numpy库数组基础详解(创建方法、数组转换、索引、切片、变形、拼接、分裂等)
前记~
IPython的%run命令
| 常用命令 | 说明 |
| %magic | 显示所有魔术命令 |
| %hist | IPython命令的输入历史 |
| %pdb | 异常发生后自动进入调试器 |
| %reset | 删除当前命令空间中的全部变量或名称 |
| %who | 显示IPython当前命令空间中已经定义的变量 |
| %time statement | 给出代码的执行时间,statement表示一段代码 |
| %timeit statement | 多次执行代码,计算综合平均执行时间 |
开始了!
理解一维、二维、多维、高维数据
在这里重点说下高维数据,其余维度与常见的概念一致
高维数据:高维数据仅利用最基本的二元关系展示数据间的复杂结构
如下面的键值对

数据维度的Python表示
一维数据:列表和集合类型
二维数据:列表类型
多维数据:列表类型
高维数据:字典类型或数据表示格式(JSON、XML、YAML格式等)
NumPy
- NumPy是一个开源的Python科学计算基础库,一个强大的N维数组对象ndarray
- 广播功能函数
- 整合C/C++/Fortran代码的工具
- 线性代数、傅里叶变换、随机数生成等功能
1、NumPy的引用
import numpy as np
2、N维数组对象:ndarray
- 数组对象可以去掉元素间运算所需的循环,使一维向量更像单个数据。
- 设置专门的数组对象,经过优化,可以提升这类用用的运算速度。
- ndarray是一个多维数组对象,由两部分构成:①实际数据 ②描述这些数据的元数据(数据维度、数据类型等)
- ndarray数组一般要求所有元素类型相同(同质),数组下标从0开始。

例如,计算![]() ,其中,A和B是一维数组
,其中,A和B是一维数组
def pySum(): import numpy as np
a = [0,1,2,3,4] def npSum():
b = [9,8,7,6,5] a = np.array([0,1,2,3,4])
c = [] b = np.array([9,8,7,6,5])
for i in range(len(a)): c = a**2 + b**3
c.append(a[i]**2 + b[i]**3) return c
return c print(npSum())
print(pySum())
运行结果:[729, 513, 347, 225, 141](1)轴(axis):保存数据的维度
秩(rank):轴的数量,即有多少个维度
(2)ndarray对象的属性
| 属性 | 说明 |
| .ndim | 秩,即轴的数量或维度的数量 |
| .shape | ndarray对象的尺度,对于矩阵,n行m列 |
| .size | ndarray对象元素的个数,相当于.shape中n*m的值 |
| .dtype | ndarray对象的元素类型 |
| .itemsize | ndarray对象中每个元素的大小,以字节为单位 |
import numpy as np
np.random.seed(0) #设置随机数种子,以确保每次程序执行时都可以生成同样的随机数组
x1 = np.random.randint(10,size=6) #一维数组
x2 = np.random.randint(10,size=(3,4)) #二维数组
x3 = np.random.randint(30,size=(3,4,5)) #三维数组
print("x3 ndim:",x3.ndim) #每个数组有ndim(数组的维度)、shape(数组每个维度的大小)和size(数组的总大小)属性:
x3 ndim: 3
print("x3 shape:",x3.shape)
x3 shape: (3, 4, 5)
print("x3 size:",x3.size)
x3 size: 60
其他属性包括每个数组元素字节大小的itemsize,以及表示数组总字节大小的属性nbytes,数组的数据类型dtype.一般认为,nbytes跟itemsize和size的乘积大小相等。(3)ndarray的元素类型
| 数据类型 | 说明 |
| bool | 布尔类型,True或False |
| intc | 与C语言中的int类型一致,一般是int32或int64 |
| intp | 用于索引的整数,与C语言中ssize_t一致,int32或int64 |
| int8 | 字节长度的整数,取值:[-128,127] |
| int16 | 16位长度的整数,取值:[-32768,32767] |
| int32 | 32位长度的整数,取值:[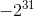 , , ] ] |
| int64 | 64位长度的整数,取值:[ ] ] |
| uint8 | 8位无符号整数,取值:[0,255] |
| uint16 | 16位无符号整数,取值:[0,65535] |
| uint32 | 32位无符号整数,取值:[0,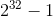 ] ] |
| uint64 | 64位无符号整数,取值:[0, ] ] |
| float16 | 16位半精度浮点数:1位符号位,5位指数,10位尾数 |
| float32 | 32位半精度浮点数:1位符号位,8位指数,23位尾数 |
| float64 | 64位半精度浮点数:1位符号位,11位指数,52位尾数 |
| complex64 | 复数类型,实部和虚部都是32位浮点数 |
| complex128 | 复数类型,实部和虚部都是64位浮点数 |
为什么ndarray需要这么多种数据类型呢?
对比:Python语法仅支持整数、浮点数和复数3种类型
- 科学计算设计数据较多,对存储和性能都有较高要求
- 对元素类型精细定义,有助于 NumPy合理使用存储空间并优化性能

3、ndarray数组的创建方法
(1)从Python中的列表、元组等类型创建ndarray数组
x = np.array(list/tuple)
x = np.array(list/tuple,dtype=np.float32)
当np.array()不指定dtype时,NumPy将根据数据情况关联一个dtype类型
import numpy as np
x = np.array([0,1,2,3]) 从列表类型创建
print(x)
结果:[0 1 2 3]
np.array([3.14,4,2,3]) 不同于Python列表,NumPy要求数组必须包含同一
结果:array([3.14,4.,2.,3.]) 类型数据。如果类型不匹配,NumPy将会向上转换
x = np.array((4,5,6,7)) 从元组类型创建
print(x)
结果:[4 5 6 7]
x = np.array([[1,2],[9,8],(1,2,3.4)]) 当数量列表与元组的“秩”不对应
print(x)
结果:[list([1, 2]) list([9, 8]) (1, 2, 3.4)]
x = np.array([[1,2],[9,8],(2.1,3.4)]) 从列表和元组混合类型创建
print(x)
结果:
[[1. 2. ]
[9. 8. ]
[2.1 3.4]](2)使用NumPy中函数创建ndarray数组
①如:arange,ones,zeros等(常用)
| 函数 | 说明 |
| np.arange(n) | 类似range()函数,返回ndarray类型,元素从0到n-1 |
| np.ones(shape) | 根据shape生成一个全1数组,shape是元组类型 |
| np.zeros(shape) | 根据shape生成一个数组,每个元素值都是val |
| np.full(shape.val) | 根据shape生成一个数组,每个元素都是val |
| np.eye(n) | 创建一个正方的n*n单位矩阵,对角线为1,其余为0 |
| np.ones_like(a) | 根据数组a的形状生成一个全1数组 |
| np.zeros_like(a) | 根据数组a的形状生成一个全0数组 |
| np.full_like(a,val) | 根据数组a的形状生成一个数组,每个元素值都是val |
np.arange(10)
Out[12]: array([0, 1, 2, 3, 4, 5, 6, 7, 8, 9])
np.random.normal(0,1,(3,3)) #创建一个3*3的、均值为0,方差为1的正态分布的随机数组
Out[4]:
array([[-0.68597138, 1.98417158, -0.29930765],
[ 0.06491759, -1.1621718 , 0.41525295],
[-0.59576117, 1.79453474, 1.31113793]])
np.random.random((3,3)) #创建一个3*3的、在0-1均匀分布的随机数组成的数组
Out[3]:
array([[0.75951983, 0.75397325, 0.90973687],
[0.9184009 , 0.6739447 , 0.64115502],
[0.1498414 , 0.4088041 , 0.73213028]])
np.random.randint(0,10,(3,3)) #创建一个3*3的、[0,10)区间的随机整型数组
Out[6]:
array([[0, 8, 3],
[4, 2, 2],
[4, 8, 8]])
np.ones((3,6))
Out[13]:
array([[1., 1., 1., 1., 1., 1.],
[1., 1., 1., 1., 1., 1.],
[1., 1., 1., 1., 1., 1.]])
np.zeros((3,6),dtype=np.int32) #如果希望明确设置数组的数据类型,可以用dtype关键字
Out[14]:
array([[0, 0, 0, 0, 0, 0],
[0, 0, 0, 0, 0, 0],
[0, 0, 0, 0, 0, 0]])
np.eye(5)
Out[15]:
array([[1., 0., 0., 0., 0.],
[0., 1., 0., 0., 0.],
[0., 0., 1., 0., 0.],
[0., 0., 0., 1., 0.],
[0., 0., 0., 0., 1.]])
#创建一个由3个整型数组成的未初始化的数组数组的值是内存空间中的任意值
np.empty(3)
Out[9]: array([0.75, 0.75, 0. ])
x = np.ones((2,3,4))
print(x)
结果:
[[[1. 1. 1. 1.]
[1. 1. 1. 1.]
[1. 1. 1. 1.]]
[[1. 1. 1. 1.]
[1. 1. 1. 1.]
[1. 1. 1. 1.]]]
x.shape
Out[19]: (2, 3, 4)
np.array([range(i,i+3)for i in [2,4,6]]) #嵌套列表构成的多维数组
array([[2,3,4], #内层的列表被当作二维数组的行
[4,5,6],
[6,7,8]])②使用NumPy中其他函数创建ndarray数组
| 函数 | 说明 |
| np.linspace() | 根据起止数据等间距地填充数据,形成数组 |
| np.concatenate() | 将两个或多个数组合并成一个新的数组 |
a = np.linspace(1,10,4) #(1,10,4) 起始为1,终止为10,元素个数为4
print(a)
[ 1. 4. 7. 10.] #使用linspace生成时,在不限定数据类型时,默认为浮点型
a
Out[23]: array([ 1., 4., 7., 10.])
pprint(a)
Pretty printing has been turned OFF
b = np.linspace(1,10,4,endpoint=False) #endpoint表示最后一个元素10是否是生成的4个元素中的一个
b #如果为False,在1和10之间会等间距地多生成一个值出来
Out[27]: array([1. , 3.25, 5.5 , 7.75])
c = np.concatenate((a,b))
c
Out[29]: array([ 1. , 4. , 7. , 10. , 1. , 3.25, 5.5 , 7.75])为什么numpy每次生成的数组中都要把元素默认为浮点型?
答:方便用于科学计算
③ndarray数组的变换
对于创建后的ndarray数组,可以对其进行维度变换和元素类型变换
维度转换
| 方法 | 说明 |
| .reshape(shape) | 不改变数组元素,返回一个shape形状的新数组,原数组不变,里面包含之前数组的一个备份 |
| .resize(shape) | 与.reshape()功能一致,但返回的数组就是之前的数组,即改变原数组形成一个新的数组 |
| .swapaxes(ax1,ax2) | 将数组n个维度中两个维度进行调换 |
| .flatten() | 对数组进行降维,返回折叠后的一维数组,原数组不变 |
a = np.ones((2,3,4),dtype=np.int32)
a.reshape((3,8))
Out[32]:
array([[1, 1, 1, 1, 1, 1, 1, 1],
[1, 1, 1, 1, 1, 1, 1, 1],
[1, 1, 1, 1, 1, 1, 1, 1]])
a
Out[33]:
array([[[1, 1, 1, 1],
[1, 1, 1, 1],
[1, 1, 1, 1]],
[[1, 1, 1, 1],
[1, 1, 1, 1],
[1, 1, 1, 1]]])
a.resize((3,8))
a
Out[35]:
array([[1, 1, 1, 1, 1, 1, 1, 1],
[1, 1, 1, 1, 1, 1, 1, 1],
[1, 1, 1, 1, 1, 1, 1, 1]])
a.flatten()
Out[36]:
array([1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1])
a
Out[37]:
array([[1, 1, 1, 1, 1, 1, 1, 1],
[1, 1, 1, 1, 1, 1, 1, 1],
[1, 1, 1, 1, 1, 1, 1, 1]])ndarray数组的类型变换
new_a = a.astype(new_type) astype()方法一定会创建新的数组(原始数据的一个拷贝),即使两个类型一致
a = np.ones((2,3,4),dtype=np.int)
a
Out[4]:
array([[[1, 1, 1, 1],
[1, 1, 1, 1],
[1, 1, 1, 1]],
[[1, 1, 1, 1],
[1, 1, 1, 1],
[1, 1, 1, 1]]])
b = a.astype(np.float)
b
Out[6]:
array([[[1., 1., 1., 1.],
[1., 1., 1., 1.],
[1., 1., 1., 1.]],
[[1., 1., 1., 1.],
[1., 1., 1., 1.],
[1., 1., 1., 1.]]])ndarray数组向列表的转换
ls = a.tolist()
a = np.ones((2,3,4),dtype=np.int)
a
Out[4]:
array([[[1, 1, 1, 1],
[1, 1, 1, 1],
[1, 1, 1, 1]],
[[1, 1, 1, 1],
[1, 1, 1, 1],
[1, 1, 1, 1]]])
b = a.astype(np.float)
b
Out[6]:
array([[[1., 1., 1., 1.],
[1., 1., 1., 1.],
[1., 1., 1., 1.]],
[[1., 1., 1., 1.],
[1., 1., 1., 1.],
[1., 1., 1., 1.]]])- 从字节流(raw bytes)中创建ndarray数组
- 从文件中读取特定格式,创建ndarray数组
4、数组的索引和切片
(1)一维数组的索引和切片:与Python的列表类似
x[start:stop:step]
a = np.array([9,8,7,6,5])
a[2]
Out[14]: 7
a[1:4:2] #(左闭右开)起始编号:终止编号:步长
Out[15]: array([8, 6])

(2)多维数组的索引
a = np.arange(24).reshape((2,3,4)) 生成包含两个3*4数组的元素
a
Out[17]:
array([[[ 0, 1, 2, 3],
[ 4, 5, 6, 7],
[ 8, 9, 10, 11]],
[[12, 13, 14, 15],
[16, 17, 18, 19],
[20, 21, 22, 23]]])
多维数组索引:
a[1,2,3] 从0开始索引,得到第二个元素的第三行第四列数据
Out[18]: 23
a[0,1,2]
Out[19]: 6
和Python列表不同,NumPy数组是固定类型的。这意味着当试图将一个浮点值插入一个整型数组时,浮点值会被截短成整型。并且这种截短是自动完成的,不会出现提示或警告。
x1[0] = 3.14159
x1
结果:array([3,0,3,3,7,9])
a[-1,-2,-3]
Out[20]: 17
(3)多维数组的切片
a[:,1,-3] #选取一个维度用:
Out[21]: array([ 5, 17])
a[:,1:3,:] #每个维度切片方法与一维数组相同
Out[22]:
array([[[ 4, 5, 6, 7],
[ 8, 9, 10, 11]],
[[16, 17, 18, 19],
[20, 21, 22, 23]]])
a[:,:,::2] #每个维度可以使用步长跳跃切片
Out[23]:
array([[[ 0, 2],
[ 4, 6],
[ 8, 10]],
[[12, 14],
[16, 18],
[20, 22]]])(4)布尔型索引
假设有一个用于存储数据的数组以及一个存储姓名的数组(含有重复项)。在这里,将使用numpy.random中的randn函数生成一些正态分布的随机数据:
import numpy as np
names = np.array(['Bob','Joe','Will','Bob','Will','Joe','Joe'])
data = np.random.randn(7,4)
names
Out[6]: array(['Bob', 'Joe', 'Will', 'Bob', 'Will', 'Joe', 'Joe'], dtype='
假设每个名字都对应data数组中的一行,而我们想要选出对应于名字“Bob”的所有行。跟算术运算一样,数组的比较运算(如==)也是矢量化的。因此,对names和字符串“Bob”的比较运算将会产生一个布尔型数组:
names =="Bob"
Out[13]: array([ True, False, False, True, False, False, False])这个布尔型数组可用于数组索引:
data[names=="Bob"]
Out[14]:
array([[ 1.84094113, 1.27865238, 1.9547406 , 0.12630075],
[ 2.06929063, -0.90186362, -0.3283161 , 0.51020551]])布尔型数组的长度必须跟被索引的轴长度一致。此外,还可以将布尔型数组跟切片、整数(或整数序列)混合使用:
data[names == 'Bob',2:]
Out[15]:
array([[ 1.9547406 , 0.12630075],
[-0.3283161 , 0.51020551]])
data[names == "Bob",3]
Out[16]: array([0.12630075, 0.51020551])要选择除“Bob”以外的其他值,既可以使用不等于符号(!=),也可以通过负号(-)对条件进行否定。选取这三个名字中的两个需要组合应用多个布尔条件,使用&(和)、|(或)之类的布尔算术运算符即可。
通过布尔型索引选取数组中的数据,将总是创建数据的副本,即使返回一模一样的数组也是如此。
python的and和or在布尔型数组中无效。
通过布尔型数组设置值是一种经常用到的手段,为了将data中的所有负值都设置为0,我们只需: data[data<0] = 0
通过一维布尔数组设置整行或列的值也很简单: data[name != 'Joe'] = 7
(5)花式索引
指的是利用整数数组进行索引。
arr = np.empty((8,4))
for i in range(8):
arr[i] = i
arr
Out[23]:
array([[0., 0., 0., 0.],
[1., 1., 1., 1.],
[2., 2., 2., 2.],
[3., 3., 3., 3.],
[4., 4., 4., 4.],
[5., 5., 5., 5.],
[6., 6., 6., 6.],
[7., 7., 7., 7.]])为了以特定顺序选取行子集,只需传入一个用于指定顺序的整数列表或ndarray即可:
arr[[4,3,0,6]] #选取第4、3、0、6行使用负数索引将会从末尾开始选取行: arr[[-1,-2]]
一次传入多个索引数组会有一点特别,它返回的是一个一维数组,其中的元素对应各个索引元组:
arr = np.arange(32).reshape((8,4))
array([[ 0, 1, 2, 3],
[ 4, 5, 6, 7],
[ 8, 9, 10, 11],
[12, 13, 14, 15],
[16, 17, 18, 19],
[20, 21, 22, 23],
[24, 25, 26, 27],
[28, 29, 30, 31]])
arr[[1,5,7,2],[0,3,1,2]] #选取的元素为 (1,0)、(5,3)、(7,1)、(2,2)
Out[4]: array([ 4, 23, 29, 10])选取矩阵的行列子集是矩阵区域的形式,如下:
arr[[1,5,7,3]][:,[3,1,0,2]]
Out[9]:
array([[ 7, 5, 4, 6],
[23, 21, 20, 22],
[31, 29, 28, 30],
[15, 13, 12, 14]])另外一个办法是使用np.ix_函数,它可以将两个一维整数数组转换为一个用于选取方形区域的索引器:
arr[np.ix_([1,5,7,2],[0,3,1,2])]
Out[10]:
array([[ 4, 7, 5, 6],
[20, 23, 21, 22],
[28, 31, 29, 30],
[ 8, 11, 9, 10]])花式索引跟切片不一样,它总是将数据复制到新数组中。
5、数组的转置和轴对换
转置(transpose)是重塑的一种特殊形式,它返回的是源数据的视图,不会进行任何复制操作。数组不仅有transpose方法,还有一个特殊的T属性:
arr =np.arange(15).reshape((3,5))
arr
Out[12]:
array([[ 0, 1, 2, 3, 4],
[ 5, 6, 7, 8, 9],
[10, 11, 12, 13, 14]])
arr.T
Out[13]:
array([[ 0, 5, 10],
[ 1, 6, 11],
[ 2, 7, 12],
[ 3, 8, 13],
[ 4, 9, 14]])在进行矩阵计算时,经常需要用到该操作,比如利用np.dot计算矩阵内积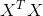 :
:
np.dot(arr.T,arr)
Out[15]:
array([[ 8.88537244, -7.45864697, -2.01102226],
[-7.45864697, 9.06679732, 1.88841719],
[-2.01102226, 1.88841719, 2.2001167 ]])对于高维数组,transpose需要得到一个由轴编号组成的元组才能对这些轴进行转置:

简单的转置可以使用.T,它其实就是进行轴对换而已,ndarray还有一个swapaxes方法,它需要接受一对轴编号:
arr.swapaxes(1,2)
Out[20]:
array([[[ 0, 4],
[ 1, 5],
[ 2, 6],
[ 3, 7]],
[[ 8, 12],
[ 9, 13],
[10, 14],
[11, 15]]])6、非副本视图的子数组
数组切片返回的是数组数据的视图,而不是数值数据的副本,这也是NumPy数组切片和Python列表切片的不同之处:
在Python列表中,切片是值的副本


7、数组的变形
(1)最灵活的实现方法是通过reshape()函数实现。例如:如果希望将数字1~9放入一个3*3的矩阵,可以采用如下方法:
grid = np.arange(1,10).reshape((3,3))
print(grid) 如果该方法可行,那麽原始数组的大小必须和变形后数组的大小一致。
[[1 2 3] 如果满足这个条件,reshape方法将会用到原始数组的一个非副本试图
[4 5 6] 但实际情况是,在非连续的数据缓存的情况下,返回非副本视图往往不可能
[7 8 9]](2)另外一种常见的变形模式是将一个一维数组转变为二维的行或列的矩阵。也可以通过reshape方法来实现,或者更简单地在一个切片操作中利用newaxis关键字:
x = np.array([1,2,3])
x.reshape((1,3)) #通过变形获得行向量
Out[13]: array([[1, 2, 3]])
x.shape
Out[14]: (3,)
x.ndim
Out[15]: 1
print(x.reshape((1,3)).ndim)
2
x[np.newaxis,:] #通过newaxis获得的行向量
Out[17]: array([[1, 2, 3]])
x.reshape((3,1)) #通过变形获得的列向量
Out[18]:
array([[1],
[2],
[3]])
x[:,np.newaxis] #通过newaxis获得的列向量
Out[19]:
array([[1],
[2],
[3]])8、数组与标量之间的运算
数组与标量的之间的运算作用于数组的每一个元素
实例:计算a与元素平均值的商
a = np.arange(24).reshape((2,3,4))
a
Out[17]:
array([[[ 0, 1, 2, 3],
[ 4, 5, 6, 7],
[ 8, 9, 10, 11]],
[[12, 13, 14, 15],
[16, 17, 18, 19],
[20, 21, 22, 23]]])
a.mean()
Out[24]: 11.5
a = a/a.mean()
a
Out[26]:
array([[[0. , 0.08695652, 0.17391304, 0.26086957],
[0.34782609, 0.43478261, 0.52173913, 0.60869565],
[0.69565217, 0.7826087 , 0.86956522, 0.95652174]],
[[1.04347826, 1.13043478, 1.2173913 , 1.30434783],
[1.39130435, 1.47826087, 1.56521739, 1.65217391],
[1.73913043, 1.82608696, 1.91304348, 2. ]]])9、数组的拼接与分裂
(1)拼接
拼接或连接NumPy中的两个数组主要由np.concatenate、np.vstack、np.hstack实现。np.concatenate将数组元组或数组列表作为第一个参数,如下所示。

沿着固定维度处理数组时,使用np.vstack(垂直栈)和np.hstack(水平线)函数会更简洁。
(2)分裂
与拼接相反的过程就是分裂,分裂可以通过np.split、np.hsplit和np.vsplit函数来实现。可以向以上函数传递一个索引列表作为参数,索引列表记录的是分裂点位置:
x = [1,2,3,99,99,3,2,1]
x1,x2,x3 = np.split(x,[3,5])
print(x1,x2,x3)
[1 2 3] [99 99] [3 2 1]值得注意的是,N分裂点会得到N+1个子数组,相关的np.hsplit和np.vsplit的用法也类似:
grid = np.arange(16).reshape((4,4))
grid
Out[24]:
array([[ 0, 1, 2, 3],
[ 4, 5, 6, 7],
[ 8, 9, 10, 11],
[12, 13, 14, 15]])
upper,lower = np.vsplit(grid,[2])
print(upper)
[[0 1 2 3]
[4 5 6 7]]
print(lower)
[[ 8 9 10 11]
[12 13 14 15]]
left,right = np.hsplit(grid,[2])
print(left)
[[ 0 1]
[ 4 5]
[ 8 9]
[12 13]]
print(right)
[[ 2 3]
[ 6 7]
[10 11]
[14 15]]同样,np.dsplit将数组沿着第三个维度分裂。