数据挖掘:探索性数据分析(EDA)(补充)
数据挖掘:探索性数据分析(EDA)(补充)
在上一篇文章数据挖掘:探索性数据分析(EDA)中,已经讨论了一些探索性分析的方法,但去敏数据的处理方式和一些多元统计的方法没有做介绍。本篇文章主要讲这两方面。
一、去敏数据的处理方式
去敏数据已经在之前有过介绍了,指为了保护数据,消除特征的意义。而对这类数据就无法根据业务知识,进行特征的创建。另外,我们得到的数据一般是原始数据通过变换得到的,变换的方式有很多种。本文主要针对通过乘除对数据进行缩放,然后通过加减对数据进行平移的这种数据还原。
以下是从网上找到的一个案例:
1.1 观察数据
首先介绍下,这个数据的特征都是x1,x2,x3…这种,并没有实际的含义,而我们需要对数据进行探索。从数据的数值来看,也无法得知具体是什么。
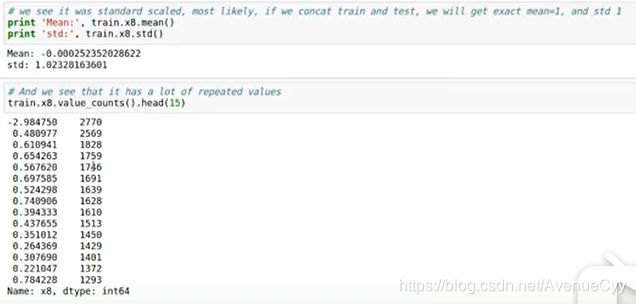
1.2 数据平移
数据是经过处理得到的,而我们要做的就是对它进行反向处理。比较常见的是平移,即加/减数据。因此,取数据唯一值unique(),然后利用用下一行数据减去上一行diff(),这样可以消除平移。
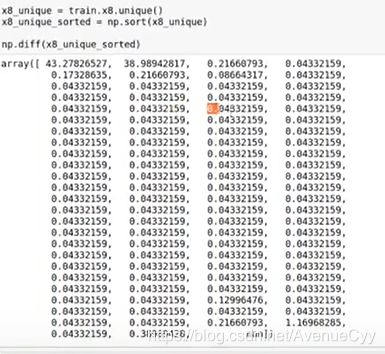
1.3 数据缩放
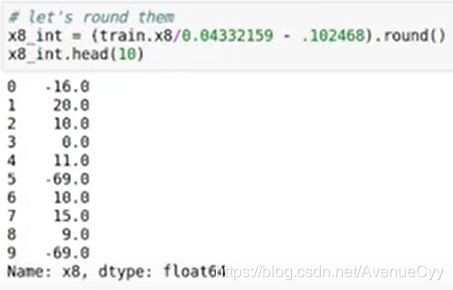
缩放是对数据进行乘/除。我们需要找到缩放的系数。经过上步可看到0.04332…这个数有很大的嫌疑。因此,除去它。得到结果如下:
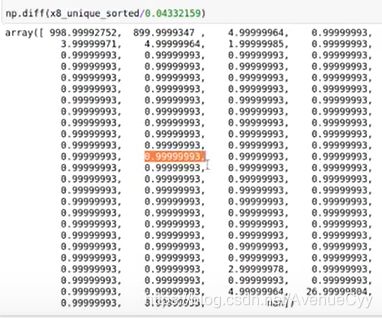
1.4 原始数据的处理
之前是在差值下找到了平移距离和缩放系数。接下来对原始数据进行处理。处理后的数据如下,这样看就比较舒服。而一般处理到这也结束了,想要知道数据的具体含义,一是根据数据的数值和数据赛题,进行猜测。另外还有以下一种方法,通过数据遗漏的信息,得到数据的实际意义。
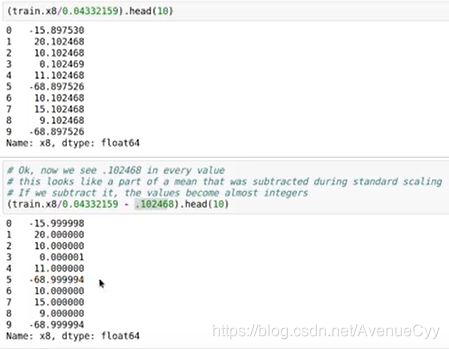
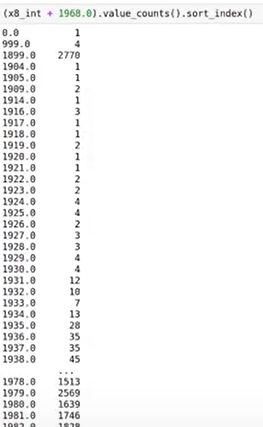
1.5 数据漏洞
通过观察数据的取值,可以看到1968。而这大概率是年份。这样我们就知道这列数据是跟年份有关的。说是数据漏洞,这可能是最开始输入数据时,输入错的一个值。比如输入了0,而它转换成了年份,别的数据是输入正确的,转为了别的数值。所以说,这是根据数据的错误得到的有用信息。

1.6最终处理
这样把年份加上后,我们就得到了想要的数据内容。
1.7 小结
以上介绍的只是一种处理方式,虽然有一定的依据,但看着可信度不是那么高,即所有的数据都能这么处理吗?答案当然是不能。不过,它可以作为处理去敏数据的一种手段,有的时候可能会有奇效。
二、EDA补充
EDA的操作方法有很多,上一篇文章是出于自己对EDA的理解。接下来要介绍的是本人之前在学习中(网上的视频,老师:途索)遇到的一些方法,跟之前的比,有重叠的方法,而也有新的方法,更多的是方法论。
2.1 单因子分析
单因素分析中包括:异常值分析,对比分析,结构分析,分布分析。
2.1.1 异常值分析
这个在之前的文章数据预处理中有过说明,不再赘述。
2.1.2 对比分析
2.1.2.1 比较什么
-
绝对数比较
比较大小。比如均值,标准差,离散系数等。 -
相对数比较
- 结构:产品合格率评价产品质量。
- 比例:总体内不同数值之间的比较,即各类别的占比。
- 比较:同一时空下的不同指标进行对比。不同时空下同一商品的价格。
- 动态:商品价格的增速。同比增长,环比增长等,自己跟自己比。
- 强度:人均GDP,密度等。
2.1.2.2 怎么比较
- 时间:同比,环比等。
- 空间:不同城市,不同公司,不同部门之间的比较。
- 经验与计划:拿现在的与之间历史上发生的事进行比较判断。
不用记清这么多的比较的事例,主要要对数据有对比的想法,包括时间,空间,结构占比,强度等。通过对比,发现新知。
2.1.3 结构分析
- 静态:直接比较。各产业之间比较。
- 动态:以时间为轴。
主要记住动态即时间。
2.1.4 分布分析
- 直接获得概率分布
- 是不是正态分布
- 极大似然:相似程度的衡量,一堆数跟一个分布有多像。
这个之前有提到过,绘制直方图,计算统计量,来掌握数据的分布情况。
2.2 多因子分析与复合分析
2.2.1 多因子分析
多因子分析主要包括以下内容:
假设检验与方差检验
相关系数:皮尔逊、斯皮尔曼
回归:线性回归
PCA与奇异值分解
这些分析方法都是统计学中的内容。
- 假设检验
假设检验的内容我会在后续统计学相关的文章进行说明,大家可以百度搜索下,了解其思想原理。
t检验:两组样本的分布是否一致。与z检验一样。只是样本大小。
卡方检验:同一事件下,两个因素之间有没有关联。化妆(事件)次数是否与性别(因素)有关。
方差F检验:多个样本,两两之间是否有差异。同一标准下,多个样本间的差异是否与某个因素有关。家电(标准)好坏是否与品牌(因素)有关。 - 相关系数
在上一篇文章说的比较全面,不再赘述。 - 线性回归
通过判断系数,来得到各个特征的重要性。也可用线性方程进行预测。这个会在后续模型选择中进行说明。
决定系数:R^2,判断拟合好坏。
残差不相关(DW检验):DW=2,残差不相关。4正相关,0负相关。 - PCA与奇异值分解
这个主要用来做特征的降维工作,在特征工程中会说明。
2.2.1 复合分析
复合分析主要包括以下几个方面:
交叉分析
数据分组与钻取
相关分析
因子分析
聚类分析
回归分析
2.2.1.1 交叉分析
两两数据进行对比。
-
z/t/卡方/F检验
看p-value大小。关于统计学的内容在统计学专题中再做详细介绍。 -
数据透视表。
这个在pandas中,用的是pivot_table,对数据进行聚合,更好的观察数据。在Excel中,应用的更加广泛也更加便捷。基本思想就是通过列联表观察数据
2.2.1.2 数据分组与钻取
- 分组:将数据进行分组后进行分析/组内差异小,组件间差异大,聚类/分类。如年龄分为青年,中年,老年。在上一篇文章中有提到过。
- 钻取:改变维的层次,变换分析的粒度。
向下钻取:数据展开,分析细节。知道每个班的分数,想看各个班男女的分数。
向上钻取:汇总,分组数据。知道每个人的分数,想看每个班的平均分是多少。或日,月,年的时间过程。
连续数据分组:
- 分隔(一阶差分),拐点(二阶差分)
- 聚类
- 不纯度(Gini):以Gini=0的点为分割点。
2.2.1.3 相关分析
贴上一张热力图。

对于数据相关性,在上一篇文章中有提到,主要是连续数据和离散数据(有序数据),对于分类数据,也可以用三大相关系数,但效果不是很好。这里介绍Gini系数用于分类。
- 二分类:可以直接用相关系数,但有些失真。也可以Gini(不纯度)来计算。
- 多分类:如果是定序的(low,midder,high),可以直接编码成0,1,2进行corr计算。
可以使用熵,进行离散数据的计算。熵:用来计算不确定性的值。样本分布的越均匀,信息熵就越大。0.5/0.5.
熵:H(X)如果样本都属于一个类别,那么熵就是0.样本分布越均匀,信息熵就越大。因此可以找熵最大的点,进行分类。
条件熵 H(Y|X)
熵增益(互信息)I(X,Y)=:H(X)-H(X|Y)对于分类数目过多的特征,有不正确的偏向。不具有归一性。
熵增益率:I(X,Y)/H(Y),不对称。
相关性:Corr(X,Y) = I(X,Y)/sqrt(H(X)*H(Y))
Gini系数:Gini(D)=1-sum((Ck/D)^2).D:关注目标的标度;Ck:相对于关注的目标,要对比的属性。取Gini最小的点为分割点。Gini越小,不纯度越小,两边的分类纯度就更好。
关于熵的简要说明,具体说明熵的含义会在后续决策树中提到,这里先有个印象,可以用熵来计算相关性。
2.2.1.4 因子分析
因子分析,也叫成分分析,从多个属性变量中分析共性。
- 探索性因子分析:通过协方差矩阵,相关性矩阵等指标,降维,得到最主要的因子。(主成分分析)
- 验证性因子分析:验证因子与关注属性之间是否有关联。(相关,卡方,覆盖,Anova,熵,F-值,自定)
因子分析是一种特征选择的方法,后续在特征工程中进行说明。
2.2.1.5 聚类分析、回归分析
这两个也会在后续模型选择时提到……
三、总结
本次对去敏数据的一般处理方法和EDA的相关知识进行了补充说明。其中的很多方法都是在特征工程中使用的,而其实特征工程也是深入了解数据的一步,与EDA之间相辅相成。
这篇文章更多的是我对之前学习的一个总结(感觉写的很一般…)。里面很多东西没有进行详细说明,会在之后的文章特征工程和模型选择上进行详细说明。