Processor Microarchitecture(Mark D.Hill ):Cache
-
- 一、Introduction(背景)
- 二、cache structure organization(缓存结构)
- 三、non-blocking cache(非阻塞缓存)
- 四、multiported cache(多端口缓存)
- 五、I-cache(指令缓存)
一、Introduction(背景)
1、什么是Cache

时间局部性: cache中储存了最近访问过的程序指令和数据
空间局部性: cache中储存了当前指令周围的内容
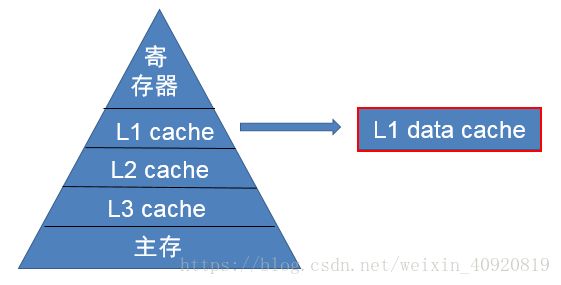
随着CPU和主存之间性能差距不断增大,人们有在一级cache和主存之间插入了二级cache,三级cache。本文作者重点讨论了一级数据缓存。
L1Cache的访问速度几乎和寄存器一样快,通常花费1~4个时钟周期;通常是更低的相联度;大小一般为十几KB。
L2和L3Cache,相联度会更高一些,大小一般为几百KB到几MB,花费几十个时钟周期。
2、Cache如何寻址
物理地址空间:处理器可在其总线上生成的地址范围;
虚拟地址空间:应用程序可使用的地址范围。
内存使用使用物理地址的问题:
(1)进程地址空间不隔离。由于程序都是直接访问物理内存,所以恶意程序可以随意修改别的进程的内存数据,以达到破坏的目的。有些非恶意的,但是有 bug 的程序也可能不小心修改了其它程序的内存 数据,就会导致其它程序的运行出现异常;
(2)效率低。在 A 和 B 都运行的情况下,如果用户又运行了程序 C ,而程序 C 需要 20M 大小的内存才能运行,而此时系统只剩下 8M 的空间可供使用,所以此时系统必须在已运行的程序中选择一个将该程序的数据暂时拷贝到硬盘上,释放出部分空间来供程序 C 使用,然后再将程序 C 的数据全部装入内存中运行;
(3)程序运行的地址不确定。当内存中的剩余空间可以满足程序 C 的要求后,操作系统会在剩余空间中随机分配一段连续的 20M 大小的空间给程序 C 使用,因为是随机分配的,所以程序运行的地址是不确定的。
使用虚拟地址2个目的:
(1)允许程序在不修改的情况下,可以运行在不同的硬件环境下;许多应用共享物理内存的多任务系统;
(2)通过虚拟地址空间隔离开不同的程序,可以保护应用
虚拟地址(AGU中产生)
线性地址分为两部分:页偏移(VPO)和页号(VPN)
物理地址 :
线性地址分为两部分:页偏移(PPO)和页号(PPN)
虚实地址转换:将一个虚拟地址转换为物理地址
页表:维护虚拟页到物理页的映射,储存在主存中
TLB(translation lookaside buffer):页表的cache,只缓存页表表项
TLB索引由虚拟地址页号的t个最低位组成(假设TLB有2^T个组,TLB标记由剩余位组成)

Alpha系列处理器中,TLB完全由软件控制,OS有很大的自由,并有专门的指令来完成TLB表项的增添和移除
X86中,TLB由硬件控制,大多数时候对OS可见,页的映射有专门的硬件可理解的格式。
3、CPU利用TLB怎么访问cache

二、cache structure organization(缓存结构)
1、通用Cache结构

一个cache被组织成有一定数目的组的数组。每个组都有一定数目的cache行。每个行里面包含一定字节的cache block,cache块。cache块中存储着程序的数据。一个valid有效位来指明这个行是否包含有有意义的信息,还有一个tag标记位,唯一的标识存储在这个cache行中的cache块。
设一个cache块有2^b个字节,有2^s的组,那这个cache的结构将一个物理地址划分成了三部分。b个比特,s个比特和剩下的比特。s个比特是一个组的索引,这个索引帮助我们找到需要的数据是在哪一个组中。一旦我们找到了数据所在的组,它前面的标记位就可以帮助我们所需要的数据是在哪一个cache行中。接下来,b个比特可以表示偏移量,帮助我们准确找到cache块中的数据。
当每个组只有一个cache行时,我们叫这种cache为直接映射cache。当一个cache只有一个组的时候,这时称这个cache为全相联cache。有多个组和多个行的cache称为组相联cache。我们以组相联为例看cache是如何根据物理地址找到数据的。
直接映射:每个组(set)只有一个行(line)
组映射:每个组(set)有多个行(line)
全相联:只有一个组(set)
行(line)
block:包含n个字节的数据
valid bit:指明这个行是否包含有意义的信息
tag:唯一的标识block

设一个cache块有2的b次方个字节,有2的s次方的组,那这个cache的结构将一个物理地址划分成了三部分。b个比特,s个比特和剩下的比特。s个比特是一个组的索引,这个索引帮助我们找到需要的数据是在哪一个组中。一旦我们找到了数据所在的组,它前面的标记位就可以帮助我们所需要的数据是在哪一个cache行中。接下来,b个比特可以表示偏移量,帮助我们准确找到cache块中的数据。

我们以一个二路组相联为例简单看一下CPU是如何访问cache的。
首先,组选择。我们用index索引位,找到我们所需要的数据是在哪个组中。
然后我们把这个组所有的数据都取出来。

其次,行匹配。我们利用标记位,在有效位有效的情况下找到我们所需要的数据是在哪个行中。
如果没有找到,就是一次cache miss。如果找到了,就是cache的命中。
最后,取数据,根据块偏移量,找我我们所需要的数据。
在进行完组选择之后,需要把这个组的tag域和data域都取出来,进行行匹配。就是说,这个组的tag和data是同时取出来的。这就是cache中对于tag和data访问的一种形式。并行访问。具体实现是这样的。

N路组相联
将tag和data域的数组都取出来,再进行tag的匹配。

并行访问的流水线实现是这样的。可以看到,tag和data数组是在同一个时钟周期内同时访问的。
那其实还有一种情况。当进行组选择之后,为什么一定要把这个组里面的所有cache行都取出来进行匹配呢?可以先把tag数组取出来,进行匹配,当确定cache命中,需要的数据就是这一行的时候,再把这一行取出来,进行块偏移量的计算,最后取出来。这种情况就是tag和data的串行访问。具体的实现是这样的。

先把tag数组取出来,tag匹配,然后再进行data的访问。

tag和data数组的串行访问的流水线实现是这样的。可以看到tag和data被分到两个时钟周期去执行,先访问tag数组,后访问data数组。

接下来比较一下并行和串行。
首先,因为不需要把整个组的数据都读出来,所有串行比并行功耗要低。
其次,因为不需要把整个组的数据都读出来,少了很多数据通路,对tag的访问时间就会变短,时钟周期就变短。换句话说,串行的处理频率要高,并行的频率低。
接着可以看到,对于cache的访问,串行要比并行多一个周期才能将数据访问出来。因此对于cache的访问,并行要比串行快。
对于对cache的访问时间要求不那么严格的处理器,例如乱序处理器,它可以通过乱序执行指令弥补运行上的延迟,因此,乱序处理器可以选择串行访问,低功耗。对于对cache访问时间要求比较严格的处理器,例如按序处理器,它可以选择并行访问,但是要处理高功耗低频率的问题。
三、non-blocking cache(非阻塞缓存)
miss分为3种:
(1)Primary miss: Cache块的first miss,向更高级发起fetch request;
(2)Secondary miss:基于first miss的再次miss;
(3)Structural-stall miss:硬件资源(例如MSHRs)无法处理的Secondary miss,会导致结构相关的停顿。
blocking cache:命中失效时阻塞流水线;等待失效处理完毕后开始流水线。
non-blocking cache:命中失效时继续执行后续无关指令;保存失效信息。
MSHR(miss status holding register):失效状态保存寄存器
设计实现:
Implicitly addressed MSHRs(Kroft提出)
explicitly addressed MSHRs(Farkas和Jouppi提出)
In-Cache MSHRs
1、Implicitly addressed MSHRs
当有一条miss信息的时候,希望把它存在MSHR里面。首先,这个MSHR要有一个有效位,能让表明MSHR里面所存储的信息是否有效。其次,希望把在同一个block里面miss的信息存储在同一个MSHR里面,这样方便以后的机制来进行管理,比如只需要一次访存把数据拿回来就可以让所有在同一block里面miss的指令来用。因此MSHR需要记录一个block 地址。还需要一个比较器,每当产生一个miss的时候,将miss的block的地址与每一个MSHR的block地址相比较,如果相同,就把它存在同一个MSHR里面。那miss在同一个block块中的信息要如何存放呢?隐式的MSHR是这样解决的。假设一个cache块里面有N个字,那一个MSHR里面就列出N个条目。每个条目记录对应word上的miss信息。

N entry(N words in a cache block):
valid bit;
destination register;
format(数据大小、有无符号扩展、字内偏移等)

缺点:
(1)无法储存同一word中的miss(按字划分,block offset已经固定了)
(2)一定的存储浪费
2、explicity addressed MSHRs
与implicitly结构类似
添加block offset
允许存储同一block offset失效的信息

3、In-Cache MSHRs
目的:减少额外的硬件开销。
发现:等待被填充的Cache Block可以作为存储MSHRs信息的存储。
实现方式:
每个tag多缓存一位transient bit来表明当前block是miss的,正在从更高级的存储中取。然后tag域存储block地址,data array存储MHSRs信息;
既可以隐式也可以显式;
可以存储尽可能多的MSHRs。
四、multiported cache(多端口缓存)
多端口缓存:
在一个周期内支持多条load/store操作;
目的:高带宽传输
实现方式:
(1)true multiported
(2)array replication
(3)virtual multiporting
(4)multibanking
1、true multiported
(1)复制全部控制通路和数据通路
(2)双倍硬件,2个读端口
(3)增长访问时间 影响时钟周期
(4)没有应用于商业处理器
true multiported:不一定需要2个写端口,如果处理器能够保证同一位不会在一个周期被写2次
2个读端口会很大程度上增加Cache访问时间,从而影响时钟周期。
2、array replication
(1)复制全部控制通路和数据通路
(2)复制tag和data array
(3)空间浪费
(4)保持同步性(存储、替换、有效位等)
Array replication和真多端口非常类似,只不过复制了数据。
或者只复制data array但使用双端口的tag array。
3、virtual multiporting
(1)分时复用
(2)前半个周期一个load,后半个周期另一个
(3)IBM Power2和Alpha 21264
(4)时钟频率太高,被弃用
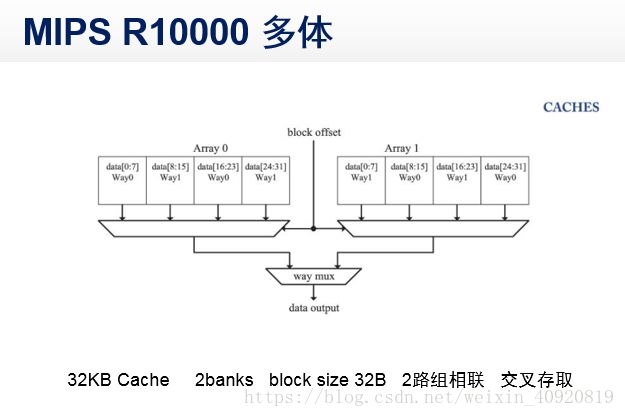
4、multibanking(多体)
(1)将cache分为多个bank
(2)每个bank是单端口
(3)访问不同bank可实现多端口访问
(4)MIPS R10000 多体 (2loads+1store)/cycle
五、I-cache(指令缓存)
1、串行vs.并行
串行:访问时间长
并行:访问时间短(缩减预测错误开销)
(低时钟周期、高功耗)
二者需要trade off
2、non-blocking vs.blocking
non-blocking:命中失效时继续执行后续无关
blocking:指令间具有相关性
3、多端口vs.单端口
多端口:同一周期内支持多条操作
取指都是连续的
同一block里包含多条指令
单端口