什么是Boosting算法——Adaptive Boosting (AdaBoost) 与Gradient Boosting详解
什么是Boosting:
与许多ML模型专注于由单个模型来完成高质量预测不同, Boosting算法试图通过训练一系列弱模型来提高预测能力,每个模型都可以弥补其前辈的弱点。

图片来自https://towardsdatascience.com/boosting-algorithms-explained-d38f56ef3f30
要了解Boosting,至关重要的是要认识到Boosting 是一种通用算法,而不是特定模型。Boosting需要你指定一个弱模型(e.g. regression, shallow decision trees, etc),然后提升它。
1.Adaboost
1.1 弱点的定义
AdaBoost是针对分类问题开发的特定Boosting算法(也称为离散AdaBoost)。弱点由弱估计器的错误率确定:

在每次迭代中,AdaBoost都会识别分类错误的数据点,从而增加其权重(从某种意义上讲减少正确点的权重),以便下一个分类器将更加重视以使其正确无误。下图解释了权重如何影响一个简单决策树(深度为1)的性能:
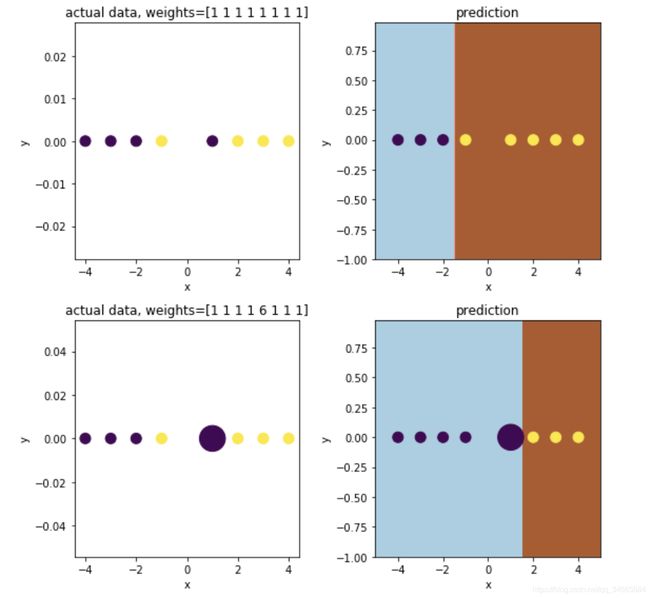
现在定义了弱点,下一步是弄清楚如何组合模型序列以使整体得到加强。
1.2 伪代码
这里给出SAMME,是一种处理多分类问题的特定方法。
AdaBoost训练一系列增强采样权重(augmented sample weights)的模型,并基于误差为各个分类器生成“置信”系数Alpha。低错误会有较大的Alpha,这意味着在最终分类结果投票中该分类器的重要性更高。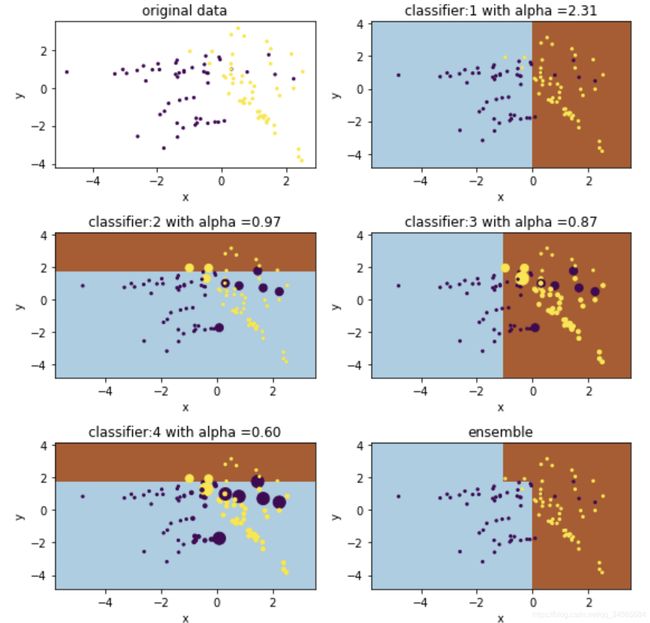
1.3 python实现
from sklearn.ensemble import AdaBoostClassifier
from sklearn.datasets import make_classification
X,Y = make_classification(n_samples=100, n_features=2, n_informative=2,
n_redundant=0, n_repeated=0, random_state=102)
clf = AdaBoostClassifier(n_estimators=4, random_state=0, algorithm='SAMME')
clf.fit(X, Y)
parameters:
- base_estimator : object, optional (default=None)
The base estimator from which the boosted ensemble is built. If None, then the base estimator is DecisionTreeClassifier(max_depth=1) ——弱分类器模型 - n_estimators : integer, optional (default=50)
The maximum number of estimators at which boosting is terminated. In case of perfect fit, the learning procedure is stopped early. —— 弱分类器最大数量,为了防止过拟合,训练过程会采用early stopping - learning_rate : float, optional (default=1.)
Learning rate shrinks the contribution of each classifier by learning_rate. —— 学习率 - algorithm : {‘SAMME’, ‘SAMME.R’}, optional (default=’SAMME.R’) ——boosting算法
If ‘SAMME.R’ then use the SAMME.R real boosting algorithm. base_estimator must support calculation of class probabilities. If ‘SAMME’ then use the SAMME discrete boosting algorithm. - random_state : int, RandomState instance or None, optional (default=None)
2.Gradient Boosting
2.1 定义弱点
Gradient Boosting对问题的处理方式有所不同。Gradient Boosting不着重于调整数据点的权重,而是着眼于预测与ground truth之间的差异。
In Gradient Boosting,“shortcomings” are identified by gradients.
In Adaboost,“shortcomings” are identified by high-weight data points
在GB中,弱点由梯度定义,在Adaboost中,弱点由高权重数据定义。
Let’s play a game…
你有(x1,y1),(x2,y2),…(xn,yn),让你拟合一个函数F(x)来最小化均方误差。假设你的朋友想帮助你,他给你一个模型F,你检查这个模型,发现模型很好,但还不够完美,有一些误差: F(x1) = 0.8, while y1 = 0.9, and F(x2) = 1.4 while y2 = 1.3… 如何提升你的模型?
游戏规则:
- 你不能改变模型F
- 你可以增加一个额外的模型(回归树)h,这样新的预测会变成F(x)+h(x)
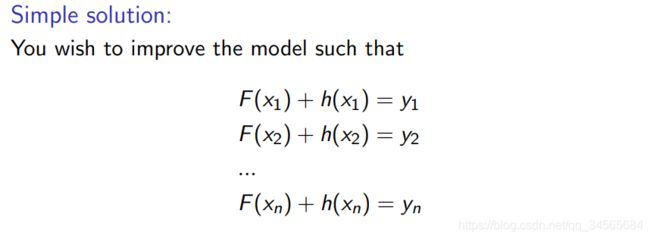
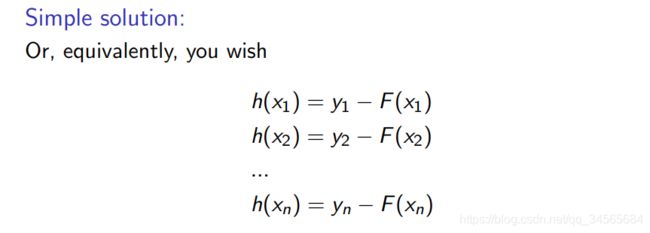
回归树h也许不能完美拟合这个误差,但它可以减小这个误差。
yi − F(xi) 称为’残差‘.。残差的存在导致了模型F不能work的很好,h的存在就是为了补偿F的弱点,如果新的模型 F+h 仍然不能满足,我们可以再加一个回归树h。
然而这和梯度有什么关系呢??
什么是梯度下降?
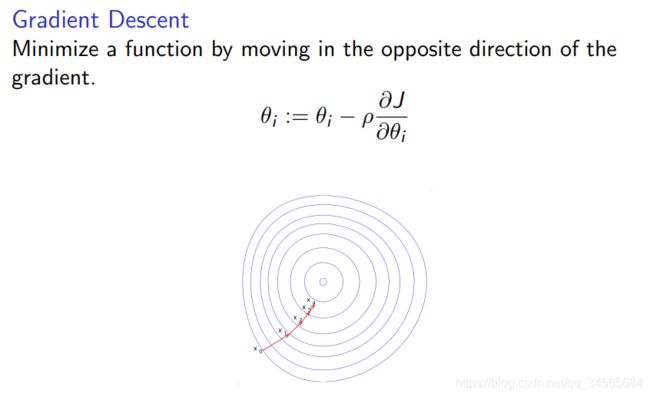
设损失函数是均方误差函数,则
所以,’残差‘就是负的梯度,用h来拟合残差,就是用h来拟合负梯度

给定一个初始化的模型F,计算损失函数关于模型预测值F(x)的倒数,得到负梯度,用负梯度作为h与模型F融合,这里的损失函数可以是任意损失函数。

python实现
from sklearn.ensemble import GradientBoostingRegressor
model = GradientBoostingRegressor(n_estimators=3,learning_rate=1)
model.fit(X,Y)
# for classification
from sklearn.ensemble import GradientBoostingClassifier
model = GradientBoostingClassifier()
model.fit(X,Y)
上述是针对GradientBoosting的回归情况,对于分类情况稍有不同:
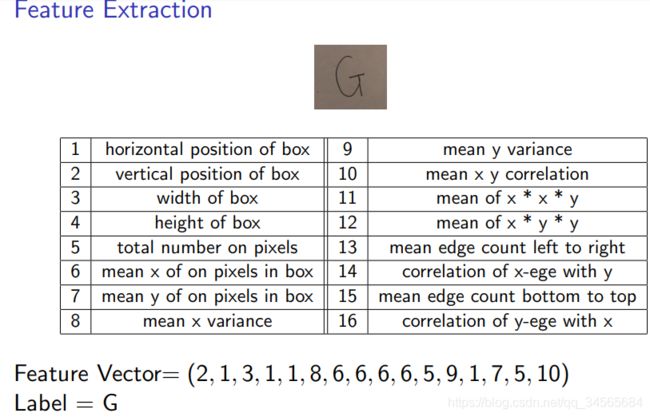
给定手写字母数据集,A~Z,
- 多类分类任务
- 26个类 A,B,C,…Z
以字母G为例,提取一下16个特征:
模型
- 26个分数方程(我们的模型): F A , F B , F C , . . . , F Z F_A, F_B, F_C,...,F_Z FA,FB,FC,...,FZ, F A 代 表 模 型 对 A 的 分 数 F_A代表模型对A的分数 FA代表模型对A的分数
- 分数被用来归一化成概率:
P A ( x ) = e F A ( x ) ∑ c = A Z e F c ( x ) P_A(x) = \frac{e^{F_A(x)}}{\sum_{c=A}^{Z}e^{F_c(x)}} PA(x)=∑c=AZeFc(x)eFA(x)
P B ( x ) = e F B ( x ) ∑ c = A Z e F c ( x ) P_B(x) = \frac{e^{F_B(x)}}{\sum_{c=A}^{Z}e^{F_c(x)}} PB(x)=∑c=AZeFc(x)eFB(x)
P Z ( x ) = e F Z ( x ) ∑ c = A Z e F c ( x ) P_Z(x) = \frac{e^{F_Z(x)}}{\sum_{c=A}^{Z}e^{F_c(x)}} PZ(x)=∑c=AZeFc(x)eFZ(x)
模型预测的类别就是分数最高的那个类别 - step 1 将数据的label转化成one-hot编码,例如 y 5 = G , 转 化 为 Y A ( x 5 ) = 0 , Y B ( x 5 ) = 0 , . . . , Y G ( x 5 ) = 1 , . . . , Y Z ( x 5 ) = 0 y_5=G,转化为Y_A(x_5)=0,Y_B(x_5)=0,...,Y_G(x_5)=1,...,Y_Z(x_5)=0 y5=G,转化为YA(x5)=0,YB(x5)=0,...,YG(x5)=1,...,YZ(x5)=0
- step 2 用现有模型 F A , F B , F C , . . . , F Z F_A, F_B, F_C,...,F_Z FA,FB,FC,...,FZ计算 P c ( x i ) P_c(x_i) Pc(xi)的概率分布
- step3 用KL散度计算真实label与预测概率分布的不同
目标
- 最小化总损失(KL散度)
- 对于每一个 x i x_i xi我们都希望预测概率分布能与真实label分布尽可能的接近
- 我们通过调整模型 F A , F B , F C , . . . , F Z F_A, F_B, F_C,...,F_Z FA,FB,FC,...,FZ来达到这个目标
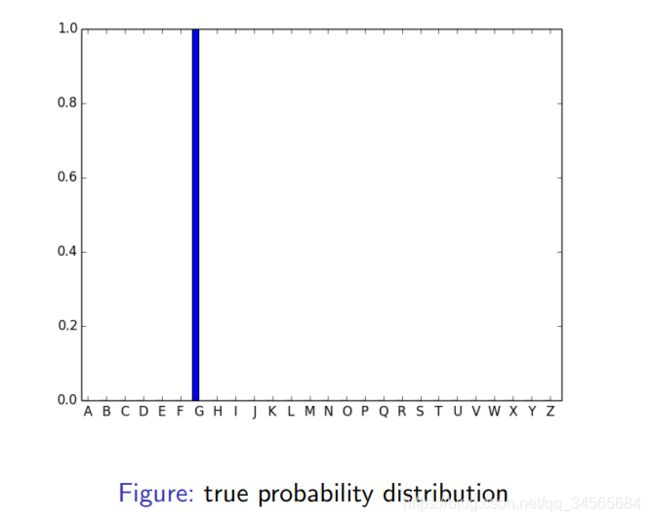
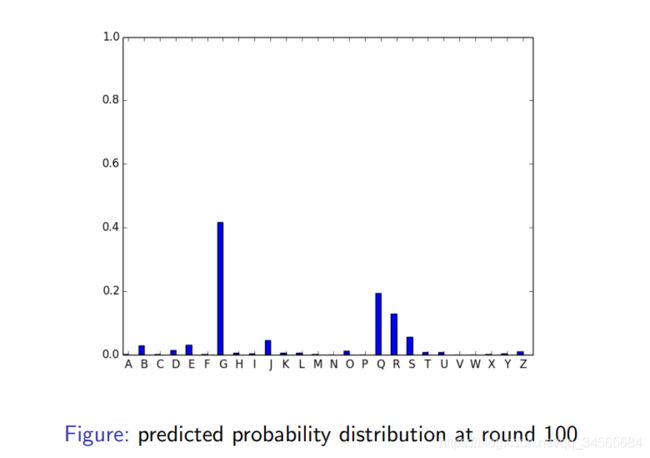
复习一下回归问题时,GradientBoosting的形式

对于分类模型

