spark架构、部署形式和运行机理(独立集群、YARN集群)
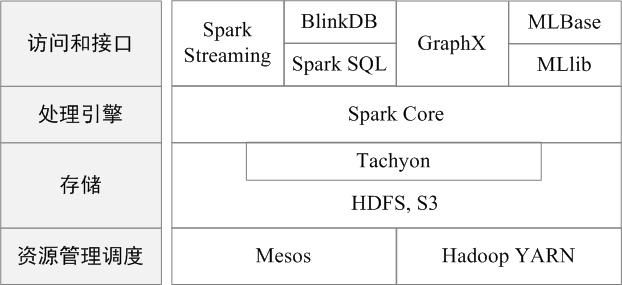
spark 生态架构
http://dblab.xmu.edu.cn/blog/spark/
Spark最初由美国加州伯克利大学(UCBerkeley)的AMP(Algorithms, Machines and People)实验室于2009年开发, 分布式大数据并行计算框架。
在实际应用中,大数据处理主要包括以下三个类型:
复杂的批量数据处理:时间跨度通常在数十分钟到数小时之间;
基于历史数据的交互式查询:时间跨度通常在数十秒到数分钟之间;
基于实时数据流的数据处理:时间跨度通常在数百毫秒到数秒之间。
伯克利数据分析软件栈BDAS(Berkeley Data Analytics Stack), “一个软件栈满足不同应用场景”的理念, 同时支持批处理、交互式查询和流数据处理。
- Spark Core:Spark Core包含Spark的基本功能,如内存计算、任务调度、部署模式、故障恢复、存储管理等。Spark建立在统一的抽象RDD之上,使其可以以基本一致的方式应对不同的大数据处理场景;通常所说的Apache Spark,就是指Spark Core;
- Spark SQL:Spark SQL允许开发人员直接处理RDD,同时也可查询Hive、HBase等外部数据源。Spark SQL的一个重要特点是其能够统一处理关系表和RDD,使得开发人员可以轻松地使用SQL命令进行查询,并进行更复杂的数据分析;
- Spark Streaming:Spark Streaming支持高吞吐量、可容错处理的实时流数据处理,其核心思路是将流式计算分解成一系列短小的批处理作业。Spark Streaming支持多种数据输入源,如Kafka、Flume和TCP套接字等;
- MLlib(机器学习):MLlib提供了常用机器学习算法的实现,包括聚类、分类、回归、协同过滤等,降低了机器学习的门槛,开发人员只要具备一定的理论知识就能进行机器学习的工作;
- GraphX(图计算):GraphX是Spark中用于图计算的API,可认为是Pregel在Spark上的重写及优化,Graphx性能良好,拥有丰富的功能和运算符,能在海量数据上自如地运行复杂的图算法。
Spark具有如下几个主要特点:
运行速度快:Spark使用先进的DAG(Directed Acyclic Graph,有向无环图)执行引擎,以支持循环数据流与内存计算,基于内存的执行速度可比Hadoop MapReduce快上百倍,基于磁盘的执行速度也能快十倍;
容易使用:scala 语言实现.Spark支持使用Scala、Java、Python和R语言进行编程,简洁的API设计有助于用户轻松构建并行程序,并且可以通过Spark Shell进行交互式编程;
通用性:Spark提供了完整而强大的技术栈,包括SQL查询、流式计算、机器学习和图算法组件,这些组件可以无缝整合在同一个应用中,足以应对复杂的计算;
运行模式多样:Spark可运行于独立的集群模式中,或者运行于Hadoop中,也可运行于Amazon EC2等云环境中,并且可以访问HDFS、Cassandra、HBase、Hive等多种数据源。
spark 部署形式
单机、Standalone独立集群、Yarn集群、Mesos集群和kubernets集群。主要介绍 Standalone独立集群、Yarn集群。
-
集群架构
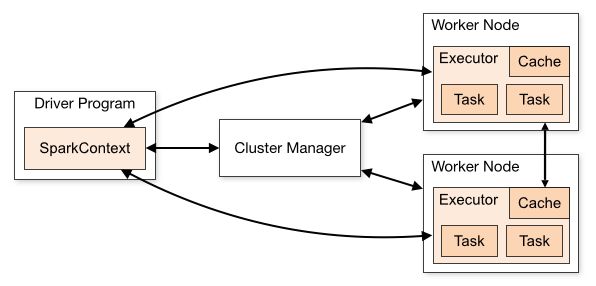
- Application:User program built on Spark. Consists of a driver program and executors on the cluster.
- Driver:
- Application的main函数并创建SparkContext,准备Spark应用程序的运行环境.
- 在Spark中有SparkContext负责与ClusterManager通信,进行资源申请、任务的分配和监控等,当Executor部分运行完毕后,Driver同时负责将SparkContext关闭,通常用SparkContext代表Driver。
- Executor: 执行器,是为某个Application运行在worker node上的一个进程, 运行任务、数据的内存和磁盘存储。
- cluster managers:
- 三种:standalone cluster manager, Mesos or YARN
- 在standalone模式中即为Master主节点,控制整个集群,监控worker。在YARN模式中为资源管理器ResourcesManager
-
几点注意:
- 不同的应用Application相互独立隔离,每个Executor跑在不同JVMs, 一个sparkcontext对应一个应用。
- Driver既可以运行在Master节点上中,也可以运行在本地Client端。
- 当用spark-shell交互式工具提交Spark的Job时,Driver在Master节点上运行;
- 当使用spark-submit工具提交Job或者在Eclips、IDEA等开发平台上使用”new SparkConf.setManager(“spark://master:7077”)”方式运行Spark任务时,Driver是运行在本地Client端上的
Spark Standalone独立集群
http://spark.apache.org/docs/latest/cluster-overview.html
http://spark.apache.org/docs/latest/spark-standalone.html
-
官网下载
-
部署启动
- 配置:{$SPARK_HOME}/conf/spark-env.sh, Options for the daemons used in the standalone deploy mode
SPARK_MASTER_HOST, to bind the master to a different IP address or hostname
SPARK_MASTER_PORT / SPARK_MASTER_WEBUI_PORT, to use non-default ports for the master
SPARK_MASTER_OPTS, to set config properties only for the master (e.g. “-Dx=y”)
SPARK_WORKER_CORES, to set the number of cores to use on this machine
SPARK_WORKER_MEMORY, to set how much total memory workers have to give executors (e.g. 1000m, 2g)
SPARK_WORKER_PORT / SPARK_WORKER_WEBUI_PORT, to use non-default ports for the worker
SPARK_WORKER_DIR, to set the working directory of worker processes
SPARK_WORKER_OPTS, to set config properties only for the worker (e.g. “-Dx=y”)
SPARK_DAEMON_MEMORY, to allocate to the master, worker and history server themselves (default: 1g).
SPARK_HISTORY_OPTS, to set config properties only for the history server (e.g. “-Dx=y”)
SPARK_SHUFFLE_OPTS, to set config properties only for the external shuffle service (e.g. “-Dx=y”)
SPARK_DAEMON_JAVA_OPTS, to set config properties for all daemons (e.g. “-Dx=y”)
SPARK_DAEMON_CLASSPATH, to set the classpath for all daemons
SPARK_PUBLIC_DNS, to set the public dns name of the master or workers - 启动:
{$SPARK_HOME}/sbin:
sbin/start-master.sh - Starts a master instance on the machine the script is executed on.
sbin/start-slaves.sh - Starts a slave instance on each machine specified in the conf/slaves file.
sbin/start-slave.sh - Starts a slave instance on the machine the script is executed on.
sbin/start-all.sh - Starts both a master and a number of slaves as described above.
sbin/stop-master.sh - Stops the master that was started via the sbin/start-master.sh script.
sbin/stop-slaves.sh - Stops all slave instances on the machines specified in the conf/slaves file.
sbin/stop-all.sh - Stops both the master and the slaves as described above.
- 配置:{$SPARK_HOME}/conf/spark-env.sh, Options for the daemons used in the standalone deploy mode
-
应用Jar包提交运行
- $ {$SPARK_HOME}/bin/spark-submit --class path.to.your.Class --master spark://SPARK_MASTER_IP:PORT[options] [app options]
-
基本运行流程
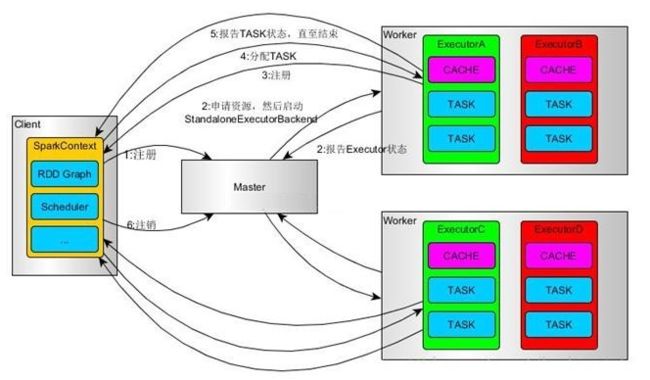
- SparkContext连接到Master,向Master注册并申请资源(CPU Core 和Memory)
- Master根据SparkContext的资源申请要求和Worker心跳周期内报告的信息决定在哪个Worker上分配资源,然后在该Worker上获取资源,然后启动StandaloneExecutorBackend;
- StandaloneExecutorBackend向SparkContext注册;
- SparkContext将Applicaiton代码发送给StandaloneExecutorBackend;并且SparkContext解析Applicaiton代码,构建DAG图,并提交给DAG Scheduler分解成Stage(当碰到Action操作时,就会催生Job;每个Job中含有1个或多个Stage,Stage一般在获取外部数据和shuffle之前产生),然后以Stage(或者称为TaskSet)提交给Task Scheduler,Task Scheduler负责将Task分配到相应的Worker,最后提交给StandaloneExecutorBackend执行;
- StandaloneExecutorBackend会建立Executor线程池,开始执行Task,并向SparkContext报告,直至Task完成;
- 所有Task完成后,SparkContext向Master注销,释放资源
Spark on YARN 集群
-
安装(需要准备YARN Hadoop 集群)
-
配置: {$SPARK_HOME}/conf/spark-env.sh, Options read in YARN client/cluster mode
- SPARK_CONF_DIR, Alternate conf dir. (Default: ${SPARK_HOME}/conf)
- HADOOP_CONF_DIR, to point Spark towards Hadoop configuration files
- YARN_CONF_DIR, to point Spark towards YARN configuration files when you use YARN
- SPARK_EXECUTOR_CORES, Number of cores for the executors (Default: 1).
- SPARK_EXECUTOR_MEMORY, Memory per Executor (e.g. 1000M, 2G) (Default: 1G)
- SPARK_DRIVER_MEMORY, Memory for Driver (e.g. 1000M, 2G) (Default: 1G)
-
应用Jar包提交运行
- $ {$SPARK_HOME}/bin/spark-submit --class path.to.your.Class --master yarn --deploy-mode cluster [options] [app options]
- 示例:
- $ ./bin/spark-submit --class org.apache.spark.examples.SparkPi
–master yarn
–deploy-mode cluster | client
–driver-memory 4g
–executor-memory 2g
–executor-cores 1
–queue thequeue
examples/jars/spark-examples*.jar
10
-
Yarn-client 运行过程:
Yarn-Client模式中,Driver在客户端本地运行,这种模式可以使得Spark Application和客户端进行交互,因为Driver在客户端,所以可以通过webUI访问Driver的状态,默认是http://hadoop1:4040访问,而YARN通过http:// hadoop1:8088访问
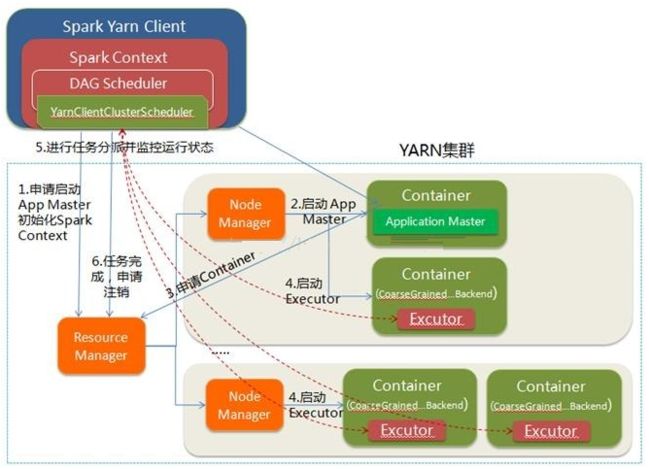
- Spark Yarn Client向YARN的ResourceManager申请启动Application Master。同时在SparkContent初始化中将创建DAGScheduler和TASKScheduler等,由于我们选择的是Yarn-Client模式,程序会选择YarnClientClusterScheduler和YarnClientSchedulerBackend
- ResourceManager收到请求后,在集群中选择一个NodeManager,为该应用程序分配第一个Container,要求它在这个Container中启动应用程序的ApplicationMaster,与YARN-Cluster区别的是在该ApplicationMaster不运行SparkContext,只与SparkContext进行联系进行资源的分派
- Client中的SparkContext初始化完毕后,与ApplicationMaster建立通讯,向ResourceManager注册,根据任务信息向ResourceManager申请资源(Container)
- 一旦ApplicationMaster申请到资源(也就是Container)后,便与对应的NodeManager通信,要求它在获得的Container中启动CoarseGrainedExecutorBackend,CoarseGrainedExecutorBackend启动后会向Client中的SparkContext注册并申请Task
- client中的SparkContext分配Task给CoarseGrainedExecutorBackend执行,CoarseGrainedExecutorBackend运行Task并向Driver汇报运行的状态和进度,以让Client随时掌握各个任务的运行状态,从而可以在任务失败时重新启动任务
- 应用程序运行完成后,Client的SparkContext向ResourceManager申请注销并关闭自己
- Yarn-cluster 运行流程:
在YARN-Cluster模式中,当用户向YARN中提交一个应用程序后,YARN将分两个阶段运行该应用程序:- 第一个阶段是把Spark的Driver作为一个ApplicationMaster在YARN集群中先启动;
- 第二个阶段是由ApplicationMaster创建应用程序,然后为它向ResourceManager申请资源,并启动Executor来运行Task,同时监控它的整个运行过程,直到运行完成
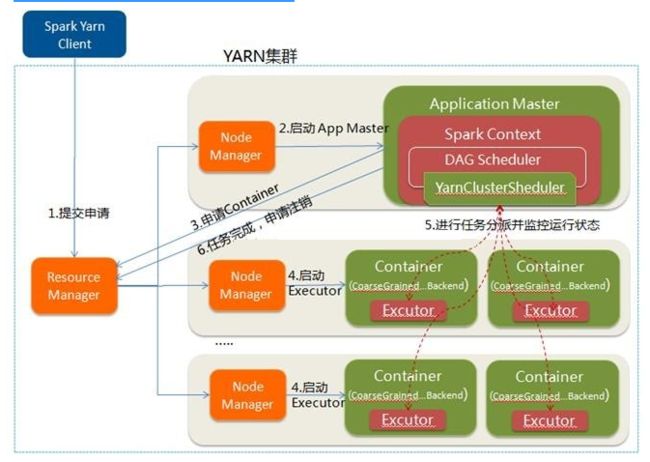
1. Spark Yarn Client向YARN中提交应用程序,包括ApplicationMaster程序、启动ApplicationMaster的命令、需要在Executor中运行的程序等
2. ResourceManager收到请求后,在集群中选择一个NodeManager,为该应用程序分配第一个Container,要求它在这个Container中启动应用程序的ApplicationMaster,其中ApplicationMaster进行SparkContext等的初始化
3. ApplicationMaster向ResourceManager注册,这样用户可以直接通过ResourceManage查看应用程序的运行状态,然后它将采用轮询的方式通过RPC协议为各个任务申请资源,并监控它们的运行状态直到运行结束
4. 一旦ApplicationMaster申请到资源(也就是Container)后,便与对应的NodeManager通信,要求它在获得的Container中启动CoarseGrainedExecutorBackend,CoarseGrainedExecutorBackend启动后会向ApplicationMaster中的SparkContext注册并申请Task。这一点和Standalone模式一样,只不过SparkContext在Spark Application中初始化时,使用CoarseGrainedSchedulerBackend配合YarnClusterScheduler进行任务的调度,其中YarnClusterScheduler只是对TaskSchedulerImpl的一个简单包装,增加了对Executor的等待逻辑等
5. ApplicationMaster中的SparkContext分配Task给CoarseGrainedExecutorBackend执行,CoarseGrainedExecutorBackend运行Task并向ApplicationMaster汇报运行的状态和进度,以让ApplicationMaster随时掌握各个任务的运行状态,从而可以在任务失败时重新启动任务
6. 应用程序运行完成后,ApplicationMaster向ResourceManager申请注销并关闭自己
- Spark Client 和 Spark Cluster的区别:
- 理解YARN-Client和YARN-Cluster深层次的区别之前先清楚一个概念:Application Master。在YARN中,每个Application实例都有一个ApplicationMaster进程,它是Application启动的第一个容器。它负责和ResourceManager打交道并请求资源,获取资源之后告诉NodeManager为其启动Container。从深层次的含义讲YARN-Cluster和YARN-Client模式的区别其实就是ApplicationMaster进程的区别
- YARN-Cluster模式下,Driver运行在AM(Application Master)中,它负责向YARN申请资源,并监督作业的运行状况。当用户提交了作业之后,就可以关掉Client,作业会继续在YARN上运行,因而YARN-Cluster模式不适合运行交互类型的作业.
- YARN-Client模式下,Application Master仅仅向YARN请求Executor,Client会和请求的Container通信来调度他们工作,也就是说Client不能离开
运行提交
spark-shell Test
-
spark-shell --master local[*], local模式,local[N] to run locally with N threads。
-
spark-shell --master spark://host:7077, 可远程访问standalone模式的集群,在本地机4040或远程spark集群的8080 webUI 可查看运行状态。开启一个spark-shell为一个名为 Spark shell 的应用。
在交互式的命令行状态下,每遇到一个Action算子,则化为一个实质计算的Job。一个worker节点,可根据DAG需要启动一个或多个Executor命令行状态下,每遇到一个Action算子,则化为一个实质计算的Job。一个worker节点,可根据DAG需要启动一个或多个Executor, 每个Exector的执行若干个Task,Task 的数量和 Action 操作对应的RDD的分区数量一致. 每个Excutor 有自己的stdout, stderr.
Remot Debug spark program
-
IDEA Remote setting
- Debugger mode: Attach to remote JVM
- Transport: Socket
- HOST/PORT: RemoteIP/Default 5055
- Command line arguments for remote JVM: -agentlib:jdwp=transport=dt_socket,server=y,suspend=n,address=5055
-
Standalone cluster
spark-submit --class Ex1_SimpleRDD --master spark://host:7077 --driver-java-options “-agentlib:jdwp=transport=dt_socket,server=y,suspend=y,address=5055” /data/jars/learningspark*.jar -
YARN cluster
spark-submit --class Ex1_SimpleRDD --master yarn --deploy-mode client --driver-java-options “-agentlib:jdwp=transport=dt_socket,server=y,suspend=y,address=5055” /data/jars/learningspark*.jar
spark-submit --class Ex1_SimpleRDD --master yarn --deploy-mode cluster --driver-java-options “-agentlib:jdwp=transport=dt_socket,server=y,suspend=y,address=5055” /data/jars/learningspark*.jar
Spark 调优
https://www.cnblogs.com/xjh713/p/7309426.html
https://www.jianshu.com/p/3716ade93b02
https://blog.csdn.net/evankaka/article/details/61934540
spark 参数配置
- num-executors
参数说明:该参数用于设置Spark作业总共要用多少个Executor进程来执行。Driver在向YARN集群管理器申请资源时,YARN集群管理器会尽可能按照你的设置来在集群的各个工作节点上,启动相应数量的Executor进程。这个参数非常之重要,如果不设置的话,默认只会给你启动少量的Executor进程,此时你的Spark作业的运行速度是非常慢的。
参数调优建议:每个Spark作业的运行一般设置50~100个左右的Executor进程比较合适,设置太少或太多的Executor进程都不好。设置的太少,无法充分利用集群资源;设置的太多的话,大部分队列可能无法给予充分的资源。
注意:新版spark, 设置spark.dynamicAllocation.enabled=true的优先级高于此设置. spark.dynamicAllocation.executorIdleTimeout=60s 当executors空闲达到设定时间后会被移除(缓存了数据的executor不会被移除)。
-
executor-memory
参数说明:该参数用于设置每个Executor进程的内存。Executor内存的大小,很多时候直接决定了Spark作业的性能,而且跟常见的JVM OOM异常,也有直接的关联。
参数调优建议:每个Executor进程的内存设置4G ~ 8G较为合适。但是这只是一个参考值,具体的设置还是得根据不同部门的资源队列来定。可以看看自己团队的资源队列的最大内存限制是多少,num-executors乘以executor-memory,就代表了你的Spark作业申请到的总内存量(也就是所有Executor进程的内存总和),这个量是不能超过队列的最大内存量的。此外,如果你是跟团队里其他人共享这个资源队列,那么申请的总内存量最好不要超过资源队列最大总内存的1/3~1/2,避免你自己的Spark作业占用了队列所有的资源,导致别的同学的作业无法运行。 -
executor-cores
参数说明:该参数用于设置每个Executor进程的CPU core数量。这个参数决定了每个Executor进程并行执行task线程的能力。因为每个CPU core同一时间只能执行一个task线程,因此每个Executor进程的CPU core数量越多,越能够快速地执行完分配给自己的所有task线程。
参数调优建议:Executor的CPU core数量设置为2~4个较为合适。同样得根据不同部门的资源队列来定,可以看看自己的资源队列的最大CPU core限制是多少,再依据设置的Executor数量,来决定每个Executor进程可以分配到几个CPU core。同样建议,如果是跟他人共享这个队列,那么num-executors * executor-cores不要超过队列总CPU core的1/3~1/2左右比较合适,也是避免影响其他同学的作业运行。
Spark 内存
https://www.cnblogs.com/gaoxing/p/5041806.html
https://www.cnblogs.com/missie/p/4370135.html
https://www.cnblogs.com/yesecangqiong/p/6274427.html
- YARN 资源抽象
- yarn.nodemanager.resource.memory-mb
- NM 节点上YARN可使用的物理内存总量,默认是8192(MB)
- yarn.scheduler.minimum-allocation-mb yarn.scheduler.maximum-allocation-mb
- RM 单个任务可申请的最少物理内存量,默认是1024(MB)
- RM 单个任务可申请的最多物理内存量,默认是8192(MB)
- mapreduce.map.memory.mb mapreduce.reduce.memory.mb
-
- 指定map和reduce task的内存大小,该值应该在RM的最大最小container之间。
- 一般地,reduce设置为map的两倍。
- mapreduce.map.java.opts mapreduce.reduce.java.opts
- 这两个参数是伪需要运行JVM程序(java,scala等)准备,通过这两个参数可以向JVM中传递参数,与内存有关的是-Xmx, -Xms等选项,数值的大小应该要再AM中的map.mb和reduce.mb之间。
- yarn.nodemanager.resource.memory-mb
- Spark Driver 和 Executor JVM进程的内存分布
- 90% Safe ( 90%*20% Shuffle, 90%*60% Storage(90%*60% *20% Unroll 处理反序列化对象) )
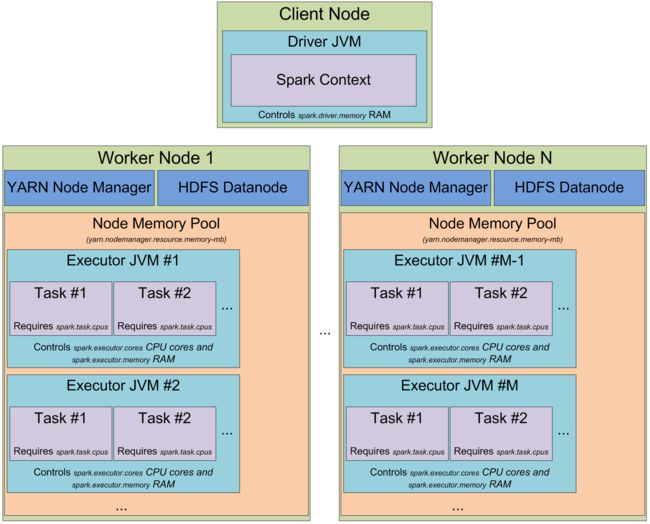
- 90% Safe ( 90%*20% Shuffle, 90%*60% Storage(90%*60% *20% Unroll 处理反序列化对象) )
Spark 数据本地化级别
https://blog.csdn.net/weixin_38750084/article/details/83187264
- PROCESS_LOACL > NODE_LOACL > NO_PREF > RACK_LOACL > ANY
Spark中任务调度时,TaskScheduler在分发之前需要依据数据的位置来分发,最好将task分发到数据所在的节点上,如果TaskScheduler分发的task在默认3s依然无法执行的话,TaskScheduler会重新发送这个task到相同的Executor中去执行,会重试5次,如果依然无法执行,那么TaskScheduler会降低一级数据本地化的级别再次发送task。
<完>