「Python3 爬虫标准化项目」爬虫目标整理和数据准备
文章目录
- 内容介绍
- 整理目标
- 操作步骤
- 总结
内容介绍
开发环境为 Python3.6,Scrapy 版本 2.4.x ,Gerapy 版本 0.9.x ,爬虫项目全部内容索引目录
看懂Python爬虫框架,所见即所得一切皆有可能
很多小伙伴爬虫做多了发现没有在开始做合理规划的情况下后期整理或者再次使用、查询的时候非常尴尬,为了避免这种尴尬的局面,很多内容要提前做好准备,也是为了后期的管理框架搭建做准备。
因此这个章节很重要,要看懂这篇文章是做什么的,为什么后面你会发现爬个网站分分钟的事。
通过这种方法整理了几万个页面进行部署管理的时候很方便。
整理目标
爬虫的目标是什么?无非分两种列表页和详情页。以新闻内容抓取举例,一般往往流程都是先通过抓取列表页的内容之后,遍历列表页抓取详情页的内容,最后将抓取的数据有序的存储到我们的数据仓库中。
以 中国中医药网的新闻中心要闻 页面举例来说,页面内容如下。


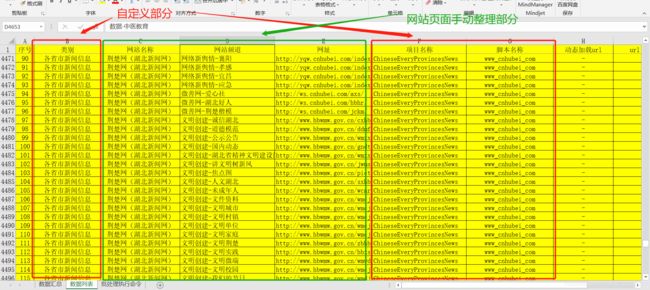
我们整理的目标是第一张图里的列表信息,整理的最终结果如下。

这样做的好处有很多,主要是便于管理和统计,抓过多少内容以及明细一目了然。

为了在写脚本的时候便于在爬虫脚本编写过程中提高对应代码编写的效率,就是在制定目标页面的时候携带相关备注信息一起进行脚本编写,为不同的项目提供数据支持,因此在表格中需要进行一些内容组合拼接的操作。

操作步骤
还是以抓取新闻内容举例。在编写爬虫脚本中设置的 Items.py 文件中定义了爬虫数据写入数据库的字段。
# 定义的字段内容,其中这些需要和表格一一对应
# 抓取的每一条数据都要对下面这些字段进行填充
title = scrapy.Field() # 文章标题
url = scrapy.Field() # 文章链接url
thumbImg = scrapy.Field() # 文章封面
publishTime = scrapy.Field() # 文章发布日期
content = scrapy.Field() # 文章正文
channel_name = scrapy.Field() # 文章所属频道
py_name = scrapy.Field() # 脚本名称
web_name = scrapy.Field() # 网站名称
其中上面 title、url、thumbImg 、publishTime 、content 这5个部分是我们通过爬虫脚本的方式从网站中获取的。但是channel_name 、py_name 、 web_name 这些是根据实际项目需要进行自定义的内容,也可以根据你的实际需要进行对应的调整,比如说增加个地区之类的字段内容。
1. 手动整理列表link

2. 制作数据列表
用于整理我们抓取的目标网页,将需要的字段信息进行整理填写表格中,为后面爬虫代码中字段编写提供基础数据的支持。
其中红色部分是根据习惯进行定义的内容,绿色的部分是根据网页的信息进行整理的。
3. 制作数据汇总
通过Excel数据透视进行页面的整理。

4.spider中的start_menu字符串处理
制作表格。
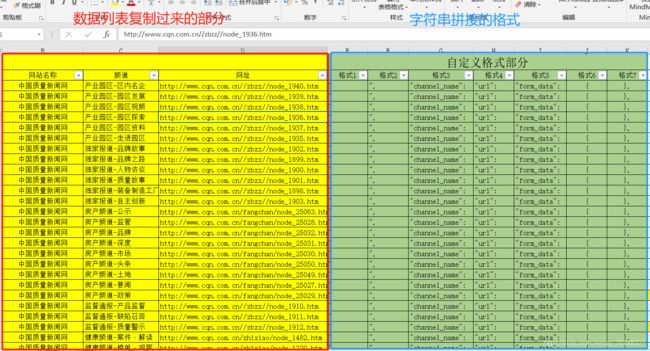
使用公式进行拼接成字符串,组合列是我们要复制到spider页面的内容。
l3 = E3&C3&F3
m3 = E3&D3&F3
n3 = J3&G3&L3&H3&M3&K3

5. 直接复制到spider中的字符串
# 这里有多少都复制过来
start_menu = [
{
"channel_name":"产业园区-区内名企","url":"http://www.cqn.com.cn//zbzz//node_1940.htm",},
{
"channel_name":"产业园区-园区发展","url":"http://www.cqn.com.cn//zbzz//node_1939.htm",},
{
"channel_name":"产业园区-园区视频","url":"http://www.cqn.com.cn//zbzz//node_1938.htm",},
{
"channel_name":"产业园区-园区探索","url":"http://www.cqn.com.cn//zbzz//node_1936.htm",},
{
"channel_name":"产业园区-园区资料","url":"http://www.cqn.com.cn//zbzz//node_1937.htm",},
....
]
6.抓取结果
- Navicat

- Compass

总结
- 抓取内容列表一目了然。
- 方便后期栏目变换批量修改。
- 标准化管理列表页。
- spider 的 url 列表页抓取有用的信息。
- spider文件中根据栏目 css 样式制作不同的 parse 模块。