python实现storm读取kafka数据
环境准备
1、kafka、zk
2、安装storm
修改conf/storm.yaml,有笔记。 这个配置文件,空格 对齐 很重要
启动storm
bin/storm nimbus【仅一台】 storm nimbus >/dev/null 2>&1 &
bin/storm supervisor storm supervisor >/dev/null 2>&1 &
bin/storm ui【仅一台】 bin/storm ui >/dev/null 2>&1 &浏览器打开: http://localhost:8080 查看集群的运行状态
3、安装pip
下载–解压–cd pip-7.1.2 python setup.py install
可能会报错:ImportError: No module named setuptools
解决方案:
下载setuptools-19.1.1.tar.gz
解压
cd setuptools-19.1.1
python setup.py build
python setup.py install4、安装pyleus
注意版本:Pyleus 0.3.0 is not compatible with Storm 0.9.2 or older. Use Pyleus 0.2.4 for older versions of Storm.
pyleus local exclamation_topology.jar
后台运行
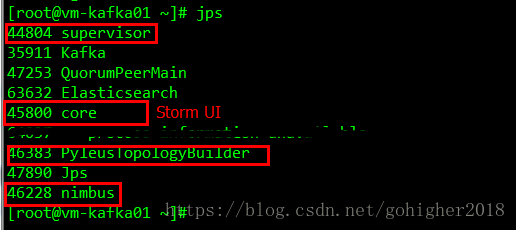
例子
下面来尝试数单词,这个例子word_count
https://yelp.github.io/pyleus/tutorial.html my_first_topology
kafka
bin/kafka-console-consumer.sh –topic Apache-AccessLog –zookeeper vm-cdhtest01:2181
test1:storm 用随机生产数据,不处理,直接写日志
[root@vm-kafka01 word_count.simple]# more pyleus_topology.yaml
# An ultra-simple topology which shows off Storm and the pyleus.storm library
name: word_count
topology:
- spout:
name: line-spout
module: word_count.line_spout
- bolt:
name: log-results
module: word_count.log_results
groupings:
- shuffle_grouping: line-spout[root@vm-kafka01 word_count.simple]#
[root@vm-kafka01 word_count.simple]# ls
pyleus_topology.yaml word_count
[root@vm-kafka01 word_count.simple]# cd word_count/
[root@vm-kafka01 word_count]# ls
__init__.py line_spout.py log_results.py
[root@vm-kafka01 word_count]# more line_spout.py
import logging
import random
from pyleus.storm import Spout
log = logging.getLogger('counter')
LINES = """
122.119.123.31 20151227_16:57:15 accesslog.201512271600 1373 10.6.141.21 - - [27
/Dec/2015:16:57:14 +0800] "STATUS / HTTP/1.1" 200 59 vm:
6666 "-" "-" "ClusterListener/1.0" 153 384 - 122.119.123.31:6666 1513
122.119.123.31 20151227_16:57:20 accesslog.201512271600 1374 10.6.141.22 - - [27
/Dec/2015:16:57:19 +0800] "STATUS / HTTP/1.1" 200 65 vm:
6666 "-" "-" "ClusterListener/1.0" 158 390 - 122.119.123.31:6666 1742
122.119.123.31 20151227_16:57:20 accesslog.201512271600 1375 10.6.141.22 - - [27
/Dec/2015:16:57:19 +0800] "STATUS / HTTP/1.1" 200 65 vm:
6666 "-" "-" "ClusterListener/1.0" 158 390 - 122.119.123.31:6666 2084
122.119.123.31 20151227_16:57:21 accesslog.201512271600 1376 10.6.141.22 - - [27
/Dec/2015:16:57:21 +0800] "STATUS / HTTP/1.1" 200 59 vm:
6666 "-" "-" "ClusterListener/1.0" 153 384 - 122.119.123.31:6666 1731
""".strip().split('\n')
class LineSpout(Spout):
OUTPUT_FIELDS = ["line"]
def next_tuple(self):
line = random.choice(LINES)
log.debug(line)
self.emit((line,), tup_id=random.randrange(999999999))
if __name__ == '__main__':
logging.basicConfig(
level=logging.DEBUG,
filename='/tmp/word_count_lines.log',
format="%(message)s",
filemode='a',
)
LineSpout().run()[root@vm-kafka01 word_count]# more log_results.py
import logging
from pyleus.storm import SimpleBolt
log = logging.getLogger('log_results')
class LogResultsBolt(SimpleBolt):
def process_tuple(self, tup):
line, = tup.values
log.debug(line)
if __name__ == '__main__':
logging.basicConfig(
level=logging.DEBUG,
filename='/tmp/word_count_results.log',
format="%(message)s",
filemode='a',
)
LogResultsBolt().run()[root@vm-kafka01 word_count]#
test2
在test1上进行修改,spout来自kafka,也是不处理,直接写日志
[root@vm-kafka01 word_count]# more pyleus_topology.yaml
# An ultra-simple topology which shows off Storm and the pyleus.storm library
name: word_count
topology:
- spout:
name: kafka-A-Log topic的名字
type: kafka
options:
topic: A-Log
zk_hosts: vm01:2181,vm03:2181,vm05:2181 kafka用到的zk信息
zk_root: /tmp/pyleus-kafka-offsets/word_count
consumer_id: pyleus-word_count
from_start: false
- bolt:
name: log-results
module: word_count.log_results
groupings:
- shuffle_grouping: kafka-A-Log[root@vm-kafka01 word_count]# ls
pyleus_topology.yaml word_count
[root@vm-kafka01 word_count]# cd word_count/
[root@vm-kafka01 word_count]# ls
__init__.py log_results.py
[root@vm-kafka01 word_count]# more log_results.py
import logging
from pyleus.storm import SimpleBolt
log = logging.getLogger('log_results')
class LogResultsBolt(SimpleBolt):
def process_tuple(self, tup):
line, = tup.values
log.debug(line) 这个debug和下面的logging.basicConfig只是日志的格式而已,不用管,保持这样就可以。line是实际的内容。
if __name__ == '__main__':
logging.basicConfig(
level=logging.DEBUG,
filename='/tmp/word_count_results.log',
format="%(message)s",
filemode='a',
)
LogResultsBolt().run()[root@vm-kafka01 word_count]#