大数据简单面试题
面试题
1、HashMap 和 Hashtable 区别
HashMap和Hashtable的存储和遍历都是无序的!
- 继承的类不同:HashMap继承的是AbstractMap类;Hashtable 继承Dictionary类。但是都实现了Map接口。
- 线程安全问题:hashmap是非线程安全的,底层是一个Entry数组,put进来的数据,会计算其hash值,然后放到对应的bucket上去,当发生hash冲突的时候,hashmap是采用链表的方式来解决的,在对应的数组位置存放链表的头结点,对链表而言,新加入的节点会从头结点加入;Hashtable是线程安全的,是个同步容器,其中实现线程安全的方式就是给每个方法都加上Synchronized关键字。
- 关于contains方法:HashMap没有Hashtable的contains方法,有的是containsValue和containsKey;Hashtable有contains,containsValue和containsKey三个方法,其中contains和containsValue功能相同。
- key和value是否可以为null:HashMap和HashTable都不能包含重复的key,但是value可以重复。HashTable,kv都不允许出现null,但是由于kv都是Object类型的对象,put(null,null)操作编译可以通过,但是在运行的时候会抛出NullPointerException(空指针)异常;而HashMap,null可以作为k,但是这样的k只有一个,而v的话,可以有多个k的v为null值。当get方法返回null值的时候,可能是没有该k,也有可能该键对应值为null,所以不能用get方法查询HashMap存不存在指定的k,而应该用containsKey方法判断。
- 遍历方式的不同:HashMap使用的是keySet、entrySet、values和entrySet+Iterator;Hashtable使用的是keySet、keys+Enumeration、entrySet+Iterator和elements;
- hash值不同:HashTable直接使用对象的hashCode;HashMap重新计算hash值。(h = key.hashCode()) ^ (h >>> 16);
- 内部实现的数组初始化和扩容不同:在不指定容量的情况下,HashTable的默认容量为11,而HashMap为16;Hashtable不要求底层数组的容量一定要为2的整数次幂,所以扩容时,将容量变为原来的2倍加1。而HashMap则要求一定为2的整数次幂,扩容时将容量变为原来的2倍。
2、Java 垃圾回收机制和生命周期
对象是否会被回收的两个经典算法:引用计数法,和可达性分析算法。
引用计数法
简单的来说就是判断对象的引用数量。实现方式:给对象共添加一个引用计数器,每当有引用对他进行引用时,计数器的值就加1,当引用失效,也就是不在执行此对象是,他的计数器的值就减1,若某一个对象的计数器的值为0,那么表示这个对象没有人对他进行引用,也就是意味着是一个失效的垃圾对象,就会被gc进行回收。
但是这种简单的算法在当前的jvm中并没有采用,原因是他并不能解决对象之间循环引用的问题。
假设有A和B两个对象之间互相引用,也就是说A对象中的一个属性是B,B中的一个属性时A,这种情况下由于他们的相互引用,从而是垃圾回收机制无法识别。

可达性分析(Reachability Analysis)
从 GC Roots 开始向下搜索,搜索所走过的路径称为引用链。当一个对象到 GC Roots 没有任何引用链相连时,则证明此对象是不可用的。不可达对象。
1)标记-清除算法
标记-清除(Mark-Sweep)算法,是现代垃圾回收算法的思想基础。
标记-清除算法将垃圾回收分为两个阶段:标记阶段和清除阶段。
一种可行的实现是,在标记阶段,首先通过根节点,标记所有从根节点开始的可达对象。因此,未被标记的对象就是未被引用的垃圾对象(好多资料说标记出要回收的对象,其实明白大概意思就可以了)。然后,在清除阶段,清除所有未被标记的对象。

-
缺点:
-
- 1、效率问题,标记和清除两个过程的效率都不高。
- 2、空间问题,标记清除之后会产生大量不连续的内存碎片,空间碎片太多可能会导致以后在程序运行过程中需要分配较大的对象时,无法找到足够的连续内存而不得不提前触发另一次垃圾收集动作。
2)标记-整理算法
标记整理算法,类似与标记清除算法,不过它标记完对象后,不是直接对可回收对象进行清理,而是让所有存活的对象都向一端移动,然后直接清理掉边界以外的内存。

-
优点:
-
- 1、相对标记清除算法,解决了内存碎片问题。
- 2、没有内存碎片后,对象创建内存分配也更快速了(可以使用TLAB进行分配)。
-
缺点:
-
- 1、效率问题,(同标记清除算法)标记和整理两个过程的效率都不高。
3)复制算法
复制算法,可以解决效率问题,它将可用内存按容量划分为大小相等的两块,每次只使用其中的一块,当这一块内存用完了,就将还存活着的对象复制到另一块上面,然后再把已经使用过的内存空间一次清理掉,这样使得每次都是对整个半区进行内存回收,内存分配时也就不用考虑内存碎片等复杂情况,只要移动堆顶指针,按顺序分配内存即可(还可使用TLAB进行高效分配内存)。

-
图的上半部分是未回收前的内存区域,图的下半部分是回收后的内存区域。通过图,我们发现不管回收前还是回收后都有一半的空间未被利用。
-
优点:
-
- 1、效率高,没有内存碎片。
-
缺点:
-
- 1、浪费一半的内存空间。
- 2、复制收集算法在对象存活率较高时就要进行较多的复制操作,效率将会变低。
4)分代收集算法
当前商业虚拟机都是采用分代收集算法,它根据对象存活周期的不同将内存划分为几块,一般是把 Java 堆分为新生代和老年代,然后根据各个年代的特点采用最适当的收集算法。
-
在新生代中,每次垃圾收集都发现有大批对象死去,只有少量存活,就选用复制算法。
-
而老年代中,因为对象存活率高,没有额外空间对它进行分配担保,就必须使用“标记清理”或者“标记整理”算法来进行回收。
-
图的左半部分是未回收前的内存区域,右半部分是回收后的内存区域。
-
对象分配策略:
-
- 对象优先在 Eden 区域分配,如果对象过大直接分配到 Old 区域。
- 长时间存活的对象进入到 Old 区域。
-
改进自复制算法
- 现在的商业虚拟机都采用这种收集算法来回收新生代,IBM 公司的专门研究表明,新生代中的对象 98% 是“朝生夕死”的,所以并不需要按照
1:1的比例来划分内存空间,而是将内存分为一块较大的 Eden 空间和两块较小的 Survivor 空间,每次使用 Eden 和其中一块 Survivor 。当回收时,将 Eden 和 Survivor 中还存活着的对象一次性地复制到另外一块 Survivor 空间上,最后清理掉 Eden 和刚才用过的 Survivor 空间。 - HotSpot 虚拟机默认 Eden 和 2 块 Survivor 的大小比例是
8:1:1,也就是每次新生代中可用内存空间为整个新生代容量的 90%(80%+10%),只有 10% 的内存会被“浪费”。当然,98% 的对象可回收只是一般场景下的数据,我们没有办法保证每次回收都只有不多于 10% 的对象存活,当 Survivor 空间不够用时,需要依赖其他内存(这里指老年代)进行分配担保(Handle Promotion)。
- 现在的商业虚拟机都采用这种收集算法来回收新生代,IBM 公司的专门研究表明,新生代中的对象 98% 是“朝生夕死”的,所以并不需要按照
对象分配规则:
- 对象优先分配在 Eden 区。
如果 Eden 区无法分配,那么尝试把活着的对象放到 Survivor0 中去(Minor GC)ps:清除 Eden、Survivor 区,就是 Minor GC 。总结来说,分配的顺序是:新生代(Eden => Survivor0 => Survivor1)=> 老年代
-
- 如果 Survivor1 可以放入,那么放入 Survivor1 之后清除 Eden 和 Survivor0 ,之后再把 Survivor1 中的对象复制到 Survivor0 中,保持 Survivor1 一直为空。
- 如果 Survivor1 不可以放入,那么直接把它们放入到老年代中,并清除 Eden 和 Survivor0 ,这个过程也称为分配担保。
- 如果 Survivor0 可以放入,那么放入之后清除 Eden 区。
- 如果 Survivor0 不可以放入,那么尝试把 Eden 和 Survivor0 的存活对象放到 Survivor1 中。
-
大对象直接进入老年代(大对象是指需要大量连续内存空间的对象)。
这样做的目的是,避免在 Eden 区和两个 Survivor 区之间发生大量的内存拷贝(新生代采用复制算法收集内存)。
-
长期存活的对象进入老年代。
虚拟机为每个对象定义了一个年龄计数器,如果对象经过了 1 次 Minor GC 那么对象会进入 Survivor 区,之后每经过一次 Minor GC 那么对象的年龄加 1 ,知道达到阀值对象进入老年区。
-
动态判断对象的年龄。
为了更好的适用不同程序的内存情况,虚拟机并不是永远要求对象的年龄必须达到 MaxTenuringThreshold 才能晋升老年代。如果 Survivor 区中相同年龄的所有对象大小的总和大于 Survivor 空间的一半,年龄大于或等于该年龄的对象可以直接进入老年代。
-
空间分配担保。
每次进行 Minor GC 时,JVM 会计算 Survivor 区移至老年区的对象的平均大小,如果这个值大于老年区的剩余值大小则进行一次 Full GC ,如果小于检查 HandlePromotionFailure 设置,如果
true则只进行 Monitor GC ,如果false则进行 Full GC 。
如下是一张对象创建时,分配内存的图:
3、怎么解决 Kafka 数据丢失的问题
Broker端:
Kafka 某个 Broker 宕机,然后重新选举 Partition 的 leader,此时其他的 follower 刚好还有些数据没有同步,结果此时 leader 挂了,然后选举某个 follower 成 leader 之后,就少了一些数据。
- 给 Topic 设置
replication.factor参数:这个值必须大于 1,要求每个 partition 必须有至少 2 个副本。 - 在 Producer 端设置
acks=all:这个是要求Producer 需要等待 ISR 中的所有 Follower 都确认接收到数据后才算一次发送完成。 - 但是如果Broker 集群里,ISR中只有leader(其他节点都和zookeeper断开连接,或者是都没追上)的情况。此时,
acks=all和acks=1就等价了。所以在Borker端设置min.insync.replicas参数:这个值必须大于 1 ,这个是要求一个 leader 至少感知到有至少一个 follower 还保持连接,没掉队,这样才能确保 leader 挂了至少还有一个 follower 。 - 关闭unclean leader选举,即不允许非ISR中的副本被选举为leader,以避免数据丢失
某种状态下,follower2副本落后leader副本很多,并且也不在leader副本和follower1副本所在的ISR(In-Sync Replicas)集合之中。follower2副本正在努力的追赶leader副本以求迅速同步,并且能够加入到ISR中。但是很不幸的是,此时ISR中的所有副本都突然下线,情形如下图所示:

此时follower2副本还在,就会进行新的选举,不过在选举之前首先要判断unclean.leader.election.enable参数的值。如果unclean.leader.election.enable参数的值为false,那么就意味着非ISR中的副本不能够参与选举,此时无法进行新的选举,此时整个分区处于不可用状态。如果unclean.leader.election.enable参数的值为true,那么可以从非ISR集合中选举follower副本称为新的leader。

我们进一步考虑unclean.leader.election.enable参数为true的情况,在上面的这种情形中follower2副本就顺其自然的称为了新的leader。随着时间的推进,新的leader副本从客户端收到了新的消息,如上图所示。
此时,原来的leader副本恢复,成为了新的follower副本,准备向新的leader副本同步消息,但是它发现自身的LEO比leader副本的LEO还要大。Kafka中有一个准则,follower副本的LEO是不能够大于leader副本的,所以新的follower副本就需要截断日志至leader副本的LEO处。

如上图所示,新的follower副本需要删除消息4和消息5,之后才能与新的leader副本进行同步。之后新的follower副本和新的leader副本组成了新的ISR集合,参考下图。

原本客户端已经成功的写入了消息4和消息5,而在发生日志截断之后就意味着这2条消息就丢失了,并且新的follower副本和新的leader副本之间的消息也不一致。也就是说如果unclean.leader.election.enable参数设置为true,就有可能发生数据丢失和数据不一致的情况,Kafka的可靠性就会降低;而如果unclean.leader.election.enable参数设置为false,Kafka的可用性就会降低。具体怎么选择需要读者更具实际的业务逻辑进行权衡,可靠性优先还是可用性优先。
producer端来说:
-
push为同步,producer.type设置为 sync;
如果是异步会丢失数据,flush是kafka的内部机制,kafka优先在内存中完成数据的交换,然后将数据持久化到磁盘.kafka首先会把数据缓存(缓存到内存中)起来再批量flush.可以通过log.flush.interval.messages和log.flush.interval.ms来配置flush间隔。内存缓冲池过满,内存溢出会让数据写入过快,但是落入磁盘过慢,有可能会造成数据的丢失。
-
设置 retries=MAX(很大很大很大的一个值,无限次重试的意思):这个是要求一旦写入失败,就无限重试,卡在这里了。
Consumer端:
消费者是poll拉取数据进行消费的,唯一导致消费者弄丢数据的情况为,消费到了数据,consumer自动提交offset,让broker以为你已经消费好了数据,但是如果你才刚开始准备处理这个数据就挂了,那么这条数据就丢失了。
high-level版本自动提交 offset
所以说要使用low-level版本关闭自动提交 offset ,在处理完之后自己手动提交 offset ,就可以保证数据不会丢。但是这样的话保证不了消息的幂等性,也就是说,刚处理完还未提交offset,自己就挂了,下一次消费的时候会重复消费数据。所以为了保证幂等性:
- 写库操作,可以先用主键查一下,如果有这条数据就update。
- 写入redis,没问题,直接set幂等。
- 让生产者发送每条数据的时候加一个全局唯一id,消费一条数据先去缓存中查找,缓存可以是写入内存的queue或者是redis,没有这条数据就处理并加入缓存,有这条数据就说明之前消费过,就不处理了。
- 数据库的唯一键约束,保证数据不会重复插入多条,只会报错但是不会有重复数据。
//producer用于压缩数据的压缩类型。默认是无压缩。正确的选项值是none、gzip、snappy。压缩最好用于批量处理,批量处理消息越多,压缩性能越好
props.put("compression.type", "gzip");
//增加延迟
props.put("linger.ms", "50");
//这意味着leader需要等待所有备份都成功写入日志,这种策略会保证只要有一个备份存活就不会丢失数据。这是最强的保证。,
props.put("acks", "all");
//无限重试,直到你意识到出现了问题,设置大于0的值将使客户端重新发送任何数据,一旦这些数据发送失败。注意,这些重试与客户端接收到发送错误时的重试没有什么不同。允许重试将潜在的改变数据的顺序,如果这两个消息记录都是发送到同一个partition,则第一个消息失败第二个发送成功,则第二条消息会比第一条消息出现要早。
props.put("retries ", MAX_VALUE);
props.put("reconnect.backoff.ms ", 20000);
props.put("retry.backoff.ms", 20000);
//关闭unclean leader选举,即不允许非ISR中的副本被选举为leader,以避免数据丢失
props.put("unclean.leader.election.enable", false);
//关闭自动提交offset
props.put("enable.auto.commit", false);
限制客户端在单个连接上能够发送的未响应请求的个数。设置此值是1表示kafka broker在响应请求之前client不能再向同一个broker发送请求。注意:设置此参数是为了避免消息乱序
props.put("max.in.flight.requests.per.connection", 1);
4、zookeeper 是如何保证数据一致性的
Zookeeper 具有如下特性:
- 顺序一致性(有序性)
从同一个客户端发起的事务请求,最终将会严格地按照其发起顺序被应用到 Zookeeper 中去。
有序性是 Zookeeper 中非常重要的一个特性。
-
- 所有的更新都是全局有序的,每个更新都有一个唯一的时间戳,这个时间戳称为zxid(Zookeeper Transaction Id)。
- 而读请求只会相对于更新有序,也就是读请求的返回结果中会带有这个 Zookeeper 最新的 zxid 。
-
原子性
所有事务请求的处理结果在整个集群中所有机器上的应用情况是一致的,即整个集群要么都成功应用了某个事务,要么都没有应用。
- 单一视图
无论客户端连接的是哪个 Zookeeper 服务器,其看到的服务端数据模型都是一致的。
- 可靠性
一旦服务端成功地应用了一个事务,并完成对客户端的响应,那么该事务所引起的服务端状态变更将会一直被保留,除非有另一个事务对其进行了变更。
- 实时性
Zookeeper 保证在一定的时间段内,客户端最终一定能够从服务端上读取到最新的数据状态。
Zookeeper 对于读写请求有所不同:
- 客户端的读请求可以被集群中的任意一台机器处理,如果读请求在节点上注册了监听器,这个监听器也是由所连接的 Zookeeper 机器来处理。
- 对于写请求,这些请求会同时发给其他 Zookeeper 机器并且达成一致后,请求才会返回成功。因此,随着 Zookeeper 的集群机器增多,读请求的吞吐会提高但是写请求的吞吐会下降。
Zookeeper保证了顺序一致性(满足最终一致性)。从整体(read 操作 +write 操作)上来说是 sequential consistency(顺序一致性),写操作实现了 Linearizability(线性一致性:也叫强一致性,或者原子一致性)。
顺序一致性:
从同一个客户端发起的事务请求,最终将会严格地按照其发起顺序被应用到 Zookeeper 中去。
顺序一致性是 Zookeeper 中非常重要的一个特性。
-
- 所有的更新都是全局有序的,每个更新都有一个唯一的时间戳,这个时间戳称为zxid(Zookeeper Transaction Id)。
- 而读请求只会相对于更新有序,也就是读请求的返回结果中会带有这个 Zookeeper 最新的 zxid 。
Paxos的基本思路:(深入解读zookeeper一致性原理)
假设有一个社团,其中有团员、议员(决议小组成员)两个角色
团员可以向议员申请提案来修改社团制度
议员坐在一起,拿出自己收到的提案,对每个提案进行投票表决,超过半数通过即可生效
为了秩序,规定每个提案都有编号ID,按顺序自增
每个议员都有一个社团制度笔记本,上面记着所有社团制度,和最近处理的提案编号,初始为0
投票通过的规则:
新提案ID 是否大于 议员本中的ID,是议员举手赞同
如果举手人数大于议员人数的半数,即让新提案生效
例如:
刚开始,每个议员本子上的ID都为0,现在有一个议员拿出一个提案:团费降为100元,这个提案的ID自增为1
每个议员都和自己ID对比,一看 1>0,举手赞同,同时修改自己本中的ID为1
发出提案的议员一看超过半数同意,就宣布:1号提案生效
然后所有议员都修改自己笔记本中的团费为100元
以后任何一个团员咨询任何一个议员:“团费是多少?”,议员可以直接打开笔记本查看,并回答:团费为100元
可能会有极端的情况,就是多个议员一起发出了提案,就是并发的情况
例如
刚开始,每个议员本子上的编号都为0,现在有两个议员(A和B)同时发出了提案,那么根据自增规则,这两个提案的编号都为1,但只会有一个被先处理
假设A的提案在B的上面,议员们先处理A提案并通过了,这时,议员们的本子上的ID已经变为了1,接下来处理B的提案,由于它的ID是1,不大于议员本子上的ID,B提案就被拒绝了,B议员需要重新发起提案
上面就是Paxos的基本思路,对照ZooKeeper,对应关系就是:
团员 -client
议员 -server
议员的笔记本 -server中的数据
提案 -变更数据的请求
提案编号 -zxid(ZooKeeper Transaction Id)
提案生效 -执行变更数据的操作
ZooKeeper中还有一个leader的概念,就是把发起提案的权利收紧了,以前是每个议员都可以发起提案,现在有了leader,大家就不要七嘴八舌了,先把提案都交给leader,由leader一个个发起提案
Paxos算法就是通过投票、全局编号机制,使同一时刻只有一个写操作被批准,同时并发的写操作要去争取选票,只有获得过半数选票的写操作才会被批准,所以永远只会有一个写操作得到批准,其他的写操作竞争失败只好再发起一轮投票
ZooKeeper采用了Zab协议。
Zab协议 zookeeper automatic broadcast 两种模式
- 恢复(选主)模式,可用性 - 当服务重启或者在leader崩溃之后,进入恢复模式,当leader被选举出来且大多数server完成了和leader的状态同步后恢复模式结束。
- 广播模式(同步)一致性
Zab做了如下几条保证,来达到ZooKeeper要求的一致性。
(a) Zab要保证同一个leader的发起的事务要按顺序被apply,同时还要保证只有先前的leader的所有事务都被apply之后,新选的leader才能在发起事务。这个是为了保证每个Server的数据视图的一致性
(b) 一些已经Skip的消息,需要仍然被Skip。
©如果任何一个server按T、T’的顺序提交了事务,那么所有server都必须按T、T’的顺序提交事务。
为了能够实现,Skip已经被skip的消息。我们在Zxid中引入了epoch。
ZooKeeper 采用了递增的事务 id 来识别,所有的 proposal(提议)都在被提出的时候加上了 zxid 。zxid 实际上是一个 64 位数字。
- 高 32 位是 epoch 用来标识 Leader 是否发生了改变,如果有新的 Leader 产生出来,epoch会自增。
- 低 32 位用来递增计数。
当新产生的 peoposal 的时候,会依据数据库的两阶段过程,首先会向其他的 Server 发出事务执行请求,如果超过半数的机器都能执行并且能够成功,那么就会开始执行。
假设ZK集群由三台机器组成,Server1、Server2、Server3。Server1为Leader,他生成了三条Proposal,P1、P2、P3。但是在发送完P1之后,Server1就挂了。

Server1挂掉之后,Server3被选举成为Leader,因为在Server3里只有一条Proposal—P1。所以,Server3在P1的基础之上又发出了一条新Proposal—P2',由于Leader发生了变换,epoch要加1,所以epoch由原来的0变成了1,而counter要置0。那么,P2'的Zxid为10。

Server2发送完P2'之后,它也挂了。此时Server1已经重启恢复,并再次成为了Leader。那么,Server1将发送还没有被deliver的Proposal—P2和P3。由于Server2中P2'的Zxid为10,而Leader-Server1中P2和P3的Zxid分别为02和03,P2'的epoch位高于P2和P3。所以此时Leader-Server1的P2和P3都会被拒绝,那么我们Zab的第二条保证也就实现了。

5、hadoop 和 spark 在处理数据时,处理出现内存溢出的方法有哪些?
Hadoop来说
堆内存溢出:
mapreduce.map.java.opts=-Xmx2048m 表示jvm堆内存
mapreduce.map.memory.mb=2304 (container的内存)
mapreduce.reduce.java.opts=-=-Xmx2048m (默认参数,表示jvm堆内存)
mapreduce.reduce.memory.mb=2304 (container的内存)
mapreduce.{map|reduce}.java.opts能够通过Xmx设置JVM最大的heap的使用,一般设置为0.75倍的memory.mb,因为需要为java code等预留些空间
栈内存溢出:
StackOverflowError,递归深度太大,在程序中减少递归。
MRAppMaster内存不足:
yarn.app.mapreduce.am.command-opts=-Xmx1024m(默认参数,表示jvm堆内存)
yarn.app.mapreduce.am.resource.mb=1536(container的内存)
Spark来说
Map过程产生大量对象内存溢出:
rdd.map(x => for(i <- 1 to 10000000) yiled i.toString),每个rdd产生大量对象会造成内存溢出问题,通过减少Task大小,也就是先调用repartion方法增加分区再map。
mappartion和foreachpartion:
这两个方法,虽然对比map方法,每个task只执行function1次,会一次把整个partion的数据拿进内存,性能比较高。写入数据库的时候会减少创建数据库连接的次数。但是如果一个partion内数据太多,会直接oom。可以进行repartion操作。
数据不平衡导致内存溢出
repartion操作。
coalesce算子
coalesce合并多个小文件,开始有100个文件,coalesce(10)后产生10个文件,但是coalesce不产生shuffle,之后的所有操作都是变成10个task,每个task一次读取10个文件执行,用的是原先的10倍内存,会oom。解决办法就是开始执行100个task,然后处理后的结果经过用repation(10)的shuffle过程变成10个分区。
shuffle内存溢出
Executor 端的任务并发度,多个同时运行的 Task 会共享 Executor 端的内存,使得单个 Task 可使用的内存减少。
数据倾斜,有可能造成单个 Block 的数据非常的大
RDD中重复数据可以转换成字符串,公用一个对象。
standalone模式下资源分配不均匀
配置了–total-executor-cores 和 –executor-memory 这两个参数,但是没有配置–executor-cores这个参数的话,就有可能导致,每个Executor的memory是一样的,但是cores的数量不同,那么在cores数量多的Executor中,由于能够同时执行多个Task,就容易导致内存溢出的情况。这种情况的解决方法就是同时配置–executor-cores或者spark.executor.cores参数,确保Executor资源分配均匀。
6、java 实现快速排序
public class QuickSort {
public static void quickSort(int[] arr) {
if (arr == null || arr.length < 2) {
return;
}
quicksort(arr, 0, arr.length - 1);
}
private static void quicksort(int[] arr, int l, int r) {
if (l < r) {
//数组中随机一个数做划分值
swap(arr, l + (int)(Math.random() * (r - l +1)), r);
int[] p = partition(arr, l, r);
quickSort(arr, l, p[0] - 1);
quickSort(arr, p[1] + 1, r);
}
}
public static int[] partition(int[] arr, int l, int r) {
int less = l - 1;
int more = r;
while (l < more) {
if (arr[l] < arr[r]) {
swap(arr, ++less, l++);
} else if (arr[l] > arr[r]) {
swap(arr, --more, l);
} else {
l++;
}
}
swap(arr, more, r);
// 等于区域的下标位置
return new int[]{
less + 1, more};
}
private static void swap(int[] arr, int i, int j) {
int tmp = arr[i];
arr[i] = arr[j];
arr[j] = tmp;
}
}
7、设计微信群发红包数据库表结构(包含表名称、字段名称、类型)
drop table if exists wc_groupsend_rp;
create external table wc_groupsend_rp (
imid string, --设备ID
wcid string, --微信号
wcname string, --微信名
wcgroupName string, --群名称
rpamount double, --红包金额
rpid string, --红包标识
rpcount int, --红包数量
rptype int, --红包类型 比如1拼手气红包,2为普通红包,3为指定人领取红包
giverpdt string, --发红包时间
setuprpdt string, --创建红包时间 点击红包按钮的时间 paydt string, --支付时间
) COMMENT '群发红包表'
PARTITIONED BY (`giverpdt` string)
row format delimited fields terminated by '\t';
create external table wc_groupcash_rp (
rpid string, --红包标识
imid string, --设备ID
wcid string, --微信号
wcname string, --微信名
wcgroupName string, --群名称
cashdt stirng, --红包领取时间 每领取一次更新一条数据
cashcount int, --领取人数
cashamount double, --领取金额
cashwcid string, --领取人的微信
cashwcname string, --领取人微信昵称
cashsum double, --已领取总金额
) COMMENT '红包领取表'
PARTITIONED BY (`rpid` string)
row format delimited fields terminated by '\t';
8、如何选型:业务场景、性能要求、维护和扩展性、成本、开源活跃度
9、spark 调优
-
算子调优
算子调优之filter过后使用coalesce减少分区数量.xls
算子调优之MapPartitions提升Map类操作性能.xls
算子调优之reduceByKey本地聚合介绍.xls
算子调优之使用foreachPartition优化写数据库性能.xls
[算子调优之使用repartition解决Spark SQL低并行度的性能问题.xls](D:\Java\大数据\知识星球\SparkStormHadoop\spark\spark调优\算子调优之使用repartition解决Spark SQL低并行度的性能问题.xls)
-
并行度和广播变量
性能调优之在实际项目中广播大变量.xls
性能调优之在实际项目中调节并行度.xls
( 性能调优之在实际项目中分配更多资源.xls ,
性能调优之在实际项目中使用fastutil优化数据格式.xls ,
性能调优之在实际项目中使用Kryo序列化.xls ,
性能调优之在实际项目中调节数据本地化等待时长.xls ,
性能调优之在实际项目中重构RDD架构以及RDD持久化.xls )
- Shuffle 调优
Shuffle调优之原理概述.xls
Shuffle调优之HashShuffleManager与SortShuffleManager.xls
Shuffle调优之合并map端输出文件.xls
Shuffle调优之调节map端内存缓冲与reduce端内存占比.xls
JVM调优之调节executor堆外内存与连接等待时长.xls
JVM调优之原理概述以及降低cache操作的内存占比.xls
1)使用foreachPartitions替代foreach。
原理类似于“使用mapPartitions替代map”,也是一次函数调用处理一个partition的所有数据,而不是一次函数调用处理一条数据。在实践中发现,foreachPartitions类的算子,对性能的提升还是很有帮助的。比如在foreach函数中,将RDD中所有数据写MySQL,那么如果是普通的foreach算子,就会一条数据一条数据地写,每次函数调用可能就会创建一个数据库连接,此时就势必会频繁地创建和销毁数据库连接,性能是非常低下;但是如果用foreachPartitions算子一次性处理一个partition的数据,那么对于每个partition,只要创建一个数据库连接即可,然后执行批量插入操作,此时性能是比较高的。实践中发现,对于1万条左右的数据量写MySQL,性能可以提升30%以上。
2)设置num-executors参数
参数说明:该参数用于设置Spark作业总共要用多少个Executor进程来执行。Driver在向YARN集群管理器申请资源时,YARN集群管理器会尽可能按照你的设置来在集群的各个工作节点上,启动相应数量的Executor进程。这个参数非常之重要,如果不设置的话,默认只会给你启动少量的Executor进程,此时你的Spark作业的运行速度是非常慢的。
参数调优建议:该参数设置的太少,无法充分利用集群资源;设置的太多的话,大部分队列可能无法给予充分的资源。针对数据交换的业务场景,建议该参数设置1-5。
3)设置executor-memory参数
参数说明:该参数用于设置每个Executor进程的内存。Executor内存的大小,很多时候直接决定了Spark作业的性能,而且跟常见的JVM OOM异常也有直接的关联。
参数调优建议:针对数据交换的业务场景,建议本参数设置在512M及以下。
4) executor-cores
参数说明:该参数用于设置每个Executor进程的CPU core数量。这个参数决定了每个Executor进程并行执行task线程的能力。因为每个CPU core同一时间只能执行一个task线程,因此每个Executor进程的CPU core数量越多,越能够快速地执行完分配给自己的所有task线程。
参数调优建议:Executor的CPU core数量设置为2~4个较为合适。建议,如果是跟他人共享一个队列,那么num-executors * executor-cores不要超过队列总CPU core的1/3~1/2左右比较合适,避免影响其他人的作业运行。
5) driver-memory
参数说明:该参数用于设置Driver进程的内存。
参数调优建议:Driver的内存通常来说不设置,或者设置512M以下就够了。唯一需要注意的一点是,如果需要使用collect算子将RDD的数据全部拉取到Driver上进行处理,那么必须确保Driver的内存足够大,否则会出现OOM内存溢出的问题。
6) spark.default.parallelism
参数说明:该参数用于设置每个stage的默认task数量。这个参数极为重要,如果不设置可能会直接影响你的Spark作业性能。
参数调优建议:如果不设置这个参数, Spark自己根据底层HDFS的block数量来设置task的数量,默认是一个HDFS block对应一个task。Spark官网建议的设置原则是,设置该参数为num-executors * executor-cores的2~3倍较为合适,此时可以充分地利用Spark集群的资源。针对数据交换的场景,建议此参数设置为1-10。
7) spark.storage.memoryFraction
参数说明:该参数用于设置RDD持久化数据在Executor内存中能占的比例,默认是0.6。也就是说,默认Executor 60%的内存,可以用来保存持久化的RDD数据。根据你选择的不同的持久化策略,如果内存不够时,可能数据就不会持久化,或者数据会写入磁盘。
参数调优建议:如果Spark作业中,有较多的RDD持久化操作,该参数的值可以适当提高一些,保证持久化的数据能够容纳在内存中。避免内存不够缓存所有的数据,导致数据只能写入磁盘中,降低了性能。但是如果Spark作业中的shuffle类操作比较多,而持久化操作比较少,那么这个参数的值适当降低一些比较合适。如果发现作业由于频繁的gc导致运行缓慢(通过spark web ui可以观察到作业的gc耗时),意味着task执行用户代码的内存不够用,那么同样建议调低这个参数的值。针对数据交换的场景,建议降低此参数值到0.2-0.4。
8) spark.shuffle.memoryFraction
参数说明:该参数用于设置shuffle过程中一个task拉取到上个stage的task的输出后,进行聚合操作时能够使用的Executor内存的比例,默认是0.2。也就是说,Executor默认只有20%的内存用来进行该操作。shuffle操作在进行聚合时,如果发现使用的内存超出了这个20%的限制,那么多余的数据就会溢写到磁盘文件中去,此时就会极大地降低性能。
参数调优建议:如果Spark作业中的RDD持久化操作较少,shuffle操作较多时,建议降低持久化操作的内存占比,提高shuffle操作的内存占比比例,避免shuffle过程中数据过多时内存不够用,必须溢写到磁盘上,降低了性能。如果发现作业由于频繁的gc导致运行缓慢,意味着task执行用户代码的内存不够用,那么同样建议调低这个参数的值。针对数据交换的场景,建议此值设置为0.1或以下。
资源参数参考示例:
./bin/spark-submit \
--master yarn-cluster \
--num-executors 1 \
--executor-memory 512M \
--executor-cores 2 \
--driver-memory 512M \
--conf spark.default.parallelism=2 \
--conf spark.storage.memoryFraction=0.2 \
--conf spark.shuffle.memoryFraction=0.1;
10、Flink和spark的通信框架
spark用netty,flink用akak
11、java 代理
java代理分为静态代理和动态代理和Cglib代理,下面进行逐个说明。
静态代理:
接口类AdminService.java接口
package com.lance.proxy.demo.service;
public interface AdminService {
void update();
Object find();
}
实现类AdminServiceImpl.java
package com.lance.proxy.demo.service;
public class AdminServiceImpl implements AdminService{
public void update() {
System.out.println("修改管理系统数据");
}
public Object find() {
System.out.println("查看管理系统数据");
return new Object();
}
}
代理类AdminServiceProxy.java
package com.lance.proxy.demo.service;
public class AdminServiceProxy implements AdminService {
private AdminService adminService;
public AdminServiceProxy(AdminService adminService) {
this.adminService = adminService;
}
public void update() {
System.out.println("判断用户是否有权限进行update操作");
adminService.update();
System.out.println("记录用户执行update操作的用户信息、更改内容和时间等");
}
public Object find() {
System.out.println("判断用户是否有权限进行find操作");
System.out.println("记录用户执行find操作的用户信息、查看内容和时间等");
return adminService.find();
}
}
测试类StaticProxyTest.java
package com.lance.proxy.demo.service;
public class StaticProxyTest {
public static void main(String[] args) {
AdminService adminService = new AdminServiceImpl();
AdminServiceProxy proxy = new AdminServiceProxy(adminService);
proxy.update();
System.out.println("=============================");
proxy.find();
}
}
输出:
判断用户是否有权限进行update操作
修改管理系统数据
记录用户执行update操作的用户信息、更改内容和时间等
=============================
判断用户是否有权限进行find操作
记录用户执行find操作的用户信息、查看内容和时间等
查看管理系统数据
总结:
静态代理模式在不改变目标对象的前提下,实现了对目标对象的功能扩展。
不足:静态代理实现了目标对象的所有方法,一旦目标接口增加方法,代理对象和目标对象都要进行相应的修改,增加维护成本。
JDK动态代理
为解决静态代理对象必须实现接口的所有方法的问题,Java给出了动态代理,动态代理具有如下特点:
1.Proxy对象不需要implements接口;
2.Proxy对象的生成利用JDK的Api,在JVM内存中动态的构建Proxy对象。需要使用java.lang.reflect.Proxy类
/**
* Returns an instance of a proxy class for the specified interfaces
* that dispatches method invocations to the specified invocation
* handler.
* @param loader the class loader to define the proxy class
* @param interfaces the list of interfaces for the proxy class
* to implement
* @param h the invocation handler to dispatch method invocations to
* @return a proxy instance with the specified invocation handler of a
* proxy class that is defined by the specified class loader
* and that implements the specified interfaces
*/
static Object newProxyInstance(ClassLoader loader, Class[]interfaces,InvocationHandler invocationHandler );
方法参数说明:
a.ClassLoader loader:指定当前target对象使用类加载器,获取加载器的方法是固定的;
b.Class[] interfaces:target对象实现的接口的类型,使用泛型方式确认类型
c.InvocationHandler invocationHandler:事件处理,执行target对象的方法时,会触发事件处理器的方法,会把当前执行target对象的方法作为参数传入。
代码为:
AdminServiceImpl.java和AdminService.java和原来一样
AdminServiceInvocation.java
package com.lance.proxy.demo.service;
import java.lang.reflect.InvocationHandler;
import java.lang.reflect.Method;
public class AdminServiceInvocation implements InvocationHandler {
private Object target;
public AdminServiceInvocation(Object target) {
this.target = target;
}
public Object invoke(Object proxy, Method method, Object[] args) throws Throwable {
System.out.println("判断用户是否有权限进行操作");
Object obj = method.invoke(target);
System.out.println("记录用户执行操作的用户信息、更改内容和时间等");
return obj;
}
}
AdminServiceDynamicProxy.java
package com.lance.proxy.demo.service;
import java.lang.reflect.InvocationHandler;
import java.lang.reflect.Proxy;
public class AdminServiceDynamicProxy {
private Object target;
private InvocationHandler invocationHandler;
public AdminServiceDynamicProxy(Object target,InvocationHandler invocationHandler){
this.target = target;
this.invocationHandler = invocationHandler;
}
public Object getPersonProxy() {
Object obj = Proxy.newProxyInstance(target.getClass().getClassLoader(), target.getClass().getInterfaces(), invocationHandler);
return obj;
}
}
DynamicProxyTest.java
package com.lance.proxy.demo.service;
import java.lang.reflect.InvocationHandler;
import java.lang.reflect.Method;
import java.lang.reflect.Proxy;
public class DynamicProxyTest {
public static void main(String[] args) {
// 方法一
System.out.println("============ 方法一 ==============");
AdminService adminService = new AdminServiceImpl();
System.out.println("代理的目标对象:" + adminService.getClass());
AdminServiceInvocation adminServiceInvocation = new AdminServiceInvocation(adminService);
AdminService proxy = (AdminService) new AdminServiceDynamicProxy(adminService, adminServiceInvocation).getPersonProxy();
System.out.println("代理对象:" + proxy.getClass());
Object obj = proxy.find();
System.out.println("find 返回对象:" + obj.getClass());
System.out.println("----------------------------------");
proxy.update();
// 方法二
System.out.println("============ 方法二 ==============");
AdminService target = new AdminServiceImpl();
AdminServiceInvocation invocation = new AdminServiceInvocation(adminService);
AdminService proxy2 = (AdminService) Proxy.newProxyInstance(target.getClass().getClassLoader(), target.getClass().getInterfaces(), invocation);
Object obj2 = proxy2.find();
System.out.println("find 返回对象:" + obj2.getClass());
System.out.println("----------------------------------");
proxy2.update();
// 方法三
System.out.println("============ 方法三 ==============");
final AdminService target3 = new AdminServiceImpl();
AdminService proxy3 = (AdminService) Proxy.newProxyInstance(target3.getClass().getClassLoader(), target3.getClass().getInterfaces(), new InvocationHandler() {
public Object invoke(Object proxy, Method method, Object[] args) throws Throwable {
System.out.println("判断用户是否有权限进行操作");
Object obj = method.invoke(target3, args);
System.out.println("记录用户执行操作的用户信息、更改内容和时间等");
return obj;
}
});
Object obj3 = proxy3.find();
System.out.println("find 返回对象:" + obj3.getClass());
System.out.println("----------------------------------");
proxy3.update();
}
}
输出结果:
============ 方法一 ==============
代理的目标对象:class com.lance.proxy.demo.service.AdminServiceImpl
代理对象:class com.sun.proxy.$Proxy0
判断用户是否有权限进行操作
查看管理系统数据
记录用户执行操作的用户信息、更改内容和时间等
find 返回对象:class java.lang.Object
----------------------------------
判断用户是否有权限进行操作
修改管理系统数据
记录用户执行操作的用户信息、更改内容和时间等
============ 方法二 ==============
判断用户是否有权限进行操作
查看管理系统数据
记录用户执行操作的用户信息、更改内容和时间等
find 返回对象:class java.lang.Object
----------------------------------
判断用户是否有权限进行操作
修改管理系统数据
记录用户执行操作的用户信息、更改内容和时间等
============ 方法三 ==============
判断用户是否有权限进行操作
查看管理系统数据
记录用户执行操作的用户信息、更改内容和时间等
find 返回对象:class java.lang.Object
----------------------------------
判断用户是否有权限进行操作
修改管理系统数据
记录用户执行操作的用户信息、更改内容和时间等
**缺点:**可以看出静态代理和JDK代理有一个共同的缺点,就是目标对象必须实现一个或多个接口。
Cglib代理
JDK动态代理要求target对象是一个接口的实现对象,假如target对象只是一个单独的对象,并没有实现任何接口,这时候就会用到Cglib代理(Code Generation Library),即通过构建一个子类对象,从而实现对target对象的代理,因此目标对象不能是final类(报错),且目标对象的方法不能是final或static(不执行代理功能)。
Cglib依赖的jar包
<dependency>
<groupId>cglibgroupId>
<artifactId>cglibartifactId>
<version>3.2.10version>
dependency>
代码:
目标对象类AdminCglibService.java
package com.lance.proxy.demo.service;
public class AdminCglibService {
public void update() {
System.out.println("修改管理系统数据");
}
public Object find() {
System.out.println("查看管理系统数据");
return new Object();
}
}
代理类AdminServiceCglibProxy.java
package com.lance.proxy.demo.service;
import net.sf.cglib.proxy.Enhancer;
import net.sf.cglib.proxy.MethodInterceptor;
import net.sf.cglib.proxy.MethodProxy;
import java.lang.reflect.Method;
public class AdminServiceCglibProxy implements MethodInterceptor {
private Object target;
public AdminServiceCglibProxy(Object target) {
this.target = target;
}
//给目标对象创建一个代理对象
public Object getProxyInstance() {
//工具类
Enhancer en = new Enhancer();
//设置父类
en.setSuperclass(target.getClass());
//设置回调函数
en.setCallback(this);
//创建子类代理对象
return en.create();
}
public Object intercept(Object object, Method method, Object[] arg2, MethodProxy proxy) throws Throwable {
System.out.println("判断用户是否有权限进行操作");
Object obj = method.invoke(target);
System.out.println("记录用户执行操作的用户信息、更改内容和时间等");
return obj;
}
}
Cglib代理测试类CglibProxyTest.java
package com.lance.proxy.demo.service;
public class CglibProxyTest {
public static void main(String[] args) {
AdminCglibService target = new AdminCglibService();
AdminServiceCglibProxy proxyFactory = new AdminServiceCglibProxy(target);
AdminCglibService proxy = (AdminCglibService)proxyFactory.getProxyInstance();
System.out.println("代理对象:" + proxy.getClass());
Object obj = proxy.find();
System.out.println("find 返回对象:" + obj.getClass());
System.out.println("----------------------------------");
proxy.update();
}
}
输出结果:
代理对象:class com.lance.proxy.demo.service.AdminCglibService$$EnhancerByCGLIB$$41b156f9
判断用户是否有权限进行操作
查看管理系统数据
记录用户执行操作的用户信息、更改内容和时间等
find 返回对象:class java.lang.Object
----------------------------------
判断用户是否有权限进行操作
修改管理系统数据
记录用户执行操作的用户信息、更改内容和时间等
Spring AOP的代理实现模式,即加入Spring中的target是接口的实现时,就使用JDK动态代理,否是就使用Cglib代理。Spring也可以通过
12、java的内存溢出和内存泄漏
内存溢出和内存泄漏是啥
。内存溢出 out of memory,是指程序在申请内存时,没有足够的内存空间供其使用,出现out of memory;比如申请了一个integer,但给它存了long才能存下的数,那就是内存溢出。
。内存泄露 memory leak,是指程序在申请内存后,无法释放已申请的内存空间。向系统申请分配内存进行使用(new),可是使用完了以后却不归还(delete),结果你申请到的那块内存你自己也不能再访问(也许你把它的地址给弄丢了),而系统也不能再次将它分配给需要的程序。一次内存泄露危害可以忽略,但内存泄露堆积后果很严重,无论多少内存,迟早会被占光。
注:memory leak会最终会导致out of memory!
内存泄漏的分类(按发生方式来分类)
常发性内存泄漏。发生内存泄漏的代码会被多次执行到,每次被执行的时候都会导致一块内存泄漏。
偶发性内存泄漏。发生内存泄漏的代码只有在某些特定环境或操作过程下才会发生。常发性和偶发性是相对的。对于特定的环境,偶发性的也许就变成了常发性的。所以测试环境和测试方法对检测内存泄漏至关重要。
一次性内存泄漏。发生内存泄漏的代码只会被执行一次,或者由于算法上的缺陷,导致总会有一块仅且一块内存发生泄漏。比如,在类的构造函数中分配内存,在析构函数中却没有释放该内存,所以内存泄漏只会发生一次。
隐式内存泄漏。程序在运行过程中不停的分配内存,但是直到结束的时候才释放内存。严格的说这里并没有发生内存泄漏,因为最终程序释放了所有申请的内存。但是对于一个服务器程序,需要运行几天,几周甚至几个月,不及时释放内存也可能导致最终耗尽系统的所有内存。所以,我们称这类内存泄漏为隐式内存泄漏。
1)Java 堆溢出
重现方式,参见 《Java 堆溢出》 文章。https://blog.csdn.net/sells2012/article/details/18654915
另外,Java 堆溢出的原因,有可能是内存泄露,可以使用 MAT 进行分析。
2)虚拟机栈和本地方法栈溢出
由于在 HotSpot 虚拟机中并不区分虚拟机栈和本地方法栈,因此,对于 HotSpot 来说,虽然 -Xoss 参数(设置本地方法栈大小)存在,但实际上是无效的,栈容量只由 -Xss参数设定。
关于虚拟机栈和本地方法栈,在 Java 虚拟机规范中描述了两种异常:
- 如果线程请求的栈深度大于虚拟机所允许的最大深度,将抛出 StackOverflowError 异常。StackOverflowError 不属于 OOM 异常。
- 如果虚拟机在扩展栈时无法申请到足够的内存空间,则抛出 OutOfMemoryError 异常。
重现方式,参见 《OutOfMemoryError 异常 —— 虚拟机栈和本地方法栈溢出》 文章。
https://blog.csdn.net/en_joker/article/details/79727675
3)运行时常量池溢出
因为 JDK7 将常量池和静态变量放到 Java 堆里,所以无法触发运行时常量池溢出。如果想要触发,可以使用 JDK6 的版本。
重现方式,参见 《JVM 内存溢出 - 方法区及运行时常量池溢出》 文章。https://www.niuhp.com/java/jvm-oom-pg.html
4)方法区的内存溢出
因为 JDK8 将方法区溢出,所以无法触发方法区的内存溢出溢出。如果想要触发,可以使用 JDK7 的版本。
重现方式,参见 《Java 方法区溢出》 文章。
https://blog.csdn.net/tanga842428/article/details/52636836
5)元数据区的内存溢出
实际上,方法区的内存溢出在 JDK8 中,变成了元数据区的内存溢出。所以,重现方式,还是参见 《Java 方法区溢出》 文章,只是说,需要增加 -XX:MaxMetaspaceSize=10m VM 配置项。
6)本机直接内存溢出
重现方式,参见 《JVM 内存溢出 —— 直接内存溢出》 文章https://www.niuhp.com/java/jvm-oom-direct.html
另外,非常推荐一篇文章,《Java 内存溢出(OOM)异常完全指南》
https://www.jianshu.com/p/2fdee831ed03
理论上 Java 因为有垃圾回收机制(GC)不会存在内存泄露问题(这也是 Java 被广泛使用于服务器端编程的一个重要原因)。然而在实际开发中,可能会存在无用但可达的对象,这些对象不能被 GC 回收也会发生内存泄露。例如说:
- Hibernate 的 Session(一级缓存)中的对象属于持久态,垃圾回收器是不会回收这些对象的,然而这些对象中可能存在无用的垃圾对象。
- 使用 Netty 的堆外的 ByteBuf 对象,在使用完后,并未归还,导致使用的一点一点在泄露。
垃圾回收机制:
- Java 中对象是采用
new或者反射的方法创建的,这些对象的创建都是在堆(Heap)中分配的,所有对象的回收都是由 Java 虚拟机通过垃圾回收机制完成的。GC 为了能够正确释放对象,会监控每个对象的运行状况,对他们的申请、引用、被引用、赋值等状况进行监控。 - Java 程序员不用担心内存管理,因为垃圾收集器会自动进行管理。
- 可以调用下面的方法之一:
System#gc()或Runtime#getRuntime()#gc(),但 JVM 也可以屏蔽掉显示的垃圾回收调用。
13、hadoop 的组件有哪些?Yarn 的调度器有哪些?
工具类,HDFS(NameNode,DataNode),MapReduce,YARN
FIFO Scheduler,
默认情况下使用的是该调度器,即所有的应用程序都是按照提交的顺序来执行的,这些应用程序都放在一个队列中,只有在前面的一个任务执行完成之后,才可以执行后面的任务,依次执行
缺点:如果有某个任务执行时间较长的话,后面的任务都要处于等待状态,这样的话会造成资源的使用率不高;如果是多人共享集群资源的话,缺点更是明显
Capacoty Scheduler,
集群会有多个队列,按照队列划分资源,每个队列中是按照FIFO方式调度的。如果某个队列的资源使用紧张,但是另一个队列的资源比较空闲,此时可以将空闲的资源暂时借用,但是一旦被借用资源的队列有新的任务提交之后,此时被借用出去的资源将会被释放还回给原队列
Fair Scheduler
作业都是放在作业池中的,默认情况下,每个用户都有自己的作业池,如果该队列池中只有一个任务的话,则该任务会使用该池中的所有资源。提交作业数较多的用户,不会因此而获得更多的集群资源。在特定的时间内未能公平的共享资源,就会终止池中占用过多资源的任务,将空出来的任务槽让给运行资源不足的作业池。
14、hadoop 的 shuffle 过程
Map端
map函数开始产生输出时,并不是简单的将它写到磁盘,而是利用缓冲的方式写到内存,并出于效率考虑,进行排序。
1)每个输入分片由一个Map任务处理。(HDFS一个块的大小默认为128M,可以设置块的大小)
2)map输出的结果会暂存在一个环形内存缓冲区中。(缓冲区默认大小为100M,由io.sort.mb属性控制)
3)当缓冲区快要溢出时(默认为缓冲区大小的80%,由io.sort.spill.percent属性控制),由一个后台线程将该缓冲区中的数据写到磁盘新建的溢出文件中。在溢出写到磁盘的过程中,map输出继续写到缓冲区,但是如果在此期间缓冲区被填满,map会被阻塞直到写磁盘过程完成。
4)在写入磁盘之前,线程首先根据Reduce任务的数目将数据划分为相同数目的分区,也就是一个Reduce任务对应一个分区的数据,这样避免Reduce任务分配到的数据不均匀。(分区就是对数据进行Hash的过程);
5)然后对每个分区中的数据进行排序(第一次排序);
6)如果此时设置了Combiner,将排序后的结果进行Combia操作,使得Map输出结果更紧凑,使得让尽可能少的数据写入到磁盘和传递给Reducer;
7)当Map任务输出最后一个记录时,可能会有很多的溢出文件,这时需要将这些文件合并,合并的过程中会不断地进行排序和Combia操作。(属性io.sort.factor控制一次最多合并多少流,默认10)。这样做的目的1,尽量减少每次写入磁盘的数据量,目的2,尽量减少下一复制阶段网络传输的数据量。最后合并成一个已分区且已排序的文件(第二次排序)。
8)为了减少网络传输数据量,节约磁盘空间,可以在这里将数据压缩。(mapred.compress.map.out设置为ture,mapred.map.output.compression.codec指定使用的压缩库)
9)将分区中的数据拷贝给相对应的Reduce任务。Reducer通过HTTP方式得到输出文件的分区。
Reduce端
1)Reduce会接收到不同Map任务传来的数据,并且每个Map传来的数据都是有序的。
2)如果Reduce端接收的数据量少,则直接存在内存中(缓冲区大小由mapred.job.shuffle.input.buffer.percent属性控制);如果数据量超过了缓冲区大小的一定比例(由mapred.job.shuffle.merge.percent决定)则对数据合并后溢写到磁盘中。
3)随着溢写文件的增多,后台线程会将这些文件合并成一个更大的有序的文件,这样做是为了给后面的合并节省时间;
4)复制完所有Map输出后,Reduce任务进入排序阶段,这个阶段将合并Map输出,维持其顺序排序(第三次排序),这是循环进行的。例如,有50个Map输出,而合并因子默认是10,合并会进行5次,每次将10个文件合并成一个文件,过程中产生5个中间文件。
5)合并的过程中会产生许多的中间文件写入磁盘,但MapReduce会让写入磁盘的数据尽可能少,并且最后一次合并的结果并没有写入磁盘,而是直接输入到Reduce函数。
6)在Reduce阶段,对已排序输出中的每个键调用Reduce函数,此阶段的输出直接写入到输出文件系统HDFS。
15、简述 spark 集群运行的几种模式
local本地模式
standalone集群模式,clinet模式driver在客户端也就是提交application的机器上,cluster模式driver在其中一个worker上
Yarn集群模式,clinet模式driver在客户端也就是提交application的机器上,cluster模式下ApplicationMaster充当了driver,在其中一个nodeManager上
16、RDD 中的 reducebyKey 与 groupByKey 哪个性能高?
reducebyKey 性能高
reduceByKey会先在map端进行本地combine,减少了到reduce端数据量。


17、@@@@@@简述 HBase 的读写过程
https://blog.csdn.net/u011833033/article/details/79773421
18、在 2.5亿个整数中,找出不重复的整数,注意:内存不足以容纳 2.5亿个整数。
使用2bitmap,一个整数用2个bit表示,其中00为整数不存在,01表示整数存在且仅存在一次,10表示整数存在且存在多次,11无意义。需要2^32 * 2bit = 1g然后扫描这些整数,查看与2bitmap的对应位,如果是发现了一个就把00变成01,如果发现第二次就把01变成10,再重复10不动。未发现就00不动。扫描完后,直接输出对应位是01的整数就行了。
内存不足以容纳这2.5亿个整数是什么意思?是不能同时就这2.5亿个整数载入内存吗?那么也就是说它的内存空间是小于250M*4B=1GB(sizeof(int)=4)???what???
19、CDH 和 HDP 的区别
- CDH支持的存储组件更丰富
- HDP支持的数据分析组件更丰富
- HDP对多维分析及可视化有了支持,引入Druid和Superset
- HDP的HBase数据使用Phoenix的jdbc查询;CDH的HBase数据使用映射Hive到Impala的jdbc查询,但分析数据可以存储Impala内部表,提高查询响应
- 多维分析Druid纳入集群,会方便管理;但可视化工具Superset可以单独安装使用
- CDH没有时序数据库,HDP将Druid作为时序数据库使用
20、java 原子操作
1、什么是原子操作
原子操作:一个或多个操作在CPU执行过程中不被中断的特性
当我们说原子操作时,需要分清楚针对的是CPU指令级别还是高级语言级别。
比如:经典的银行转账场景,是语言级别的原子操作;
而当我们说volatile修饰的变量的复合操作,其原子性不能被保证,指的是CPU指令级别。
二者的本质是一致的。
“原子操作”的实质其实并不是指“不可分割”,这只是外在表现,本质在于多个资源之间有一致性的要求,操作的中间态对外不可见。
比如:在32位机器上写64位的long变量有中间状态(只写了64位中的32位);银行转账操作中也有中间状态(A向B转账,A扣钱了,B还没来得及加钱)
2、Java中原子操作的实现方式
Java使用锁和自旋CAS实现原子操作
2.1 用CAS实现原子操作
2.1.2 使用CAS实现原子操作
public class Counter {
private final AtomicInteger atomicI = new AtomicInteger(0);
private int i = 0;
public static void main(String[] args) {
Counter counter = new Counter();
ArrayList<Thread> list = new ArrayList<>(1000);
long start = System.currentTimeMillis();
IntStream.range(0, 100).forEach(u -> {
list.add(new Thread(() ->
IntStream.range(0, 1000).forEach(v -> {
counter.safeCount();
counter.count();
})));
});
list.forEach(Thread::start);
/* wait for all the threads to complete*/
list.forEach(u -> {
try {
u.join();
} catch (InterruptedException e) {
e.printStackTrace();
}
});
System.out.println(counter.i);
System.out.println(counter.atomicI.get());
System.out.println(System.currentTimeMillis() - start);
}
/* 使用CAS 来实现原子操作*/
public void safeCount() {
for (; ; ) {
int i = atomicI.get();
/*Atomically sets the value to the given updated value if the current value == the expected value.*/
/*Parameters:
expect - the expected value
update - the new value*/
/* 其实,假如使用 原子类来实现计数器,不需要直接用 cas 的API,原子类已经提供了现成的API了*/
boolean success = atomicI.compareAndSet(i, i + 1);
if (success) {
break;
}
}
}
/* 使用 锁 来实现原子操作*/
public synchronized void safeCount1() {
i++;
}
/* 线程不安全的累加*/
public void count() {
i++;
}
}
并发包中提供了很多原子类来支持原子操作:
- AtomicInteger
- AtomicLong
- AtomicBoolean
- AtomicReference
- LongAdder
2.1.3 CAS实现原子操作的问题
CAS是并发包的基石,但用CAS有三个问题:
1)ABA问题
根源:CAS的本质是对变量的current value ,期望值 expected value 进行比较,二者相等时,再将 给定值 given update value 设为当前值。
因此会存在一种场景,变量值原来是A,变成了B,又变成了A,使用CAS检查时会发现值并未变化,实际上是变化了。
对于数值类型的变量,比如int,这种问题关系不大,但对于引用类型,则会产生很大影响。
ABA问题解决思路:版本号。在变量前加版本号,每次变量更新时将版本号加1,A -> B -> A,就变成 1A -> 2B -> 3A。
JDK5之后Atomic包中提供了AtomicStampedReference#compareAndSet来解决ABA问题。
public boolean compareAndSet(@Nullable V expectedReference,
V newReference,
int expectedStamp,
int newStamp)
Atomically sets the value of both the reference and stamp to the given update values if the current reference is == to the expected reference and the current stamp is equal to the expected stamp.
Parameters:
expectedReference - the expected value of the reference
newReference - the new value for the reference
expectedStamp - the expected value of the stamp
newStamp - the new value for the stamp
2)循环时间长则开销大
自旋CAS若长时间不成功,会对CPU造成较大开销。不过有的JVM可支持CPU的pause指令的话,效率可有一定提升。
pause作用:
延迟流水线指令(de-pipeline),使CPU不至于消耗过多执行资源。
可避免退出循环时因内存顺序冲突(memorey order violation )引起CPU流水线被清空(CPU pipeline flush),从而提高CPU的执行效率。
3)只能保证一个共享变量的原子操作
CAS只能对单个共享变量如是操作,对多个共享变量操作时则无法保证原子性,此时可以用锁。
另外,也可“取巧”,将多个共享变量合成一个共享变量来操作。比如a=2,b=t,合并起来ab=2t,然后用CAS操作ab.
JDK5提供AtomicReference保证引用对象间的原子性,它可将多个变量放在一个对象中来进行CAS操作。
3、Java中使用锁实现原子操作
锁机制保证只有拿到锁的线程才能操作锁定的内存区域。
JVM内部实现了多种锁,偏向锁、轻量锁、互斥锁。不过轻量锁、互斥锁(即不包括偏向锁),实现锁时还是使用了CAS,即:一个线程进入同步代码时用自CAS拿锁,退出块的时候用CAS释放锁。
synchronized锁定的临界区代码对共享变量的操作是原子操作。
21、Java 封装、继承和多态
- 封装:给对象提供了隐藏内部特性和行为的能力。四种修饰符:default、public、private、protected
| 作用域 | 当前类 | 同一个package | 子孙类 | 其他package |
|---|---|---|---|---|
| public | √ | √ | √ | √ |
| protected | √ | √ | √ | × |
| defalut | √ | √ | × | × |
| private | √ | × | × | × |
private只能本类可见;
public所有类都可见;
protected同一个包下的所有类可见,不同包的子类可以访问,不同包不是子类不能访问;
default只有本包可见(默认情况)
好处:
隐藏并保护对象属性和内部的状态;可以对外公开简单的接口,便于外界使用,从而提高系统的扩展性、可维护性。禁止了一些不正确的交互。
-
继承
extends关键字。给对象提供了从基类获取字段和方法的能力,在不修改类的情况下还可以给类添加新特性,重用了代码。
只支持单继承;
如果没有声明继承关系,默认继承Object类;
子类使用父类的private属性,可以用get、set方法;
可以通过super访问父类中被子类覆盖的方法或属性,普通方法随意调用,构造方法如果不显式调用super(),那么会默认用super()作为父类的初始化方法。
-
多态
多态是同一个行为具有多个不同表现形式或形态的能力。
多态就是同一个接口,使用不同的实例而执行不同操作,如图所示:
一个多态类型上的操作可以应用到其它类型的值上。
class Animal{
public String name;
public Animal(String name){
this.name = name;
}
}
class Dog extends Animal{
public String folorColor;
public Dog(String name,StringfolorColor){
super(name); this.folorColor = folorColor;
}
}
class Cat extends Animal{
public String eyesColor;
public Cat(String name,String eyesColor){
super(name); this.eyesColor = eyesColor;
}
}
public class TestCasting{
public static void main(String args[]){
Animal a = new Animal("a");
Cat c = new Cat("c","cEyesColor");
Dog d = new Dog("d","dForlorColor");
System.out.println(a instanceof Animal); //true
System.out.println(c instanceof Animal); //true
System.out.println(d instanceof Animal); //true
System.out.println(a instanceof Dog); //false
a = new Dog("d2","d2ForlorColor"); //父类引用指向子类对象,向上转型
System.out.println(a.name); //可以访问
//System.out.println(a.folorColor);
//!error 不可以访问超出Animal自身的任何属性
System.out.println(a instanceof Animal); //是一只动物 System.out.println(a instanceof Dog); //是一只狗,但是不能访问狗里面的属性
Dog d2 = (Dog)a; //强制转换
System.out.println(d2.folorColor); //将a强制转换之后,就可以访问狗里面的属性了
}
}
22、JVM 模型
类加载器,运行时数据区(方法区和堆为线程共享数据区,java栈、本地方法栈和程序计数器为线程私有的数据区),执行引擎,本地库接口,本地方法库
-
程序计数器: Java 线程私有,类似于操作系统里的 PC 计数器,它可以看做是当前线程所执行的字节码的行号指示器。
-
- 如果线程正在执行的是一个 Java 方法,这个计数器记录的是正在执行的虚拟机字节码指令的地址;如果正在执行的是 Native 方法,这个计数器值则为空(Undefined)。
- 此内存区域是唯一一个在 Java 虚拟机规范中没有规定任何 OutOfMemoryError 情况的区域。
-
虚拟机栈(栈内存):Java线程私有,虚拟机栈描述的是 Java 方法执行的内存模型:
-
- 每个方法在执行的时候,都会创建一个栈帧用于存储局部变量、操作数、动态链接、方法出口等信息。
- 每个方法调用都意味着一个栈帧在虚拟机栈中入栈到出栈的过程。
-
本地方法栈 :和 Java 虚拟机栈的作用类似,区别是该区域为 JVM 提供使用 Native 方法的服务。
-
堆内存(线程共享):所有线程共享的一块区域,垃圾收集器管理的主要区域。
-
- 目前主要的垃圾回收算法都是分代收集算法,所以 Java 堆中还可以细分为:新生代和老年代;再细致一点的有 Eden 空间、From Survivor 空间、To Survivor 空间等,默认情况下新生代按照
8:1:1的比例来分配。 - 根据 Java 虚拟机规范的规定,Java 堆可以处于物理上不连续的内存空间中,只要逻辑上是连续的即可,就像我们的磁盘一样。
- 目前主要的垃圾回收算法都是分代收集算法,所以 Java 堆中还可以细分为:新生代和老年代;再细致一点的有 Eden 空间、From Survivor 空间、To Survivor 空间等,默认情况下新生代按照
-
方法区(线程共享):各个线程共享的一个区域,用于存储虚拟机加载的类信息、常量、静态变量、即时编译器编译后的代码等数据。
-
-
虽然 Java 虚拟机规范把方法区描述为堆的一个逻辑部分,但是它却有一个别名叫做 Non-Heap(非堆),目的应该是与 Java 堆区分开来。
-
运行时常量池:是方法区的一部分,用于存放编译器生成的各种字面量和符号引用。
-
实际上,后续的版本,主要对【方法区】做了一定的调整
-
-
JDK7 的改变
-
- 存储在永久代的部分数据就已经转移到了 Java Heap 或者是 Native Heap。但永久代仍存在于 JDK7 中,但是并没完全移除。
- 常量池和静态变量放到 Java 堆里。
-
JDK8 的改变
-
- 废弃 PermGen(永久代),新增 Metaspace(元数据区)。
- 那么方法区还在么?FROM 狼哥 的解答:方法区在 Metaspace 中了,方法区都是一个概念的东西。 狼哥通过撸源码获得该信息。
-
因为,《Java 虚拟机规范》只是规定了有方法区这么个概念和它的作用,并没有规定如何去实现它。那么,在不同的 JVM 上方法区的实现肯定是不同的了。
同时,大多数用的 JVM 都是 Sun 公司的 HotSpot 。在 HotSpot 上把 GC 分代收集扩展至方法区,或者说使用永久带来实现方法区。
-
-
JDK8 之后 Perm Space 有哪些变动? MetaSpace ⼤⼩默认是⽆限的么? 还是你们会通过什么⽅式来指定⼤⼩?
-
JDK8 后用元空间替代了 Perm Space ;字符串常量存放到堆内存中。
-
MetaSpace 大小默认没有限制,一般根据系统内存的大小。JVM 会动态改变此值。
-
可以通过 JVM 参数配置
-
-XX:MetaspaceSize: 分配给类元数据空间(以字节计)的初始大小(Oracle 逻辑存储上的初始高水位,the initial high-water-mark)。此值为估计值,MetaspaceSize 的值设置的过大会延长垃圾回收时间。垃圾回收过后,引起下一次垃圾回收的类元数据空间的大小可能会变大。-XX:MaxMetaspaceSize:分配给类元数据空间的最大值,超过此值就会触发Full GC 。此值默认没有限制,但应取决于系统内存的大小,JVM 会动态地改变此值。
为什么要废弃永久代?
1)现实使用中易出问题。
由于永久代内存经常不够用或发生内存泄露,爆出异常 java.lang.OutOfMemoryError: PermGen 。
- 字符串存在永久代中,容易出现性能问题和内存溢出。
- 类及方法的信息等比较难确定其大小,因此对于永久代的大小指定比较困难,太小容易出现永久代溢出,太大则容易导致老年代溢出。
23、@@@@@@Flume taildirSorce 重复读取数据解决方法
24、@@@@@@Flume 如何保证数据不丢
25、Java 类加载过程

在加载阶段,虚拟机需要完成以下三件事情:
- 通过一个类的全限定名来获取其定义的二进制字节流。
- 将这个字节流所代表的静态存储结构转化为方法区的运行时数据结构。
- 在Java堆中生成一个代表这个类的
java.lang.Class对象,作为对方法区中这些数据的访问入口。
验证阶段
为了确保 Class 文件的字节流中包含的信息符合当前虚拟机的要求,并且不会危害虚拟机自身的安全。
- 文件格式验证:验证字节流是否符合 Class 文件格式的规范。例如:是否以
0xCAFEBABE开头、主次版本号是否在当前虚拟机的处理范围之内、常量池中的常量是否有不被支持的类型。 - 元数据验证:对字节码描述的信息进行语义分析(注意:对比 javac 编译阶段的语义分析),以保证其描述的信息符合 Java 语言规范的要求。例如:这个类是否有父类,除了
java.lang.Object之外。 - 字节码验证:通过数据流和控制流分析,确定程序语义是合法的、符合逻辑的。
- 符号引用验证:确保解析动作能正确执行。
准备阶段
正式为类变量分配内存并设置类变量初始值的阶段
pirvate static int size = 12。那么在这个阶段,size的值为0,而不是12。 final修饰的类变量将会赋值成真实的值。
解析阶段
是虚拟机将常量池内的符号引用替换为直接引用的过程。对类或接口、字段、类方法、接口方法、方法类型、方法句柄和调用点限定符 7 类符号引用进行
初始化阶段
在准备阶段,类变量已经经过一次初始化了,在这个阶段,则是根据程序员通过程序制定的计划去初始化类的变量和其他资源。这些资源有static{}块,构造函数,父类的初始化等。
JVM 初始化步骤:
- 1、假如这个类还没有被加载和连接,则程序先加载并连接该类。
- 2、假如该类的直接父类还没有被初始化,则先初始化其直接父类。
- 3、假如类中有初始化语句,则系统依次执行这些初始化语句。
https://www.cnblogs.com/javaee6/p/3714716.html
public class SingleTon {
private static SingleTon singleTon = new SingleTon();
public static int count1;
public static int count2 = 3;
private SingleTon() {
count1++;
count2++;
}
public static SingleTon getInstance() {
return singleTon;
}
public static void main(String[] args) {
SingleTon singleTon = SingleTon.getInstance();
System.out.println("count1=" + singleTon.count1);
System.out.println("count2=" + singleTon.count2);
}
}
输出为:
count1=1
count2=3
26、Spark Task 运行原理

task运行之前的工作是Driver启动Executor,接着Executor准备好一切运行环境,并向Driver反向注册,最终Driver向Executor发送LunchTask事件消息,从Executor接受到LanchTask那一刻起,task开始通过java线程来进行以后的工作。在正式工作之前taskScheduler会进行“数据的本地化”
| PROCESS_LOCAL |
|---|
| NODE_LOCAL |
| NO_PREF |
| RACK_LOCAL |
| ANY |
TaskScheduler在发送task的时候,会根据数据所在的节点发送task,这时候的数据本地化的级别是最高的,如果这个task在这个Executor中等待了三秒,重试发射了5次还是依然无法执行,那么TaskScheduler就会认为这个Executor的计算资源满了,TaskScheduler会降低一级数据本地化的级别,重新发送task到其他的Executor中执行,如果还是依然无法执行,那么继续降低数据本地化的级别。
task所做的事情:
- 通过网络拉取运行所需的资源,并反序列化
- 获取shuffleManager,从shuffleManager中获取shuffleWriter(shuffleWriter用于后面的数据处理并把返回的数据结果写入磁盘)
- 调用rdd.iterator(),并传入当前task要处理的partition(针对RDD的某个partition执行自定义的算子或逻辑函数,返回的数据都是通过上面生成的ShuffleWriter,经过HashPartitioner[默认是这个]分区之后写入对应的分区backet,其实就是写入磁盘文件中)
- 封装数据结果为MapStatus ,发送给MapOutputTracker,供ResultTask拉取。(MapStatus里面封装了ShuffleMaptask计算后的数据和存储位置地址等数据信息。其实也就是BlockManager相关信息,BlockManager 是Spark底层的内存,数据,磁盘数据管理的组件)
- ResultTask拉取ShuffleMapTask的结果数据
https://www.cnblogs.com/itboys/p/9207725.html
27、手写一个线程安全的单例
public class SingleTon {
private static volatile SingleTon singleTon;
private SingleTon() {
}
public static SingleTon getInstance() {
if (singleTon == null) {
synchronized (SingleTon.class) {
if (singleTon == null) {
singleTon = new SingleTon();
}
}
}
return singleTon;
}
}
28、@@@@@@设计模式
29、@@@@@@impala 和 kudu 的适用场景,读写性能如何
30、kafka ack
当 Producer 向 Leader 发送数据时,可以通过request.required.acks 参数来设置数据可靠性的级别:
acks=1(默认):意味着ISR中的Leader成功接收到消息,并进行了确认后才发送下一条。
acks=0:意味着Producer无需等待来自Broker的确认就发送下一条数据,这种模式下数据传输效率最快,但是数据会丢失,可靠性最低。
acks=all或者是-1:意味着Producer需要等待ISR中所有的Follower都成功接收到了数据并进行了确认,才发送下一条数据,可靠性最高,但是也不会完全保证数据不丢失,比如只有leader存在,其他节点与zookeeper断开连接或者是都没追上,全进了OSR。这样变成了acks=1。所以在Borker端设置 min.insync.replicas 参数:这个值必须大于 1 ,这个是要求一个 leader 至少感知到有至少一个 follower 还保持连接,没掉队,这样才能确保 leader 挂了至少还有一个 follower 。
31、@@@@@@phoenix 创建索引的方式及区别
32、@@@@@@Flink TaskManager 和 Job Manager 通信
33、@@@@@@Flink 双流 join方式
34、@@@@@@Flink state 管理和 checkpoint 的流程
35、@@@@@@Flink 分层架构
36、@@@@@@Flink 窗口
37、@@@@@@Flink watermark 如何处理乱序数据
38、@@@@@@Flink time
39、@@@@@@Flink 支持exactly-once 的 sink 和 source
40、@@@@@@Flink 提交作业的流程
41、@@@@@@Flink connect 和 join 区别
42、@@@@@@重启 task 的策略
43、hive 的锁
Hive 锁的类型与关系:
hive 目前主要有两种锁,SHARED(共享锁 S)和 Exclusive(排他锁 X)。共享锁 S 和 排他锁 X 它们之间的兼容性矩阵关系如下:

总结起来就是:
- 1)查询操作使用共享锁,共享锁是可以多重、并发使用的
- 2)修改表操作使用独占锁,它会阻止其他的查询、修改操作
- 3)可以对分区使用锁。
以下情况会出发锁,以及它的类型和锁定范围如下:
| Hive Command | Locks Acquired |
|---|---|
| select … T1 partition P1 | S on T1, T1.P1 |
| insert into T2(partition P2) select … T1 partition P1 | S on T2, T1, T1.P1 and X on T2.P2 |
| insert into T2(partition P.Q) select … T1 partition P1 | S on T2, T2.P, T1, T1.P1 and X on T2.P.Q |
| alter table T1 rename T2 | X on T1 |
| alter table T1 add cols | X on T1 |
| alter table T1 replace cols | X on T1 |
| alter table T1 change cols | X on T1 |
| alter table T1 *concatenate* | X on T1 |
| alter table T1 add partition P1 | S on T1, X on T1.P1 |
| alter table T1 drop partition P1 | S on T1, X on T1.P1 |
| alter table T1 touch partition P1 | S on T1, X on T1.P1 |
| alter table T1 set serdeproperties | S on T1 |
| alter table T1 set serializer | S on T1 |
| alter table T1 set file format | S on T1 |
| alter table T1 set tblproperties | X on T1 |
| alter table T1 partition P1 concatenate | X on T1.P1 |
| drop table T1 | X on T1 |
2、如何开启锁机制
修改hive-site.xml,配置如下:
hive.zookeeper.quorum
zk1,zk2,zk3
hive.support.concurrency
true
除此之外,还可以手动显式设置独占锁:
-- 1)锁表
hive> lock table t1 exclusive;
-- 表被独占锁之后,将不能执行查询操作:
hive> SELECT COUNT(*) FROM people;
conflicting lock present for default@people mode SHARED
FAILED: Error in acquiring locks: locks on the underlying objects
cannot be acquired. retry after some time
-- 2)解除锁
hive> unlock table t1;
注:Lock 是一种悲观的顺序化机制。它假设很可能发生冲突,因此在操作数据时,就加锁。
如果冲突的可能性很小,多数的锁都是不必要的。比如 Innodb 实现了一个延迟加锁的机制,来减少加锁的数量,提升性能,在代码中称为隐式锁(Implicit Lock),在本文中提到的 Hive锁默认都是隐式锁,除非手动加锁才是显式锁。
可以使用以下命令开始debug和排查锁问题:
SHOW LOCKS <TABLE_NAME>;
SHOW LOCKS <TABLE_NAME> EXTENDED;
SHOW LOCKS <TABLE_NAME> PARTITION (<PARTITION_DESC>);
SHOW LOCKS <TABLE_NAME> PARTITION (<PARTITION_DESC>) EXTENDED;
总结:
想要避免 Hive 锁造成的读、写失败问题,注意以下3点:
1、表建议设置分区,锁的粒度可以到分区,否则容易遭遇长时间锁表,尤其大字典表、单张全量表要注意。
2、建议脚本重跑一段时间范围数据时设置 sleep 间隔,避免长期持有锁,造成依赖表的任务调度失败。
hive.lock.numretries #重试次数 hive.lock.sleep.between.retries #重试时sleep的时间
3、我们可以通过 set hive.support.concurrency=false 来关闭锁,优先保证插入数据成功,虽然此时读数据会有问题。
44、hive sql 优化方式
https://mp.weixin.qq.com/s/DfvN7S_00oYw1hqAQDr48g
列裁剪和分区裁剪
最基本的操作。所谓列裁剪就是在查询时只读取需要的列,分区裁剪就是只读取需要的分区。
谓词下推
在关系型数据库如MySQL中,也有谓词下推(Predicate Pushdown,PPD)的概念。它就是将SQL语句中的where谓词逻辑都尽可能提前执行,减少下游处理的数据量。
sort by代替order by
HiveSQL中的order by与其他SQL方言中的功能一样,就是将结果按某字段全局排序,这会导致所有map端数据都进入一个reducer中,在数据量大时可能会长时间计算不完。
如果使用sort by,那么还是会视情况启动多个reducer进行排序,并且保证每个reducer内局部有序。为了控制map端数据分配到reducer的key,往往还要配合distribute by一同使用。如果不加distribute by的话,map端数据就会随机分配到reducer。
group by代替distinct
当要统计某一列的去重数时,如果数据量很大,count(distinct)就会非常慢,原因与order by类似,count(distinct)逻辑只会有很少的reducer来处理。这时可以用group by来改写:
select count(1) from (select uid from calendar_record_logwhere pt_date >= 20190101 group by uid) t;
但是这样写会启动两个MR job(单纯distinct只会启动一个),所以要确保数据量大到启动job的overhead远小于计算耗时,才考虑这种方法。当数据集很小或者key的倾斜比较明显时,group by还可能会比distinct慢。
那么如何用group by方式同时统计多个列?下面是解决方法:
select t.a,sum(t.b),count(t.c),count(t.d) from (select a,b,null c,null d from some_tableunion allselect a,0 b,c,null d from some_table group by a,cunion allselect a,0 b,null c,d from some_table group by a,d) t;
group by配置调整
map端预聚合
group by时,如果先起一个combiner在map端做部分预聚合,可以有效减少shuffle数据量。预聚合的配置项是hive.map.aggr,默认值true,对应的优化器为GroupByOptimizer,简单方便。
通过hive.groupby.mapaggr.checkinterval参数也可以设置map端预聚合的行数阈值,超过该值就会分拆job,默认值100000。
倾斜均衡配置项
group by时如果某些key对应的数据量过大,就会发生数据倾斜。Hive自带了一个均衡数据倾斜的配置项hive.groupby.skewindata,默认值false。
其实现方法是在group by时启动两个MR job。第一个job会将map端数据随机输入reducer,每个reducer做部分聚合,相同的key就会分布在不同的reducer中。第二个job再将前面预处理过的数据按key聚合并输出结果,这样就起到了均衡的效果。
join基础优化
build table(小表)前置
Hive在解析带join的SQL语句时,会默认将最后一个表作为probe table,将前面的表作为build table并试图将它们读进内存。如果表顺序写反,probe table在前面,引发OOM的风险就高了。
在维度建模数据仓库中,事实表就是probe table,维度表就是build table。
多表join时key相同
这种情况会将多个join合并为一个MR job来处理
select a.event_type,a.event_code,a.event_desc,b.upload_timefrom calendar_event_code ainner join (select event_type,upload_time from calendar_record_logwhere pt_date = 20190225) b on a.event_type = b.event_typeinner join (select event_type,upload_time from calendar_record_log_2where pt_date = 20190225) c on a.event_type = c.event_type;
利用map join特性
map join特别适合大小表join的情况。Hive会将build table和probe table在map端直接完成join过程,消灭了reduce,效率很高。
select a.event_type,b.upload_timefrom calendar_event_code a inner join (select event_type,upload_time from calendar_record_logwhere pt_date = 20190225) b on a.event_type < b.event_type;
hive.mapjoin.smalltable.filesize,当build table大小小于该值就会启用map join,默认值25000000(25MB)
hive.mapjoin.cache.numrows,表示缓存build table的多少行数据到内存,默认值25000。
分桶表map join
倾斜均衡配置项
hive.optimize.skewjoin如果开启了,在join过程中Hive会将计数超过阈值hive.skewjoin.key(默认100000)的倾斜key对应的行临时写进文件中,然后再启动另一个job做map join生成结果。通过hive.skewjoin.mapjoin.map.tasks参数还可以控制第二个job的mapper数量,默认10000。
优化SQL处理join数据倾斜
空值或无意义值
这种情况很常见,比如当事实表是日志类数据时,往往会有一些项没有记录到,我们视情况会将它置为null,或者空字符串、-1等。如果缺失的项很多,在做join时这些空值就会非常集中,拖累进度。
因此,若不需要空值数据,就提前写where语句过滤掉。需要保留的话,将空值key用随机方式打散,例如将用户ID为null的记录随机改为负值:
单独处理倾斜key
一般来讲倾斜的key都很少,我们可以将它们抽样出来,对应的行单独存入临时表中,然后打上一个较小的随机数前缀(比如0~9),最后再进行聚合。
新旧表数据类型转换频繁
假如我们有一旧一新两张日历记录表,旧表的记录类型字段是(event_type int),新表的是(event_type string)。为了兼容旧版记录,新表的event_type也会以字符串形式存储旧版的值,比如’17’。当这两张表join时,经常要耗费很长时间。其原因就是如果不转换类型,计算key的hash值时默认是以int型做的,这就导致所有“真正的”string型key都分配到一个reducer上。所以要注意类型转换:
select a.uid,a.event_type,b.record_datafrom calendar_record_log aleft outer join (select uid,event_type from calendar_record_log_2where pt_date = 20190228) b on a.uid = b.uid and b.event_type = cast(a.event_type as string)where a.pt_date = 20190228;
build table过大
有时,build table会大到无法直接使用map join的地步,比如全量用户维度表,而使用普通join又有数据分布不均的问题。这时就要充分利用probe table的限制条件,削减build table的数据量,再使用map join解决。代价就是需要进行两次join。举个例子:
select /*+mapjoin(b)*/ a.uid,a.event_type,b.status,b.extra_infofrom calendar_record_log aleft outer join (select /*+mapjoin(s)*/ t.uid,t.status,t.extra_infofrom (select distinct uid from calendar_record_log where pt_date = 20190228) sinner join user_info t on s.uid = t.uid) b on a.uid = b.uidwhere a.pt_date = 20190228;
MapReduce优化
调整mapper数
mapper数量与输入文件的split数息息相关。
如果输入文件是少量大文件,就减少mapper数。适当调高mapred.min.split.size,split数就减少了。
如果输入文件是大量非小文件,就增大mapper数。降低mapred.min.split.size,也可以调高mapred.map.tasks
调整reducer数
使用参数mapred.reduce.tasks
reducer数量与输出文件的数量相关。如果reducer数太多,会产生大量小文件,对HDFS造成压力。如果reducer数太少,每个reducer要处理很多数据,容易拖慢运行时间或者造成OOM。
合并小文件
- 输入阶段合并
需要更改Hive的输入文件格式,即参数hive.input.format,默认值是org.apache.hadoop.hive.ql.io.HiveInputFormat,我们改成org.apache.hadoop.hive.ql.io.CombineHiveInputFormat。 - 输出阶段合并
直接将hive.merge.mapfiles和hive.merge.mapredfiles都设为true即可,前者表示将map-only任务的输出合并,后者表示将map-reduce任务的输出合并。
启用压缩
压缩job的中间结果数据和输出数据,可以用少量CPU时间节省很多空间。压缩方式一般选择Snappy,效率最高。
JVM重用
在MR job中,默认是每执行一个task就启动一个JVM。如果task非常小而碎,那么JVM启动和关闭的耗时就会很长。可以通过调节参数mapred.job.reuse.jvm.num.tasks来重用。例如将这个参数设成5,那么就代表同一个MR job中顺序执行的5个task可以重复使用一个JVM,减少启动和关闭的开销。但它对不同MR job中的task无效。
并行执行与本地模式
- 并行执行
Hive中互相没有依赖关系的job间是可以并行执行的,最典型的就是多个子查询union all。在集群资源相对充足的情况下,可以开启并行执行,即将参数hive.exec.parallel设为true。另外hive.exec.parallel.thread.number可以设定并行执行的线程数,默认为8,一般都够用。 - 本地模式
Hive也可以不将任务提交到集群进行运算,而是直接在一台节点上处理。因为消除了提交到集群的overhead,所以比较适合数据量很小,且逻辑不复杂的任务。
设置hive.exec.mode.local.auto为true可以开启本地模式。但任务的输入数据总量必须小于hive.exec.mode.local.auto.inputbytes.max(默认值128MB),且mapper数必须小于hive.exec.mode.local.auto.tasks.max(默认值4),reducer数必须为0或1,才会真正用本地模式执行。
严格模式
所谓严格模式,就是强制不允许用户执行3种有风险的HiveSQL语句,一旦执行会直接失败。这3种语句是:
- 查询分区表时不限定分区列的语句;
- 两表join产生了笛卡尔积的语句;
- 用order by来排序但没有指定limit的语句。
要开启严格模式,需要将参数hive.mapred.mode设为strict。
采用合适的存储格式
在HiveSQL的create table语句中,可以使用stored as ...指定表的存储格式。Hive表支持的存储格式有TextFile、SequenceFile、RCFile、Avro、ORC、Parquet等。
存储格式一般需要根据业务进行选择,在我们的实操中,绝大多数表都采用TextFile与Parquet两种存储格式之一。
TextFile是最简单的存储格式,它是纯文本记录,也是Hive的默认格式。虽然它的磁盘开销比较大,查询效率也低,但它更多地是作为跳板来使用。RCFile、ORC、Parquet等格式的表都不能由文件直接导入数据,必须由TextFile来做中转。
Parquet和ORC都是Apache旗下的开源列式存储格式。列式存储比起传统的行式存储更适合批量OLAP查询,并且也支持更好的压缩和编码。我们选择Parquet的原因主要是它支持Impala查询引擎,并且我们对update、delete和事务性操作需求很低。
https://juejin.im/post/5cd83b9ff265da038364e35d
45、hadoop shuffle 过程和架构
过程:
Map端
map函数开始产生输出时,并不是简单的将它写到磁盘,而是利用缓冲的方式写到内存,并出于效率考虑,进行排序。
1)每个输入分片由一个Map任务处理。(HDFS一个块的大小默认为128M,可以设置块的大小)
2)map输出的结果会暂存在一个环形内存缓冲区中。(缓冲区默认大小为100M,由io.sort.mb属性控制)
3)当缓冲区快要溢出时(默认为缓冲区大小的80%,由io.sort.spill.percent属性控制),由一个后台线程将该缓冲区中的数据写到磁盘新建的溢出文件中。在溢出写到磁盘的过程中,map输出继续写到缓冲区,但是如果在此期间缓冲区被填满,map会被阻塞直到写磁盘过程完成。
4)在写入磁盘之前,线程首先根据Reduce任务的数目将数据划分为相同数目的分区,也就是一个Reduce任务对应一个分区的数据,这样避免Reduce任务分配到的数据不均匀。(分区就是对数据进行Hash的过程);
5)然后对每个分区中的数据进行排序(第一次排序);
6)如果此时设置了Combiner,将排序后的结果进行Combia操作,使得Map输出结果更紧凑,使得让尽可能少的数据写入到磁盘和传递给Reducer;
7)当Map任务输出最后一个记录时,可能会有很多的溢出文件,这时需要将这些文件合并,合并的过程中会不断地进行排序和Combia操作。(属性io.sort.factor控制一次最多合并多少流,默认10)。这样做的目的1,尽量减少每次写入磁盘的数据量,目的2,尽量减少下一复制阶段网络传输的数据量。最后合并成一个已分区且已排序的文件(第二次排序)。
8)为了减少网络传输数据量,节约磁盘空间,可以在这里将数据压缩。(mapred.compress.map.out设置为ture,mapred.map.output.compression.codec指定使用的压缩库)
9)将分区中的数据拷贝给相对应的Reduce任务。Reducer通过HTTP方式得到输出文件的分区。
Reduce端
1)Reduce会接收到不同Map任务传来的数据,并且每个Map传来的数据都是有序的。
2)如果Reduce端接收的数据量少,则直接存在内存中(缓冲区大小由mapred.job.shuffle.input.buffer.percent属性控制);如果数据量超过了缓冲区大小的一定比例(由mapred.job.shuffle.merge.percent决定)则对数据合并后溢写到磁盘中。
3)随着溢写文件的增多,后台线程会将这些文件合并成一个更大的有序的文件,这样做是为了给后面的合并节省时间;
4)复制完所有Map输出后,Reduce任务进入排序阶段,这个阶段将合并Map输出,维持其顺序排序(第三次排序),这是循环进行的。例如,有50个Map输出,而合并因子默认是10,合并会进行5次,每次将10个文件合并成一个文件,过程中产生5个中间文件。
5)合并的过程中会产生许多的中间文件写入磁盘,但MapReduce会让写入磁盘的数据尽可能少,并且最后一次合并的结果并没有写入磁盘,而是直接输入到Reduce函数。
6)在Reduce阶段,对已排序输出中的每个键调用Reduce函数,此阶段的输出直接写入到输出文件系统HDFS。
架构:
**Hadoop1.x版本:**由一个JobTracker和多个TaskTracker组成。
JobTracker的主要作用:JobTracker是框架的中心,接收任务,计算资源,分配资源,分配任务,与DataNode进行交流等功能。决策程序失败时 重启等操作。
TaskTracker同时监视当前机器上的task运行状况。TaskTracker需要把这些信息通过心跳,发送给jobTracker,jobTracker会收集这些信息以给新提交的job分配运行在那些机器上。
存在问题:
1.JobTracker是mapreduce的集中处理点,存在单点故障;
2.JobTracker完成了太多任务,造成了过多资源的消耗,当mapreduce job非常多的时候,会造成很大的内存消耗,同时 也增加了JobTracker失效的风险,这也是业界普遍总结出老的hadoop的mapreduce只能支持4000节点主机的上限。

Hadoop2.x版本:
变成了运行于资源管理框架YARN之上的计算框架MapReduce。它的运行时环境不再由JobTracker和TaskTracker等服务组成,而是变为通用资源管理系统YARN和作业控制进程ApplicationMaster,其中,YARN负责资源管理和调度,而ApplicationMaster仅负责一个作业的管理。


46、如何优化 shuffle过程
Hadoop:
combiner 合并优化
在 map 阶段提前进行了一次合并,一般来讲等同于提前执行了 reduce 操作
compress 压缩优化:大大减少磁盘 IO 以及网络 IO
MapReduce 有很多地方都可以压缩
输入的就是一个压缩文件
map shuffle 中合并成一个大文件,对该文件进行压缩,reduce 过来取数据就是压缩之后的数
内存化
Shuffle的数据不放在磁盘而是尽量放在内存中,除非逼不得已往磁盘上放;
Spark:
spark.shuffle.file.buffer
用于设置shuffle write task的BufferedOutputStream的buffer缓冲大小(默认是32K)。将数据写到磁盘文件之前,会先写入buffer缓冲中,待缓冲写满之后,才会溢写到磁盘。
适当增加这个参数的大小(比如64k),从而减少shuffle write过程中溢写磁盘文件的次数,也就可以减少磁盘IO次数,进而提升性能
spark.reducer.maxSizeInFlight:
用于设置shuffle read task的buffer缓冲大小,而这个buffer缓冲决定了每次能够拉取多少数据。
适当增加这个参数的大小(比如96m),从而减少拉取数据的次数,也就可以减少网络传输的次数,进而提升性能。
spark.shuffle.io.maxRetries和spark.shuffle.io.retryWait:
spark.shuffle.io.maxRetries:shuffle read task从shuffle write task所在节点拉取属于自己的数据时,如果因为网络异常导致拉取失败,是会自动进行重试的。该参数就代表了可以重试的最大次数。(默认是3次)
spark.shuffle.io.retryWait:代表了每次重试拉取数据的等待间隔。(默认为5s)
一般的调优都是将重试次数调高,不调整时间间隔。
spark.shuffle.memoryFraction:
代表了Executor内存中,分配给shuffle read task进行聚合操作的内存比例。reduce端聚合内存变大了,减少spill到磁盘的次数,而且减少了后面聚合读取磁盘文件的数量。
spark.shuffle.manager
用于设置shufflemanager的类型(默认为sort)
Hash:spark1.x版本的默认值,HashShuffleManager
Sort:spark2.x版本的默认值,普通机制,当shuffle read task 的数量小于等于spark.shuffle.sort.bypassMergeThreshold参数,自动开启bypass 机制
tungsten-sort
spark.shuffle.sort.bypassMergeThreshold
当ShuffleManager为SortShuffleManager时,如果shuffle read task的数量小于这个阈值(默认是200),则shuffle write过程中不会进行排序操作。
使用SortShuffleManager时,如果的确不需要排序操作,那么建议将这个参数调大一些
spark.shuffle.consolidateFiles:
如果使用HashShuffleManager,该参数有效。如果设置为true,那么就会开启consolidate机制,也就是开启优化后的HashShuffleManager。
如果的确不需要SortShuffleManager的排序机制,那么除了使用bypass机制,还可以尝试将spark.shffle.manager参数手动指定为hash,使用HashShuffleManager,同时开启consolidate机制。有时候其性能比开启了bypass机制的SortShuffleManager要高出10%~30%。
47、冒泡排序和快速排序
public class BubbleSort{
private void swap(int[] arr, int i, int j) {
int tmp = arr[i];
arr[i] = arr[j];
arr[j] = tmp;
}
public void bubbleSort(int[] arr) {
if (arr == null || arr.length < 2) return;
for (int i = arr.length - 1; i > 0; i--) {
for (int j = 0; j < i; j++) {
if (arr[j] > arr[j + 1]) {
swap(arr, j, j + 1);
}
}
}
}
}
public class QuickSort{
private void swap(int[] arr, int i, int j) {
int tmp = arr[i];
arr[i] = arr[j];
arr[j] = tmp;
}
public void quickSort(int[] arr) {
if (arr == null || arr.length < 2) return;
quickSort(arr, 0, arr.length - 1);
}
private void quicksort(int[] arr, int low, int high) {
if (low < high) {
swap(arr, low + (int)(Math.random() * (high - low + 1)), high);
int[] p = partition(arr, low, high);
quickSort(arr, low, p[0] - 1);
quickSort(arr, p[1] + 1, high);
}
}
private int[] partition(int arr[], int low, int high) {
int less = low - 1;
int more = high;
while (low < more) {
if (arr[low] < arr[high]) {
swap(arr, ++less, low++);
} else if (arr[low] > arr[high]) {
swap(arr, --more, low);
} else {
low++;
}
}
swap(arr, more, high);
return new int[]{
less + 1, more};
}
}
48、Spark stage
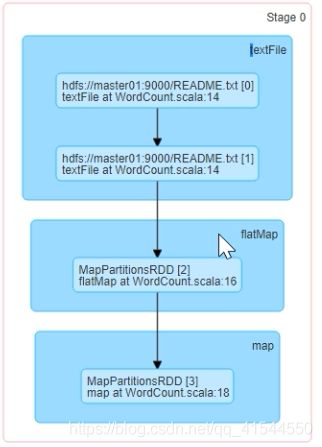
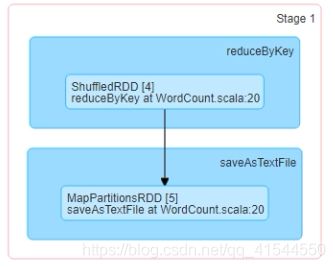
原始的RDD通过一系列转换就形成了DAG,根据RDD之间的宽窄依赖来将DAG切分成不同stage,对于窄依赖,partion的转换会在stage中通过pipline的形式计算,对于宽依赖,因为是shuffle,所以父RDD完成计算后才可以进行接卸来的计算。所以宽依赖就是划分stage的条件。
stage分为ShuffleMapStage和ResultStage,一个job被切分结果为0或多个ShuffleMapStage和一个ResultStage。
49、spark makerdd和Parrallilaze函数区别
调用parallelize()方法的时候,不指定分区数的时候,使用系统给出的分区数,而调用makeRDD()方法的时候,会为每个集合对象创建最佳分区,而这对后续的调用优化很有帮助。
50、Spark checkpoint 过程
checkpoint将RDD持久化保存在HDFS中,通过创建备份保证数据的安全性。切断RDD的血缘关系,直接用checkpoint路径下的数据,不需要知道父RDD是谁。
- 在HDFS上设置检查点路径
sc.setCheckpointDir(“hdfs://hadoop100:9000/checkpoint”) - 将rdd转化为携带当前时间戳并做checkpoint
val ch = rdd.map(_.toString + System.currentTimeMillis)
ch.checkpoint - ch.collect;注意要跟着action算子。但是不能直接在后面加,会报错。
需要长时间运算或运算量很大才能得到的RDD,血缘关系过长或依赖其他RDD很多的RDD。
checkpoint需要等到job完成后,会新启动专门的job区完成checkpoint。说明checkpoint操作,RDD会被运算两次,所以我们使用checkpoint的时候,可以加上rdd.cache,这样就不用运算两次,第二次直接用。
rdd.persist(StorageLevel.DISK_ONLY) 这样的方法,相当于 cache 到磁盘上,这样可以做到 rdd 第一次被计算得到时就存储到磁盘上,但是这样的方式是把RDD的partion交给BlockManager管理,当driver结束后,BlockManager的数据也会被清除;但是checkpoint这种方式是持久化到hdfs或本地文件夹,不手动remove的话是会一直存在的。
步骤为:
- rdd.checkpoint调用中,设置的目录中所有依赖的RDD都会被删除,函数必须在job运行之前调用执行。RDD会被RDDCheckPointData管理。
- 初始化后,RDDCheckPointData标记RDD为MarkedForCheckpoint。
- 每个job结束后会调用finalRDD.doCheckpoint(),finalRDD顺着血缘关系回溯扫描,碰到被标记为MarkedForCheckpoint的RDD将其标记为CheckPointingInProgress,然后把写磁盘的配置文件广播到其他worker节点上的blockmanage上。完成后启动一个job,这时会重新计算上一个job,如果已经cache了就直接用缓存中的RDD,然后把RDD输出到指定的目录下,每个分区一个文件,先写进临时文件,成功后进行rename,失败就回滚删除。
- job完成后,将该RDD的依赖清除掉,并设定该RDD状态为CHeckpointed。然后为该RDD强加一个依赖,设置该RDD的父RDD为CheckpointRDD,它负责以后读取该文件系统上的Checkpoint文件,生成该RDD的partion。
51、二次排序
public class MySortKey implements Ordered<MySortKey>, Serializable {
private int head;
private int middle;
private int last;
public MySortKey(int head, int middle, int last) {
this.head = head;
this.middle = middle;
this.last = last;
}
public MySortKey() {
}
public int gethead() {
return head;
}
public void sethead(int head) {
this.head = head;
}
public int getmiddle() {
return middle;
}
public void setmiddle(int middle) {
this.middle = middle;
}
public int getlast() {
return last;
}
public void setlast(int last) {
this.last = last;
}
@Override
public boolean $greater(MySortKey other) {
if (head > other.gethead()) {
return true;
} else if (head == other.gethead() &&
middle > other.getmiddle()) {
return true;
} else if (head == other.gethead() &&
middle == other.getmiddle() &&
last > other.getlast()) {
return true;
}
return false;
}
@Override
public boolean $greater$eq(MySortKey other) {
if ($greater(other)) {
return true;
} else if (head == other.gethead() &&
middle == other.getmiddle() &&
last == other.getlast()) {
return true;
}
return false;
}
@Override
public boolean $less(MySortKey other) {
if (head < other.gethead()) {
return true;
} else if (head == other.gethead() &&
middle < other.getmiddle()) {
return true;
} else if (head == other.gethead() &&
middle == other.getmiddle() &&
last < other.getlast()) {
return true;
}
return false;
}
@Override
public boolean $less$eq(MySortKey other) {
if ($less(other)) {
return true;
} else if (head == other.gethead() &&
middle == other.getmiddle() &&
last == other.getlast()) {
return true;
}
return false;
}
@Override
public int compare(MySortKey other) {
if (head - other.gethead() != 0) {
return (int) (head - other.gethead());
} else if (middle - other.getmiddle() != 0) {
return (int) (middle - other.getmiddle());
} else if (last - other.getlast() != 0) {
return (int) (last - other.getlast());
}
return 0;
}
@Override
public int compareTo(MySortKey other) {
if (head - other.gethead() != 0) {
return (int) (head - other.gethead());
} else if (middle - other.getmiddle() != 0) {
return (int) (middle - other.getmiddle());
} else if (last - other.getlast() != 0) {
return (int) (last - other.getlast());
}
return 0;
}
}
52、注册 hive udf
UDF: 一进一出 upper lower substring
UDAF:Aggregation 多进一出 count max min sum …
UDTF: Table-Generation 一进多出
临时:
add jar /home/hadoop/lib/hive-1.0.jar;
CREATE TEMPORARY FUNCTION sayHello AS 'com.ruozedata.bigdata.HelloUDF';
永久:
create function helloword as 'com.it.applogs.udf.DayStartUDF' using jar 'hdfs:/jars/hive-functions-0.0.1.jar';
53、SQL 去重方法
distinct,group by
54、Hive 分析和窗口函数
https://www.cnblogs.com/ZackSun/p/9713435.html
https://blog.csdn.net/abc200941410128/article/details/78408942
-
SUM、AVG、MIN、MAX。用于实现分组内所有和连续累积的统计。
-
NTILE,ROW_NUMBER,RANK,DENSE_RANK,CUME_DIST,PERCENT_RANK。
这一类主要用于排序编号,分组排序编号,取前topn,分组百分比和组内比例等用途。
注意: 这类序列函数不支持WINDOW子句。
-
LAG,LEAD,FIRST_VALUE,LAST_VALUE
这几个函数在时间序列中作用非常大,因为hive没有非等值链接,因此这几个函数可以替换序列类的表关联。
注意: 这几个函数不支持WINDOW子句。
-
GROUPING SETS,GROUPING__ID,CUBE,ROLLUP
这几个分析函数通常用于OLAP中,不能累加,而且需要根据不同维度上钻和下钻的指标统计,比如,分小时、天、月的UV数。
55、Hadoop 容错,一个节点挂掉然后又上线
sbin/hadoop-daemon.sh start datanode
sbin/yarn-daemon.sh start nodemanager
心跳机制,在Namenode和Datanode之间维持心跳检测,当由于网络故障之类的原因,导致Datanode发出的心跳包没有被Namenode正常收到的时候,Namenode就不会将任何新的IO操作派发给那个Datanode,该Datanode上的数据被认为是无效的,因此Namenode会检测是否有文件block的副本数目小于设置值,如果小于就自动开始复制新的副本并分发到其他Datanode节点。
检测文件block的完整性,HDFS会记录每个新创建的文件的所有block的校验和。当以后检索这些文件的时候,从某个节点获取block,会首先确认校验和是否一致,如果不一致,会从其他Datanode节点上获取该block的副本。
集群的负载均衡,由于节点的失效或者增加,可能导致数据分布的不均匀,当某个Datanode节点的空闲空间大于一个临界值的时候,HDFS会自动从其他Datanode迁移数据过来。
Namenode上的fsimage和edits日志文件是HDFS的核心数据结构,如果这些文件损坏了,HDFS将失效。因而,Namenode可以配置成支持维护多个FsImage和Editlog的拷贝。任何对FsImage或者Editlog的修改,都将同步到它们的副本上。它总是选取最近的一致的FsImage和Editlog使用。Namenode在HDFS是单点存在,如果 Namenode所在的机器错误,手工的干预是必须的。
文件的删除,删除并不是马上从Namenode移出namespace,而是放在/trash目录随时可恢复,直到超过设置时间才被正式移除。

56、掌握 JVM 原理
JVM是一个可以执行 Java 字节码的虚拟机进程。Java 源文件被编译成能被 Java 虚拟机执行的字节码文件( .class ),而字节码文件又通过Java虚拟机中的解释器,编译成特定机器上的机器码。


57、Java 并发原理
有两个或者多个线程,如果程序在单核处理器上运行,多个线程将交替地换入或者换出内存,这些线程是同时“存在”的,每个线程都处于执行过程中的某个状态,如果运行在多核处理器上,此时,程序中的每个线程都将分配到一个处理器核上,因此可以同时运行。
并发(Concurrency)和并行(Parallellism)是:
- 解释一:并行是指两个或者多个事件在同一时刻发生;而并发是指两个或多个事件在同一时间间隔发生。
- 解释二:并行是在不同实体上的多个事件;并发是在同一实体上的多个事件。
- 解释三:在一台处理器上“同时”处理多个任务,在多台处理器上同时处理多个任务。如 Hadoop 分布式集群。
所以并发编程的目标是,充分的利用处理器的每一个核,以达到最高的处理性能。
http://ifeve.com/java-multi-threading-concurrency-interview-questions-with-answers/
58、多线程的实现方法
- 继承 Thread 类创建线程类。
public class ThreadDemo01 extends Thread{
public ThreadDemo01(){
//编写子类的构造方法,可缺省
}
public void run(){
//编写自己的线程代码
System.out.println(Thread.currentThread().getName());
}
public static void main(String[] args){
ThreadDemo01 threadDemo01 = new ThreadDemo01();
threadDemo01.setName("我是自定义的线程1");
threadDemo01.start();
System.out.println(Thread.currentThread().toString());
}
}
- 通过 Runnable 接口创建线程类。
public class ThreadDemo02 {
public static void main(String[] args){
System.out.println(Thread.currentThread().getName());
Thread t1 = new Thread(new MyThread(), "ThreadWithRunnable");
t1.start();
}
}
class MyThread implements Runnable{
@Override
public void run() {
// TODO Auto-generated method stub
System.out.println(Thread.currentThread().getName()+"-->我是通过实现接口的线程实现方式!");
}
}
- 通过 Callable 和 Future 创建线程。
public class ThreadDemo03 {
public static void main(String[] args) {
Callable<Object> oneCallable = new Tickets<Object>();
FutureTask<Object> oneTask = new FutureTask<Object>(oneCallable);
Thread t = new Thread(oneTask);
System.out.println(Thread.currentThread().getName());
t.start();
}
}
class Tickets<Object> implements Callable<Object>{
//重写call方法
@Override
public Object call() throws Exception {
System.out.println(Thread.currentThread().getName()+"-->我是通过实现Callable接口通过FutureTask包装器来实现的线程");
return null;
}
}
- 通过线程池创建线程
import java.io.Serializable;
import java.util.concurrent.ArrayBlockingQueue;
import java.util.concurrent.ThreadPoolExecutor;
import java.util.concurrent.TimeUnit;
public class ThreadPoolExcutorDemo {
private static int produceTaskSleepTime = 5;
private static int consumeTaskSleepTime = 5000;
private static int produceTaskMaxNumber = 20; //定义最大添加10个线程到线程池中
public static void main(String[] args) {
//构造一个线程池
ThreadPoolExecutor threadPool = new ThreadPoolExecutor(2, 4, 3,
TimeUnit. SECONDS, new ArrayBlockingQueue<Runnable>(3),
new ThreadPoolExecutor.DiscardOldestPolicy());
for( int i=1; i<= produceTaskMaxNumber;i++){
try {
//一个任务,并将其加入到线程池
String work= "work@ " + i;
System. out.println( "put :" +work);
threadPool.execute( new ThreadPoolTask(work));
//便于观察,等待一段时间
Thread. sleep(produceTaskSleepTime);
} catch (Exception e) {
e.printStackTrace();
}
}
}
/**
* 线程池执行的任务
* @author zhu
*/
public static class ThreadPoolTask implements Runnable,Serializable{
private static final long serialVersionUID = 0;
//保存任务所需要的数据
private Object threadPoolTaskData;
ThreadPoolTask(Object works){
this. threadPoolTaskData =works;
}
public void run(){
//处理一个任务,这里的处理方式太简单了,仅仅是一个打印语句
System. out.println( "start------"+threadPoolTaskData );
try {
//便于观察,等待一段时间
Thread. sleep(consumeTaskSleepTime);
} catch (Exception e) {
e.printStackTrace();
}
threadPoolTaskData = null;
}
public Object getTask(){
return this. threadPoolTaskData;
}
}
}
59、@@@@@@RocksDBStatebackend实现(源码级别)
60、HashMap、ConcurrentMap和 Hashtable 区别:
https://www.jianshu.com/p/a91f72310545
ConcurrentMap:
- JDK1.7的ConcurrentHashMap采用 分段锁的机制,实现并发的更新操作,底层采用数组+链表的存储结构。其包含两个核心静态内部类 Segment和HashEntry。其中Segment继承ReentrantLock用来充当锁的角色,每个 Segment 对象守护每个散列映射表的若干个桶。HashEntry 用来封装映射表的键/值对;每个桶是由若干个 HashEntry 对象链接起来的链表。一个 ConcurrentHashMap 实例中包含由若干个 Segment 对象组成的数组。如图:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-E4JmIL52-1590579243614)(https://github.com/wangzhiwubigdata/God-Of-BigData/raw/master/%E5%B9%B6%E5%8F%91%E5%AE%B9%E5%99%A8/%E5%A4%A7%E6%95%B0%E6%8D%AE%E6%88%90%E7%A5%9E%E4%B9%8B%E8%B7%AF-Java%E9%AB%98%E7%BA%A7%E7%89%B9%E6%80%A7%E5%A2%9E%E5%BC%BA(ConcurrentHashMap)].resources/4C9E2E7A-9471-46E4-BC40-3F7803EA8C2B.png)
-
JDK1.8的ConcurrentHashMap已经抛弃了Segment分段锁机制,利用CAS+Synchronized来保证并发更新的安全,底层采用数组+链表+红黑树的存储结构。JDK8中彻底放弃了Segment转而采用的是Node, 保存key,value及key的hash值的数据结构。其中value和next都用volatile修饰,保证并发的可见性。时间复杂度:从原来的遍历链表O(n),变成遍历红黑树O(logN)。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-r2Rr2AHR-1590579243616)(https://github.com/wangzhiwubigdata/God-Of-BigData/raw/master/%E5%B9%B6%E5%8F%91%E5%AE%B9%E5%99%A8/%E5%A4%A7%E6%95%B0%E6%8D%AE%E6%88%90%E7%A5%9E%E4%B9%8B%E8%B7%AF-Java%E9%AB%98%E7%BA%A7%E7%89%B9%E6%80%A7%E5%A2%9E%E5%BC%BA(ConcurrentHashMap)].resources/33571F0A-5AF5-4191-AC11-06AC6A8D8E03.png)
CAS是compare and swap的缩写,即我们所说的比较交换。它是一种乐观锁,CAS包含三个操作数,内存位置(V)、预期原值(A)和新值(B),如果内存地址里面的值和A的值是一样的,那么就将内存里面的值更新成B。CAS是通过无限循环来获取数据的,若果在第一轮循环中,a线程获取地址里面的值被b线程修改了,那么a线程需要自旋,到下次循环才有可能机会执行。
CAS 操作有什么缺点?
1)ABA 问题
比如说一个线程 one 从内存位置 V 中取出 A ,这时候另一个线程 two 也从内存中取出 A ,并且 two 进行了一些操作变成了 B ,然后 two 又将 V 位置的数据变成 A ,这时候线程 one 进行 CAS 操作发现内存中仍然是 A ,然后 one 操作成功。尽管线程 one 的 CAS 操作成功,但可能存在潜藏的问题。
从 Java5 开始 JDK 的 atomic包里提供了一个类 AtomicStampedReference 来解决 ABA 问题。
2)循环时间长开销大
对于资源竞争严重(线程冲突严重)的情况,CAS 自旋的概率会比较大,从而浪费更多的 CPU 资源,效率低于 synchronized 。
3)只能保证一个共享变量的原子操作
当对一个共享变量执行操作时,我们可以使用循环 CAS 的方式来保证原子操作,但是对多个共享变量操作时,循环 CAS 就无法保证操作的原子性,这个时候就可以用锁。
61、@@@@@@Flink Checkpoint 是怎么做的,作用到算子还是chain
62、@@@@@@Checkpoint失败了的监控
63、String、StringBuffer和 StringBuilder的区别
String、StringBuffer和StringBuilder类用来封装字符串,并提供了一系列操作字符串对象的方法。
-
可变与不可变:
String类是一个不可变类,即创建String对象后,该对象中的字符串是不可改变的,直到这个对象被销毁。StringBuffer与StringBuilder都继承自AbstractStringBuilder类,在AbstractStringBuilder中也是使用字符数组保存字符串,是可变类。String适合在需要被共享的场合中使用,当一个字符串经常被修改时,最好使用StringBuffer实现。
-
初始化方式:
当创建String对象时,可以利用构造方法String str = new String(“Java”)的方式来对其进行初始化,也可以直接用赋值的方式String s = "Java"来初始化。而StringBuffer只能使用构造方法StringBuffer sb = new StringBuffer(“hello”)的方式初始化。
-
字符串修改方式:
String字符串修改方法是首先创建一个StringBuffer,其次调用StringBuffer的append方法,最后调用StringBuffer的toString()方法把结果返回,示例代码如下:
String str = "hello"; str += "java";以上代码等价于下面的代码:
StringBuffer sb = new StringBuffer(str); sb.append("java"); str = sb.toString();上述String字符串的修改过程要比StringBuffer多一些额外操作,会增加一些临时的对象,从而导致程序的执
行效率降低。StringBuffer和StringBuilder在修改字符串方面比String的性能要高,他们不产生临时对象,对
象可以多次修改。
-
是否实现了equals和hashCode方法:
String实现了equals()方法和hashCode()方法,new String(“java”).equals(new String(“java”))的结果为true;
而StringBuffer没有实现equals()方法和hashCode()方法,因此,new StringBuffer(“java”).equals(new
StringBuffer(“java”))的结果为false,将StringBuffer对象存储进Java集合类中会出现问题。
-
是否线程安全:
StringBuffer与StringBuilder都提供了一系列插入、追加、改变字符串里的字符序列的方法,它们的用法基本相同,只是StringBuilder是线程不安全的,StringBuffer是线程安全的,。如果只是在单线程中使用字符串缓冲区,则StringBuilder的效率会高些,但是当多线程访问时,最好使用StringBuffer。
64、Kafka存储流程,为什么高吞吐:
https://blog.51cto.com/12445535/2432350
//存储流程:
写流程

步骤:
1.连接ZK集群,从ZK中拿到对应topic的partition信息和partition的Leader的相关信息
2.连接到对应Leader对应的broker
3.将消息发送到partition的Leader上
4.其他Follower从Leader上复制数据
5.依次返回ACK
6.直到所有ISR中的数据写完成,才完成提交,整个写过程结束
因为是描述写流程,没有将replica与zk的心跳通讯表达出来,心跳通讯就是为了保证kafka高可用。一旦Leader挂了,或者Follower同步超时或者同步过慢,都会通过心跳将信息报告给ZK,由ZK做Leader选举或者将Follower从ISR中移动到OSR中
读流程
步骤:
1.连接ZK集群,从ZK中拿到对应topic的partition信息和partition的Leader的相关信息
2.连接到对应Leader对应的broker
3.consumer将自己保存的offset发送给Leader
4.Leader根据offset等信息定位到segment(索引文件和日志文件)
5.根据索引文件中的内容,定位到日志文件中该偏移量对应的开始位置,读取相应长度的数据并返回给consumer
特点
1)吞吐量
高吞吐是 Kafka 需要实现的核心目标之一,为此 kafka 做了以下一些设计:
-
1、数据磁盘持久化:消息不在内存中 Cache ,直接写入到磁盘,充分利用磁盘的顺序读写性能。
直接使用 Linux 文件系统的 Cache ,来高效缓存数据。
-
2、zero-copy:减少 IO 操作步骤
采用 Linux Zero-Copy 提高发送性能。
-
- 传统的数据发送需要发送 4 次上下文切换。
- 采用 sendfile 系统调用之后,数据直接在内核态交换,系统上下文切换减少为 2 次。根据测试结果,可以提高 60% 的数据发送性能。Zero-Copy 详细的技术细节可以参考 《Efficient data transfer through zero copy》 文章。
-
3、数据批量发送
-
4、数据压缩
-
5、Topic 划分为多个 Partition ,提高并行度。
数据在磁盘上存取代价为
O(1)。发布者发到某个 Topic 的消息会被均匀的分布到多个 Partition 上(随机或根据用户指定的回调函数进行分布),Broker 收到发布消息往对应 Partition 的最后一个 segment 上添加该消息。
当某个 segment上 的消息条数达到配置值或消息发布时间超过阈值时,segment上 的消息会被 flush 到磁盘,只有 flush 到磁盘上的消息订阅者才能订阅到,segment 达到一定的大小后将不会再往该 segment 写数据,Broker 会创建新的 segment 文件。 -
- Kafka 以 Topic 来进行消息管理,每个 Topic 包含多个 Partition ,每个 Partition 对应一个逻辑 log ,有多个 segment 文件组成。
- 每个 segment 中存储多条消息(见下图),消息 id 由其逻辑位置决定,即从消息 id 可直接定位到消息的存储位置,避免 id 到位置的额外映射。
- 每个 Partition 在内存中对应一个 index ,记录每个 segment 中的第一条消息偏移。
2)负载均衡
- 1、Producer 根据用户指定的算法,将消息发送到指定的 Partition 中。
- 2、Topic 存在多个 Partition ,每个 Partition 有自己的replica ,每个 replica 分布在不同的 Broker 节点上。多个Partition 需要选取出 Leader partition ,Leader Partition 负责读写,并由 Zookeeper 负责 fail over 。
- 3、相同 Topic 的多个 Partition 会分配给不同的 Consumer 进行拉取消息,进行消费。
3)拉取系统
由于 Kafka Broker 会持久化数据,Broker 没有内存压力,因此, Consumer 非常适合采取 pull 的方式消费数据,具有以下几点好处:
- 1、简化 Kafka 设计。
- 2、Consumer 根据消费能力自主控制消息拉取速度。
- 3、Consumer 根据自身情况自主选择消费模式,例如批量,重复消费,从尾端开始消费等。
4)可扩展性
通过 Zookeeper 管理 Broker 与 Consumer 的动态加入与离开。
- 当需要增加 Broker 节点时,新增的 Broker 会向 Zookeeper 注册,而 Producer 及 Consumer 会根据注册在 Zookeeper 上的 watcher 感知这些变化,并及时作出调整。
- 当新增和删除 Consumer 节点时,相同 Topic 的多个 Partition 会分配给剩余的 Consumer 们。
很多人都知道Kafka吞吐量高,延迟低,那么为什么Kafka会这么快?
**顺序IO**
首先,Kafka使用了顺序IO(Sequential IO),并极力避免随机磁盘访问(Random Disk Access)。前者的写入速度比后者快了一个数量级,比如在一个由6块7200转SATA硬盘组成的磁盘阵列上,顺序写入的速度可以达到300MB/S,而随机写入速度只有50KB/S。差距如此之大,难怪Kafka会快得飞起来。
Kafka所采用的提交日志就是以追加的方式写入分区的,就是说单个分区的写入是可以保证顺序的,没有删除和更新操作,因此避免了随机写入。另外,从分区读取数据的时候也是按顺序读取的,避免了随机读取。

那么问题来了,就算顺序IO再快,也快不过内存,那么为什么Kafka不用内存来保存数据呢?第一个原因大概所有人都知道,内存虽快,但比硬盘要贵得多。Kafka作为一个大数据生态系统的一员,是为保存海量数据而生的,使用内存来保存海量数据显然是不现实的。另外,Kafka的高可用是通过创建多个副本来实现的,一个消息可能会被复制三份五份,这无疑又增加了存储开销,使用内存来存储就更是天方夜谭。除此之外,Kafka运行在JVM上,如果内存堆中的对象太多,必然会在垃圾回收时造成严重的延迟,从而影响系统的整体性能。
**内存映射文件**
内存映射文件将磁盘上的文件内容与内存映射起来,我们往内存里写入数据,操作系统会在稍后把数据冲刷到磁盘上。所以,在写入数据时几乎就是写入内存的速度,这是Kafka快到飞起的另一个原因。
那么问题又来了,既然可以使用内存映射文件,那么为什么不直接使用内存呢?这个问题已经回答过了,就不再累述了。
**零拷贝**
当Kafka客户端从服务器读取数据时,如果不使用零拷贝技术,那么大致需要经历这样的一个过程:
1. 操作系统将数据从磁盘上读入到内核空间的读缓冲区中。这个传输是通过DMA搬运的。
2. 应用程序(也就是Kafka)从内核空间的读缓冲区将数据拷贝到用户空间的缓冲区中。这个传输是通过CPU搬运的。
3. 应用程序将数据从用户空间的缓冲区再写回到内核空间的socket缓冲区中。这个传输,还是由CPU搬运的。
4. 操作系统将socket缓冲区中的数据拷贝到网卡(NIC缓冲区)中,然后通过网络发送给客户端。这个传输又是通过DMA搬运的。

从图中可以看到,数据在内核空间和用户空间之间穿梭了两次,那么能否避免这个多余的过程呢?当然可以,Kafka使用了零拷贝技术,也就是 调用了Java NIO库,具体是FileChannel里面的transferTo方法。我们的数据并没有读到中间的应用内存里面,而是直接通过Channel,写入到对应的网络设备里。
并且,对于Socket的操作,也不是写入到Socket的Buffer里面,而是直接根据描述符(Descriptor)写到到网卡的缓冲区里面。
第一次,是通过DMA,从硬盘直接读到操作系统内核的读缓冲区里面。
第二次,则是根据Socket的描述符信息,直接从读缓冲区里面,写入到网卡NIC缓冲区里面。

**应用层面的优化**
除了利用底层的技术外,Kafka还在应用程序层面提供了一些手段来提升性能。最明显的就是使用批次。在向Kafka写入数据时,可以启用批次写入,这样可以避免在网络上频繁传输单个消息带来的延迟和带宽开销。假设网络带宽为10MB/S,一次性传输10MB的消息比传输1KB的消息10000万次显然要快得多。
**写在后面**
需要注意的是,作为大数据生态系统的一员,Kafka在设计之初就是为了满足高吞吐量、低延迟、高可用等方面的需求,所以这些技术可以派上用场。但如果换成其他消息中间件,就不一定也能照搬这些技术,具体还是要根据产品的特点来决定。
65、Spark 优化方法举例
算子调优之filter过后使用coalesce减少分区数量.xls
算子调优之MapPartitions提升Map类操作性能.xls
算子调优之reduceByKey本地聚合介绍.xls
算子调优之使用foreachPartition优化写数据库性能.xls
[算子调优之使用repartition解决Spark SQL低并行度的性能问题.xls](D:\Java\大数据\知识星球\SparkStormHadoop\spark\spark调优\算子调优之使用repartition解决Spark SQL低并行度的性能问题.xls)
性能调优之在实际项目中广播大变量.xls
性能调优之在实际项目中调节并行度.xls
性能调优之在实际项目中分配更多资源.xls
性能调优之在实际项目中使用fastutil优化数据格式.xls
性能调优之在实际项目中使用Kryo序列化.xls
性能调优之在实际项目中调节数据本地化等待时长.xls
性能调优之在实际项目中重构RDD架构以及RDD持久化.xls
66、keyby 的最大并行度
**Flink:**设置最大并行度,实际上调用的方法是setMaxParallelism(),其调用位置和setParallelism()一样。
默认的最大并行度是近似于operatorParallelism + (operatorParallelism / 2),下限是127,上线是32768.
67、@@@@@@Flink 优化方法
68、kafka isr 机制
Kafka 的副本机制,是多个 Broker 节点对其他节点的 Topic 分区的日志进行复制。当集群中的某个节点出现故障,访问故障节点的请求会被转移到其他正常节点(这一过程通常叫 Reblance),Kafka 每个主题的每个分区都有一个主副本以及 0 个或者多个副本,副本保持和主副本的数据同步,当主副本出故障时就会被替代。

下面说的 Leader 指的是每个 Topic 的某个分区的 Leader ,而不是 Broker 集群中的【集群控制器】。
在 Kafka 中并不是所有的副本都能被拿来替代主副本,所以在 Kafka 的Leader 节点中维护着一个 ISR(In sync Replicas)集合,翻译过来也叫正在同步中集合,在这个集合中的需要满足两个条件:
- 1、节点必须和 Zookeeper 保持连接。
- 2、在同步的过程中这个副本不能落后主副本太多。
另外还有个 AR(Assigned Replicas)用来标识副本的全集,OSR 用来表示由于落后被剔除的副本集合,所以公式如下:
- ISR = Leader + 没有落后太多的副本。
- AR = OSR + ISR 。
这里先要说下两个名词:HW 和 LEO 。
- HW(高水位 HighWatermark),是 Consumer 能够看到的此 Partition 的位置。
- LEO(logEndOffset),是每个 Partition 的 log 最后一条 Message 的位置。
- HW 能保证 Leader 所在的 Broker 失效,该消息仍然可以从新选举的Leader 中获取,不会造成消息丢失。
当 Producer 向 Leader 发送数据时,可以通过request.required.acks 参数来设置数据可靠性的级别:
- 1(默认):这意味着 Producer 在 ISR 中的 Leader 已成功收到的数据并得到确认后发送下一条 message 。如果 Leader 宕机了,则会丢失数据。
- 0:这意味着 Producer 无需等待来自 Broker 的确认而继续发送下一批消息。这种情况下数据传输效率最高,但是数据可靠性确是最低的。
- -1:Producer 需要等待 ISR 中的所有 Follower 都确认接收到数据后才算一次发送完成,可靠性最高。但是这样也不能保证数据不丢失,比如当 ISR 中只有 Leader 时(其他节点都和 Zookeeper 断开连接,或者都没追上),这样就变成了
acks=1的情况。
69、kafka partition 的 4个状态
https://www.cnblogs.com/zhy-heaven/p/10994193.html
PartitionStateMachine 记录着集群所有 Partition 的状态信息,它决定着一个 Partition 处在什么状态以及它在什么状态下可以转变为什么状态,Kafka 中 Partition 的状态总共有以下四种类型:
- NonExistentPartition:这个代表着这个 Partition 之前没有被创建过或者之前创建了现在又被删除了,它有效的前置状态是 OfflinePartition;
- NewPartition:Partition 创建后,它将处于这个状态,这个状态的 Partition 还没有 leader 和 isr,它有效的前置状态是 NonExistentPartition;
- OnlinePartition:一旦这个 Partition 的 leader 被选举出来了,它将处于这个状态,它有效的前置状态是 NewPartition、OnlinePartition、OfflinePartition;
- OfflinePartition:如果这个 Partition 的 leader 掉线,这个 Partition 将被转移到这个状态,它有效的前置状态是 NewPartition、OnlinePartition、OfflinePartition。
分区状态机转移图如下所示:

70、kafka 副本的 7个状态
https://www.cnblogs.com/zhy-heaven/p/10994193.html
ReplicaStateMachine 记录着集群所有 Replica 的状态信息,它决定着一个 replica 处在什么状态以及它在什么状态下可以转变为什么状态,Kafka 中副本的状态总共有以下七种类型:
- NewReplica:这种状态下 Controller 可以创建这个 Replica,这种状态下该 Replica 只能作为 follower,它可以是当创建topic或分区重新分配期间副本被创建,也可以是 Replica 删除后的一个临时状态,它有效的前置状态是 NonExistentReplica;
- OnlineReplica:一旦这个 Replica 被分配到指定的 Partition 上,并且 Replica 创建完成,那么它将会被置为这个状态,在这个状态下,这个 Replica 既可以作为 leader 也可以作为 follower,它有效的前置状态是 NewReplica、OnlineReplica 或 OfflineReplica;
- OfflineReplica:如果一个 Replica 挂掉(所在的节点宕机或者其他情况),该 Replica 将会被转换到这个状态,它有的效前置状态是 NewReplica、OfflineReplica 或者 OnlineReplica;
- ReplicaDeletionStarted:Replica 开始删除时被置为的状态,它有效的前置状态是 OfflineReplica;
- ReplicaDeletionSuccessful:如果 Replica 在删除时没有遇到任何错误信息,它将被置为这个状态,这个状态代表该 Replica 的数据已经从节点上清除了,它有效的前置状态是 ReplicaDeletionStarted;
- ReplicaDeletionIneligible:如果 Replica 删除失败,它将会转移到这个状态,这个状态意思是非法删除,也就是删除是无法成功的,它有效的前置状态是 ReplicaDeletionStarted;
- NonExistentReplica:如果 Replica 删除成功,它将被转移到这个状态,它有效的前置状态是:ReplicaDeletionSuccessful。
上面的状态中其中后面4是专门为 Replica 删除而服务的,副本状态机转移图如下所示:

71、@@@@@@Flink的taskmanager 的数量:
https://cloud.tencent.com/developer/article/1500184
72、if 和 switch 的性能及 switch 支持的参数
switch的执行速度并不是一直都超过if,当数据量达到万级或者百万级时,if的执行速度反而会比switch更快
switch语句,他所支持的参数类型有三类:
1、基本数据类型:byte、short、char、int
2、引用数据类型:Byte、Short、Character、Integer、String
3、特殊类型:枚举
其实,switch只支持int类型!
byte、short、char可以自动转换为int,这四种基本数据类型所对应的封装类,通过自动拆箱机制,也可以作为参数。枚举的话就是枚举常量的序号是int类型的。String的话就是hashcode方法,返回的哈希码是int类型的。
不支持long、float、double、boolean四种基本类型。
73、kafka 零拷贝:
https://cloud.tencent.com/developer/article/1421266
https://blog.csdn.net/weixin_30235225/article/details/102054125
当Kafka客户端从服务器读取数据时,如果不使用零拷贝技术,那么大致需要经历这样的一个过程:
1. 操作系统将数据从磁盘上读入到内核空间的读缓冲区中。这个传输是通过DMA搬运的。
2. 应用程序(也就是Kafka)从内核空间的读缓冲区将数据拷贝到用户空间的缓冲区中。这个传输是通过CPU搬运的。
3. 应用程序将数据从用户空间的缓冲区再写回到内核空间的socket缓冲区中。这个传输,还是由CPU搬运的。
4. 操作系统将socket缓冲区中的数据拷贝到网卡(NIC缓冲区)中,然后通过网络发送给客户端。这个传输又是通过DMA搬运的。
从图中可以看到,数据在内核空间和用户空间之间穿梭了两次,那么能否避免这个多余的过程呢?当然可以,Kafka使用了零拷贝技术,也就是 调用了Java NIO库,具体是FileChannel里面的transferTo方法。我们的数据并没有读到中间的应用内存里面,而是直接通过Channel,写入到对应的网络设备里。
并且,对于Socket的操作,也不是写入到Socket的Buffer里面,而是直接根据描述符(Descriptor)写到到网卡的缓冲区里面。
第一次,是通过DMA,从硬盘直接读到操作系统内核的读缓冲区里面。
第二次,则是根据Socket的描述符信息,直接从读缓冲区里面,写入到网卡NIC缓冲区里面。
74、hadoop 节点容错机制:
https://www.cnblogs.com/zhangyinhua/p/7681146.html
心跳机制,在Namenode和Datanode之间维持心跳检测,当由于网络故障之类的原因,导致Datanode发出的心跳包没有被Namenode正常收到的时候,Namenode就不会将任何新的IO操作派发给那个Datanode,该Datanode上的数据被认为是无效的,因此Namenode会检测是否有文件block的副本数目小于设置值,如果小于就自动开始复制新的副本并分发到其他Datanode节点。
检测文件block的完整性,HDFS会记录每个新创建的文件的所有block的校验和。当以后检索这些文件的时候,从某个节点获取block,会首先确认校验和是否一致,如果不一致,会从其他Datanode节点上获取该block的副本。
集群的负载均衡,由于节点的失效或者增加,可能导致数据分布的不均匀,当某个Datanode节点的空闲空间大于一个临界值的时候,HDFS会自动从其他Datanode迁移数据过来。
Namenode上的fsimage和edits日志文件是HDFS的核心数据结构,如果这些文件损坏了,HDFS将失效。因而,Namenode可以配置成支持维护多个FsImage和Editlog的拷贝。任何对FsImage或者Editlog的修改,都将同步到它们的副本上。它总是选取最近的一致的FsImage和Editlog使用。Namenode在HDFS是单点存在,如果 Namenode所在的机器错误,手工的干预是必须的。
文件的删除,删除并不是马上从Namenode移出namespace,而是放在/trash目录随时可恢复,直到超过设置时间才被正式移除。
75、HDFS 的副本分布策略
每一个block都可以在多个datanode上存储多个副本(副本数量也可以通过参数设置dfs.replication)
机架感知:
本地节点:如果是在集群内提交的就在提交的那个节点上,如果那个节点空间不足、负载过重,就选一个同一个机架内的合适的节点。
第一个副本:本地机架节点选择一个
第二个副本:放置在与第一个副本不同的机架的节点上,增加副本可靠性
第三个副本:在与第一个副本同一机架的另外一个节点上。
77、@@@@@@Kudu 和Impala 权限控制
78、Time_wait状态?
当server处理完client的请求后立刻closesocket此时会出现time_wait状态.
在TCP连接中四次挥手关闭连接时,主动关闭连接的一方(上图中时Client)会在发送最后一条ACK报文后维持一段时长2MSL(MSL指的是数据包在网络中的最大生存时间)的等待时间后才会真正关闭连接到CLOSED状态,该时间段内主动关闭方的状态为TIME_WAIT。

1.为实现TCP全双工连接的可靠释放
当服务器先关闭连接,如果不在一定时间内维护一个这样的TIME_WAIT状态,那么当被动关闭的一方的FIN到达时,服务器的TCP传输层会用RST包响应对方,这样被对方认为是有错误发生,事实上这只是正常的关闭连接工程,并没有异常
2.为使过期的数据包在网络因过期而消失
在这条连接上,客户端发送了数据给服务器,但是在服务器没有收到数据的时候服务器就断开了连接
现在数据到了,服务器无法识别这是新连接还是上一条连接要传输的数据,一个处理不当就会导致诡异的情况发生
虽然按道理,四个报文都发送完毕,我们可以直接进入CLOSE状态了,但是我们必须假象网络是不可靠的,有可以最后一个ACK丢失。所以TIME_WAIT状态就是用来重发可能丢失的ACK报文。
79、三次握手交换了什么? SYN,ACK,SEQ,窗口大小:
https://blog.csdn.net/whuslei/article/details/6667471
3次握手建立链接,4次握手断开链接。
80、hashmap 1.7和1.8 的区别? :
https://blog.csdn.net/qq_36520235/article/details/82417949
https://blog.csdn.net/IM_MESSI/article/details/83386726
1.7 是 数组+链表;1.8 是数组+链表+红黑树,为了避免死循环、提高插入效率 log(N)
81、concurrenthashmap 1.7和1.8?
分段锁,属于细粒度,比 hashtable 效率高, cas
为了保证原子操作和线程安全的
82、Kafka 的ack
当 Producer 向 Leader 发送数据时,可以通过request.required.acks 参数来设置数据可靠性的级别:
acks=1(默认):意味着ISR中的Leader成功接收到消息,并进行了确认后才发送下一条。
acks=0:意味着Producer无需等待来自Broker的确认就发送下一条数据,这种模式下数据传输效率最快,但是数据会丢失,可靠性最低。
acks=all或者是-1:意味着Producer需要等待ISR中所有的Follower都成功接收到了数据并进行了确认,才发送下一条数据,可靠性最高,但是也不会完全保证数据不丢失,比如只有leader存在,其他节点与zookeeper断开连接或者是都没追上,全进了OSR。这样变成了acks=1。所以在Borker端设置 min.insync.replicas 参数:这个值必须大于 1 ,这个是要求一个 leader 至少感知到有至少一个 follower 还保持连接,没掉队,这样才能确保 leader 挂了至少还有一个 follower 。
83、sql 去重方法
group by 、distinct、窗口函数
84、哪些 hive sql 不能在 spark sql 上运行:
https://spark.apache.org/docs/2.2.0/sql-programming-guide.html#unsupported-hive-functionality
spark不支持hive的桶(bucket)
不支持union数据类型
不支持unique join
不支持列统计信息收集
不支持insert overwrite/into directory 语法
85、 什么情况下发生死锁? (就是说说条件,然后举个例子):
https://blog.csdn.net/hd12370/article/details/82814348
两个或两个以上的进程(或线程)在执行过程中,因争夺资源而造成的一种互相等待的现象,若无外力作用,它们都将无法推进下去。
产生死锁的必要条件:
- 互斥条件:所谓互斥就是进程在某一时间内独占资源。
- 请求与保持条件:一个进程因请求资源而阻塞时,对已获得的资源保持不放。
- 不剥夺条件:进程已获得资源,在末使用完之前,不能强行剥夺。
- 循环等待条件:若干进程之间形成一种头尾相接的循环等待资源关系。
86、事务隔离级别? 可重复读、不可重复读、读未提交、串行化
事务的基本要素(ACID)
1、原子性(Atomicity):事务开始后所有操作,要么全部做完,要么全部不做,不可能停滞在中间环节。事务执行过程中出错,会回滚到事务开始前的状态,所有的操作就像没有发生一样。也就是说事务是一个不可分割的整体,就像化学中学过的原子,是物质构成的基本单位。
2、一致性(Consistency):事务开始前和结束后,数据库的完整性约束没有被破坏 。比如A向B转账,不可能A扣了钱,B却没收到。
3、隔离性(Isolation):同一时间,只允许一个事务请求同一数据,不同的事务之间彼此没有任何干扰。比如A正在从一张银行卡中取钱,在A取钱的过程结束前,B不能向这张卡转账。
4、持久性(Durability):事务完成后,事务对数据库的所有更新将被保存到数据库,不能回滚。
事务的并发问题
1、脏读:事务A读取了事务B更新的数据,然后B回滚操作,那么A读取到的数据是脏数据
2、不可重复读:事务 A 多次读取同一数据,事务 B 在事务A多次读取的过程中,对数据作了更新并提交,导致事务A多次读取同一数据时,结果不一致。
3、幻读:系统管理员A将数据库中所有学生的成绩从具体分数改为ABCDE等级,但是系统管理员B就在这个时候插入了一条具体分数的记录,当系统管理员A改结束后发现还有一条记录没有改过来,就好像发生了幻觉一样,这就叫幻读。
小结:不可重复读的和幻读很容易混淆,不可重复读侧重于修改,幻读侧重于新增或删除。解决不可重复读的问题只需锁住满足条件的行,解决幻读需要锁表
隔离性
- 读未提交(read uncommitted):一个事务还没有提交时,它做的变更就能被别的事务看到。
- 读提交(read committed):一个事物提交之后,它做的变更才会被其他事务看到。
- 可重复读(repeatable read):一个事物执行过程中看到的数据,总是跟这个事务在启动时看到的数据是一致的。未提交变更对其他事务也是不可见的。
- 串行化(serializable):对于同一行记录,写会加“写锁”,读会加“读锁”,当出现锁冲突时,后访问的事务需要等前一个事务执行完成,才能继续执行。
| 事务隔离级别 | 脏读 | 不可重复读 | 幻读 |
|---|---|---|---|
| 读未提交(read-uncommitted) | 是 | 是 | 是 |
| 不可重复读(read-committed) | 否 | 是 | 是 |
| 可重复读(repeatable-read) | 否 | 否 | 是 |
| 串行化(serializable) | 否 | 否 | 否 |
https://blog.csdn.net/xcy1193068639/article/details/85058641
https://www.cnblogs.com/wyaokai/p/10921323.html
87、spark shuffle 和 hadoop shuffle :
https://0x0fff.com/spark-architecture-shuffle/
https://www.cnblogs.com/itboys/p/9226479.html
88、spark 静态内存和动态内存:
https://blog.csdn.net/high2011/article/details/84575442
静态内存管理(Spark 1.6.x版本前的策略)
静态内存管理图示——堆内

静态内存管理图示——堆外

统一内存管理(Spark 1.6.x以后的策略)
统一内存管理图示——堆内

统一内存管理图示——堆外

其中最重要的优化在于动态占用机制,其规则如下:
1\设定基本的存储内存和执行内存区域(spark.storage.storageFraction 参数),该设定确定了双方各自拥有的空间的范围
双方的空间都不足时,则存储到硬盘;若己方空间不足而对方空余时,可借用对方的空间;(存储空间不足是指不足以放下一个完整的 Block)
2\执行内存的空间被对方占用后,可让对方将占用的部分转存到硬盘,然后"归还"借用的空间
3\存储内存的空间被对方占用后,无法让对方"归还",因为需要考虑 Shuffle 过程中的很多因素,实现起来较为复杂
动态占用机制图示

凭借统一内存管理机制,Spark 在一定程度上提高了堆内和堆外内存资源的利用率,降低了开发者维护 Spark 内存的难度,但并不意味着开发者可以高枕无忧。譬如,所以如果存储内存的 空间太大 或者说 缓存的数据 过多,反而会导致频繁的全量垃圾回收,降低任务执行时的性能,因为缓存的 RDD 数据通常都是长期驻留内存的。所以要想充分发挥 Spark 的性能,需要开发者进一步了解存储内存和执行内存各自的管理方式和实现原理。
统一内存管理还可以简化如图

89、mysql btree 和 hash tree 的区别。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-qlzPZ5MK-1590579243642)(https://www.heibai.org/zb_users/upload/2018/07/201807181531901541472699.png)]
hash 索引结构的特殊性,其检索效率非常高,索引的检索可以一次定位,不像B-Tree 索引需要从根节点到枝节点,最后才能访问到页节点这样多次的IO访问,所以 Hash 索引的查询效率要远高于 B-Tree 索引。
btree 需要唯一主键,
hash tree 适合>= 等,精确匹配,不适合范围检索,因为经过相应的 Hash 算法处理之后的 Hash 值的大小关系,并不能保证和Hash运算前完全一样。
Hash 索引无法被用来避免数据的排序操作。
Hash 索引不能利用部分索引键查询。
Hash 索引在任何时候都不能避免表扫描。
Hash 索引遇到大量Hash值相等的情况后性能并不一定就会比B-Tree索引高。
https://blog.csdn.net/zhaoliang831214/article/details/89393466
90、udf、udtf和 udaf 的区别
UDF:用户定义(普通)函数,只对单行数值产生作用;
extends UDF
方法名 evaluate
UDAF:User- Defined Aggregation Funcation;用户定义聚合函数,可对多行数据产生作用;等同与SQL中常用的SUM(),AVG(),也是聚合函数;
示例函数:sum,count,max,min…
实现方法:extends UDAF,内部静态类实现接口UDAFEvaluator
五大方法:
init:初始化map或是reduce需用到的变量
iterate:迭代处理每条数据。true
terminatePartial:相当于mr的combiner
merge:其输入一定是terminatePartial的输出
terminate:处理的是merge的结果
具体介绍:
init():类似于构造函数,用于UDAF的初始化
iterate():接收传入的参数,并进行内部的轮转。其返回类型为boolean
terminatePartial():无参数,其为iterate函数轮转结束后,返回乱转数据,iterate和 terminatePartial类似于hadoop的Combiner(iterate–mapper;terminatePartial–reducer)
merge():接收terminatePartial的返回结果,进行数据merge操作,其返回类型为boolean
terminate():返回最终的聚集函数结果
UDTF:User-Defined Table-Generating Functions,用户定义表生成函数,用来解决输入一行输出多行;
示例函数:explode
实现方法:udf+explode
91、hive sql 的执行过程
hiveSQL转换成MapReduce的执行计划包括如下几个步骤:
HiveSQL ->AST(抽象语法树) -> QB(查询块) ->OperatorTree(操作树)->优化后的操作树->mapreduce任务树->优化后的mapreduce任务树

SQL Parser:Antlr定义SQL的语法规则,完成SQL词法,语法解析,将SQL转化为抽象 语法树AST Tree;
Semantic Analyzer:遍历AST Tree,抽象出查询的基本组成单元QueryBlock;
Logical plan:遍历QueryBlock,翻译为执行操作树OperatorTree;
Logical plan optimizer: 逻辑层优化器进行OperatorTree变换,合并不必要的ReduceSinkOperator,减少shuffle数据量;
Physical plan:遍历OperatorTree,翻译为MapReduce任务;
Logical plan optimizer:物理层优化器进行MapReduce任务的变换,生成最终的执行计划;
92、client 端,spark sql 的执行过程
SparkSQL大致的执行流程是这样的:
- SQL 语句经过SqlParser 完成sql 语句的语法解析功能,解析成Unresolved LogicalPlan(未解析的逻辑计划);
- 使用分析器Analyser将不同来源的Unresolved LogicalPlan和元数据(如hive metastore、Schema catalog)进行绑定,生成Resolved LogicalPlan(解析后的逻辑计划);
- 使用优化器Optimizer 对Resolved LogicalPlan 进行优化,生成Optimized LogicalPlan(优化后的逻辑计划);
- 使用SparkPlan 将LogicalPlan(逻辑计划) 转换成PhysicalPlan(物理计划);
- 使用prepareForExecution() 将PhysicalPlan转换成可执行物理计划;
- 使用execute() 执行可执行物理计划,生成SchemaRDD 即Dataset或DataFrame。
93、找出数组中最长的 top10 字符串:
https://www.nowcoder.com/questionTerminal/2c81f88ecd5a4cc395b5308a99afbbec
int i=0;
for (int j=0;j<xxx.length();j++) {
if (xxx[j].length>i) {
i=xxx[j];
}
}
return i;
94、@@@@@@Flink 数据处理流程
95、@@@@@@Flink 与 Spark streaming 对比
96、@@@@@@Flink watermark 使用
97、@@@@@@窗口与流的结合
98、@@@@@@Flink 实时告警设计
99、Java:面向对象、容器、多线程、单例
100、@@@@@@Flink:部署、API、状态、checkpoint、savepoint、watermark、重启策略、datastream 算子和优化、job和task状态
101、Spark:原理、部署、优化
103、hive的外部表问题
CREATE [EXTERNAL] TABLE [IF NOT EXISTS] table_name
[(col_name data_type [COMMENT col_comment], ...)]
[COMMENT table_comment]
[PARTITIONED BY (col_name data_type [COMMENT col_comment], ...)]
[CLUSTERED BY (col_name, col_name, ...)
[SORTED BY (col_name [ASC|DESC], ...)] INTO num_buckets BUCKETS]
[ROW FORMAT row_format]
[STORED AS file_format]
[LOCATION hdfs_path]
create external table transaction1(id int,sex string,age int,date string,role string,region string) row format delimited fields terminated by ' ' stored as textfile location '/user/hdfs/source/hive_test';
create external table t(rowkey string, uid int)
row format delimited
fields terminated by ‘\t’
stored as textfile
location ‘/user/hdfs/source/hive_test’;
外部表的表数据由HDFS管理,Hive管理外部表元数据,尔内部表的表数据和元数据都由Hive管理
外部表的表数据存储位置由用户指定,而内部表的数据默认存储位置为/apps/hive/warehouse/数据库名.db/数据文件名
删除外部表时,只会删除表的元数据,表数据仍然存储在HDFS中,删除内部表时,元数据和表数据都会删除
对内部表修改时会同步到元数据,而对外部表结构和分区修改时,需要进行修复
msck rapair table table_name
使用场合
- 希望做数据备份并且不经常改变的数据,存放在外部表可以减少失误操作
- 数据清洗转换后的中间结果,可以存放在内部表,因为Hive对内部表支持的功能比较全面,方便管理
- 处理完成的数据由于需要共享,可以存储在外部表,这样能够防止失误操作,增加数据的安全性
104、spark的函数式编程
https://www.cnblogs.com/Gxiaobai/p/10460336.html
105、线性数据结构和数据结构
https://www.cnblogs.com/mr-wuxiansheng/p/8688946.html
106、映射,rdd。
sc.textFile();
sc.parallesize(Array());
111、Checkpoint失败了的监控
checkpoint的最大的弊端在于,一旦你的流式程序代码或配置改变了,或者更新迭代新功能了,这个时候,你先停旧的sparkstreaming程序,然后新的程序打包编译后执行运行,会出现两种情况:
- (1)启动报错,反序列化异常
- (2)启动正常,但是运行的代码仍然是上一次的程序的代码。
为什么会出现上面的两种情况?
这是因为checkpoint第一次持久化的时候会把整个相关的jar给序列化成一个二进制文件,每次重启都会从里面恢复,但是当你新的程序打包之后序列化加载的仍然是旧的序列化文件,这就会导致报错或者依旧执行旧代码。但是一旦你删除了旧的checkpoint,新启动的程序,只能从kafka的smallest或者largest的偏移量消费,默认是从最新的,如果是最新的,而不是上一次程序停止的那个偏移量
就会导致有数据丢失,如果是老的,那么就会导致数据重复。
停机的时候,记录下最后一次的偏移量,然后新恢复的程序读取这个偏移量继续工作,从而达到不丢消息。
122、Hdfs读写流程(结合cap理论讲)
写流程如下:
1、客户端访问NameNode,NameNode检查路径和权限,如果路径中有与要上传的文件重名的文件就不能上传了,不能覆盖,如果没有才创建,创建名为file.copying的临时文件;
2、NameNode触发副本放置策略,如果客户端在集群内的某一台机器,那么副本第一块放置在该服务器上,然后再另外挑两台服务器;如果在集群外,namenode会根据策略先找一个机架选出一个datanode,然后再从另外的机架选出另外两个datanode,然后namenode会将选出的三个datanode按距离组建一个顺序,然后将顺序返回给客户端;
3、客户端会根据返回的三个节点和第一个节点建立一个socket连接(只会和第一个节点建立),第一个节点又会和第二个节点建立socket连接,由第二个节点又会和第三个节点建立一个socket连接,这种连接的方式叫Pipeline;
4、客户端会将block切分成package(默认是64kB),以流式在pipeline中传输
好处:
(1)速度快:时间线重叠(其实流式也是一种变异的并行);
(2)客户端简单:副本的概念是透明的;
5、由DataNode完成接收block块后,block的metadata(MD5校验用)通过一个心跳将信息汇报给NameNode;
6、如果再pipeline传输中,任意节点失败,上游节点直接连接失败节点的下游节点继续传输,最终在第5步汇报后,NameNode会发现副本数不足,一定会出发DataNode复制更多副本,客户端Client副本透明;
7、client一直重复以上操作,逐一将block块上传,同时DataNode汇报block的位置信息,时间线重叠;
8、最终,如果NameNode收到了DataNode汇报的所有块的信息,将文件的.copying去掉,文件可用。
读流程如下:
我们先说一个语义:下载回这个文件。换句话说就是取回这个文件的所有的块,那么当有能力取回文件的所有块的时候,那么它的子集操作就是取回其中某些块或者某个块也能实现。所以我们先来看取回文件的所有块的流程是怎么实现的:
1、客户端和NameNode建立连接,获取文件block的位置信息(fileBlockLocations)
2、客户端根据自己想要获取的数据位置挑选需要连接的DataNode(如果全文下载,从0开始;如果是从某一位置开始,客户端需要给出)
需要用inputstream.seek(long)//从什么位置开始读取,和哪个DataNode开始连接获取block;
3、距离的概念:只有文件系统在读流程中附加距离优先的概念,计算层才能够被动实现计算向数据移动,距离有以下三种:
(1)本地,最近的距离;
(2)同机架,次之的距离;
(3)other(数据中心),最远的距离;
4、客户端下载完成block后会验证DataNode中的MD5,保证块数据的完整性。
123、技术选型原则
社区活跃度高的,从实际业务场景出发选择最合适的
124、Kafka组件介绍

- Topic :消息根据Topic进行归类
特指 Kafka 处理的消息源(feeds of messages)的不同分类。
Topic:一类消息,每个topic将被分成多个partition(区),在集群的配置文件中配置。
partition:在存储层面是逻辑append log文件,包含多个segment文件。
Segement:消息存储的真实文件,会不断生成新的。
offset:每条消息在文件中的位置(偏移量)。offset为一个long型数字,它是唯一标记一条消息。
- Producer:发送消息者
- Consumer:消息接受者
- broker:每个kafka实例(server)
- Zookeeper:依赖集群保存meta信息。
https://blog.csdn.net/qq_41455420/article/details/79372051
125、g1和csm区别
cms:

g1:

- CMS :并发标记清除。他的主要步骤有:初始收集,并发标记,重新标记,并发清除(删除)、重置。
- G1:主要步骤:初始标记,并发标记,重新标记,复制清除(整理)
- CMS 的缺点是对 CPU 的要求比较高。G1是将内存化成了多块,所有对内段的大小有很大的要求。
- CMS是清除,所以会存在很多的内存碎片。G1是整理,所以碎片空间较小。
- G1 和 CMS 都是响应优先把,他们的目的都是尽量控制 STW 时间。
https://crowhawk.github.io/2017/08/15/jvm_3/
127、spark oom处理方法
内存溢出就是Driver和executor内存不够。
Driver读取大量数据加内存
Map过程产生大量对象内存溢出:
rdd.map(x => for(i <- 1 to 10000000) yiled i.toString),每个rdd产生大量对象会造成内存溢出问题,通过减少Task大小,也就是先调用repartion方法增加分区再map。
mappartion和foreachpartion:
这两个方法,虽然对比map方法,每个task只执行function1次,会一次把整个partion的数据拿进内存,性能比较高。写入数据库的时候会减少创建数据库连接的次数。但是如果一个partion内数据太多,会直接oom。可以进行repartion操作。
数据不平衡导致内存溢出
repartion操作。
coalesce算子
coalesce合并多个小文件,开始有100个文件,coalesce(10)后产生10个文件,但是coalesce不产生shuffle,之后的所有操作都是变成10个task,每个task一次读取10个文件执行,用的是原先的10倍内存,会oom。解决办法就是开始执行100个task,然后处理后的结果经过用repation(10)的shuffle过程变成10个分区。
shuffle内存溢出
Executor 端的任务并发度,多个同时运行的 Task 会共享 Executor 端的内存,使得单个 Task 可使用的内存减少。
数据倾斜,有可能造成单个 Block 的数据非常的大
给每个shuffle类型的方法,都会接收一个参数,值就是partition值,设置一个比较好值。
RDD中重复数据可以转换成字符串,公用一个对象。
rdd = sc.parallelize(range(100))
def myfunc(x): return x
rdd.flatMap(lambda x: [('k', 'v') for _ in range(200000000)]).foreach(myfunc) # 每次生成一个 tuple 对象,内存溢出
rdd.flatMap(lambda x: ['k'+'v' for _ in range(2000000)]).count() # 无需生成新的 string 对象,可执行
tuple 为不可变对象,字符串是可变对象。
standalone模式下资源分配不均匀
配置了–total-executor-cores 和 –executor-memory 这两个参数,但是没有配置–executor-cores这个参数的话,就有可能导致,每个Executor的memory是一样的,但是cores的数量不同,那么在cores数量多的Executor中,由于能够同时执行多个Task,就容易导致内存溢出的情况。这种情况的解决方法就是同时配置–executor-cores或者spark.executor.cores参数,确保Executor资源分配均匀。
128、@@@@@@看了哪些源码
130、@@@@@@解决过的问题
131、@@@@@@Hbase读写流程
132、Spark数据倾斜的处理方案
-
数据倾斜解决方案之原理以及现象分析.xls
-
数据倾斜解决方案之聚合源数据.xls (使用hive先进行聚合或者map 端先局部聚合,过滤异常数据)
在 map 端加个 combiner 函数进行局部聚合。加上 combiner 相当于提前进行 reduce ,就会把一个 mapper 中的相同 key 进行聚合,减少 shuffle 过程中数据量 以及 reduce 端的计算量。这种方法可以有效的缓解数据倾斜问题,但是如果导致数据倾斜的 key 大量分布在不同的 mapper 的时候,这种方法就不是很有效了。
TIPS 使用 reduceByKey 而不是 groupByKey。
-
数据倾斜解决方案之提高shuffle操作reduce并行度.xls (提高 shuffle 并行度)
RDD 操作 可在需要 Shuffle 的操作算子上直接设置并行度或者使用 spark.default.parallelism 设置。如果是 Spark SQL,还可通过 SET spark.sql.shuffle.partitions=[num_tasks] 设置并行度。默认参数由不同的 Cluster Manager 控制。
dataFrame 和 sparkSql 可以设置 spark.sql.shuffle.partitions=[num_tasks] 参数控制 shuffle 的并发度,默认为200。
(2)适用场景
大量不同的 Key 被分配到了相同的 Task 造成该 Task 数据量过大。
(3)解决方案
调整并行度。一般是增大并行度,但有时如减小并行度也可达到效果。
(4)优势
实现简单,只需要参数调优。可用最小的代价解决问题。一般如果出现数据倾斜,都可以通过这种方法先试验几次,如果问题未解决,再尝试其它方法。
(5)劣势
适用场景少,只是让每个 task 执行更少的不同的key。无法解决个别key特别大的情况造成的倾斜,如果某些 key 的大小非常大,即使一个 task 单独执行它,也会受到数据倾斜的困扰。并且该方法一般只能缓解数据倾斜,没有彻底消除问题。从实践经验来看,其效果一般。
TIPS 可以把数据倾斜类比为 hash 冲突。提高并行度就类似于 提高 hash 表的大小。
- 数据倾斜解决方案之使用随机key实现双重聚合.xls (加盐局部聚合 + 去盐全局聚合)
这个方案的核心实现思路就是进行两阶段聚合。第一次是局部聚合,先给每个 key 都打上一个 1~n 的随机数,比如 3 以内的随机数,此时原先一样的 key 就变成不一样的了,比如 (hello, 1) (hello, 1) (hello, 1) (hello, 1) (hello, 1),就会变成 (1_hello, 1) (3_hello, 1) (2_hello, 1) (1_hello, 1) (2_hello, 1)。接着对打上随机数后的数据,执行 reduceByKey 等聚合操作,进行局部聚合,那么局部聚合结果,就会变成了 (1_hello, 2) (2_hello, 2) (3_hello, 1)。然后将各个 key 的前缀给去掉,就会变成 (hello, 2) (hello, 2) (hello, 1),再次进行全局聚合操作,就可以得到最终结果了,比如 (hello, 5)。
def antiSkew(): RDD[(String, Int)] = {
val SPLIT = "-"
val prefix = new Random().nextInt(10)
pairs.map(t => ( prefix + SPLIT + t._1, 1))
.reduceByKey((v1, v2) => v1 + v2)
.map(t => (t._1.split(SPLIT)(1), t2._2))
.reduceByKey((v1, v2) => v1 + v2)
}
不过进行两次 mapreduce,性能稍微比一次的差些。
- [数据倾斜解决方案之将reduce join转换为map join.xls](D:\Java\大数据\知识星球\SparkStormHadoop\spark\spark调优\数据倾斜解决方案之将reduce join转换为map join.xls)
(1)适用场景
参与Join的一边数据集足够小,可被加载进 Driver 并通过 Broadcast 方法广播到各个 Executor 中。
(2)解决方案
在 Java/Scala 代码中将小数据集数据拉取到 Driver,然后通过 Broadcast 方案将小数据集的数据广播到各 Executor。或者在使用 SQL 前,将 Broadcast 的阈值调整得足够大,从而使 Broadcast 生效。进而将 Reduce Join 替换为 Map Join。
(3)优势
避免了 Shuffle,彻底消除了数据倾斜产生的条件,可极大提升性能。
(4)劣势
因为是先将小数据通过 Broadcase 发送到每个 executor 上,所以需要参与 Join 的一方数据集足够小,并且主要适用于 Join 的场景,不适合聚合的场景,适用条件有限。
NOTES:使用Spark SQL时需要通过 SET spark.sql.autoBroadcastJoinThreshold=104857600 将 Broadcast 的阈值设置得足够大,才会生效。
- 数据倾斜解决方案之sample采样倾斜key进行两次join.xls (拆分 join 再 union)
将一个 join 拆分成 倾斜数据集 Join 和 非倾斜数据集 Join,最后进行 union:
- 对包含少数几个数据量过大的 key 的那个 RDD (假设是 leftRDD),通过 sample 算子采样出一份样本来,然后统计一下每个 key 的数量,计算出来数据量最大的是哪几个 key。具体方法上面已经介绍过了,这里不赘述。
- 然后将这 k 个 key 对应的数据从 leftRDD 中单独过滤出来,并给每个 key 都打上 1~n 以内的随机数作为前缀,形成一个单独的 leftSkewRDD;而不会导致倾斜的大部分 key 形成另外一个 leftUnSkewRDD。
- 接着将需要 join 的另一个 rightRDD,也过滤出来那几个倾斜 key 并通过 flatMap 操作将该数据集中每条数据均转换为 n 条数据(这 n 条数据都按顺序附加一个 0~n 的前缀),形成单独的 rightSkewRDD;不会导致倾斜的大部分 key 也形成另外一个 rightUnSkewRDD。
- 现在将 leftSkewRDD 与 膨胀 n 倍的 rightSkewRDD 进行 join,且在 Join 过程中将随机前缀去掉,得到倾斜数据集的 Join 结果 skewedJoinRDD。注意到此时我们已经成功将原先相同的 key 打散成 n 份,分散到多个 task 中去进行 join 了。
- 对 leftUnSkewRDD 与 rightUnRDD 进行Join,得到 Join 结果 unskewedJoinRDD。
- 通过 union 算子将 skewedJoinRDD 与 unskewedJoinRDD 进行合并,从而得到完整的 Join 结果集。
(1)适用场景
两张表都比较大,无法使用 Map 端 Join。其中一个 RDD 有少数几个 Key 的数据量过大,另外一个 RDD 的 Key 分布较为均匀。
(2)解决方案
将有数据倾斜的 RDD 中倾斜 Key 对应的数据集单独抽取出来加上随机前缀,另外一个 RDD 每条数据分别与随机前缀结合形成新的RDD(相当于将其数据增到到原来的N倍,N即为随机前缀的总个数),然后将二者Join并去掉前缀。然后将不包含倾斜Key的剩余数据进行Join。最后将两次Join的结果集通过union合并,即可得到全部Join结果。
(3)优势
相对于 Map 则 Join,更能适应大数据集的 Join。如果资源充足,倾斜部分数据集与非倾斜部分数据集可并行进行,效率提升明显。且只针对倾斜部分的数据做数据扩展,增加的资源消耗有限。
(4)劣势
如果倾斜 Key 非常多,则另一侧数据膨胀非常大,此方案不适用。而且此时对倾斜 Key 与非倾斜 Key 分开处理,需要扫描数据集两遍,增加了开销。
- 数据倾斜解决方案之使用随机数以及扩容表进行join.xls (大表 key 加盐,小表扩大 N 倍 jion)
如果出现数据倾斜的 Key 比较多,上一种方法将这些大量的倾斜 Key 分拆出来,意义不大。此时更适合直接对存在数据倾斜的数据集全部加上随机前缀,然后对另外一个不存在严重数据倾斜的数据集整体与随机前缀集作笛卡尔乘积(即将数据量扩大N倍)。
其实就是上一个方法的特例或者简化。少了拆分,也就没有 union。
(1)适用场景
一个数据集存在的倾斜 Key 比较多,另外一个数据集数据分布比较均匀。
(2)优势
对大部分场景都适用,效果不错。
(3)劣势
需要将一个数据集整体扩大 N 倍,会增加资源消耗。
8.自定义 Partitioner
(1)原理
使用自定义的 Partitioner(默认为 HashPartitioner),将原本被分配到同一个 Task 的不同 Key 分配到不同 Task。
例如,我们在 groupByKey 算子上,使用自定义的 Partitioner:
.groupByKey(new Partitioner() {
@Override
public int numPartitions() {
return 12;
}
@Override
public int getPartition(Object key) {
int id = Integer.parseInt(key.toString());
if(id >= 9500000 && id <= 9500084 && ((id - 9500000) % 12) == 0) {
return (id - 9500000) / 12;
} else {
return id % 12;
}
}
})
TIPS 这个做法相当于自定义 hash 表的 哈希函数。
(2)适用场景
大量不同的 Key 被分配到了相同的 Task 造成该 Task 数据量过大。
(3)解决方案
使用自定义的 Partitioner 实现类代替默认的 HashPartitioner,尽量将所有不同的 Key 均匀分配到不同的 Task 中。
(4)优势
不影响原有的并行度设计。如果改变并行度,后续 Stage 的并行度也会默认改变,可能会影响后续 Stage。
(5)劣势
适用场景有限,只能将不同 Key 分散开,对于同一 Key 对应数据集非常大的场景不适用。效果与调整并行度类似,只能缓解数据倾斜而不能完全消除数据倾斜。而且需要根据数据特点自定义专用的 Partitioner,不够灵活。
https://blog.csdn.net/qq_38247150/article/details/80366769
https://mp.weixin.qq.com/s/piW10KGJVgaSB_i72OVntA
133、SQL优化



