Flink - 尚硅谷- 大数据高级 Flink 技术精讲 - 1
Flink - 尚硅谷- 大数据高级 Flink 技术精讲
- Flink - 尚硅谷- 大数据高级 Flink 技术精讲
- 一、Flink 简介
- 二、Quick Start
- 2.1 环境
- 2.1 Flink 安装包
- 2.2 nc
- 2.3 pom 配置
- 2.2 批处理
- 2.3 流处理
- 2.1 环境
- 三、Flink 部署
- 3.1 Standalone 模式
- 3.2 Yarn 模式
- 3.2.1 Flink on Yarn
- 3.2.2 Session Cluster
- 3.2.3 Per Job Cluster
- 3.3 Kubernets 部署
- 四、Flink 运行时架构
- 4.1 Flink 运行时的组件
- 4.2 任务提交流程
- 4.3 任务调度原理
- 4.3.1 TaskManager 和 Slots
- 4.3.2 程序与数据流(DataFlow)
- 4.3.3 执行图(ExecutionGraph)
- 4.3.4 并行度(Parallelism)
- 4.3.5 任务链(Operator Chains)
- 五、Flink 流处理 API
- 5.1 Environment
- 5.1.1 getExecutionEnvironment
- 5.1.2 createLocalEnviroment
- 5.1.3 createRemoteEnvironment
- 5.2 Source
- 5.2.1 从集合读取数据
- 5.2.2 从文件读取数据
- 5.2.3 以 socket 作为来源
- 5.2.4 以 Kafka 消息队列的数据作为来源
- 5.2.5 自定义 Source
- 5.2.6 Full Demo Code
- 5.3 Transform
- 5.3.1 map
- 5.3.2 flatMap
- 5.3.3 Filter
- 5.3.4 KeyBy
- 5.3.5 滚动聚合算子
- 5.3.6 Reduce
- 5.3.7 Split 和 Select & SideOutput
- 5.3.8 Connect 和 CoMap
- 5.3.9 Union
- 5.3.10 Full Code
- 5.4 支持的数据类型
- 5.4.1 基本数据类型
- 5.4.2 Java 和 Scala 元组(Tuples)
- 5.4.3 Scala 样例类(case classes)
- 5.4.4 Java 简单对象(POJOs)
- 5.4.5 其它
- 5.5 实现 UDF 函数
- 5.5.1 函数类
- 5.5.2 匿名函数
- 5.5.3 富函数
- 5.5.4 总结
- 5.6 Sink
- 5.6.1 Kafka
- 5.6.2 Redis
- 5.6.3 Elasticsearch
- 5.6.4 JDBC 自定义 sink
- 5.1 Environment
- 六、Flink Window
- 6.1 Window
- 6.1.1 Window 概述
- 6.1.2 Window 类型
- 6.2 Flink Window API
- 6.2.1 Flink Window API 总览
- 6.2.2 Flink Window Assigner
- 6.2.2.1 窗口分配器
- 6.2.2.2 timeWindow & countWindow
- 6.2.3 Flink Window Function
- 6.2.3.1 Incremental aggregation functions
- 6.2.3.2 Full window functions
- 6.3 总结
- 6.1 Window
- 七、Flink 时间语义与 Watermark
- 7.1 Flink 中的时间语义
- 7.2 设置 Event Time
- 7.3 水位线 - Watermark
- 7.3.1 基本概念
- 7.3.2 WaterMark 传递
- 7.3.3 WaterMark 注意点
- 7.3.4 Watermark Demo
- 八、ProcessFunction API(底层 API)
- 8.1 KeyedProcessFunction 和 定时器(Timers)
- 8.2 侧输出流(SlideOutput)
- 8.3 CoProcessFunction
- 九、状态编程和容错机制
- 9.1 Flink 中的状态
- 9.1.1 算子状态(Operator State)
- 9.1.2 键控状态(Keyed State)
- 9.1.3 状态后端(State Backends)
- 9.1.4 Demo
- 9.1.5 总结
- 9.2 状态一致性
- 9.2.1 概念
- 9.2.2 一致性检查点(checkpoint)
- 9.2.3 从检查点恢复状态
- 9.2.4 Flink 检查点算法
- 9.2.5 保存点(save points)
- 9.2.6 配置
- 9.2.7 总结
- 9.3 状态一致性分类
- 9.3.1 端到端(end to end)一致性
- 9.3.2 端到端的 exactly-once 保证
- 9.3.3 Flink + Kafka 如何实现端到端的 exactly-once
- 9.1 Flink 中的状态
- 十、Table API & SQL
- 10.1 定义
- 10.2 pom
- 10.3 两种 planner(old & blink) 的区别
- 十一、Table API & SQL 调用
- 11.1 基本程序结构
- 11.2 创建表环境
- 11.3 在 Catalog 中注册表
- 11.3.1 表的概念
- 11.3.2 临时表 - TemporaryTable 和 永久表 - PermanentTable
- 11.3.3 创建表
- 11.3.4 连接到外部系统
- 11.4 表的查询
- 11.4.1 Table API
- 11.4.2 SQL
- 11.4.3 Demo
- 11.5 Table、View、流 的转换
- 11.5.1 Scala 隐式转换
- 11.5.2 DataSet/DataStream to View
- 11.5.3 DataStream/DataSet to Table
- 11.5.4 Table to DataStream
- 11.5.5 Table to DataSet
- 11.5.6 数据类型与 Schema 的映射
- 11.6 表的输出
- 11.6.1 更新模式
- 11.6.2 输出到文件
- 11.6.3 输出到 Kafka
- 11.6.4 输出到 ES
- 11.6.5 输出到 Mysql
- 11.7 Explaining
- 十二、Table API & SQL 流式概念
- 12.1 动态表
- 12.1.1 DataStream 上的关系查询
- 12.1.2 动态表 & 连续查询(Continuous Query)
- 12.1.3 更新和追加查询
- 12.1.4 查询限制
- 12.1.5 表到流的转换
- 12.2 时间属性
- 12.2.1 处理时间
- 12.2.2 事件时间
- 12.1 动态表
- 十三、Table API
- 十四、Table API 自定义函数
- 附.项目实战
- 1. 项目整体介绍
- 1.1 电商用户行为分析
- 1.2 项目模块设计
- 2. 实时热门商品统计
- 3. 实时流量统计
- 3.1 PVTopN - 热点网站
- 3.2 PV - 网站总浏览量
- 3.3 UV - 网站独立访客数
- 4. 市场营销商业指标统计分析
- 4.1 APP 市场推广统计
- 4.2 页面广告分析
- 5. 恶意登陆监控
- 5.1 Demo
- 5.2 CEP
- 6. 订单支付实时监控
- 6.1 付款超时 - Cep Code
- 6.2 付款超时 - Without Cep
- 6.3 实时对账 - connect
- 6.4 实时对账 - intervalJoin
- 7. 电商常见指标汇总
- 1. 项目整体介绍
- 附.Q&A
注:次文档参考 【尚硅谷】大数据高级 flink技术精讲(2020年6月) 编写。
1.由于视频中并未涉及到具体搭建流程,Flink 环境搭建部分并未编写。
2.视频教程 Flink 版本为 1.10.0,此文档根据 Flink v1.11.1 进行部分修改。
3.文档中大部分程序在 Windows 端运行会有超时异常,需要打包后在 Linux 端运行。
4.程序运行需要的部分 Jar 包,请很具情况去掉 pom 中的 “scope” 标签的再进行打包,才能在集群上运行。
5.原始文档在 Markdown 中编写,此处目录无法直接跳转。且因字数限制,分多篇发布
此文档仅用作个人学习,请勿用于商业获利。
一、Flink 简介
概念
Flink 是一个 框架 和 分布式处理引擎,用于对 无界和有界数据流 进行 状态 计算。
为什么选择 Flink
- 传统的数据架构是基于有限数据集的
- 流数据更真实地反映我们的生活方式
- 相较于 Spark 的微批处理,Flink 做到了真正的流式处理,且 Flink 包含了批处理和流处理两种处理引擎
- Flink 的目标
- 低延迟 : 来一条数据处理一条
- 高吞吐 : 分布式的架构处理高吞吐的数据量
- 结果的准确性和良好的容错性 : 因为网络延迟造成的乱序问题不会影响结果的准确性
哪些行业需要处理流数据
- 电商和市场营销
- 数据报表、广告投放、业务流程需要
- 物联网(IOT)
- 传感器实时数据采集和显示、实时报警、交通运输业
- 电信业
- 基站流量调配
- 银行和金融业
- 实时结算和通知推送,实时检测异常行为
Flink 主要特点
- 事件驱动(Event-driven):来一条数据处理一条
- 基于流的世界观:在 Flink 中,一切都是流,离线数据是有界的流实时数据是没有界限的流
分层 API
- 越顶层越抽象,表达含义越简明,使用越发辫
- 越底层越具体,表达能力越丰富,使用越灵活
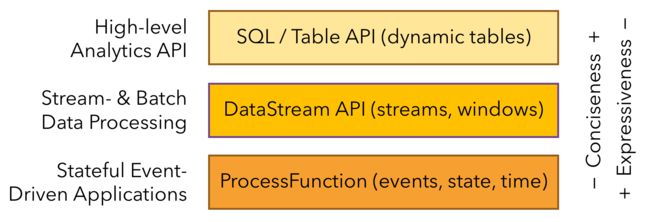
Flink 其他特点
- 支持事件事件(event-time)和处理时间(processing-time)语义
- 精确一次(exactly-once)的状态一致性保证
- 低延迟,每秒处理百万个事件,毫秒级延迟
- 与众多常用存储系统的连接
- 高可用,动态扩展,实现 7*23 小时全天候运行
Flink VS SparkStreaming
- 流(stream) 和 微批(micro–batching)
- 数据模型
- spark 采用 RDD 模型,spark streaming 和 DStream 实际上也就是一组组小批数据 RDD 的集合
- Flink 基本数据模型是数据流,以及事件(Event)序列
- 运行时架构
- spark 是批计算,将 DAG 划分为不同的 stage,一个完成后才可以计算下一个
- flink 是标准的流执行模型,一个事件在一个节点处理完后可以直接发往下一个节点进行处理
二、Quick Start
2.1 环境
2.1 Flink 安装包
# 创建用户
userdel -r flink && useradd flink && echo flink | passwd --stdin flink
# 下载
wget https://archive.apache.org/dist/flink/flink-1.11.1/flink-1.11.1-bin-scala_2.11.tgz
或
wget https://mirror.bit.edu.cn/apache/flink/flink-1.11.1/flink-1.11.1-bin-scala_2.11.tgz
# 解压并启动
tar -zxvf flink-1.11.1-bin-scala_2.11.tgz
/home/flink/flink-1.11.1/bin/start-cluster.sh
# UI
http://test01:8081/#/overview
2.2 nc
sudo yum -y install nc
# 使用 linux 的 nc 命令来向 socket 当中发送一些单词
nc -lk 7777
2.3 pom 配置
org.apache.flink
flink-scala_2.11
1.11.1
provided
org.apache.flink
flink-streaming-scala_2.11
1.11.1
provided
org.apache.flink
flink-clients_2.11
1.11.1
provided
dev
true
dev
prod
prod
src/main/resources/env/config-${env}.properties
src/main/resources
*.properties
*.txt
*.xml
*.yaml
net.alchim31.maven
scala-maven-plugin
3.4.6
-target:jvm-1.8
compile
org.apache.maven.plugins
maven-compiler-plugin
3.1
1.8
1.8
1.8
org.apache.maven.plugins
maven-assembly-plugin
3.0.0
jar-with-dependencies
make-assembly
package
single
2.2 批处理
Code
package com.mso.flink.dataset
import org.apache.flink.api.java.utils.ParameterTool
import org.apache.flink.api.scala._
object DataSetWordCount {
def main(args: Array[String]): Unit = {
// 创建一个批处理执行环境
val environment: ExecutionEnvironment = ExecutionEnvironment.getExecutionEnvironment
// 从文件中读取数据
// val resource: URL = getClass.getResource("/word.txt")
// val inputDataSet: DataSet[String] = environment.readTextFile(resource.getPath)
val params: ParameterTool = ParameterTool.fromArgs(args)
val inputDataSet: DataSet[String] = environment.readTextFile(params.get("input-path"))
// 基于 DataSet 做转换,首先按空格拆分,然后按照 word 作为 key 做 groupBy 分组聚合
val resultDataSet: AggregateDataSet[(String, Int)] = inputDataSet
.flatMap((_: String).split(" ")) // 分词得到 word 构成的数据集
.map(((_: String), 1)) // 转换成一个二元组 (word, count)
.groupBy(0) // 以二元组中第一个元素作为 key 分组
.sum(1) // 聚合二元组中第二个元素的值
resultDataSet.printOnTaskManager("DataSetWordCount")
environment.execute("DataSetWordCount")
// ~/flink-1.11.1/bin/flink run -p 1 -c com.mso.flink.dataset.DataSetWordCount FlinkPractice-1.0-SNAPSHOT-jar-with-dependencies.jar --input-path /home/flink/word.txt
}
}
Run
~/flink-1.11.1/bin/flink run -p 1 -c com.mso.flink.dataset.DataSetWordCount FlinkPractice-1.0-SNAPSHOT-jar-with-dependencies.jar --input-path /home/flink/word.txt
2.3 流处理
Code
package com.mso.flink.stream
import org.apache.flink.streaming.api.scala._
object StreamWordCount {
def main(args: Array[String]): Unit = {
// 创建流处理执行环境
val environment: StreamExecutionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment
// 接收 socket 文本流
val inputSocketDataStream: DataStream[String] = environment.socketTextStream("test01", 7777)
// 定义转换操作, word count
val resultDataStream: DataStream[(String, Int)] = inputSocketDataStream
.flatMap(_.split(" ")) // 分词得到 word 构成的数据集
.filter(_.nonEmpty) // 过滤空集
.map((_, 1)) // 转换成一个二元组 (word, count)
.keyBy(0) // 以二元组中第一个元素作为 key 分组
.sum(1) // 聚合二元组中第二个元素的值
// 打印输出
resultDataStream.print()
// 提交执行
environment.execute()
}
}
Run
~/flink-1.11.1/bin/flink run -c com.mso.flink.stream.StreamWordCount -p 1 FlinkPractice-1.0-SNAPSHOT-jar-with-dependencies.jar
Result
tail -f flink-flink-taskexecutor-0-test01.out
Stop
~/flink-1.11.1/bin/flink list
~/flink-1.11.1/bin/flink cancel jobID
三、Flink 部署
3.1 Standalone 模式
规划
| Node | JobManager | TaskManager | JPS |
|---|---|---|---|
| test01 | Y | Y | StandaloneSessionClusterEntrypoint、TaskManagerRunner |
| test02 | N | Y | TaskManagerRunner |
| test03 | N | Y | TaskManagerRunner |
安装
# 修改 flink-conf.yaml
vim ~/flink-1.11.1/conf/flink-conf.yaml
#jobmanager.rpc.address: localhost
jobmanager.rpc.address: test01
# 修改 workers
vim ~/flink-1.11.1/conf/workers
test01
test02
test03
# 免密
ssh-keygen
ssh-copy-id test02
ssh-copy-id test03
# 分发安装包
scp -r ~/flink-1.11.1/ flink@test02:
scp -r ~/flink-1.11.1/ flink@test03:
# 启动 Flink 集群
~/flink-1.11.1/bin/start-cluster.sh
# WebUI 界面访问
http://test01:8081/#/overview
提交任务
3.2 Yarn 模式
3.2.1 Flink on Yarn
Session-cluster 模式
先启动集群,然后再提交作业。首先向 yarn 申请一块空间,之后资源永远保持不变,如果资源满了,下一个作业就无法提交。
所有作业共享 Dispatcher 和 ResourceManager。
适用于规模小且执行时间短的作业。
Per-Job-Cluster
每次提交 Job 都会对应一个 Flink 集群,每提交一个作业会根据自身的情况,都会单独向 yarn 申请资源,直到作业执行完成。
3.2.2 Session Cluster
# 启动
~/flink-1.11.1/bin/yarn-session.sh -n 2 -s 2 -jm 1024 -tm 1024 -nm test -d
-n(--container) : TaskManager 的数量
-s(--slots) : 每个 TaskManager 的 slot 数量,默认一个 slot 一个 core,默认每个 taskmanager 的 slot 的个数为 1,有时可以多一些
-jm : JobManager 的内存(单位 MB)
-tm : 每个 TaskManager 的内存(单位 MB)
-nm : yarn 的 appName(现在 yarn 的 ui 上的名字)
-d : 后台执行
# 取消 yarn session
yarn application --kill applicationId
# 提交任务
~/flink-1.11.1/bin/flink run -m yarn-cluster -c com.mso.flink.stream.StreamWordCount -p 1 FlinkPractice-1.0-SNAPSHOT-jar-with-dependencies.jar
3.2.3 Per Job Cluster
# 提交任务
~/flink-1.11.1/bin/flink run -c com.mso.flink.stream.StreamWordCount -p 1 FlinkPractice-1.0-SNAPSHOT-jar-with-dependencies.jar
3.3 Kubernets 部署
搭建 Kubernetes 集群
略
配置各组件的 yaml 文件
在 k8s 上构建 Flink Session Cluster,需要将 Flink 集群的组件对应的 docker 镜像分别在 k8s 上启动。
包括 JobManager、TaskManager、JobManagerService 三个镜像服务。每个镜像服务都可以从中央镜像仓库中获取。
启动Flink Session Cluster
# 启动 jobmanager-service 服务
kubectl create -f jobmanager-service.yaml
# 启动 jobmanager-deployment 服务
kubectl create -f jobmanager-deployment.yaml
# 启动 taskmanager-deployment 服务
kubectl create -f taskmanager-deployment.yaml
访问 Flink 111 页面
http://(JobManagerHost:Port)/api/v1/namespaces/default/services/flink-jobmanager:ui/proxy
四、Flink 运行时架构
4.1 Flink 运行时的组件
- JobManager : 作业管理器
- TaskManager : 任务管理器
- ResourceManager : 资源管理器
- Dispacher : 分发器
JobManager
- 控制一个应用程序执行的主要进程,每个应用程序都会被一个不同的 JobManager 所控制执行
- JobManager 会先接收到要执行的应用程序,这个应用程序会包括:作业图(JobGraph)、逻辑数据流图(logical dataflow graph)和打包了所有的类库和其他资源的 JAR 包
- JobManager 会把 JobGraph 转换成一个物理层面的数据流图,这个图被叫做执行图(ExecutionGraph),包含了所有可以并发执行的任务
- JobManager 会向资源管理器(ResourceManager)请求执行任务必要的资源,也就是任务管理器(TaskManager)上的插槽(slot)。一旦它获取到了足够的资源,就会将执行图分发到真正运行在它们的 TaskManager 上。而在运行过程中,JobManager 会负责所有需要中央协调的操作,比如说检查点(checkpoint)协调
TaskManager
- Flink 中的工作进程。通常在 Flink 中会有多个 TaskManager 运行,每一个 TaskManager 都包含了一定数量的插槽(slots)。插槽的数量限制了 TaskManager 能够执行的任务数量
- 启动之后,TaskManager 会向资源管理器注册它的插槽;收到资源管理器的指令后,TaskManager 就会将一个或者多个插槽提供给 JobManager 调用。JobManager 就可以向插槽分配任务(tasks)来执行了
- 在执行过程中,一个 TaskManager 可以跟其它运行同一应用程序的 TaskManager 交换数据。
ResourceManager
- 主要负责管理任务管理器(TaskManager)的插槽(slot),TaskManger 插槽是 Flink 中定义的处理资源单元。
- Flink 为不同的环境和资源管理工具提供了不同的资源管理器,比如 Yarn、Mesos、K8s,以及 standalone 部署
- 当 JobManager 申请插槽资源时,ResourceManager 会将有空闲插槽的 TaskManager 分配给 JobManager。如果 ResourceManager 没有足够的插槽来满足 JobManager 的请求,它还可以向资源提供平台发起会话,以及提供启动 TaskManager 进程的容器。
Dispacher
- 可以跨作业运行,它为应用提交提供了 REST 接口。
- 当一个应用被提交执行时,分发器就会启动并将应用移交给一个 JobManager
- Dispatcher 也会启动一个 Web UI,用来方便地展示和监控作业执行的信息
- Dispatcher 在架构中可能并不是必需的,这取决于应用提交运行的方式
4.2 任务提交流程
任务提交流程
任务提交流程 On Yarn
4.3 任务调度原理
4.3.1 TaskManager 和 Slots
- 默认情况下,Flink 允许子任务共享 slot,即使他们时不同任务的子任务。这样可以提高资源的利用率,且一个 slot 可以保存作业的整个管道
- Task slot 是静态的概念 ,是指 TaskManager 具有的并发执行能力。一个程序需要的 slot 数量,其实就是所有任务中最大的那个并行度
4.3.2 程序与数据流(DataFlow)
- 在运行时,Flink 上运行的程序会被映射成 逻辑数据流(dataflows),它包含了这三部分
- 每一个 dataflow 以一个或多个 sources 开始以一个或多个 sinks 结束。dataflow 类似于任意的有向无环图(DAG)
- 在大部分情况下,程序中的转换运算(transformations)跟dataflow中的算子
4.3.3 执行图(ExecutionGraph)
- Flink 中的执行图可以分成四层:StreamGraph -> JobGraph -> ExecutionGraph -> 物理执行图
- StreamGraph : 是根据用户通过 StreamAPI 编写的代码生成的最初的图。用来表示程序的拓扑结构。
- JobGraph : StreamGraph 经过优化后生成了 JobGraph,提交给 JobManager 的数据结构。主要的优化为,将多个符合条件的节点 chain 在一起作为一个节点,在客户端执行。
- ExecutionGraph : JobManager 根据 JobGraph 生成 ExecutionGraph。ExecutionGraph 是 JobGraph 的并行化版本,是调度层最核心的数据结构。在 JobManager 执行。
- 物理执行图:JobManager 根据 ExecutionGraph 对 Job 进行调度后,在各个 TaskManager 上部署 Task 后形成的“图”,并不是一个具体的数据结构。
4.3.4 并行度(Parallelism)
- 一个程序中,不同的算子可能具有不同的并行度
- 算子之间传输数据的形式可以是 one-to-one (forwarding) 的模式也可以是 redistributing 的模式,具体是哪一种形式,取决于算子的种类
- One-to-one : stream 维护着分区以及元素的顺序(比如 source 和 map 之间)。这意味着 map 算子的子任务看到的元素的个数以及顺序跟 source 算子的子任务生产的元素的个数、顺序相同。map、fliter、flatMap 等算子都是 one-to-one 的对应关系。
- Redistributing : stream 的分区会发生改变。每一个算子的子任务依据所选择的 transformation 发送数据到不同的目标任务。例如,keyBy 基于 hashCode 重分区、而broadcast 和 rebalance 会随机重新分区,这些算子都会引起 redistribute 过程,而 redistribute 过程就类似于 Spark 中的 shuffle 过程。
4.3.5 任务链(Operator Chains)
- Flink 采用了一种称为任务链的优化技术,可以在特定条件下减少本地通信的开销。为了满足任务链的要求,必须将两个或多个算子设为相同的并行度,并通过本地转发(local forward)的方式进行连接
- 相同并行度的 one-to-one 操作,Flink 这样相连的算子链接在一起形成一个 task,原来的算子成为里面的 subtask
- 并行度相同、并且是 one-to-one 操作,两个条件缺一不可
代码中定义的每一步操作(算子、operator)就是一个任务。
算子可以设置并行度,所以每一步操作都可以有多个并行的子任务。
Flink 可以将前后执行的不同任务合并起来。
即,如果并行度相同,one-to-one 数据传输,那么可以把算子合并成一个任务链。
slot 是 TaskManager 拥有的计算资源的子集,一个任务必须再一个 slot 上执行。
每个算子的并行任务,必须执行在不同的 slot 上。
如果是不同算子的任务,可以共享一个 slot。
一般情况下,一段代码执行需要的 slot 数量,就是并行度最大的算子的并行度。
并行度和任务有关,就是每一个算子拥有的并行任务数量。
slot 数量只跟 TaskManager 配置有关,代表 TaskManager 并行处理数据的能力。
注:不共享 slot 的配置
# 全局不共享
environment.disableOperatorChaining()
# 算子之间不共享
Transform.slotSharingGroup("1")
Transform.disableChaining()
Transform.startNewChain()
五、Flink 流处理 API
5.1 Environment
5.1.1 getExecutionEnvironment
// 0. Create stream environment
val streamEnvironment: StreamExecutionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment
streamEnvironment.setParallelism(1)
val dataSetEnvironment: ExecutionEnvironment = ExecutionEnvironment.getExecutionEnvironment
dataSetEnvironment.setParallelism(1)
5.1.2 createLocalEnviroment
// 0. 返回本地执行环境,需要在调用时指定默认的并行度
val streamLocalExeEnvironment: StreamExecutionEnvironment = StreamExecutionEnvironment.createLocalEnvironment(1)
5.1.3 createRemoteEnvironment
// 0. 返回集群执行环境,将 Jar 提交到远程服务器。需要在调用时指定集群地址和要在集群运行的 Jar 包
val streamRemoteExeEnvironment: StreamExecutionEnvironment = StreamExecutionEnvironment.createRemoteEnvironment("test01", 6123,"PATH/something.jar")
streamRemoteExeEnvironment.setParallelism(1)
5.2 Source
5.2.1 从集合读取数据
Code
// 输入数据的样例类
case class SensorReading(id: String, timestamp: Long, temperature: Double)
object SourceDemo {
def main(args: Array[String]): Unit = {
// 0. Create stream environment.
val environment: StreamExecutionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment
environment.setParallelism(1)
// 1. Source from Collection
val sourceFromCollection1: DataStream[String] = environment.fromElements[String]("hello world", "hello flink")
val sourceFromCollection2: DataStream[SensorReading] = environment.fromCollection(List(
SensorReading("sensor_1", 1547718199, 35.8),
SensorReading("sensor_6", 1547718201, 15.4),
SensorReading("sensor_7", 1547718202, 6.7),
SensorReading("sensor_10", 1547718205, 38.1),
SensorReading("sensor_1", 1547718207, 37.2),
SensorReading("sensor_1", 1547718212, 33.5),
SensorReading("sensor_1", 1547718215, 38.1),
SensorReading("sensor_6", 1547718222, 35.8)
))
// 打印输出
sourceFromCollection1.print("sourceFromCollection1")
sourceFromCollection2.print("sourceFromCollection2")
environment.execute("Source demo")
}
}
5.2.2 从文件读取数据
File
sensor_1,1547718199,35.8
sensor_6,1547718201,15.4
sensor_7,1547718202,6.7
sensor_10,1547718205,38.1
sensor_1,1547718207,37.2
sensor_1,1547718212,33.5
sensor_1,1547718215,38.1
sensor_6,1547718222,35.8
Code
// 2. Source from File
val params: ParameterTool = ParameterTool.fromArgs(args)
val sourceFromFile: DataStream[String] = environment.readTextFile(params.get("path"))
5.2.3 以 socket 作为来源
Code
// 3. Source from socket
val sourceFromSocket: DataStream[String] = environment.socketTextStream("test01", 7777)
5.2.4 以 Kafka 消息队列的数据作为来源
Create topic
kafka-topics --list --zookeeper localhost:2181/kafka
kafka-topics --create --zookeeper localhost:2181/kafka --replication-factor 3 --partitions 2 --topic sensor
kafka-topics --describe --zookeeper localhost:2181/kafka --topic sensor
kafka-console-producer --broker-list test01:9092,test02:9092,test03:9092 --topic sensor
kafka-console-consumer --bootstrap-server test01:9092,test02:9092,test03:9092 --topic sensor
pom
org.apache.flink
flink-connector-kafka_2.11
1.11.1
provided
Code
// 4. Source from kafka
val properties = new Properties()
properties.setProperty("bootstrap.servers", "test01:9092")
properties.setProperty("group.id", "test-group")
properties.setProperty("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer")
properties.setProperty("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer")
properties.setProperty("auto.offset.reset", "latest")
// earliest : 当各分区下有已提交的 offset 时,从提交的 offset 开始消费;无提交的 offset 时,从头开始消费
// latest : 当各分区下有已提交的 offset 时,从提交的 offset 开始消费;无提交的 offset 时,消费新产生的该分区下的数据
// none : topic各分区都存在已提交的 offset 时,从 offset 后开始消费;只要有一个分区不存在已提交的 offset,则抛出异常
val sourceFromKafka: DataStream[String] = environment.addSource(new FlinkKafkaConsumer[String]("sensor", new SimpleStringSchema(), properties))
5.2.5 自定义 Source
Code
// 5. Source from Custom Source
val sourceFromMySensorSource: DataStream[SensorReading] = environment.addSource(new MySensorSource)
sourceFromMySensorSource.print("sourceFromMySensorSource")
// 实现一个自定义的 SourceFunction,自动生成测试数据
class MySensorSource() extends SourceFunction[SensorReading] {
// 定义一个 flag,表示数据源是否正常运行
private var running: Boolean = true
override def cancel(): Unit = running = false
// 随机生成 SensorReading 数据
override def run(sourceContext: SourceFunction.SourceContext[SensorReading]): Unit = {
// 定义一个随机数发生器
val rand = new Random()
// 定义 10 个传感器的初始温度
var curTemps = 1.to(10).map(i => ("sensor_" + i, 60 + rand.nextGaussian() * 20))
// 无限循环,生成随机数据
while (running) {
// 在当前温度基础上,随机生成微小波动
curTemps = curTemps.map(data => (data._1, data._2 + rand.nextGaussian()))
// 包装成样例类,用 sourceContext 发出数据
curTemps.foreach(
data => sourceContext.collect(SensorReading(data._1, System.currentTimeMillis(), data._2))
)
Thread.sleep(1000L)
}
}
}
5.2.6 Full Demo Code
package com.mso.flink.stream.source
import java.util.Properties
import org.apache.flink.api.common.serialization.SimpleStringSchema
import org.apache.flink.api.java.utils.ParameterTool
import org.apache.flink.streaming.api.functions.source.SourceFunction
import org.apache.flink.streaming.api.scala._
import org.apache.flink.streaming.connectors.kafka.FlinkKafkaConsumer
import scala.util.Random
// 输入数据的样例类
case class SensorReading(id: String, timestamp: Long, temperature: Double)
object SourceDemo {
def main(args: Array[String]): Unit = {
// 0. Create stream environment.
val environment: StreamExecutionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment
environment.setParallelism(1)
// 1. Source from Collection
val sourceFromCollection1: DataStream[String] = environment.fromElements[String]("hello world", "hello flink")
val sourceFromCollection2: DataStream[SensorReading] = environment.fromCollection(List(
SensorReading("sensor_1", 1547718199, 35.8),
SensorReading("sensor_6", 1547718201, 15.4),
SensorReading("sensor_7", 1547718202, 6.7),
SensorReading("sensor_10", 1547718205, 38.1),
SensorReading("sensor_1", 1547718207, 37.2),
SensorReading("sensor_1", 1547718212, 33.5),
SensorReading("sensor_1", 1547718215, 38.1),
SensorReading("sensor_6", 1547718222, 35.8)
))
// 2. Source from File
val params: ParameterTool = ParameterTool.fromArgs(args)
val sourceFromFile: DataStream[String] = environment.readTextFile(params.get("path"))
// 3. Source from socket
// val sourceFromSocket: DataStream[String] = environment.socketTextStream("test01", 7777)
// 4. Source from kafka
val properties = new Properties()
properties.setProperty("bootstrap.servers", "test01:9092")
properties.setProperty("group.id", "test-group")
properties.setProperty("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer")
properties.setProperty("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer")
properties.setProperty("auto.offset.reset", "latest")
// earliest : 当各分区下有已提交的 offset 时,从提交的 offset 开始消费;无提交的 offset 时,从头开始消费
// latest : 当各分区下有已提交的 offset 时,从提交的 offset 开始消费;无提交的 offset 时,消费新产生的该分区下的数据
// none : topic各分区都存在已提交的 offset 时,从 offset 后开始消费;只要有一个分区不存在已提交的 offset,则抛出异常
val sourceFromKafka: DataStream[String] = environment.addSource(new FlinkKafkaConsumer[String]("sensor", new SimpleStringSchema(), properties))
// 5. Source from Custom Source
val sourceFromMySensorSource: DataStream[SensorReading] = environment.addSource(new MySensorSource)
// 打印输出
// sourceFromCollection1.print("sourceFromCollection1")
// sourceFromCollection2.print("sourceFromCollection2")
// sourceFromFile.print("sourceFromFile")
// sourceFromKafka.print("sourceFromKafka")
sourceFromMySensorSource.print("sourceFromMySensorSource")
environment.execute("Source demo")
}
}
// 实现一个自定义的 SourceFunction,自动生成测试数据
class MySensorSource() extends SourceFunction[SensorReading] {
// 定义一个 flag,表示数据源是否正常运行
private var running: Boolean = true
override def cancel(): Unit = running = false
// 随机生成 SensorReading 数据
override def run(sourceContext: SourceFunction.SourceContext[SensorReading]): Unit = {
// 定义一个随机数发生器
val rand = new Random()
// 定义 10 个传感器的初始温度
var curTemps = 1.to(10).map(i => ("sensor_" + i, 60 + rand.nextGaussian() * 20))
// 无限循环,生成随机数据
while (running) {
// 在当前温度基础上,随机生成微小波动
curTemps = curTemps.map(data => (data._1, data._2 + rand.nextGaussian()))
// 包装成样例类,用 sourceContext 发出数据
curTemps.foreach(
data => sourceContext.collect(SensorReading(data._1, System.currentTimeMillis(), data._2))
)
Thread.sleep(1000L)
}
}
}
5.3 Transform
转换算子,读取数据之后,sink 之前的操作。
5.3.1 map
dataStream.map { x => x * 2 }
5.3.2 flatMap
dataStream.flatMap { str => str.split(" ") }
5.3.3 Filter
dataStream.filter { _ != 0 }
dataStream.filter { x => x==1 }
5.3.4 KeyBy
逻辑的将一个流拆分成不相交的分区,每个分区包含具有相同 key 的元素,在内部以 hash 的行式实现的。
package com.mso.flink.stream.transform
import org.apache.flink.api.common.functions.ReduceFunction
import org.apache.flink.api.java.functions.KeySelector
import org.apache.flink.api.java.utils.ParameterTool
import org.apache.flink.streaming.api.functions.ProcessFunction
import org.apache.flink.streaming.api.scala._
import org.apache.flink.util.Collector
// 输入数据的样例类
case class SensorReading(id: String, timestamp: Long, temperature: Double)
object TransformDemo {
def main(args: Array[String]): Unit = {
val environment: StreamExecutionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment
// 从文件中红读取数据
val params: ParameterTool = ParameterTool.fromArgs(args)
val sourceStream: DataStream[String] = environment.readTextFile(params.get("path"))
// 1. 基本转换
val basicTransDataStream: DataStream[SensorReading] = sourceStream
.map((data: String) => {
val dataArray: Array[String] = data.split(",")
SensorReading(dataArray(0), dataArray(1).toLong, dataArray(2).toDouble)
})
// 2. 分组滚动聚合
val aggStream: DataStream[SensorReading] = basicTransDataStream
// .keyBy(0)
// .keyBy("id")
// .keyBy(data => data.id)
.keyBy(new MyKeySelector)
// .min("temperature") // 取当前分组内,temperature 最小的数据,且其他字段取第一条数据的值
.minBy("temperature") //取当前分组内,temperature 最小的数据,且其他字段取 temperature 最小的那条数据的值
basicTransDataStream.print("basicTransDataStream")
aggStream.print("aggStream")
environment.execute()
}
}
// 自定义函数类,key 选择器
private class MyKeySelector2 extends KeySelector[SensorReading2, String] {
override def getKey(in: SensorReading2): String = in.id
}
5.3.5 滚动聚合算子
keyedStream.sum(0)
keyedStream.sum("key")
keyedStream.min(0)
keyedStream.min("key")
keyedStream.max(0)
keyedStream.max("key")
keyedStream.minBy(0)
keyedStream.minBy("key")
keyedStream.maxBy(0)
keyedStream.maxBy("key")
5.3.6 Reduce
// .reduce(new MyReduceFunction)
.reduce((curData: SensorReading, newData: SensorReading) =>
SensorReading(
curData.id,
curData.timestamp.max(newData.timestamp),
curData.temperature.min(newData.temperature)
)
) // 取 时间的最大值 和 温度的最小值
// 自定义 Reduce 方法
private class MyReduceFunction extends ReduceFunction[SensorReading] {
override def reduce(t: SensorReading, t1: SensorReading): SensorReading = {
SensorReading(t.id, t.timestamp.max(t1.timestamp), t.temperature.min(t1.temperature))
}
}
5.3.7 Split 和 Select & SideOutput
// 3. 分流
val splitStream: SplitStream[SensorReading] = aggStream
.split(
(data: SensorReading) => {
if (data.temperature > 30)
Seq("high")
else
Seq("low")
}
)
val highTempStream: DataStream[SensorReading] = splitStream.select("high")
val lowTempStream: DataStream[SensorReading] = splitStream.select("low")
val allTempStream: DataStream[SensorReading] = splitStream.select("high", "low")
val highTempOutputTag: OutputTag[String] = new OutputTag[String]("high")
val lowTempOutputTag: OutputTag[String] = new OutputTag[String]("low")
val mainDataStream: DataStream[SensorReading] = aggStream
.process(new ProcessFunction[SensorReading, SensorReading] {
override def processElement(
value: SensorReading,
ctx: ProcessFunction[SensorReading, SensorReading]#Context,
out: Collector[SensorReading]): Unit = {
if (value.temperature > 30) {
// 将数据发送到侧输出中
ctx.output(highTempOutputTag, String.valueOf(value))
}
else if (value.temperature < 20) {
ctx.output(lowTempOutputTag, String.valueOf(value))
}
else {
// 将数据发送到常规输出中
out.collect(value)
}
}
}
)
// 通过 getSideOutput 获取侧输出流
val sideOutputHighTempDataStream: DataStream[String] = mainDataStream.getSideOutput(highTempOutputTag)
val sideOutputLowTempDataStream: DataStream[String] = mainDataStream.getSideOutput(lowTempOutputTag)
highTempStream.print("highTempStream")
lowTempStream.print("lowTempStream")
allTempStream.print("allTempStream")
sideOutputHighTempDataStream.print("sideOutputHighTempDataStream")
sideOutputLowTempDataStream.print("sideOutputLowTempDataStream")
5.3.8 Connect 和 CoMap
connect,主要用于合并两个不同类型的流,且合并之后的流不能再 connect
// 4. 合流
val waringStream: DataStream[(String, Double)] = highTempStream.map((data: SensorReading) => (data.id, data.temperature))
val connectedStreams: ConnectedStreams[(String, Double), SensorReading] = waringStream.connect(lowTempStream)
val connectedResultStream: DataStream[Product] = connectedStreams.map(
(waringData: (String, Double)) => (waringData._1, waringData._2, "high temp waring"),
(lowTempData: SensorReading) => (lowTempData.id, "normal")
)
connectedResultStream.print("connectedResultStream")
5.3.9 Union
union,主要用于合并相同类型的流,且合并之后的流可以继续合并
val unionStream: DataStream[SensorReading] = highTempStream.union(lowTempStream)
unionStream.print("unionStream")
5.3.10 Full Code
package com.mso.flink.stream.transform
import org.apache.flink.api.common.functions.ReduceFunction
import org.apache.flink.api.java.functions.KeySelector
import org.apache.flink.api.java.utils.ParameterTool
import org.apache.flink.streaming.api.functions.ProcessFunction
import org.apache.flink.streaming.api.scala._
import org.apache.flink.util.Collector
// 输入数据的样例类
case class SensorReading(id: String, timestamp: Long, temperature: Double)
object TransformDemo {
def main(args: Array[String]): Unit = {
val environment: StreamExecutionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment
// 从文件中红读取数据
val params: ParameterTool = ParameterTool.fromArgs(args)
val sourceStream: DataStream[String] = environment.readTextFile(params.get("path"))
// 1. 基本转换
val basicTransDataStream: DataStream[SensorReading] = sourceStream
.map((data: String) => {
val dataArray: Array[String] = data.split(",")
SensorReading(dataArray(0), dataArray(1).toLong, dataArray(2).toDouble)
})
// 2. 分组滚动聚合
val aggStream: DataStream[SensorReading] = basicTransDataStream
// .keyBy(0)
// .keyBy("id")
// .keyBy(data => data.id)
.keyBy(new MyKeySelector)
// .min("temperature") // 取当前分组内,temperature 最小的数据,且其他字段取第一条数据的值
// .minBy("temperature") //取当前分组内,temperature 最小的数据,且其他字段取 temperature 最小的那条数据的值
// .reduce(new MyReduceFunction)
.reduce((curData: SensorReading, newData: SensorReading) =>
SensorReading(
curData.id,
curData.timestamp.max(newData.timestamp),
curData.temperature.min(newData.temperature)
)
) // 取 时间的最大值 和 温度的最小值
// 3. 分流
val splitStream: SplitStream[SensorReading] = aggStream
.split(
(data: SensorReading) => {
if (data.temperature > 30)
Seq("high")
else
Seq("low")
}
)
val highTempStream: DataStream[SensorReading] = splitStream.select("high")
val lowTempStream: DataStream[SensorReading] = splitStream.select("low")
val allTempStream: DataStream[SensorReading] = splitStream.select("high", "low")
val highTempOutputTag: OutputTag[String] = new OutputTag[String]("high")
val lowTempOutputTag: OutputTag[String] = new OutputTag[String]("low")
val mainDataStream: DataStream[SensorReading] = aggStream
.process(new ProcessFunction[SensorReading, SensorReading] {
override def processElement(
value: SensorReading,
ctx: ProcessFunction[SensorReading, SensorReading]#Context,
out: Collector[SensorReading]): Unit = {
if (value.temperature > 30) {
// 将数据发送到侧输出中
ctx.output(highTempOutputTag, String.valueOf(value))
}
else if (value.temperature < 20) {
ctx.output(lowTempOutputTag, String.valueOf(value))
}
else {
// 将数据发送到常规输出中
out.collect(value)
}
}
}
)
// 通过 getSideOutput 获取侧输出流
val sideOutputHighTempDataStream: DataStream[String] = mainDataStream.getSideOutput(highTempOutputTag)
val sideOutputLowTempDataStream: DataStream[String] = mainDataStream.getSideOutput(lowTempOutputTag)
// 4. 合流
val unionStream: DataStream[SensorReading] = highTempStream.union(lowTempStream)
val waringStream: DataStream[(String, Double)] = highTempStream.map((data: SensorReading) => (data.id, data.temperature))
val connectedStreams: ConnectedStreams[(String, Double), SensorReading] = waringStream.connect(lowTempStream)
val connectedResultStream: DataStream[Product] = connectedStreams.map(
(waringData: (String, Double)) => (waringData._1, waringData._2, "high temp waring"),
(lowTempData: SensorReading) => (lowTempData.id, "normal")
)
basicTransDataStream.print("basicTransDataStream")
aggStream.print("aggStream")
highTempStream.print("highTempStream")
lowTempStream.print("lowTempStream")
allTempStream.print("allTempStream")
sideOutputHighTempDataStream.print("sideOutputHighTempDataStream")
sideOutputLowTempDataStream.print("sideOutputLowTempDataStream")
unionStream.print("unionStream")
connectedResultStream.print("connectedResultStream")
environment.execute()
}
}
// 自定义函数类,key 选择器
private class MyKeySelector extends KeySelector[SensorReading, String] {
override def getKey(in: SensorReading): String = in.id
}
// 自定义 Reduce 方法
private class MyReduceFunction extends ReduceFunction[SensorReading] {
override def reduce(t: SensorReading, t1: SensorReading): SensorReading = {
SensorReading(t.id, t.timestamp.max(t1.timestamp), t.temperature.min(t1.temperature))
}
}
5.4 支持的数据类型
5.4.1 基本数据类型
Flink 支持所有的 Java 和 Scala 基础数据类型,Int、Double、Long、String …
val numbers: DataStream[Long] = env.fromElements(1L, 2L, 3L, 4L)
numbers.map(n => n + 1)
5.4.2 Java 和 Scala 元组(Tuples)
val persons: DataStream[(String, Integer)] = env.fromElements(
("Adam", 17),
("Sarah", 23) )
persons.filter(p => p._2 > 18)
5.4.3 Scala 样例类(case classes)
case class Person(name: String, age: Int)
val persons: DataStream[Person] = env.fromElements(
Person("Adam", 17),
Person("Sarah", 23)
)
persons.filter(p => p.age > 18)
5.4.4 Java 简单对象(POJOs)
public class Person {
public String name;
public int age;
public Person() {}
public Person(String name, int age) {
this.name = name;
this.age = age;
}
}
DataStream persons = env.fromElements(
new Person("Alex", 42),
new Person("Werdy", 23));
5.4.5 其它
Flink 对 Java 和 Scala 中的一些特殊的数据类型也是支持的。比如 Java 的 ArrayList、HashMap、Enum 等
5.5 实现 UDF 函数
5.5.1 函数类
Flink 暴露了所有 UDF 函数的接口,实现方式为接口或抽象类。比如上面例子中的 MyKeySelector,MyReduceFunction
5.5.2 匿名函数
val tweets: DataStream[String] = ...
val flinkTweets = tweets.filer(_.contains("flink"))
5.5.3 富函数
富函数 是 DataStream API 提供的一个函数类的接口,所有 Flink 函数类都有其 Rich 版本。
它与常规函数的不同在于,可以获取运行环境的上下文,并拥有一些生命周期方法,所以可以实现更复杂的功能。
- RichMapFunction
- RichFlatMapFunction
- RichFilterFunction
- ,
Rich Function 有一个生命周期的概念,典型的生命周期方法有:
- open() : 是 rich function 的初始化方法,当一个算子,例如 map 或者 filter 被调用之前 open() 会被调用
- close() : 是生命周期中的最后一个调用的方法,做一些清理工作
- getRuntimeContext() : 提供了函数的 Runtimecontext 的一些信息,例如函数执行的并行度,任务的名字,以及 state 状态
private class MyRichMap extends RichMapFunction{
getRuntimeContext.getIndexOfThisSubtask // 并行子任务的索引
// 调用方法最初的操作,常用于创建数据库连接
override def open(parameters: Configuration): Unit = super.open(parameters)
override def map(in: Nothing): Nothing = ???
// 调用方法最后的操作,常用于关闭数据库连接
override def close(): Unit = super.close()
}
5.5.4 总结
keyBy
基于 keyBy 的 hash code 重分区
同一个 key 只能再一个分区内处理,一个分区内可以有不同的 key 的数据
keyBy 之后的所有操作,针对的作用域都只是当前的 key,不同于 Spark reduceByKey() 在本地聚合的操作,keyBy 不涉及计算,仅确定当前数据要发往哪个分区
滚动聚合操作
DataStream 没有聚合操作,目前所有的聚合操作都是针对 KeyedStream
多流转换算子
split-select, connect-comap/coflatmap 成对出现
先转换成 SplitStream, ConnectedStreams,然后再通过 select/comap 操作转换回 DataStream
所谓 coMap,其实就是基于 ConnectedStreams 的 map 方法,里面传入的参数是 CoMapFunction
富函数
富函数是函数类的增强版,可以有生命周期方法,还可以获取运行时上下文,在运行时上下文可以对 state 进行操作
Flink 有状态的流式计算,状态编程,就是基于 RichFunction
5.6 Sink
更多连接器:DataStream Connectors
5.6.1 Kafka
Create topic
kafka-topics --list --zookeeper localhost:2181/kafka
kafka-topics --create --zookeeper localhost:2181/kafka --replication-factor 3 --partitions 1 --topic flink-sink
kafka-topics --describe --zookeeper localhost:2181/kafka --topic flink-sink
kafka-console-producer --broker-list test01:9092,test02:9092,test03:9092 --topic flink-sink
kafka-console-consumer --bootstrap-server test01:9092,test02:9092,test03:9092 --topic flink-sink
Data
sensor_1,1547718199,35.8
sensor_6,1547718201,15.4
sensor_7,1547718202,6.7
sensor_10,1547718205,38.1
sensor_1,1547718207,37.2
sensor_1,1547718212,33.5
sensor_1,1547718215,38.1
sensor_6,1547718222,35.8
Code
package com.mso.flink.stream.sink
import java.util.Properties
import org.apache.flink.api.common.serialization.SimpleStringSchema
import org.apache.flink.streaming.api.scala._
import org.apache.flink.streaming.connectors.kafka.{FlinkKafkaConsumer, FlinkKafkaProducer}
// 输入数据的样例类
case class SensorReading(id: String, timestamp: Long, temperature: Double)
object KafkaSinkDemo {
def main(args: Array[String]): Unit = {
val environment: StreamExecutionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment
// Source
// 输入数据同 sensor.txt 格式为:sensor_1, 1547718199, 35.8
val properties = new Properties()
properties.setProperty("bootstrap.servers", "test01:9092")
properties.setProperty("group.id", "test-group")
properties.setProperty("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer")
properties.setProperty("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer")
properties.setProperty("auto.offset.reset", "latest")
val sourceFromKafka: DataStream[String] = environment.addSource(
new FlinkKafkaConsumer[String](
"sensor",
new SimpleStringSchema(),
properties))
// Transform
val basicTransDataStream: DataStream[String] = sourceFromKafka
.map((data: String) => {
val dataArray: Array[String] = data.split(",")
SensorReading(dataArray(0), dataArray(1).trim.toLong, dataArray(2).toDouble).toString
})
// Sink
basicTransDataStream.addSink(new FlinkKafkaProducer[String](
"test01:9092",
"flink-sink",
new SimpleStringSchema()))
environment.execute("Kafka sink demo")
}
}
5.6.2 Redis
POM
org.apache.bahir
flink-connector-redis_2.11
1.0
provided
Data
sensor_1,1547718199,35.8
sensor_6,1547718201,15.4
sensor_7,1547718202,6.7
sensor_10,1547718205,38.1
sensor_1,1547718207,37.2
sensor_1,1547718212,33.5
sensor_1,1547718215,38.1
sensor_6,1547718222,35.8
Code
package com.mso.flink.stream.sink
import org.apache.flink.api.java.utils.ParameterTool
import org.apache.flink.streaming.api.scala._
import org.apache.flink.streaming.connectors.redis.RedisSink
import org.apache.flink.streaming.connectors.redis.common.config.FlinkJedisPoolConfig
import org.apache.flink.streaming.connectors.redis.common.mapper.{RedisCommand, RedisCommandDescription, RedisMapper}
object RedisSinkDemo {
def main(args: Array[String]): Unit = {
val environment: StreamExecutionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment
// 从文件中红读取数据
val params: ParameterTool = ParameterTool.fromArgs(args)
val sourceStream: DataStream[String] = environment.readTextFile(params.get("path"))
// Transform
val sourceDataStream: DataStream[SensorReading] = sourceStream
.map((data: String) => {
val dataArray: Array[String] = data.split(",")
SensorReading(dataArray(0), dataArray(1).toLong, dataArray(2).toDouble)
})
// Sink
val conf = new FlinkJedisPoolConfig.Builder().setHost("localhost").setPort(6379).build()
sourceDataStream.addSink(new RedisSink[SensorReading](conf, new MyRedisMapper))
environment.execute("Redis sink demo")
}
}
class MyRedisMapper extends RedisMapper[SensorReading] {
// 定义保存到 redis 的命令,hset table_name key value
override def getCommandDescription: RedisCommandDescription = {
new RedisCommandDescription(RedisCommand.HSET, "sensor_temp")
}
override def getKeyFromData(data: SensorReading): String = data.id
override def getValueFromData(data: SensorReading): String = data.temperature.toString
}
5.6.3 Elasticsearch
POM
org.apache.flink
flink-connector-elasticsearch6_2.11
1.11.1
provided
Data
sensor_1,1547718199,35.8
sensor_6,1547718201,15.4
sensor_7,1547718202,6.7
sensor_10,1547718205,38.1
sensor_1,1547718207,37.2
sensor_1,1547718212,33.5
sensor_1,1547718215,38.1
sensor_6,1547718222,35.8
Code
package com.mso.flink.stream.sink
import java.util
import org.apache.flink.api.common.functions.RuntimeContext
import org.apache.flink.api.java.utils.ParameterTool
import org.apache.flink.streaming.api.scala._
import org.apache.flink.streaming.connectors.elasticsearch.{ElasticsearchSinkFunction, RequestIndexer}
import org.apache.flink.streaming.connectors.elasticsearch6.ElasticsearchSink
import org.apache.http.HttpHost
import org.elasticsearch.action.index.IndexRequest
import org.elasticsearch.client.Requests
object ESSinkDemo {
def main(args: Array[String]): Unit = {
val environment: StreamExecutionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment
// 从文件中红读取数据
val params: ParameterTool = ParameterTool.fromArgs(args)
val sourceStream: DataStream[String] = environment.readTextFile(params.get("path"))
// Transform
val sourceDataStream: DataStream[SensorReading] = sourceStream
.map((data: String) => {
val dataArray: Array[String] = data.split(",")
SensorReading(dataArray(0), dataArray(1).toLong, dataArray(2).toDouble)
})
// Sink
val httpHosts = new util.ArrayList[HttpHost]()
httpHosts.add(new HttpHost("127.0.0.1", 9200, "http"))
val myEsSinkFunc: ElasticsearchSinkFunction[SensorReading] = new ElasticsearchSinkFunction[SensorReading] {
override def process(t: SensorReading, runtimeContext: RuntimeContext, requestIndexer: RequestIndexer): Unit = {
// 包装写入 es 的数据
val dataSource = new util.HashMap[String, String]()
dataSource.put("sensor_id", t.id)
dataSource.put("timestamp", t.timestamp.toString)
dataSource.put("temperature", t.temperature.toString)
// 创建一个 index request
val indexRequest: IndexRequest = Requests.indexRequest()
.index("sensor_temp")
.`type`("readingdata")
.source(dataSource)
requestIndexer.add(indexRequest)
}
}
sourceDataStream.addSink(new ElasticsearchSink.Builder[SensorReading](httpHosts, myEsSinkFunc).build())
environment.execute("Elasticsearch sink demo")
}
}
5.6.4 JDBC 自定义 sink
POM
org.apache.flink
flink-connector-jdbc_2.11
1.11.1
provided
mysql
mysql-connector-java
5.1.21
provided
Create table
# 注,此处参照生产环境添加了唯一性索引。
# 若没有唯一性索引,可使用第一种方法进行新增和修改数据
# 若有唯一性索引,两种方法都可以使用
DROP TABLE IF EXISTS `testdb`.`sensor_table`;
CREATE TABLE `testdb`.`sensor_table` (
`id` bigint(20) NOT NULL AUTO_INCREMENT,
`sensor` varchar(20) CHARACTER SET latin1 COLLATE latin1_swedish_ci NOT NULL,
`temperature` double NULL DEFAULT NULL,
PRIMARY KEY (`id`) USING BTREE,
UNIQUE INDEX `sensor`(`sensor`) USING BTREE
) ENGINE = InnoDB AUTO_INCREMENT = 80 CHARACTER SET = latin1 COLLATE = latin1_swedish_ci ROW_FORMAT = Compact;
SET FOREIGN_KEY_CHECKS = 1;
Data
sensor_1,1547718199,35.8
sensor_6,1547718201,15.4
sensor_7,1547718202,6.7
sensor_10,1547718205,38.1
sensor_1,1547718207,37.2
sensor_1,1547718212,33.5
sensor_1,1547718215,38.1
sensor_6,1547718222,35.8
Code 1
package com.mso.flink.stream.sink
import java.sql.{Connection, DriverManager, PreparedStatement}
import org.apache.flink.api.java.utils.ParameterTool
import org.apache.flink.configuration.Configuration
import org.apache.flink.streaming.api.functions.sink.{RichSinkFunction, SinkFunction}
import org.apache.flink.streaming.api.scala._
object JdbcSinkDemo1 {
def main(args: Array[String]): Unit = {
val environment: StreamExecutionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment
// 从文件中红读取数据
val params: ParameterTool = ParameterTool.fromArgs(args)
val sourceStream: DataStream[String] = environment.readTextFile(params.get("path"))
// Transform
val sourceDataStream: DataStream[SensorReading] = sourceStream
.map((data: String) => {
val dataArray: Array[String] = data.split(",")
SensorReading(dataArray(0), dataArray(1).toLong, dataArray(2).toDouble)
})
// Sink
sourceDataStream.addSink(new MyJdbcSink).setParallelism(1)
environment.execute("Jdbc sink demo")
}
}
class MyJdbcSink extends RichSinkFunction[SensorReading] {
// 首先定义 sql 连接,以及预编译语句
var coon: Connection = _
var insertStmt: PreparedStatement = _
var updateStmt: PreparedStatement = _
// 在 open 生命周期方法中创建连接以及预编译语句
override def open(parameters: Configuration): Unit = {
Class.forName("com.mysql.jdbc.Driver");
// coon = DriverManager.getConnection("jdbc:mysql://localhost:3306/testdb?useUnicode=true&characterEncoding=utf-8", "admin", "12345678")
coon = DriverManager.getConnection("jdbc:mysql://localhost:3306/testdb", "admin", "12345678")
updateStmt = coon.prepareStatement("UPDATE sensor_table set temperature=? WHERE sensor = ?")
insertStmt = coon.prepareStatement("INSERT INTO sensor_table (id, sensor, temperature) VALUES (null,?,?)")
}
// 调用连接 执行sql
override def invoke(value: SensorReading, context: SinkFunction.Context[_]): Unit = {
// 执行更新语句
updateStmt.setDouble(1, value.temperature)
updateStmt.setString(2, value.id)
updateStmt.execute()
// 如果 update 没有更新,即没有查询到数据,那么执行插入操作
if (updateStmt.getUpdateCount == 0) {
insertStmt.setString(1, value.id)
insertStmt.setDouble(2, value.temperature)
insertStmt.execute()
}
}
// 关闭操作
override def close(): Unit = {
insertStmt.close()
updateStmt.close()
coon.close()
}
}
Code 2
package com.mso.flink.stream.sink
import java.sql.PreparedStatement
import org.apache.flink.api.java.utils.ParameterTool
import org.apache.flink.connector.jdbc.{JdbcConnectionOptions, JdbcExecutionOptions, JdbcSink, JdbcStatementBuilder}
import org.apache.flink.streaming.api.functions.sink.SinkFunction
import org.apache.flink.streaming.api.scala._
object JdbcSinkDemo2 {
def main(args: Array[String]): Unit = {
val environment: StreamExecutionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment
// 从文件中红读取数据
val params: ParameterTool = ParameterTool.fromArgs(args)
val sourceStream: DataStream[String] = environment.readTextFile(params.get("path"))
// Transform
val sourceDataStream: DataStream[(String, Double, Double)] = sourceStream
.map((data: String) => {
val dataArray: Array[String] = data.split(",")
(dataArray(0), dataArray(2).toDouble, dataArray(2).toDouble)
})
// Sink
val insertSql = "INSERT INTO sensor_table (id, sensor, temperature) VALUES (NULL,?,?)"
val updateSql = "UPDATE sensor_table set temperature=? WHERE sensor = ?"
val upsertSql = "INSERT INTO sensor_table (sensor, temperature) VALUES (?,?) ON DUPLICATE KEY UPDATE temperature=?"
val myJdbcSinkFunction: SinkFunction[(String, Double, Double)] = JdbcSink.sink(
upsertSql,
new MyJdbcSinkBuilder(),
new JdbcExecutionOptions.Builder().withBatchSize(500).build(),
new JdbcConnectionOptions.JdbcConnectionOptionsBuilder()
.withDriverName("com.mysql.jdbc.Driver")
.withUrl("jdbc:mysql://localhost:3306/testdb")
.withUsername("admin")
.withPassword("12345678")
.build())
sourceDataStream.addSink(myJdbcSinkFunction)
environment.execute("Jdbc sink demo2")
}
}
//手动实现 interface 的方式来传入相关 JDBC Statement build 函数
class MyJdbcSinkBuilder extends JdbcStatementBuilder[(String, Double, Double)] {
override def accept(t: PreparedStatement, u: (String, Double, Double)): Unit = {
t.setString(1, u._1)
t.setDouble(2, u._2)
t.setDouble(3, u._3)
}
}
六、Flink Window
6.1 Window
6.1.1 Window 概述
对于流式计算,如果需要求一些聚合的数据,例如最大值,最小值,平均值等,是没办法做到的。
通常使用窗口来解决流式计算求取聚合数据的问题。
- 一般真实的流都是无界的,但有时需要处理无界的数据
- 可以把无限的数据流进行切分,得到有限的数据集进行处理,也就是得到有界流
- 窗口(window) 就是将无限流切割为有限流的一种方式,它会将流数据分发到 有限大小的桶(bucket) 中进行分析
6.1.2 Window 类型
- 时间窗口(Time Window)
- 滚动时间窗口
- 滑动时间窗口
- 会话窗口
- 计数窗口(Count Window)
- 滚动计数窗口
- 滑动计数窗口
滚动窗口(Tumbling Windows)
- 将数据依据固定的窗口长度对数据进行切分
- 时间对齐,窗口长度固定,数据没有重叠,每一个数据都只能属于一个窗口,窗口交界处的数据是左闭右开
滑动窗口(Sliding Windows)
- 滑动窗口是固定窗口的更广义的一种行式,滑动窗口由固定的窗口长度和滑动间隔组成
- 窗口长度固定,数据有重叠
会话窗口(Session Windows)
- 由一系列事件组合一个指定事件长度的 timeout 间隙组成,也就是一段时间没有接收到新数据就会生成新的窗口
- 时间无对齐
- 即一段时间不操作,则会话失效,使用时指定一个间隔时间即可
滚动窗口是特殊的滑动窗口,当滑动步长等于窗口长度时,两者内的数据相同,代码写法相同。
6.2 Flink Window API
6.2.1 Flink Window API 总览
- Keyed Windows
stream
.keyBy(...) <- keyed versus non-keyed windows
.window(...) <- required: "assigner"
[.trigger(...)] <- optional: "trigger" (else default trigger)
[.evictor(...)] <- optional: "evictor" (else no evictor)
[.allowedLateness(...)] <- optional: "lateness" (else zero)
[.sideOutputLateData(...)] <- optional: "output tag" (else no side output for late data)
.reduce/aggregate/fold/apply() <- required: "function"
[.getSideOutput(...)] <- optional: "output tag"
- Non-Keyed Windows
stream
.windowAll(...) <- required: "assigner"
[.trigger(...)] <- optional: "trigger" (else default trigger)
[.evictor(...)] <- optional: "evictor" (else no evictor)
[.allowedLateness(...)] <- optional: "lateness" (else zero)
[.sideOutputLateData(...)] <- optional: "output tag" (else no side output for late data)
.reduce/aggregate/fold/apply() <- required: "function"
[.getSideOutput(...)] <- optional: "output tag"
在上面,方括号([…])中的命令是可选的。且 widow function 必须在 window() 和 聚合操作中间。
Flink 允许以多种不同的方式自定义窗口逻辑,以实现需求。
.trigger() - 触发器,定义 window 什么时候关闭,计算,输出结果
.evictor() - 移除器,定义移除某些数据的逻辑
.allowedLateness() - 允许处理迟到的数据
.sideOutputLateData() - 将迟到的数据放入侧输出流
.getSideOutput() - 获取侧输出流

6.2.2 Flink Window Assigner
6.2.2.1 窗口分配器
窗口分配器 - window() 方法
- 可以用 .window() 来定义一个窗口,然后基于这个 window 去做一些聚合或者其他处理操作。(注意 window() 方法必须在 keyBy 之后才能用)
- .timeWindow 和 .countWindow 方法,用于定义时间窗口和计数窗口
val minTempPerWindow = dataStream
.map(r => (r.id , r.temperature))
.keyBy(_._1)
.timeWindow(Time.seconds(15))
.reduce((r1,r2) => (r1._1, r1._2.min(r2._2)))
窗口分配器(Window assigner)
- window() 方法接收的输入参数是一个 WindowAssigner
- WindowAssigner 负责将每条输入的数据分发到正确的 window 中
- Flink 提供了通用的 WindowAssigner
- 滚动窗口(tumbling window)
- 滑动窗口(sliding window)
- 会话窗口(session window)
- 全局窗口(global window):把所有的数据放到一个窗口中,需要自定义触发器
6.2.2.2 timeWindow & countWindow
Window 是一种可以把数据切割成有限数据块的手段,窗口可以是 时间驱动[Time Window]的(比如每30秒) 或者 数据驱动[Count Window]的(比如每100个)
创建不同类型的窗口
- 滚动时间窗口 - tumbling time window : .timeWindow(Time.seconds(15))
- 滑动时间窗口 - sliding time window : .timeWindow(Time.seconds(15), Time.seconds(5))
- 会话窗口 - session window : .window(EventTimeSessionWindows.withGap(Time.minutes(10)))
- 滚动计数窗口 - tumbling count window : .countWindow(5)
- 滑动计数窗口 - sliding count window : .countWindow(10, 2)
sourceDataStream
.keyBy(data => data.id)
// 会话窗口,10min 失效
.window(EventTimeSessionWindows.withGap(Time.minutes(10)))
.window(ProcessingTimeSessionWindows.withGap(Time.minutes(10)))
// 滚动时间窗口,窗口大小 1h (第三种为前两种的简写)
.window(TumblingEventTimeWindows.of(Time.hours(1), Time.hours(-8))) // 第二个参数为偏移量,常用于表示时区
.window(TumblingProcessingTimeWindows.of(Time.hours(1), Time.hours(-8))) // 第二个参数为偏移量,常用于表示时区
.timeWindow(Time.hours(1))
// 滑动时间窗口,窗口大小 1h ,每过 1min 滑动一次 (第三种为前两种的简写)
.window(SlidingEventTimeWindows.of(Time.hours(1), Time.minutes(1), Time.hours(-8))) // 第三个参数为偏移量,常用于表示时区,可以省略
.window(SlidingProcessingTimeWindows.of(Time.hours(1), Time.minutes(1), Time.hours(-8))) // 第三个参数为偏移量,常用于表示时区,可以省略
.timeWindow(Time.hours(1), Time.minutes(1))
// 滚动计数窗口,窗口大小为 10
.countWindow(10L)
// 滑动计数窗口,窗口大小为 10,每过 2条 滑动一次
.countWindow(10L, 2L)
6.2.3 Flink Window Function
window function 定义了要对窗口中收集的数据做的计算操作,分为以下两类:
- 增量聚合函数 - incremental aggregation functions : 每条数据到来就进行计算,保持一个简单的状态
- reduce(reduceFunction) - 输入输出中间状态的类型相同
- aggregate(aggregateFunction) - 输入输出中间状态的类型不同
- sum(), min(), max()
- 全窗口函数 - full window functions : 先把窗口所有数据收集起来,等到计算的时候会遍历所有的数据
- apply(windowFunction)
- process(processWindowFunction) - processWindowFunction 比 windowFunction 提供了更多的上下文信息
- aggregate(preAggregator, windowFunction)
- aggregate(preAggregator, ProcessWindowFunction)
- reduce(preAggregator, windowFunction)
- reduce(preAggregator, ProcessWindowFunction)
增量聚合函数 更加符合流式处理的架构,但是 增量聚合函数 有局限,仅能保存一个简单的状态信息。
比如求中位数、根据排序后的数据进行复杂计算,增量聚合函数 并不适合这些场景。
6.2.3.1 Incremental aggregation functions
增量聚合函数 - reduce - Demo
package com.mso.flink.stream.window
import org.apache.flink.api.common.functions.ReduceFunction
import org.apache.flink.streaming.api.scala._
import org.apache.flink.streaming.api.windowing.time.Time
// 输入数据的样例类
case class SensorReading(id: String, timestamp: Long, temperature: Double)
object IncrementalWindowDemo {
def main(args: Array[String]): Unit = {
val environment: StreamExecutionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment
val sourceStream: DataStream[String] = environment.socketTextStream("localhost", 7777)
// Transform
val sourceDataStream: DataStream[SensorReading] = sourceStream
.map((data: String) => {
val dataArray: Array[String] = data.split(",")
SensorReading(dataArray(0), dataArray(1).toLong, dataArray(2).toDouble)
})
val resultStream: DataStream[SensorReading] = sourceDataStream
.keyBy(data => data.id)
.timeWindow(Time.seconds(15), Time.seconds(5))
.reduce(new MyReduceFunction)
resultStream.print()
environment.execute("Incremental window demo")
}
}
// 自定义 Reduce 方法
private class MyReduceFunction extends ReduceFunction[SensorReading] {
override def reduce(t: SensorReading, t1: SensorReading): SensorReading = {
SensorReading(t.id, t.timestamp.max(t1.timestamp), t.temperature.min(t1.temperature))
}
}
此处 demo 为滑动时间窗口,窗口大小为 15s,每 5s 滑动一次。
从测试结果中可发现,keyBy 后的每一个 key 都会出现三次,输出三次后会被丢弃,且输出的数据并未按照输入数据输出。
每个 key 会输出三次,是因为按照我们设置的窗口大小,每 5S 滑动一次(会输出一次),数据输出次数等于窗口重叠次数。每一个 key 会存在于三个窗口中,在三次滑动达到 窗口大小后,这条数据就会被丢弃。
输出数据乱序是因为,window 是在聚合端开了个桶,所有数据都在同一个桶内进行计算,按照数据计算的先后顺序进行输出。
6.2.3.2 Full window functions
全窗口函数 - apply - Demo
package com.mso.flink.stream.window
import org.apache.flink.streaming.api.scala._
import org.apache.flink.streaming.api.scala.function.WindowFunction
import org.apache.flink.streaming.api.windowing.time.Time
import org.apache.flink.streaming.api.windowing.windows.TimeWindow
import org.apache.flink.util.Collector
object FullWindowDemo {
def main(args: Array[String]): Unit = {
val environment: StreamExecutionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment
val sourceStream: DataStream[String] = environment.socketTextStream("localhost", 7777)
// Transform
val sourceDataStream: DataStream[SensorReading] = sourceStream
.map((data: String) => {
val dataArray: Array[String] = data.split(",")
SensorReading(dataArray(0), dataArray(1).toLong, dataArray(2).toDouble)
})
val resultStream: DataStream[(String, Long, Int)] = sourceDataStream
.keyBy(data => data.id)
.timeWindow(Time.seconds(15), Time.seconds(5))
.apply(new MyWindowFunction)
resultStream.print("Full window demo")
environment.execute()
}
}
// 自定义全窗口函数。 不同于 ReduceFunction 和 MapFunction 仅能处理一条数据,全窗口函数可以处理一堆数据
/**
* Base interface for functions that are evaluated over keyed (grouped) windows.
* trait WindowFunction[IN, OUT, KEY, W <: Window] extends Function with Serializable {
* tparam IN The type of the input value.
* tparam OUT The type of the output value.
* tparam KEY The type of the key.
*/
class MyWindowFunction extends WindowFunction[SensorReading, (String, Long, Int), String, TimeWindow] {
override def apply(key: String, window: TimeWindow, input: Iterable[SensorReading], out: Collector[(String, Long, Int)]): Unit = {
// 获取当前时间窗的 起始时间 和 数据量
// 注意此处可发现窗口的起始点为 h/min/s 取整的时间,不是程序启动时间
out.collect((key, window.getStart, input.size))
// val id: String = input.head.id
// val id: String = key.asInstanceOf[Tuple1[String]].f0
}
}
全窗口函数 - process - Demo
package com.practice.flink.stream.demo6
import com.amazonaws.services.ecr.model.EmptyUploadException
import org.apache.flink.api.java.tuple.Tuple
import org.apache.flink.streaming.api.datastream.DataStreamSink
import org.apache.flink.streaming.api.scala.function.ProcessWindowFunction
import org.apache.flink.streaming.api.scala.{DataStream, StreamExecutionEnvironment}
import org.apache.flink.streaming.api.windowing.windows.GlobalWindow
import org.apache.flink.util.Collector
object CountWindowAvg {
def main(args: Array[String]): Unit = {
val environment: StreamExecutionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment
// Source
import org.apache.flink.api.scala._
// 使用 nc -lk 手动生成一些数字进行计算
val sourceStream: DataStream[String] = environment.socketTextStream("test01", 9002)
// Transform & Sink
val avgResult: DataStreamSink[Double] = sourceStream.map(x => (1, x.toInt))
.keyBy(0)
.countWindow(3) // 滚动窗口。窗口大小为 3条 数据
// .countWindow(5, 3) // 滑动窗口,窗口大小为 5条 数据,每 3条 数据向前滑动
.process(new MyProcessWindow)
.print()
// execute
environment.execute()
}
}
/**
* IN - (Int, Int) : The type of the input value.
* OUT - Double : The type of the output value.
* KEY - Tuple : The type of the key.
* W - GlobalWindow : The type of the window.
*/
private class MyProcessWindow extends ProcessWindowFunction[(Int, Int), Double, Tuple, GlobalWindow] {
/**
*
* @param key 定义我们聚合的 key
* @param context 上下文对象。用于将数据进行一些上下文的获取
* @param elements 传入的数据
* @param out
*/
override def process(key: Tuple, context: Context, elements: Iterable[(Int, Int)], out: Collector[Double]): Unit = {
// 用于统计一共有多少条数据
var totalNum: Int = 0;
// 用于定义我们所有数据的累加的和
var totalResult: Int = 0;
for(element <- elements){
totalNum+=1
totalResult+=element._2
}
out.collect(totalResult/totalNum)
}
}
6.3 总结
Window 操作主要有两个操作
- 窗口分配器 - .window() : 窗口分配的桶是什么样的
- 窗口函数 - reduce/aggregate/apply/process : 在桶内对数据进行什么操作
window 类型
- 通过窗口分配器来决定,分 时间窗口 和 计数窗口
- 按照窗口起止时间来决定,分 滑动窗口、滚动窗口 和 会话窗口
注:滑动窗口中,每条数据可以属于 size/slide 个窗口。且滑动步长是多大,就多久输出一次。
若 size 远大于 slide 会造成同一条数据存在于多个桶中,会占用大量的资源。
会话窗口,窗口长度不固定,需要指定间隔时间,
窗口函数 - 窗口函数是基于当前窗口内的数据的,是有界数据集的计算,通常只在窗口关闭时输出一次。
window function 定义了要对窗口中收集的数据做的计算操作,分为以下两类:
- 增量聚合函数 - incremental aggregation functions : 每条数据到来就进行计算,保持一个简单的状态
- reduce(reduceFunction) - 输入输出中间状态的类型相同
- aggregate(aggregateFunction) - 输入输出中间状态的类型不同
- sum(), min(), max()
- 全窗口函数 - full window functions : 先把窗口所有数据收集起来,等到计算的时候会遍历所有的数据
- apply(windowFunction)
- process(processWindowFunction) - processWindowFunction 比 windowFunction 提供了更多的上下文信息
- aggregate(preAggregator, windowFunction)
- aggregate(preAggregator, ProcessWindowFunction)
- reduce(preAggregator, windowFunction)
- reduce(preAggregator, ProcessWindowFunction)
程序默认的时间语义,是 Processing Time