshape(64,64),cmap=plt.cm.hot)

plt.imshow(rfc.feature_importances_.reshape(64,64),cmap=plt.cm.hot)

波士顿房价进行特征重要性选择
# 波士顿房价
boston = load_boston()
data = boston.data
target = boston.target
feature_names = boston.feature_names
data = pd.DataFrame(data=data, columns=feature_names)
data
| CRIM | ZN | INDUS | CHAS | NOX | RM | AGE | DIS | RAD | TAX | PTRATIO | B | LSTAT | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 0.00632 | 18.0 | 2.31 | 0.0 | 0.538 | 6.575 | 65.2 | 4.0900 | 1.0 | 296.0 | 15.3 | 396.90 | 4.98 |
| 1 | 0.02731 | 0.0 | 7.07 | 0.0 | 0.469 | 6.421 | 78.9 | 4.9671 | 2.0 | 242.0 | 17.8 | 396.90 | 9.14 |
| 2 | 0.02729 | 0.0 | 7.07 | 0.0 | 0.469 | 7.185 | 61.1 | 4.9671 | 2.0 | 242.0 | 17.8 | 392.83 | 4.03 |
| 3 | 0.03237 | 0.0 | 2.18 | 0.0 | 0.458 | 6.998 | 45.8 | 6.0622 | 3.0 | 222.0 | 18.7 | 394.63 | 2.94 |
| 4 | 0.06905 | 0.0 | 2.18 | 0.0 | 0.458 | 7.147 | 54.2 | 6.0622 | 3.0 | 222.0 | 18.7 | 396.90 | 5.33 |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 501 | 0.06263 | 0.0 | 11.93 | 0.0 | 0.573 | 6.593 | 69.1 | 2.4786 | 1.0 | 273.0 | 21.0 | 391.99 | 9.67 |
| 502 | 0.04527 | 0.0 | 11.93 | 0.0 | 0.573 | 6.120 | 76.7 | 2.2875 | 1.0 | 273.0 | 21.0 | 396.90 | 9.08 |
| 503 | 0.06076 | 0.0 | 11.93 | 0.0 | 0.573 | 6.976 | 91.0 | 2.1675 | 1.0 | 273.0 | 21.0 | 396.90 | 5.64 |
| 504 | 0.10959 | 0.0 | 11.93 | 0.0 | 0.573 | 6.794 | 89.3 | 2.3889 | 1.0 | 273.0 | 21.0 | 393.45 | 6.48 |
| 505 | 0.04741 | 0.0 | 11.93 | 0.0 | 0.573 | 6.030 | 80.8 | 2.5050 | 1.0 | 273.0 | 21.0 | 396.90 | 7.88 |
506 rows × 13 columns
data.describe([0.99]).T
| count | mean | std | min | 50% | 99% | max | |
|---|---|---|---|---|---|---|---|
| CRIM | 506.0 | 3.613524 | 8.601545 | 0.00632 | 0.25651 | 41.37033 | 88.9762 |
| ZN | 506.0 | 11.363636 | 23.322453 | 0.00000 | 0.00000 | 90.00000 | 100.0000 |
| INDUS | 506.0 | 11.136779 | 6.860353 | 0.46000 | 9.69000 | 25.65000 | 27.7400 |
| CHAS | 506.0 | 0.069170 | 0.253994 | 0.00000 | 0.00000 | 1.00000 | 1.0000 |
| NOX | 506.0 | 0.554695 | 0.115878 | 0.38500 | 0.53800 | 0.87100 | 0.8710 |
| RM | 506.0 | 6.284634 | 0.702617 | 3.56100 | 6.20850 | 8.33500 | 8.7800 |
| AGE | 506.0 | 68.574901 | 28.148861 | 2.90000 | 77.50000 | 100.00000 | 100.0000 |
| DIS | 506.0 | 3.795043 | 2.105710 | 1.12960 | 3.20745 | 9.22277 | 12.1265 |
| RAD | 506.0 | 9.549407 | 8.707259 | 1.00000 | 5.00000 | 24.00000 | 24.0000 |
| TAX | 506.0 | 408.237154 | 168.537116 | 187.00000 | 330.00000 | 666.00000 | 711.0000 |
| PTRATIO | 506.0 | 18.455534 | 2.164946 | 12.60000 | 19.05000 | 21.20000 | 22.0000 |
| B | 506.0 | 356.674032 | 91.294864 | 0.32000 | 391.44000 | 396.90000 | 396.9000 |
| LSTAT | 506.0 | 12.653063 | 7.141062 | 1.73000 | 11.36000 | 33.91850 | 37.9700 |
from sklearn.model_selection import cross_val_predict
from sklearn.neighbors import KNeighborsRegressor
knn = KNeighborsRegressor()
y_ = cross_val_predict(knn,data,target,cv=10)
y_
array([21.38, 21.3 , 22.74, 20.4 , 19.26, 21.74, 23.14, 21.88, 21.74,
23.76, 21.88, 23.68, 24.46, 23.5 , 39.14, 21.84, 31.58, 23.74,
23.32, 23.96, 27.12, 21.86, 21.88, 21.88, 21.88, 27.36, 32.74,
27.36, 21.88, 32.74, 32.02, 33.06, 19.88, 35.98, 21.88, 27.66,
22.66, 27.28, 28.5 , 37.54, 34.96, 23.38, 23.38, 23.06, 20.72,
20.72, 20.72, 20.12, 23.92, 21.1 , 24.64, 24.46, 27.9 , 27.9 ,
28.9 , 38.44, 25.78, 37.54, 23.96, 29.1 , 24.32, 39.02, 24.32,
28.74, 30.82, 27.5 , 26.66, 29.46, 22.88, 22.88, 29.96, 31.06,
29.96, 29.96, 22.26, 22.46, 25.54, 22.46, 21.5 , 22.46, 24.94,
30.14, 24.16, 28.86, 22.92, 22.5 , 22.98, 23.12, 21.42, 21.92,
21.54, 19.26, 36.44, 34.02, 36.08, 22.38, 20.58, 18.46, 24.76,
22.42, 18.82, 18.7 , 18.14, 21.6 , 21.6 , 20.84, 19.96, 21.6 ,
26.9 , 21.6 , 23.04, 37.84, 37.84, 37.84, 37.84, 26.8 , 26.08,
37.84, 21.94, 19.98, 38.56, 33.24, 33.24, 33.24, 33.24, 33.24,
33.24, 44.54, 44.54, 37.84, 44.54, 44.54, 44.54, 44.54, 21.88,
44.54, 39.2 , 44.54, 44.54, 44.54, 44.54, 44.54, 31.84, 31.84,
31.84, 19.38, 19.38, 31.84, 31.6 , 27. , 42.92, 21.94, 26.8 ,
17.84, 17.28, 15.36, 15.36, 17.92, 17.92, 17.92, 17.28, 19.48,
18.08, 18.76, 14.44, 14.34, 18. , 14.34, 17.26, 17.28, 17.26,
17.92, 19.16, 23.54, 19.98, 24.28, 23.12, 21.92, 24.58, 27.72,
20.6 , 27.72, 20.6 , 20.6 , 20.6 , 28.42, 30.66, 23.62, 23.62,
23.62, 25.08, 23.62, 23.62, 30.24, 29.62, 33.7 , 22.08, 20.52,
21.54, 25.2 , 25.08, 21.8 , 20.96, 39.04, 38.74, 24.96, 23.08,
20.36, 21.06, 20.9 , 20.4 , 20.4 , 22.94, 28.22, 22. , 26.74,
23.34, 20.4 , 20.4 , 20.4 , 20.56, 16.86, 18.76, 20.94, 22. ,
18.98, 21.48, 18.98, 23.04, 23.04, 19.92, 18.3 , 22.62, 21.38,
17. , 20.52, 18.76, 21.54, 22.2 , 23.46, 24. , 22.34, 24.38,
21.6 , 19.98, 18.78, 24. , 18.78, 22.12, 24.88, 25.8 , 25.82,
25.32, 25.8 , 26.58, 24.32, 42.18, 22.42, 21.7 , 21.7 , 20.4 ,
22.18, 21.22, 22.62, 21.04, 22.1 , 21.22, 22.1 , 22.92, 26.72,
22.92, 23.9 , 26.36, 30.16, 23.2 , 22.62, 22.2 , 26.72, 23.2 ,
23.6 , 28.36, 23.6 , 27.6 , 38.96, 30.38, 23.9 , 41.68, 24.24,
22.94, 22.6 , 36.54, 39.92, 39.92, 24.86, 23.28, 24.86, 22.54,
22.6 , 27.08, 27.08, 24.34, 24.9 , 26.32, 29.56, 27.54, 26.96,
30.38, 30.38, 29.1 , 25.1 , 30.58, 21.76, 19.1 , 25.8 , 23.12,
23.68, 20.3 , 22.76, 22.52, 20.86, 23.34, 23.34, 23.48, 23.7 ,
23.9 , 24.52, 25.84, 23.6 , 21.18, 21.94, 20.6 , 23.1 , 23.54,
26.02, 26.02, 26.02, 27.76, 30.48, 26.02, 27.76, 30.48, 23.5 ,
20.74, 29.26, 28.8 , 21.3 , 20.18, 28.52, 33.06, 26.4 , 24.26,
33.14, 33.72, 45.58, 30.62, 30.62, 16.2 , 18.06, 19.74, 19.9 ,
17.52, 17.6 , 15.64, 17.6 , 17.98, 15.58, 15.2 , 12.16, 16.5 ,
16.5 , 17.7 , 14.66, 17.6 , 15.48, 13.98, 13.68, 14.14, 14.92,
13.08, 13.08, 13.84, 13.68, 15.48, 15.48, 15.84, 13.98, 13.98,
14.24, 15.36, 14.92, 14.92, 17.78, 14.92, 16.68, 14.92, 15.52,
16.32, 15.44, 13.98, 17.4 , 13.98, 14.66, 15.36, 13.08, 17.98,
14.76, 13.72, 23.36, 13.88, 15.3 , 16.94, 16.94, 16.94, 15.3 ,
16.94, 16.94, 16.94, 16.94, 16.94, 16.94, 23.26, 22.12, 15.06,
16.94, 16.94, 16.94, 16.94, 16.94, 16.94, 16.94, 16.94, 16.94,
16.94, 16.94, 16.94, 16.94, 16.94, 16.94, 16.94, 11.66, 9.62,
13.82, 12.14, 13.82, 15.06, 16.94, 22.12, 12.8 , 12.18, 15.6 ,
16.94, 22.5 , 18.52, 23.06, 16.94, 16.94, 11.5 , 12.34, 15.06,
18.7 , 13.94, 19.38, 18.7 , 19.18, 20.8 , 24.5 , 10.74, 19.12,
20.16, 20.8 , 18.66, 17.16, 20.8 , 23.08, 23.16, 17.56, 13.14,
23.16, 16.04, 17.36, 20.8 , 20.8 , 19.38, 23.04, 23.08, 23.04,
19.38, 23.04, 16.3 , 25.96, 16.98, 13.52, 18.66, 22.32, 21.08,
21.66, 22.64, 23.08, 23.46, 22.76, 22.76, 21.48, 25.94, 23.7 ,
23.7 , 27.2 ])
from sklearn.metrics import mean_squared_error
# 回归问题 mae mse
mean_squared_error(target,y_) # 真实y,预测y
107.66199288537547
# 随机森林回归对比knn回归
from sklearn.ensemble import RandomForestRegressor
rfr = RandomForestRegressor(n_estimators=500)
y_ = cross_val_predict(rfr,data,target,cv=10) # estimator,X,y,cv
mean_squared_error(target,y_)
21.79603733960475
rfr.fit(data,target)
RandomForestRegressor(n_estimators=500)
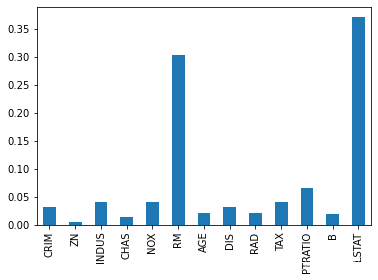
rfr.feature_importances_# 特征重要性系数
array([0.04083947, 0.00106137, 0.0062109 , 0.00097723, 0.02196979,
0.4291571 , 0.01303726, 0.06594065, 0.00349397, 0.01394747,
0.01677022, 0.01155127, 0.3750433 ])
pd.Series(data=rfr.feature_importances_,index=feature_names).plot(kind='bar')
X = data[['CRIM','RM','LSTAT','DIS']].copy() # 获取重要性参数
X
| CRIM | RM | LSTAT | DIS | |
|---|---|---|---|---|
| 0 | 0.00632 | 6.575 | 4.98 | 4.0900 |
| 1 | 0.02731 | 6.421 | 9.14 | 4.9671 |
| 2 | 0.02729 | 7.185 | 4.03 | 4.9671 |
| 3 | 0.03237 | 6.998 | 2.94 | 6.0622 |
| 4 | 0.06905 | 7.147 | 5.33 | 6.0622 |
| ... | ... | ... | ... | ... |
| 501 | 0.06263 | 6.593 | 9.67 | 2.4786 |
| 502 | 0.04527 | 6.120 | 9.08 | 2.2875 |
| 503 | 0.06076 | 6.976 | 5.64 | 2.1675 |
| 504 | 0.10959 | 6.794 | 6.48 | 2.3889 |
| 505 | 0.04741 | 6.030 | 7.88 | 2.5050 |
506 rows × 4 columns
# 重新利用比较重要的特征进行knn建模
knn = KNeighborsRegressor()
y_ = cross_val_predict(knn, X,target,cv=10)
# mse 对比真实的y和预测的y
mean_squared_error(target,y_)
23.756157312252967
王哥补充:使用标准化处理
from sklearn.preprocessing import StandardScaler
data = pd.DataFrame(data=StandardScaler().fit_transform(data),columns=data.columns)
data
| CRIM | ZN | INDUS | CHAS | NOX | RM | AGE | DIS | RAD | TAX | PTRATIO | B | LSTAT | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | -0.419782 | 0.284830 | -1.287909 | -0.272599 | -0.144217 | 0.413672 | -0.120013 | 0.140214 | -0.982843 | -0.666608 | -1.459000 | 0.441052 | -1.075562 |
| 1 | -0.417339 | -0.487722 | -0.593381 | -0.272599 | -0.740262 | 0.194274 | 0.367166 | 0.557160 | -0.867883 | -0.987329 | -0.303094 | 0.441052 | -0.492439 |
| 2 | -0.417342 | -0.487722 | -0.593381 | -0.272599 | -0.740262 | 1.282714 | -0.265812 | 0.557160 | -0.867883 | -0.987329 | -0.303094 | 0.396427 | -1.208727 |
| 3 | -0.416750 | -0.487722 | -1.306878 | -0.272599 | -0.835284 | 1.016303 | -0.809889 | 1.077737 | -0.752922 | -1.106115 | 0.113032 | 0.416163 | -1.361517 |
| 4 | -0.412482 | -0.487722 | -1.306878 | -0.272599 | -0.835284 | 1.228577 | -0.511180 | 1.077737 | -0.752922 | -1.106115 | 0.113032 | 0.441052 | -1.026501 |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 501 | -0.413229 | -0.487722 | 0.115738 | -0.272599 | 0.158124 | 0.439316 | 0.018673 | -0.625796 | -0.982843 | -0.803212 | 1.176466 | 0.387217 | -0.418147 |
| 502 | -0.415249 | -0.487722 | 0.115738 | -0.272599 | 0.158124 | -0.234548 | 0.288933 | -0.716639 | -0.982843 | -0.803212 | 1.176466 | 0.441052 | -0.500850 |
| 503 | -0.413447 | -0.487722 | 0.115738 | -0.272599 | 0.158124 | 0.984960 | 0.797449 | -0.773684 | -0.982843 | -0.803212 | 1.176466 | 0.441052 | -0.983048 |
| 504 | -0.407764 | -0.487722 | 0.115738 | -0.272599 | 0.158124 | 0.725672 | 0.736996 | -0.668437 | -0.982843 | -0.803212 | 1.176466 | 0.403225 | -0.865302 |
| 505 | -0.415000 | -0.487722 | 0.115738 | -0.272599 | 0.158124 | -0.362767 | 0.434732 | -0.613246 | -0.982843 | -0.803212 | 1.176466 | 0.441052 | -0.669058 |
506 rows × 13 columns
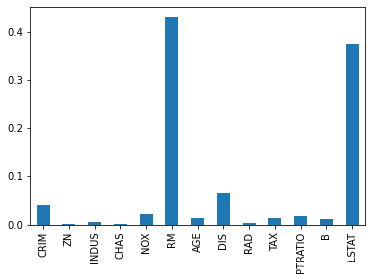
rfc = RandomForestRegressor()
rfc.fit(data,target)
RandomForestRegressor()
pd.Series(data=rfc.feature_importances_,index=feature_names).plot(kind='bar')
极限树进行特征重要性评估
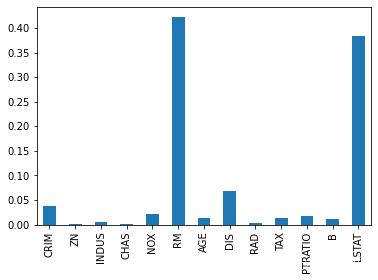
from sklearn.ensemble import ExtraTreesRegressor
etr = ExtraTreesRegressor()
etr.fit(data,target)
ExtraTreesRegressor()
pd.Series(data=etr.feature_importances_,index=feature_names).plot(kind='bar')