【JUC源码】图解LongAdder
简介
本文介绍了LongAdder的的整体流程。
LongAdder和AtomicLong的区别
通俗地讲,AtomicLong对象用 一个 long类型的内部变量存储值,多个线程得交替执行累加操作。
LongAdder用 多个 long类型的内部变量存储值,多个线程可以一起执行累加操作(当然要多个cpu啦)。
下图中一个箭头就代表一个线程。左边代表LongAdder,右边代表AtomicLong。可以看出LongAdder可以同时处理多个线程的加操作,效率自然也就更高了。
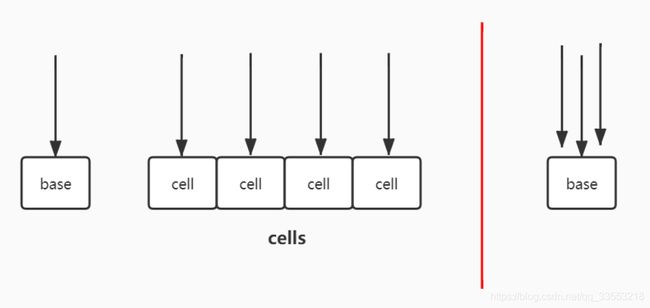
怎么实现的呢?现在除了一个base,还有好多个cell,每个cell里面存的都是一个long类型的值。那很多线程一起来的时候,就让不同的线程把要加的值加到不同的cell里面去就好了,这样就能减少冲突了。最后想要获取结果的时候,就把所有的cell和base加起来。
源码理解
AtomicLong继承了Striped64,成员变量都在Striped64里面,我们先来认识一下它们。
// cpu数,cells的数量不能超过cpu数。
static final int NCPU = Runtime.getRuntime().availableProcessors();
// Cell列表,大小总是2的幂
transient volatile Cell[] cells;
// 和cells一起存储累加结果,如果没有线程间的竞争,就都存在base里
transient volatile long base;
// 锁,cells扩容,创建的时候都需要用到
transient volatile int cellsBusy;
接下来看看Cell
// 这个注释最后说
@sun.misc.Contended static final class Cell {
// 存储结果
volatile long value;
Cell(long x) {
value = x; }
// 用cas修改value
final boolean cas(long cmp, long val) {
return UNSAFE.compareAndSwapLong(this, valueOffset, cmp, val);
}
private static final long valueOffset;
//...
}
可以看到Cell里面真正有用的变量其实就一个value。
接下去就可以来看看整体流程了。
整体流程
add
当调用LongAdder的add方法时,就会执行下图的流程。
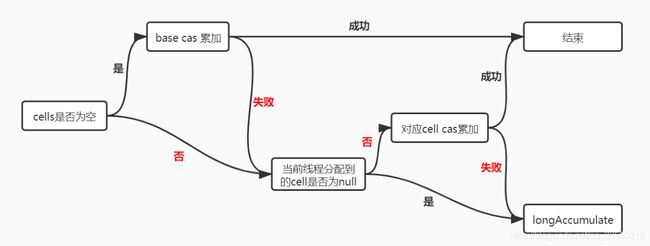
除了为线程分配cell有点问题,其他部分应该是很清晰的,对照图看一眼代码。
// LongAdder
public void add(long x) {
Cell[] as; long b, v; int m; Cell a;
if ((as = cells) != null || !casBase(b = base, b + x)) {
boolean uncontended = true;
if (as == null || (m = as.length - 1) < 0 ||
(a = as[getProbe() & m]) == null ||
!(uncontended = a.cas(v = a.value, v + x)))
longAccumulate(x, null, uncontended);
}
}
在说longAccumulate之前,先看看怎么为线程分为cell。
as = cells
m = as.length - 1
a = as[getProbe() & m]
之前介绍LongAdder的成员变量时说了cells数组的长度永远是2的倍数,那么m就是2的倍数-1,写成二进制就是一串00000…00111…11,这一串东西跟其他数字进行&操作,实际就是取余。其实就是跟HashMap里面一样的。
getProbe()获取线程探针,可以理解为是线程的hash值,在LongAdder里的作用就是将线程和cell对应起来,防止所有线程都指向同样的cell,这个东西在ConcurrentHashMap里面也有用到。所以个人理解,这个探针的作用就是在并发数据结构中,尽量让不同的线程指向数据结构中不同的最小加锁单位。
// #Striped64
static final int getProbe() {
return UNSAFE.getInt(Thread.currentThread(), PROBE);
}
// #Thread
// 和threadLocalRandomSeed一起初始化
@sun.misc.Contended("tlr")
int threadLocalRandomProbe;
接下去分析longAccumulate。
longAccumulate
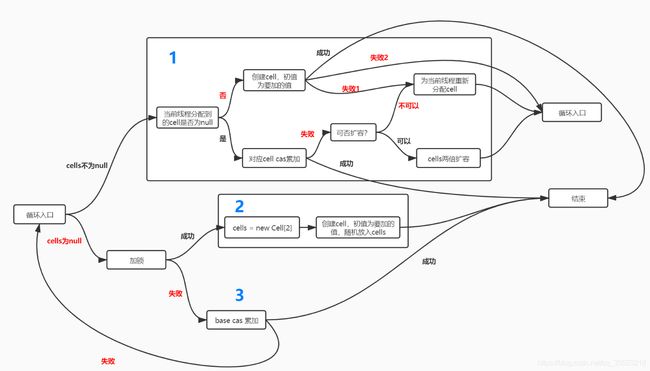
注:上图的失败1和失败2在代码注释中进行标注,两个循环入口是一样的,因为作图原因分成两个。
可以看到上图中主要分成了3部分,这也是代码的整体结构,接下去对着图看看代码。1,2,3分别对应代码注释中的第一部分,第二部分,第三部分。
// # Striped64
final void longAccumulate(long x, LongBinaryOperator fn,
boolean wasUncontended) {
int h;
// 初始化探针哈希值
if ((h = getProbe()) == 0) {
ThreadLocalRandom.current();
h = getProbe();
wasUncontended = true;
}
boolean collide = false; // True if last slot nonempty
for (;;) {
Cell[] as; Cell a; int n; long v;
// *** 第1部分 ***
// cells不为null
if ((as = cells) != null && (n = as.length) > 0) {
// 当前线程对应的cell为null
if ((a = as[(n - 1) & h]) == null) {
// 检查是否处于加锁状态,也就是看是否有其它线程在改变cells
if (cellsBusy == 0) {
// 创建一个cell,初值赋为要加的x
Cell r = new Cell(x);
// 尝试加锁
// 如果加锁不成功就是失败1.
if (cellsBusy == 0 && casCellsBusy()) {
// 加锁成功
boolean created = false;
try {
Cell[] rs; int m, j;
// 再一次检查在加锁之前这个cell有没有被其他线程初始化
if ((rs = cells) != null &&
(m = rs.length) > 0 &&
rs[j = (m - 1) & h] == null) {
// 把创建好的cell赋给cells数组对应位置
rs[j] = r;
created = true;
}
} finally {
// 释放锁
cellsBusy = 0;
}
// 如果创建成功,直接退出循环。
if (created)
break;
// 失败2:因为其他线程抢先占用了本线程对应的cell
continue;
}
}
// 加锁失败说明存在竞争
collide = false;
}
else if (!wasUncontended) // CAS already known to fail
wasUncontended = true; // Continue after rehash
// 尝试对线程对应的cell进行cas,成功就break。失败就继续往下。
else if (a.cas(v = a.value, ((fn == null) ? v + x :
fn.applyAsLong(v, x))))
break;
// cells长度不能超过CPU核数
else if (n >= NCPU || cells != as)
collide = false; // At max size or stale
else if (!collide)
collide = true;
// 扩容操作
else if (cellsBusy == 0 && casCellsBusy()) {
try {
// 在执行上面那些if判断的时候,没有其它线程抢先扩容
if (cells == as) {
// Expand table unless stale
// 扩容为当前长度*2
Cell[] rs = new Cell[n << 1];
for (int i = 0; i < n; ++i)
rs[i] = as[i];
cells = rs;
}
} finally {
cellsBusy = 0;
}
collide = false;
continue; // Retry with expanded table
}
// rehash线程探针
h = advanceProbe(h);
}
// *** 第二部分 ***
// 初始化cells
else if (cellsBusy == 0 && cells == as && casCellsBusy()) {
boolean init = false;
try {
// Initialize table
if (cells == as) {
// 初始长度为2
Cell[] rs = new Cell[2];
// 把新的cell放到0或者1位置
rs[h & 1] = new Cell(x);
cells = rs;
init = true;
}
} finally {
cellsBusy = 0;
}
// 直接结束循环
if (init)
break;
}
// *** 第三部分***
// 再对base进行cas试试看。
else if (casBase(v = base, ((fn == null) ? v + x :
fn.applyAsLong(v, x))))
break; // Fall back on using base
}
}
都详细注释啦,就不多说了。
最后简单看一下怎么获取值。
sum
public long sum() {
Cell[] as = cells; Cell a;
long sum = base;
if (as != null) {
for (int i = 0; i < as.length; ++i) {
if ((a = as[i]) != null)
sum += a.value;
}
}
return sum;
}
很简单,就是全部加起来,没有任何加锁操作。所以很显然,这是弱一致性的。
@sun.misc.Contended
最后结合作者的注释解释一下为什么要在Cell上加@sun.misc.Contended。涉及到缓存行的知识可以先搜一下。
@sun.misc.Contended是用来填充Cell的,防止两个Cell在同一个缓存行内,减少缓存竞争。
作者认为对大多数Atomics类来说,是没必要填充的,因为它们是不规则地分布在内存中的。但是在LongAdder中,用到了数组,一个数组中的元素是相邻的,所以多个Cell会共享同一个缓存行,就会极大地影响性能。