R语言小白学习笔记14—线性模型
R语言小白学习笔记14—线性模型
- 笔记链接
- 学习笔记14—线性模型
-
- 14.1 简单线性回归
- 14.2 多元回归——以纽约市公开数据详细分析
笔记链接
学习笔记1—R语言基础.
学习笔记2—高级数据结构.
学习笔记3—R语言读取数据.
学习笔记4—统计图.
学习笔记5—编写R语言函数和简单的控制循环语句.
学习笔记6—分组操作.
学习笔记7—高效的分组操作:dplyr.
学习笔记8—数据迭代.
学习笔记9—数据整理.
学习笔记10—数据重构:Tidyverse.
学习笔记11—字符串操作.
学习笔记12—概率分布.
学习笔记13—基本统计.
学习笔记14—线性模型
14.1 简单线性回归
简单线性回归公式:
y=a+bx+∈

∈~Ν(0,σ^2)
以UsingR包中的father.son数据为例,将父亲的身高作为预测变量,儿子的身高作为反应变量。
例:
> data(father.son, package = 'UsingR')
> library(ggplot2)
> head(father.son)
fheight sheight
1 65.04851 59.77827
2 63.25094 63.21404
3 64.95532 63.34242
4 65.75250 62.79238
5 61.13723 64.28113
6 63.02254 64.24221
> ggplot(father.son, aes(x=fheight, y=sheight)) + geom_point() +
+ geom_smooth(method = "lm") + labs(x="Fathers", y="Sons")

这里得到了一个回归图形,但我们仍需要计算回归结果,用lm函数:
> heightsLM <- lm(sheight ~ fheight, data = father.son)
> heightsLM
Call:
lm(formula = sheight ~ fheight, data = father.son)
Coefficients:
(Intercept) fheight
33.8866 0.5141
用summary函数可以得到模型的完整结果:
> summary(heightsLM)
Call:
lm(formula = sheight ~ fheight, data = father.son)
Residuals:
Min 1Q Median 3Q Max
-8.8772 -1.5144 -0.0079 1.6285 8.9685
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 33.88660 1.83235 18.49 <2e-16 ***
fheight 0.51409 0.02705 19.01 <2e-16 ***
---
Signif. codes:
0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
Residual standard error: 2.437 on 1076 degrees of freedom
Multiple R-squared: 0.2513, Adjusted R-squared: 0.2506
F-statistic: 361.2 on 1 and 1076 DF, p-value: < 2.2e-16
方差分析:
这里介绍另一种做方差分析检验的方法:仅用一个分类变量且无截距项来拟合一个回归
例:
> data(tips, package = "reshape2")
> head(tips)
total_bill tip sex smoker day time size
1 16.99 1.01 Female No Sun Dinner 2
2 10.34 1.66 Male No Sun Dinner 3
3 21.01 3.50 Male No Sun Dinner 3
4 23.68 3.31 Male No Sun Dinner 2
5 24.59 3.61 Female No Sun Dinner 4
6 25.29 4.71 Male No Sun Dinner 4
> tipsAnova <- aov(tip ~ day - 1, data = tips)
> tipsLM <- lm(tip ~ day - 1, data = tips)
> summary(tipsAnova)
Df Sum Sq Mean Sq F value Pr(>F)
day 4 2203.0 550.8 290.1 <2e-16 ***
Residuals 240 455.7 1.9
---
Signif. codes:
0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
> summary(tipsLM)
Call:
lm(formula = tip ~ day - 1, data = tips)
Residuals:
Min 1Q Median 3Q Max
-2.2451 -0.9931 -0.2347 0.5382 7.0069
Coefficients:
Estimate Std. Error t value Pr(>|t|)
dayFri 2.7347 0.3161 8.651 7.46e-16 ***
daySat 2.9931 0.1477 20.261 < 2e-16 ***
daySun 3.2551 0.1581 20.594 < 2e-16 ***
dayThur 2.7715 0.1750 15.837 < 2e-16 ***
---
Signif. codes:
0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
Residual standard error: 1.378 on 240 degrees of freedom
Multiple R-squared: 0.8286, Adjusted R-squared: 0.8257
F-statistic: 290.1 on 4 and 240 DF, p-value: < 2.2e-16
14.2 多元回归——以纽约市公开数据详细分析
多元回归可以有多个预测变量。
以纽约市公开数据为例:
获取数据
> housing <- read.table("http://www.jaredlander.com/data/housing.csv",
+ sep = ",", header = TRUE,
+ stringsAsFactors = FALSE)
重命名
> names(housing) <- c("Neighborhood", "Class", "Units", "YearBuilt",
+ "SqFt", "Income", "IncomePerSqFt", "Expense",
+ "ExpensePerSqFt", "NetIncome", "Value",
+ "ValuePerSqFt", "Boro")
> head(housing)
Neighborhood Class Units YearBuilt SqFt
1 FINANCIAL R9-CONDOMINIUM 42 1920 36500
2 FINANCIAL R4-CONDOMINIUM 78 1985 126420
3 FINANCIAL RR-CONDOMINIUM 500 NA 554174
4 FINANCIAL R4-CONDOMINIUM 282 1930 249076
5 TRIBECA R4-CONDOMINIUM 239 1985 219495
6 TRIBECA R4-CONDOMINIUM 133 1986 139719
Income IncomePerSqFt Expense ExpensePerSqFt
1 1332615 36.51 342005 9.37
2 6633257 52.47 1762295 13.94
3 17310000 31.24 3543000 6.39
4 11776313 47.28 2784670 11.18
5 10004582 45.58 2783197 12.68
6 5127687 36.70 1497788 10.72
NetIncome Value ValuePerSqFt Boro
1 990610 7300000 200.00 Manhattan
2 4870962 30690000 242.76 Manhattan
3 13767000 90970000 164.15 Manhattan
4 8991643 67556006 271.23 Manhattan
5 7221385 54320996 247.48 Manhattan
6 3629899 26737996 191.37 Manhattan
这里反应变量是每平方英尺的值,预测变量是剩下所有变量。
首先探索性地对数据进行可视化,用不同的视角看待数据
画出ValuePerSqFt的直方图。
> library(ggplot2)
> ggplot(housing, aes(x=ValuePerSqFt)) +
+ geom_histogram(binwidth = 10) + labs(x="Value per Square Foot")
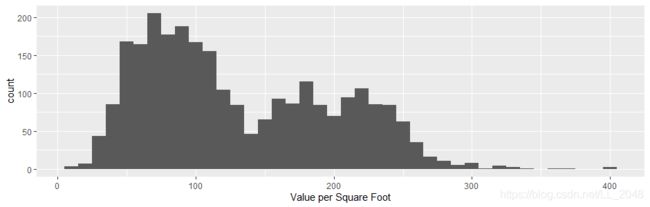
直方图的双峰特征说明有东西需要继续探索
接下来用不同的颜色代表不同Boro。并画出不同城市的直方图作对比
> ggplot(housing, aes(x=ValuePerSqFt, fill=Boro)) +
+ geom_histogram(binwidth = 10) + labs(x="Value per Square Foot")

> ggplot(housing, aes(x=ValuePerSqFt, fill=Boro)) +
+ geom_histogram(binwidth = 10) + labs(x="Value per Square Foot") +
+ facet_wrap(~Boro)
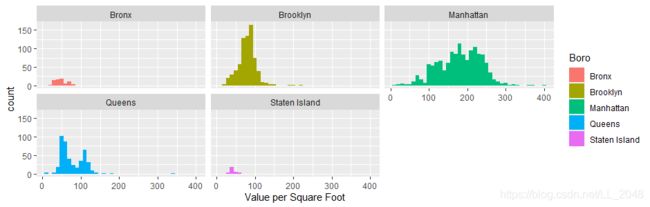
可以看出Brooklyn和Queens是一个模式,Manhattan是另外一个模式,其余数据不足。
现在我们看下建筑面积和单元的个数
> ggplot(housing, aes(x=SqFt)) + geom_histogram()

> ggplot(housing, aes(x=Units)) + geom_histogram()

去除单元数大于1000的数据
> ggplot(housing[housing$Units < 1000, ], aes(x=SqFt)) + geom_histogram()

> ggplot(housing[housing$Units < 1000, ], aes(x=Units)) + geom_histogram()
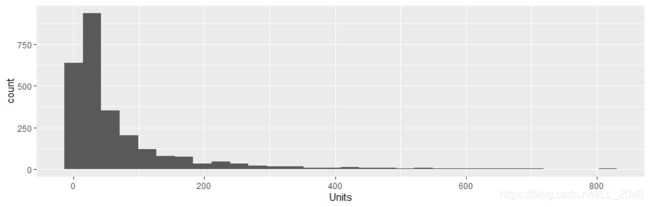
会发现去除超过1000单元的建筑后是一样的
那么以每平方英尺的值为纵坐标,分别以单元数和建筑面积为横坐标,画出散点图:
> ggplot(housing, aes(x=SqFt, y=ValuePerSqFt)) + geom_point()

> ggplot(housing, aes(x=Units, y=ValuePerSqFt)) + geom_point()

同样,去除超过1000单元的数据进行观察
> ggplot(housing[housing$Units < 1000, ], aes(x=SqFt, y=ValuePerSqFt)) + geom_point()

> ggplot(housing[housing$Units < 1000, ], aes(x=Units, y=ValuePerSqFt)) + geom_point()
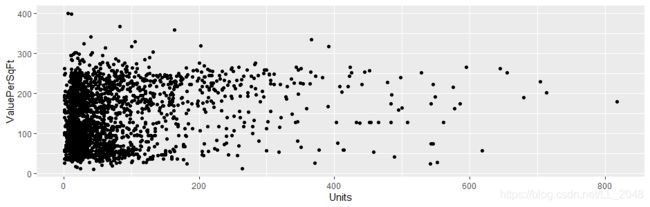
可以看出删除这些离群值数据影响不大。所以删除后继续分析
> sum(housing$Units >= 1000)
[1] 6
> housing <- housing[housing$Units < 1000, ]
可以看出数据在Units较小时较为集中,较大时较为分散,所以作对数可能更好分析一些。
所以这里分别对SqFt和Units作对数并作图进行比较
> ggplot(housing, aes(x=SqFt, y=ValuePerSqFt)) +geom_point()
> ggplot(housing, aes(x=log(SqFt), y=ValuePerSqFt)) +geom_point()
> ggplot(housing, aes(x=SqFt, y=log(ValuePerSqFt))) +geom_point()
> ggplot(housing, aes(x=log(SqFt), y=log(ValuePerSqFt))) +geom_point()



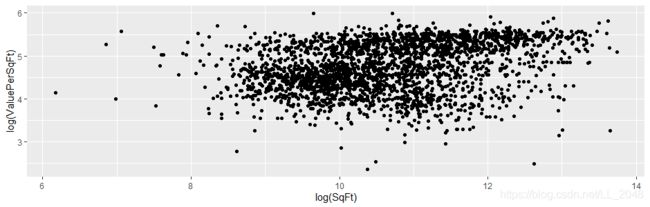
> ggplot(housing, aes(x=Units, y=ValuePerSqFt)) +geom_point()
> ggplot(housing, aes(x=log(Units), y=ValuePerSqFt)) +geom_point()
> ggplot(housing, aes(x=Units, y=log(ValuePerSqFt))) +geom_point()
> ggplot(housing, aes(x=log(Units), y=log(ValuePerSqFt))) +geom_point()

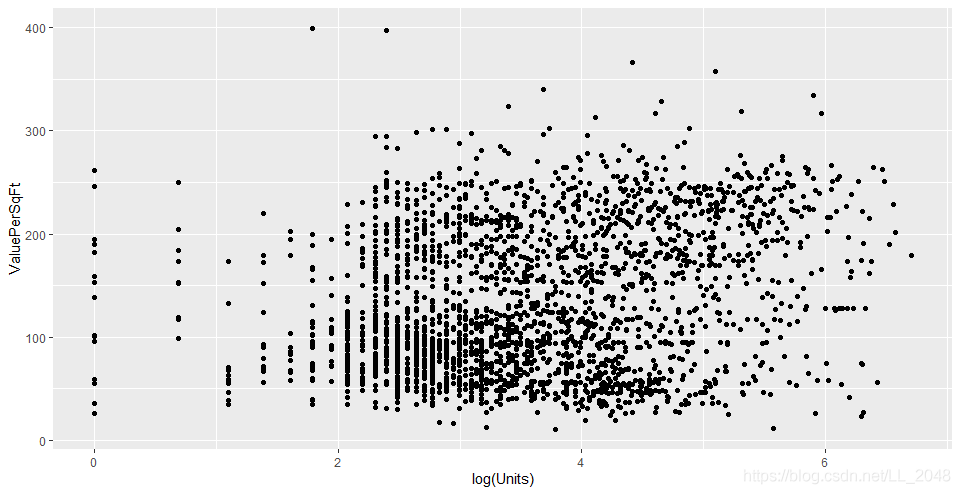


通过这些对比可以看到对建筑面积和单元数取对数或许更有用
接下来开始进行模型的建立
用lm函数建立模型,多个预测变量用“+”隔开
> house1 <- lm(ValuePerSqFt ~ Units + SqFt + Boro, data=housing)
> summary(house1)
Call:
lm(formula = ValuePerSqFt ~ Units + SqFt + Boro, data = housing)
Residuals:
Min 1Q Median 3Q Max
-168.458 -22.680 1.493 26.290 261.761
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 4.430e+01 5.342e+00 8.293 < 2e-16
Units -1.532e-01 2.421e-02 -6.330 2.88e-10
SqFt 2.070e-04 2.129e-05 9.723 < 2e-16
BoroBrooklyn 3.258e+01 5.561e+00 5.858 5.28e-09
BoroManhattan 1.274e+02 5.459e+00 23.343 < 2e-16
BoroQueens 3.011e+01 5.711e+00 5.272 1.46e-07
BoroStaten Island -7.114e+00 1.001e+01 -0.711 0.477
(Intercept) ***
Units ***
SqFt ***
BoroBrooklyn ***
BoroManhattan ***
BoroQueens ***
BoroStaten Island
---
Signif. codes:
0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
Residual standard error: 43.2 on 2613 degrees of freedom
Multiple R-squared: 0.6034, Adjusted R-squared: 0.6025
F-statistic: 662.6 on 6 and 2613 DF, p-value: < 2.2e-16
这里给出了模型的信息:包括函数的名称、残差(residuals)的分位数、系数估计、标准误差、每个变量的p值、自由度、模型的p值和F统计量的值。
模型的p值和F统计量是度量模型的拟合优度。
从模型中快速获取系数的一种方法是使用coef函数,或对模型对象使用$运算符
> house1$coefficients
(Intercept) Units SqFt
4.430325e+01 -1.532405e-01 2.069727e-04
BoroBrooklyn BoroManhattan BoroQueens
3.257554e+01 1.274259e+02 3.011000e+01
BoroStaten Island
-7.113688e+00
> coef(house1)
(Intercept) Units SqFt
4.430325e+01 -1.532405e-01 2.069727e-04
BoroBrooklyn BoroManhattan BoroQueens
3.257554e+01 1.274259e+02 3.011000e+01
BoroStaten Island
-7.113688e+00
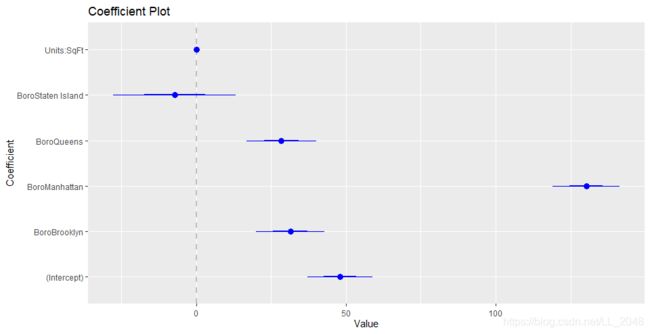
接下来对回归结果进行可视化
用coefplot包可以完成。
> library(coefplot)
> coefplot(house1)

其中每个系数的估计值是一个点,粗线表示一个标准误差的置信区间,细线代表两倍标准误差的置信区间。竖直的直线表示0。
一般情况下,判断在统计上是否显著的方法是看两倍置信区间是否包含0,如果不包含,则在统计上显著。
观察此图可以发现Manhattan对每英尺价值具有最大影响。但建筑中的单元数或面积对其影响不大。
这个模型只有相加项,但变量之间的相互作用也可能会有影响。
在交互变量之间使用“*”符号可以把交互项加入表达式中。
如果只包括交互项不包括单个变量用“:”。
> house2 <- lm(ValuePerSqFt ~ Units * SqFt + Boro, data=housing)
> house3 <- lm(ValuePerSqFt ~ Units : SqFt + Boro, data=housing)
> house2$coefficients
(Intercept) Units SqFt
4.093685e+01 -1.024579e-01 2.362293e-04
BoroBrooklyn BoroManhattan BoroQueens
3.394544e+01 1.272102e+02 3.040115e+01
BoroStaten Island Units:SqFt
-8.419682e+00 -1.809587e-07
> house3$coefficients
(Intercept) BoroBrooklyn BoroManhattan
4.804972e+01 3.141208e+01 1.302084e+02
BoroQueens BoroStaten Island Units:SqFt
2.841669e+01 -7.199902e+00 1.088059e-07
> coefplot(house2)

> coefplot(house3)
如果3个变量有交互作用,那么回归的系数包括3个单个变量的系数、3个两两交互的系数和一个3变量交互项的系数。
> house4 <- lm(ValuePerSqFt ~ SqFt * Units * Income, housing)
> house4$coefficients
(Intercept) SqFt Units
1.116433e+02 -1.694688e-03 7.142611e-03
Income SqFt:Units SqFt:Income
7.250830e-05 3.158094e-06 -5.129522e-11
Units:Income SqFt:Units:Income
-1.279236e-07 9.107312e-14
一个连续变量(如SqFt)和一个factor(如Boro)交互,结果是连续变量的个体项
> house5 <- lm(ValuePerSqFt ~ Class*Boro, housing)
> house5$coefficients
(Intercept)
47.041481
ClassR4-CONDOMINIUM
4.023852
ClassR9-CONDOMINIUM
-2.838624
ClassRR-CONDOMINIUM
3.688519
BoroBrooklyn
27.627141
BoroManhattan
89.598397
BoroQueens
19.144780
BoroStaten Island
-9.203410
ClassR4-CONDOMINIUM:BoroBrooklyn
4.117977
ClassR9-CONDOMINIUM:BoroBrooklyn
2.660419
ClassRR-CONDOMINIUM:BoroBrooklyn
-25.607141
ClassR4-CONDOMINIUM:BoroManhattan
47.198900
ClassR9-CONDOMINIUM:BoroManhattan
33.479718
ClassRR-CONDOMINIUM:BoroManhattan
10.619231
ClassR4-CONDOMINIUM:BoroQueens
13.588293
ClassR9-CONDOMINIUM:BoroQueens
-9.830637
ClassRR-CONDOMINIUM:BoroQueens
34.675220
ClassR4-CONDOMINIUM:BoroStaten Island
NA
ClassR9-CONDOMINIUM:BoroStaten Island
NA
ClassRR-CONDOMINIUM:BoroStaten Island
NA
由于SqFt变量和Units变量不显著,所以我们放大进行观察
> coefplot(house1, sort='mag') + scale_x_continuous(limits = c(-.25, .1))
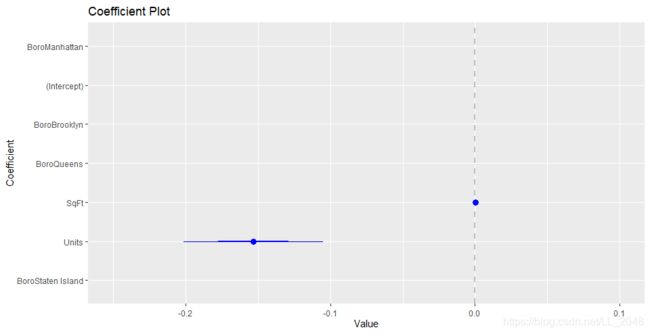
> coefplot(house1, sort='mag') + scale_x_continuous(limits = c(-.0005, .0005))

可以看到放大后其系数都不为0,所以可能是尺度问题。
尺度问题可以通过标准化或归一化变量解决,变量减去均值再除以标准差。
标准化可以用scale函数实现
> house.b <- lm(ValuePerSqFt ~ scale(Units) + scale(SqFt) + Boro, data=housing)
> coefplot(house.b, sort='mag')

通过和之前的图进行对比可以发现,SqFt变量有一个标准差的改变时,ValuePerSqFt变量变化约30。也可以看出Units变量有负面的影响,说明Units变量有利于建筑的Value变量。
另一种好的检验方法是将Units变量与SqFt变量的比值作为一个变量。除法必须放在I函数里边
> house6 <- lm(ValuePerSqFt ~ I(SqFt/Units) + Boro, housing)
> house6$coefficients
(Intercept) I(SqFt/Units) BoroBrooklyn
43.754838763 0.004017039 30.774343209
BoroManhattan BoroQueens BoroStaten Island
130.769502685 29.767922792 -6.134446417
我们已经拟合了很多模型,模型的选择之后介绍。此时可以将多个模型系数进行可视化:
> multiplot(house1, house2, house3)

回归经常用于做预测,R语言中predict函数就可以完成。
例:
> housingNew <- read.table("http://www.jaredlander.com/data/housingNew.csv", sep=",", header=TRUE, stringsAsFactors = FALSE)
> housePredict <- predict(house1, newdata=housingNew, se.fit=TRUE, interval = "prediction", level=.95)
> head(housePredict$fit)
fit lwr upr
1 74.00645 -10.813887 158.8268
2 82.04988 -2.728506 166.8283
3 166.65975 81.808078 251.5114
4 169.00970 84.222648 253.7968
5 80.00129 -4.777303 164.7799
6 47.87795 -37.480170 133.2361
> head(housePredict$se.fit)
1 2 3 4 5 6
2.118509 1.624063 2.423006 1.737799 1.626923 5.318813