并发编程(二),python 多线程爬虫
目录
单线程爬取数据与多线程对比
python实现生产者消费者爬虫
多组件的Pipeline技术架构
生产者消费者爬虫架构
多线程数据通信的queue.Queue
代码编写实现生产者消费者爬虫
单线程爬取数据与多线程对比
import requests, time import threading urls = [ f"https://q.cnblogs.com/list/unsolved?page={page}" for page in range(1, 50 + 1) ] def crawling(url): data = requests.get(url) print(url, len(data.text)) # 单线程 def single_thread(): for url in urls: crawling(url) # 多线程 def single_threading(): threads = [] for url in urls: # 线程执行的函数,不能加()否则调用,args元祖传参 threads.append(threading.Thread(target=crawling, args=(url,))) for thread in threads: thread.start() for thread in threads: thread.join() if __name__ == '__main__': print('start to perform!') start = time.time() single_thread() # single_threading() end = time.time() print(end - start)# 单线程
>>start to perform!
https://q.cnblogs.com/list/unsolved?page=1 48108
https://q.cnblogs.com/list/unsolved?page=2 48842.......
https://q.cnblogs.com/list/unsolved?page=50 49580
9.569056272506714
# 多线程
>>start to perform!
https://q.cnblogs.com/list/unsolved?page=6 49070
https://q.cnblogs.com/list/unsolved?page=19 488750.3545997142791748
9.5690/0.3545
26.992947813822287 整整26倍差距
从上述代码中我们不难看出线程的速度之快,同时也可以看到多线程的无序性,线程的调度是由cpu调度决定的,所以是无序的。同时也看到一个叫做join()的函数,下面对join()做一个讲解。
join():子线程执行完毕后在执行主线程,当这个线程执行完毕后在执行其它线程。从三个案例中去分析:
案例一:无join
def single_threading(): threads = [] for url in urls: # 线程执行的函数,不能加()否则调用,args元祖传参 threads.append(threading.Thread(target=crawling, args=(url,))) for thread in threads: thread.start() # for thread in threads: # thread.join()>>start to perform!
0.06383013725280762
https://q.cnblogs.com/list/unsolved?page=23 49409
https://q.cnblogs.com/list/unsolved?page=7 49806
从上述结果中我们不难看出,没有join()主线程先执行后子线程才执行,并且子线程无需
案例二:start()后立即执行join()
def single_threading(): threads = [] for url in urls: # 线程执行的函数,不能加()否则调用,args元祖传参 threads.append(threading.Thread(target=crawling, args=(url,))) for thread in threads: thread.start() thread.join()>>start to perform!
https://q.cnblogs.com/list/unsolved?page=1 48108
https://q.cnblogs.com/list/unsolved?page=2 488429.003865003585815
多线程变成了顺序执行,同时失去了其优势。
第三种案例就是上面模式,无序,但是子线程执行完毕后再执行主线程。
python实现生产者消费者爬虫
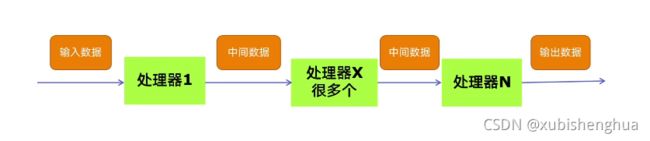
多组件的Pipeline技术架构
一般来说,在编程的时间中,复杂的事情基本不会一下子做完,都会分成很多中间步骤去做,这就是Pipeline架构思想。
生产者消费者爬虫架构
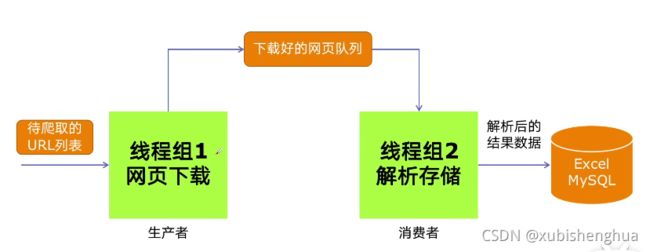
使用生产者消费者模式去开发爬虫优势:生产者消费者可以由两部分人同时开发,降低耦合性,可以分别配置不同的资源比如线程数。
多线程数据通信的queue.Queue
queue.Queue队列 可实现多线程之间,线程安全(多个线程并发访问数据不会出现冲突)的数据通信。
具体操作:
1.导入queue库:import queue
2.实例化queue对象:q = queue.Queue(maxsize=0) maxsize=0 可指定队列数量,为0时无限。
3.添加元素:q.put(item)
4.获取元素:q.get(item)
5.查询:# 数量 q.qsize()
# 判断是否为空 q.empty()
# 判断是否已满 q.full()
6.清空队列:q.clear()
这里需要提到的是,put和get当队列中没有数据,或者队列以满将会进入阻塞状态后面代码中会有体现。
代码编写实现生产者消费者爬虫
import random, requests, time, threading import queue from bs4 import BeautifulSoup urls = [ f"https://www.cnblogs.com/#p{page}" for page in range(1, 50 + 1) ] def carw(url): r = requests.get(url) return r.text def parse(html): soup = BeautifulSoup(html, 'html.parser') links = soup.find_all("a", class_="post-item-title") return [(link['href'], link.get_text()) for link in links] # 生产者 def do_carw(url_queue: queue.Queue, html_queue: queue.Queue): while True: url = url_queue.get() html = carw(url) html_queue.put(html) print(threading.current_thread().name, '生产者生产:{},url_queue.size:{}' .format(url, url_queue.qsize())) time.sleep(random.randint(1, 2)) # 消费者 def do_parse(html_queue: queue.Queue, file): while True: html = html_queue.get() text = parse(html) for result in text: file.write(str(result) + '\n') print(threading.current_thread().name, "消费者消费:{},html_queue.size:{}" .format(len(html), html_queue.qsize())) time.sleep(random.randint(1, 2)) if __name__ == '__main__': url_queue = queue.Queue() html_queue = queue.Queue() for url in urls: url_queue.put(url) # 生产者开启三个线程 for i in range(3): t = threading.Thread(target=do_carw, args=(url_queue, html_queue), name=f'carw{i}') t.start() file = open('test.txt', 'w') # 消费者开启两个线程 for i in range(2): t = threading.Thread(target=do_parse, args=(html_queue, file), name=f'parse{i}') t.start()>>parse1 消费者消费:69324,html_queue.size:1
carw0 生产者生产:https://www.cnblogs.com/#p6,url_queue.size:43
carw1 生产者生产:https://www.cnblogs.com/#p7,url_queue.size:43
parse0 消费者消费:69324,html_queue.size:2
carw2 生产者生产:https://www.cnblogs.com/#p8,url_queue.size:42
parse0 消费者消费:69324,html_queue.size:1
parse1 消费者消费:69324,html_queue.size:1
carw0 生产者生产:https://www.cnblogs.com/#p9,url_queue.size:40
carw1 生产者生产:https://www.cnblogs.com/#p10,url_queue.size:40
carw2 生产者生产:https://www.cnblogs.com/#p11,url_queue.size:38
carw1 生产者生产:https://www.cnblogs.com/#p12,url_queue.size:38
parse0 消费者消费:69324,html_queue.size:3
parse1 消费者消费:69324,html_queue.size:3carw0 生产者生产:https://www.cnblogs.com/#p46,url_queue.size:4
parse0 消费者消费:69324,html_queue.size:14
carw1 生产者生产:https://www.cnblogs.com/#p47,url_queue.size:3
carw2 生产者生产:https://www.cnblogs.com/#p48,url_queue.size:2
parse1 消费者消费:69324,html_queue.size:15
carw1 生产者生产:https://www.cnblogs.com/#p49,url_queue.size:1
parse0 消费者消费:69324,html_queue.size:15
carw0 生产者生产:https://www.cnblogs.com/#p50,url_queue.size:0
parse0 消费者消费:69324,html_queue.size:15
parse1 消费者消费:69324,html_queue.size:14
parse0 消费者消费:69324,html_queue.size:13
parse1 消费者消费:69324,html_queue.size:12
parse0 消费者消费:69324,html_queue.size:11
parse1 消费者消费:69324,html_queue.size:9
parse0 消费者消费:69324,html_queue.size:9
parse1 消费者消费:69324,html_queue.size:8
parse0 消费者消费:69324,html_queue.size:7
parse1 消费者消费:69324,html_queue.size:6
parse0 消费者消费:69324,html_queue.size:5
parse1 消费者消费:69324,html_queue.size:4
parse0 消费者消费:69324,html_queue.size:3
parse1 消费者消费:69324,html_queue.size:2
parse0 消费者消费:69324,html_queue.size:1
parse1 消费者消费:69324,html_queue.size:0
消费者因为开启线程少于生产者所以执行较慢,从结果中可见queue的线程数据安全性,以及当生产者生产完毕后,因为获取不到数据所以进入阻塞状态,消费者消费完毕后,因为无数据消费所以进入阻塞状态。