性能优化专题 - MySql 性能优化 - 01 - MySql索引机制
目录导航
-
- 前言
- MySql之索引入门
-
- 索引的使用
- 数据结构之树
- 索引
- MySql默认数据结构
- MySql B+Tree索引体现形式
-
- MyISAM引擎
- Innodb引擎
- MyISAM引擎和InnoDB引擎的区别
- 写在最后
前言
性能优化专题共计四个部分,分别是:
- Tomcat 性能优化
- MySql 性能优化
- JVM 性能优化
- 性能测试
本节是性能优化专题第二部分 —— MySql 性能优化篇,共计四个小节,分别是:
- MySql索引机制
- MySql运行机理
- 深入理解InnoDB
- MySql调优
本节重点:
➢ 索引是谁实现的
➢ 索引的定义
➢ 为什么选择B+Tree
➢ B+Tree在两大引擎中如何体现
MySql之索引入门
索引的使用
关于索引的基础语法,增删改查功能,这里转发了一篇博客:
mysql索引的使用【转载】
索引分为:
- 单列索引:节点中的关键字[name]
- 联合索引: 节点中的关键字[name,phone]
单列索引是特殊的联合索引。
覆盖索引:如果查询列可通过索引节点中的关键字直接返回,则该索引称之为覆盖索引,覆盖索引可减少数据库IO,将随机IO变为顺序IO,可提高查询性能
联合索引选择原则:
- 经常用的列优先【最左匹配原则】
- 选择性(离散度)高的列优先【离散度高原则】
- 宽度小的列优先【最小空间原则】
数据结构之树
与树相关的数据结构知识,我这里给大家提供了 二叉树、平衡二叉树 、红黑树、B+树以及二叉树遍历算法相关总结,在此转载声明!如果同学们不了解这里的知识点,更需要先掌握才能掌握,以便理解后续的MySql索引机制。
1. 二叉树遍历算法【转载】
- 前序遍历
- 中序遍历
- 后序遍历
2. 二叉树与平衡二叉树【转载】
二叉树的缺陷:
- 顺序存储可能会浪费空间(在非完全二叉树的时候),但是读取某个指定的节点的时候效率比较高O(0)
- 链式存储相对二叉树比较大的时候浪费空间较少,但是读取某个指定节点的时候效率偏低O(nlogn)
3. 平衡二叉树与红黑树【转载】
4. B树与B+树【转载】
5. 【图文】 红黑树,B树,B+树 本质区别及应用场景【转载】
叶子结点是离散数学中的概念。一棵树当中没有子结点(即度为0)的结点称为叶子结点,简称“叶子”。 叶子是指出度为0的结点,又称为终端结点。
int leaf(BiTree root){
static int leaf_count = 0; --->在递归调用时只进行一次初始化。
if (NULL != root) {
leaf(root->lchild);
leaf(root->rchild);
if (root->lchild == NULL & root->rchild == NULL)
leaf_count++;
}
return leaf_count;
}
索引
正确的创建合适的索引,是提升数据库查询性能的基础
什么是索引?
索引是为了加速对表中数据行的检索而创建的一种分散存储的数据结构
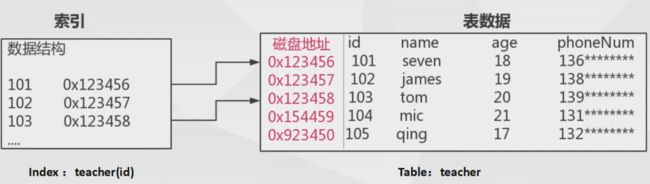
索引的优点:
- 极大的减少存储引擎需要扫描的数据量
- 可以把随机IO变成顺序IO
- 在分组排序时使用索引,可以避免使用临时表
MySql默认数据结构
使用Hash存储,时间复杂度为log(N),使用B+Tree存储,时间复杂度为O(1),为什么MySql选择B+树作为默认数据结构?
我们使用在线数据结构解析工具,查看二叉树的排列情况:
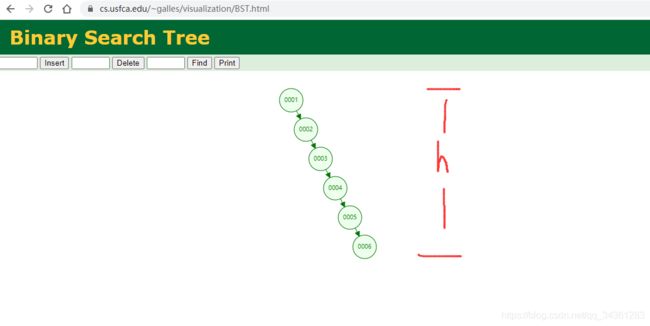
若仅仅是 select * from table where id=45 , hash算法可以轻易实现,但若是select * from table where id<6 , 就不好使了,它们的查找方式就类似于"全表扫描",因为他们的高度是不可控的(如上图)。B+Tree的高度是可控的,mysql通常是3到5层。注意:B+Tree只在最末端叶子节点存数据,叶子节点是以链表的形势互相指向的。
- B+树扫库、表能力更强
- B+树的磁盘读写能力更强
- B+树的排序能力更强
- B+树的查询效率更加稳定
MySql B+Tree索引体现形式
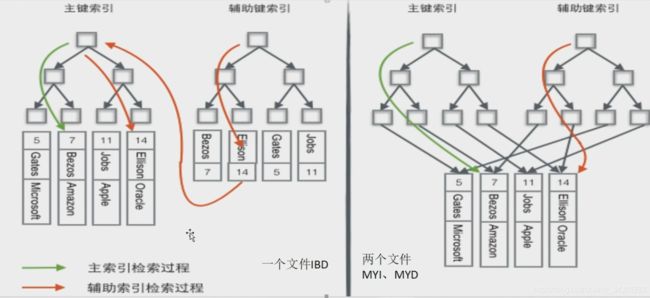
MyISAM引擎
Myisam引擎(非聚集索引)
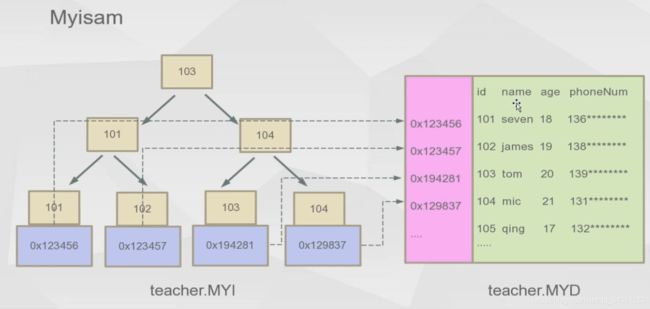
MySql中B+树索引体现形式-MyISAM
若以这个引擎创建数据库表Create table user (…..),它实际是生成三个文件:
- user.myi 索引文件
- user.myd 数据文件
- user.frm 数据结构类型
如下图:当我们执行 select * from user where id = 1的时候,它的执行流程。
-
查看该表的myi文件有没有以id为索引的索引树。
-
根据这个id索引找到叶子节点的id值,从而得到它里面的数据地址。(叶子节点存的是索引和数据地址)。
-
根据数据地址去myd文件里面找到对应的数据返回出来。
Innodb引擎
Innodb引擎(聚集索引)
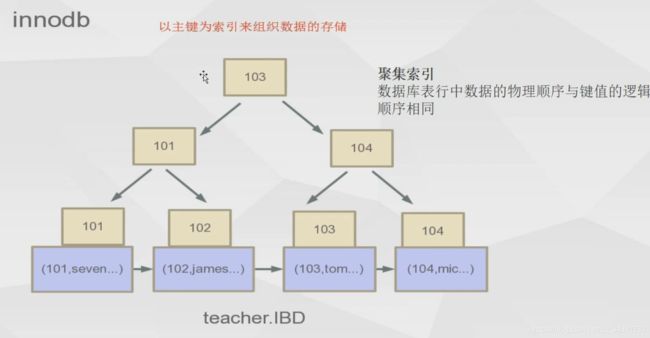
若以这个引擎创建数据库表Create table user (…..),它实际是生成两个文件:
- user.ibd 索引文件
- user.frm 数据结构类型
因为innodb引擎创建表默认就是以主键为索引,所以不需要myi文件
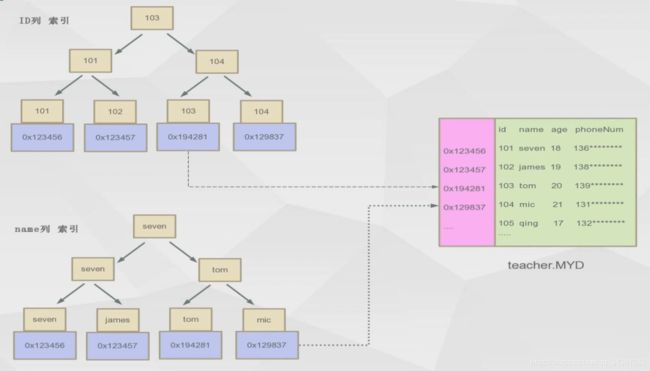
很显然它与myisam最大的区别是将整条数据存在叶子节点,而不是地址。(叶子节点存的是主键索引和数据信息)
若此时,你在其他列创建索引例如name,它就会另外创建一个以name为索引的索引树,(叶子节点存的是索引和主键索引)。
你在执行select * from user where name = ‘zhangsan’,他的执行过程如下:
-
找到name索引树
-
根据name的值找到该树下叶子的name索引和主键值
-
用主键值去主键索引树去叶子节点到该条数据信息
MyISAM引擎和InnoDB引擎的区别
- MyISAM:支持全文索引;不支持事务;它是表级锁;会保存表的具体行数.
- InnoDB:5.6以后才有全文索引;支持事务;它是行级锁;不会保存表的具体行数.
不用事务的时候,count计算多的时候适合myisam引擎。对可靠性要求高就是用innodby引擎。推荐用InnoDB引擎.
加了索引之后能够大幅度的提高查询速度,但是索引也不是越多越好,一方面它会占用存储空间,另一方面它会使得写操作变得很慢。通常我们对查询次数比较频繁,值比较多的列才建索引。
例如:select * from user where sex = "famale", 这个就不需要建立索引,因为性别一共就两个值,查询本身就是比较快的。
select * from user where user_id = 1995 ,这个就需要建立索引,因为user_id的值是非常多的。
写在最后
本节Tips:
- 索引列的数据长度能少则少。
- 索引一定不是越多越好,越全越好,一定是建立合适的
- 匹配列前缀可用到索引 like 999%,like %999%,like %999用不到索引
- where条件中not in 和<> 操作无法使用索引
- 匹配范围值,order by也可以用到索引
- 多用指定列查询,只返回自己想到的数据里,少用select *
- 联合索引中如果不是按照索引最左列开始查找,无法使用索引
- 联合索引中精确匹配1最左前列并范围匹配另外一列可以用到索引
- 联合索引中如果查询中有某个列的范围查询,则其右边的所有列都无法使用索引
参考链接:
理解Mysql底层B+tree索引机制
更多架构知识,欢迎关注本套系列文章:Java架构师成长之路