python中的多线程
线程
线程是操作系统能够进行运算调度的最小单位(程序执行流的最小单元)
它被包含在进程之中,是进程中的实际运作单位。一个进程中可以并发多个线程
每条线程并行执行不同的任务
(线程是进程中的一个实体,是被系统独立调度和分派的基本单元)
每一个进程启动时都会最先产生一个线程,即主线程
然后主线程会再创建其他的子进程
例子:看电影和听音乐会同时开始,然后按照各自的沉睡时间进行输出
import threading
from time import ctime,sleep
def music(a):
for i in range(2):
print 'I was listening to %s. %s' %(a,ctime())
sleep(1)
def movie(b):
for i in range(2):
print 'I was watching to %s. %s' %(b,ctime())
sleep(5)
# music('双子')
# movie('迷雾')
t1 = threading.Thread(target=music,args=('双子',))
t1.start()
t2 = threading.Thread(target=movie,args=('迷雾',))
t2.start()
print 'all over %s ' %ctime()
这里面包含两个线程,一个主线程,一个子线程
主线程会先执行
from threading import Thread
def Foo(arg):
print arg
print 'before'
#线程和函数建立关系
t1 = Thread(target=Foo,args=(1,))
t1.start()
print 'after'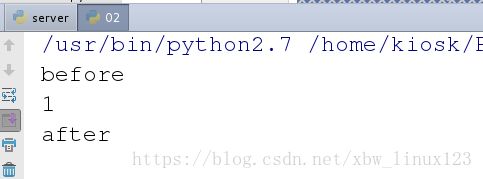
这里面包含三个线程,一个主线程,两个子线程
会先执行主线程
from threading import Thread
def Foo(arg):
print arg
print 'before'
#线程和函数建立关系
t1 = Thread(target=Foo,args=(1,))
t1.start()
print t1.getName()
t2 = Thread(target=Foo,args=(2,))
t2.start()
print t2.getName()
print 'after'
加上t1.setDaemon(True)这句代码后,程序只会执行主线程
from threading import Thread
import time
def Foo():
for item in range(100):
print item
time.sleep(1)
print 'before'
t1 = Thread(target=Foo)
t1.setDaemon(True)
t1.start()
print 'after'
加上t1.setDaemon(True)这句代码后,程序会先执行主线程,再执行子线程,子线程只执行10秒
from threading import Thread
import time
def Foo():
for item in range(100):
print item
time.sleep(1)
print 'before'
t1 = Thread(target=Foo)
t1.setDaemon(True)
t1.start()
print 'after'
time.sleep(10)
主线程到join()就不往下走了,直到子线程执行完
from threading import Thread
import time
def Foo():
for item in range(10):
print item
time.sleep(1)
print 'before'
t1 = Thread(target=Foo)
t1.start()
#主线程到join()就不往下走了,直到子线程执行完
t1.join(5)
print 'after'
多线程能干什么:
生产者消费者问题:(经典)
一直生产 一直消费 中间有阀值 避免供求关系不平衡
线程安全问题,要是线程同时来,听谁的
锁:一种数据结构 队列:先进线出 栈:先进后出
生产者消费者的优点(为什么经典的设计模式)
1.解耦(让程序各模块之间的关联性降到最低)
假设生产者和消费者是两个类,如果让生产者直接调用消费者的某个方法,那么生产者对于消费者就会产生依赖(也就是耦合),如果将来消费者的代码发生变换,可能会影响到生产者,而如果两者都依赖于某个缓冲区,两者之间不直接依赖,耦合也就相应降低了
生活中的例子:我们 邮筒 邮递员
举个例子,我们去邮局投递信件,如果不使用邮筒(也就是缓冲区),你必须得把信直接交给邮递员,有同学会说,直接交给邮递员不是挺简单的嘛,其实不简单,你必须得认识邮递员,才能把信给他(光凭身上的制服,万一有人假冒呢???),这就产成你和邮递员之间的依赖了(相当于生产者消费者强耦合),万一哪天邮递员换人了,你还要重新认识一下(相当于消费者变化导致修改生产者代码),而邮筒相对来说比较固定,你依赖它的成本就比较低(相当于和缓冲区之间的弱耦合)
2.支持并发
生产者消费者是两个独立的并发体,他们之间是用缓冲区作为桥梁连接,生产者之需要往缓冲区里丢数据,就可以继续生产下一个数据,而消费者者只需要从缓冲区里拿数据即可,这样就不会因为彼此速度而发生阻塞
接着上面的例子:如果我们不使用邮筒,我们就得在邮局等邮递员,直到他回来了,我们才能把信给他,这期间我们啥也不能干(也就是产生阻塞),或者邮递员挨家挨户的问(产生论寻)
3.支持忙闲不均
如果制造数据的速度时快时慢,缓冲区的好处就体现出来了,当数据制造快的时候,消费者来不及处理,未处理的数据可以暂时存在缓冲区中,等生产者的速度慢下来,消费者再慢慢处理
情人节信件太多了,邮递员一次处理不了,可以放在邮筒中,下次在来取
例子:消费者买包子,生产者做包子,都会有中间环节,生产者做好后储存到笼子里(即缓冲区)
消费者从笼子里得到包子,两者之间不直接依赖,耦合就降低
import threading
import Queue
import time
import random
def Producer(name,que):
while True:
if que.qsize() <3:
que.put('baozi')
print '%s:Made a baozi..======' %name
else:
print '还有三个包子'
time.sleep(random.randrange(5))
def Consumer(name,que):
while True:
try:
que.get_nowait()
print '%s:Got a baozi..' %name
except Exception:
print '没有包子了'
time.sleep(random.randrange(3))
#创建队列
q = Queue.Queue()
p1 = threading.Thread(target=Producer,args=['chef1',q])
p2 = threading.Thread(target=Producer,args=['chef2',q])
p1.start()
p2.start()
c1 = threading.Thread(target=Consumer,args=['tom',q])
c2 = threading.Thread(target=Consumer,args=['lily',q])
c1.start()
c2.start()事件驱动
import threading
import time
def Producer():
print 'chef:等人来买包子'
#收到了消费者的event.set 也就是把这个flag改为了true,但是我们的包子并没有做好
event.wait()
#此时应该将flag的值改回去
event.clear()
print 'chef:someone is coming for 包子'
print 'chef:making a 包子 for someone'
time.sleep(5)
# 告诉人家包子做好了
print '你的包子好了~'
event.set()
def Consumer():
print 'tom:去买包子'
# 告诉人家我来了
event.set()
time.sleep(2)
print 'tom:waiting for 包子 to be ready'
event.wait()
print '哎呀~真好吃'
event = threading.Event()
p1 = threading.Thread(target=Producer)
c1 = threading.Thread(target=Consumer)
p1.start()
c1.start()
异步
import threading
import time
def Producer():
print 'chef:等人来买包子'
# 收到了消费者的event.set 也就是把这个flag改为了true,但是我们的包子并没有做好
event.wait()
# 此时应该将flag的值改回去
event.clear()
print 'chef:someone is coming for 包子'
print 'chef:making a 包子 for someone'
time.sleep(5)
# 告诉人家包子做好了
print '你的包子好了~'
event.set()
def Consumer():
print 'tom:去买包子'
# 告诉人家我来了
event.set()
time.sleep(2)
print 'tom:waiting for 包子 to be ready'
# 我在不断检测,但我已经不阻塞了
while True:
if event.is_set():
print 'Thanks~'
break
else:
print '怎么还没好呀~'
# 模拟正在做自己的事情
time.sleep(1)
event = threading.Event()
p1 = threading.Thread(target=Producer)
c1 = threading.Thread(target=Consumer)
p1.start()
c1.start()
LOCK
多线程不加锁的影响:
多线程和多进程最大的不同在于,多进程中,同一个变量,各自有一份拷贝存在于
每个进程中,互不影响,而多线程中,所有变量都由所有线程共享,所以,任何一
个变量都可以被任何一个线程修改,因此,线程之间共享数据最大的危险在于多个
线程同时改一个变量,把内容给改乱了
锁的好处:
锁的好处就是确保了某段关键代码只能由一个线程从头到尾完整地执行,坏处当然
也很多,首先是阻止了多线程并发执行,包含锁的某段代码实际上只能以单线程模
式执行,效率就大大地下降了。其次,由于可以存在多个锁,不同的线程持有不同
的锁,并试图获取对方持有的锁时,可能会造成死锁,导致多个线程全部挂起,既
不能执行,也无法结束,只能靠操作系统强制终止。
import threading
import time
num = 0
def run(n):
time.sleep(1)
global num
#线程锁
lock.acquire()
num += 1
print '%s\n' %num
#释放线程锁
lock.release()
lock = threading.Lock()
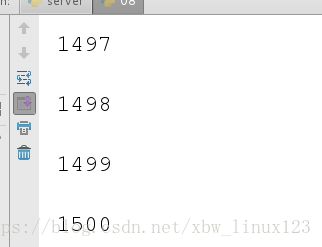
for i in range(1500):
t = threading.Thread(target=run,args=(i,))
t.start()