机器学习/推荐系统/推荐系统算法工程师面试指导
面试指导
文章目录
-
-
- 面试指导
- 1、机器学习/推荐系统/推荐系统算法工程师面试技能图
- 2.1 推荐系统算法相关面试笔试题
-
- 2.2 机器学习相关问题
- 重点:
- 2.3 框架方面
- 2.4 业务流程
- 3、简历指导项目编写
- 4、书籍资料网站推荐
-
- 1、机器学习/推荐系统/推荐系统算法工程师面试技能图
- 2、知识、工具、逻辑、业务面试题
- 3、简历编写与招聘需求
- 4、书籍资料网站推荐
1、机器学习/推荐系统/推荐系统算法工程师面试技能图
但抛开具体的岗位要求,从稍高的角度角度看待这个问题,一名机器学习/推荐系统算法、研发工程师的技术素质基本可以拆解成下面四个方面:知识、工具、逻辑、业务。

在最小要求的基础上,算法工程师的能力要求是相对全面的。其实所谓算法工程师,就是因为你不仅应该是一位合格的“工程师”,还应该再次基础上有算法的改进和实现的能力。除此之外,大数据工程师更注重大数据工具和平台的改进,研究员则在知识和逻辑层面相对突出。
下面给出相关要求,有通用的要求,不管是做不想关的领域。然后深入一个具体领域如推荐系统工程师的职位,会对应有一些具体的能力要求:
知识:主要是指你对ML相关知识和理论的储备(40%)
- 机器学习相关的知识+基础的深度学习知识
- 如主流CTR模型、推荐算法模型的原理和技术细节
工具:将你的ML知识应用于实际业务的框架工具(30%)
- 如coding能力、spark、tensorflow、serving相关工具
逻辑:基础算法逻辑相关(10%)
- 常见基础算法题,逻辑题,模型之间演化关系,考量举一反三能力
业务:深入理解所在行业的商业模式,从业务中发现而改进模型算法的能力(20%)
- 根据比如文章推荐构建模型场景和需求,了解业务走向,根据业务指定目标模型
2.1 推荐系统算法相关面试笔试题
11.如果选用一种其他的模型替代XGBoost或者改进XGBoost你会怎么做,为什么?(业务+逻辑+知识)
1、 协同过滤(基于物品和基于用户)的原理,ItemCF、UserCF、SVD矩阵分解必须会说明?
2、以下推荐方法中,推荐结果多样性最好的是:( B )
A. 基于内容的推荐
B. 基于用户的协同过滤推荐
C. 基于物品的协同过滤推荐
D. 热门推荐
3、请描述至少2种熟悉的推荐系统中常用的算法原理(如: 协同过滤、矩阵分解等)
4、协同过滤经常被用于推荐系统,包含基于内存的协同过滤、基于模型的协同过滤以及混合模型。 以下说法不正确的是(C)
- 基于用户的协同过滤推荐、基于物品的协同过滤推荐都是基于内存的协同过滤推荐
- 混合模型综合两个模型的优点,通常能够达到由于两者的效果
- 基于内存的协同过滤可以较好解决冷启动问题
- 基于内存的协同过滤实现比较简单,新数据可以较方便的加入
5、协同过滤是推荐系统构成中非常经典的算法,分为基于用户的协同过滤和基于物品的协同过滤。它的本质是通过计算用户与用户之间的相似度,或物品与物品的相似度来对用户的兴趣进行预测,进而推荐相关物品给用户。请使用上述知识解答下面问题:
(1)现有五个用户A,B,C,D,E;三个物品X,Y,Z;通过分析用户在网站上的购物历史和人群画像标签,分析出各个用户对各个物品的兴趣指数。兴趣指数见下面表格:
| X | Y | Z | |
|---|---|---|---|
| A | 3 | 4 | 3 |
| B | 2 | 4 | 4 |
| C | 3 | 5 | 4 |
| D | 2 | 2 | 3 |
| E | 4 | 1 | 4 |
现需要向用户E推荐相机,已知A,B,C,D对于三种相机M,N,O的兴趣打分如下:
| M | N | O | |
|---|---|---|---|
| A | 3 | 4 | 3 |
| B | 5 | 1 | 2 |
| C | 2 | 5 | 5 |
| D | 4 | 2 | 3 |
请给出给E推荐相机的最佳顺序, 给出详细解答过程
(2) 在上述的问题中,大家可以发现,协同过滤对于用户的历史数据依赖较强,那么对于冷启动问题,有什么样比较好的解决方法?
6、视频推荐场景中过于聚焦的视频推荐往往会损害用户体验,所以,系统会通过一定程度的随机性给用户带来发现的惊喜感。假设在某推荐场景中,经计算A和B两个视频与当前访问用户的匹配度分别为0.8分和0.2分,系统将随机为A生成一个均匀分布于0到0.8的最终得分,为B生成一个均匀分布于0到0.2的最终得分,那么最终B的分数大于A的分数的概率为( B)
1/2、 1/8、1/16、1/4
7、协同过滤经常被用于推荐系统, 包含基于内存的协同过滤, 基于模型的协同过滤以及混合模型, 以下说法正确的是
- 基于模型的协同过滤能比较好的处理数据稀疏的问题
- 基于模型的协同过滤不需要item的内容信息
- 基于内存的协同过滤可以较好解决冷启动问题
- 基于内存的协同过滤实现比较简单, 新数据可以较方便的加入
8、说说矩阵分解
9、简述word2vec;说说滑动窗口大小以及负采样个数的参数设置以及设置的比例;怎么衡量学到的embedding的好坏
10、说说推荐系统算法大概可以分为哪些种类:(1)基于内容;(2)基于协同过滤:基于内存(UB IB);基于模型(MF)
11、推导LR过程
12、图结构是怎么存储的?利用你所做的这个图结构实现深度/广度优先遍历,深度优先遍历用栈结构实现;广度优先遍历用队列结构实现
13、详细描述工作,画出来整体框架?
14、随机森林有了解吗?知道里面的有放回的采样方法吗?给定n个小球,有放回地采样。当n趋向于无穷的时候,某小球不被取到的概率是多少?
15、关键词怎么提取的?TF-IDF有改进吗?怎么改进?与TextRank区别?
16、UserCF、ItemCF公式?原理区别?与基于内容的推荐的区别?
2.2 机器学习相关问题
重点:
- 线性回归、逻辑回归
- 决策树相关算法:决策树、随机森林、GBDT、XGboost
- 聚类相关算法
- 神经网络:NN相关基础原理
- 算法优化:正则化、梯度下降等
1.GBDT的原理**(知识)**
2.决策树节点分裂时是如何选择特征的?(知识)
3.写出Gini Index和Information Gain的公式并举例说明
(知识)
4.分类树和回归树的区别是什么?(知识)
5.与Random Forest作比较,并以此介绍什么是模型的6.Bias和Variance**(知识)**
7.XGBoost的参数调优有哪些经验**(工具)**
8.XGBoost的正则化是如何实现的**(工具)**
9.XGBoost的并行化部分是如何实现的**(工具)**
10.为什么预测股票涨跌一般都会出现严重的过拟合现象
(业务)
1.softmax函数的定义是什么?(知识)
2.神经网络为什么会产生梯度消失现象?(知识)
3.常见的激活函数有哪些?都有什么特点?(知识)
4.挑一种激活函数推导梯度下降的过程。(知识+逻辑)
5.Attention机制什么?(知识)
6.阿里是如何将attention机制引入推荐模型的?(知识+业务)
7.DIN是基于什么业务逻辑引入attention机制的?(业务)
8.DIN中将用户和商品进行了embedding,请讲清楚两项9.你知道的embedding方法。(知识)
10.你如何serving类似DIN这样的深度学习模型**(工具+业务)**
查找相关资料找到更多面试题:《百面机器学习》

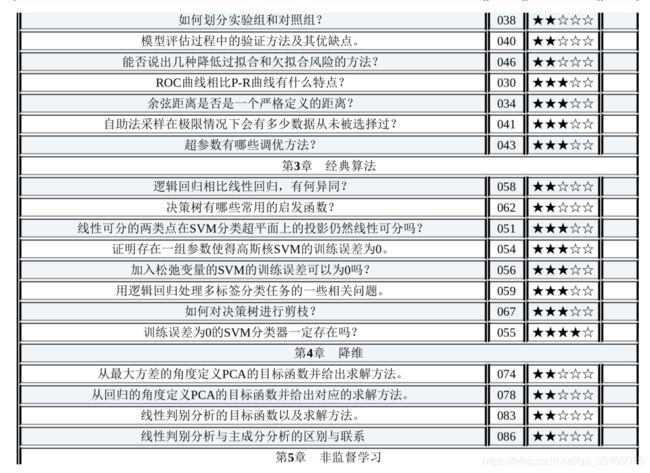


2.3 框架方面
- 大数据相关框架:spark、hbase、Hive、kafka
- 深度学习框架:TensorFlow
2.4 业务流程
- 项目总结
3、简历指导项目编写


二、掌握技能(根据就业方向选择性增加修改删除)
1、机器学习相关、模型、算法原理、特征处理
2、深度学习推荐、基础推荐相关
3、大数据框架、数据库使用
- 熟练使用Numpy科学计算工具、Pandas数据分析包、Matplotlib数据可视化工具等进行数据操作、采集、处理、清洗、可视化、规整数据集。
- 熟悉Scikit-learn机器学习框架,熟练掌握K-近邻、LinearRegression、LogisticsRegression、RidgeRegression、LassoRegression、Decision Tree、Bayes、SVM、K-Means等机器学习算法应用。
- 熟悉PCA进行数据降维。
- 熟练掌握特征工程的使用(REF, chi2)。
- 熟悉数据集的基本处理方法(空值处理, 数据归一化以及标准化)
- 熟悉欠拟合、过拟合产生的原因及解决办法。
- 熟练应用网格搜素、交叉验证、混淆矩阵进行模型参数调优和模型评估。
- 熟悉常见集成的分类及算法,例如RF(Bagging)、GBDT(Boosting)算法。
- 熟悉hadoop的搭建以及相关组件(Yarn、Hdfs、MapReduce)的使用、开发;
- 熟练使用Flume数据采集工具;
- 熟悉hbase、mysql等相关数据库使用,以及Hivesql的编写;
- 熟悉Kafka消息处理工具;
- 熟悉spark 、spark sql 、spark streaming 架构模型及使用;
- 熟练使用linux系统,熟悉常用的linux的shell命令,能在linux系统下搭建开发环境;
- 掌握sqoop的数据迁移工具的使用;
- 熟悉深度学习框架TensorFlow。
三、项目介绍编写(根据项目特点选择性增加修改删除):
1、项目的描述
样本:
黑马头条推荐系统建立在海量用户与海量文章之上,使用Lambda架构整合实时计算和离线计算,借助分布式环境提升计算能力;使用Flume收集用户的点击、浏览、收藏等行为,建立用户画像和文章画像,并存储于HDFS集群;通过离线Spark SQL计算建立HIVE特征中心,存储到HBase集群;通过ALS、LR、Wide&Deep等机器学习与深度学习、推荐算法进行智能推荐,达到千人千面的用户推荐效果。
项目描述:本项目是一个个性化推荐系统。该项目以离线推荐为主,实时推荐为辅, 协同过滤与基于内容推荐相结合,来提高用户体验并增加用户粘性及使用时间。主要的流程包括业务数据处理,书籍画像建模,日志数据处理处理,实时推荐等部分。
项目描述
项目描述:一个为用户提供家居主题讨论、商城服务、客户调查、社区功能的平台。爱尚家居广告推荐系统旨在提高用户转率,提高公司收益,增加用户体验,主要的包括创建ALS模型,召回商品,基于逻辑回归实现CTR预估,离线数据处理缓存,实时推荐等
项目描述:本项目主要是通过收集用户的行为数据,用户经常关注和收听的内容,以及用户的年龄分布,终端设备等,对每个用户建立用户画像,通过训练模型,完成推荐系统。目的是做到更精准的推送,在不影响业务的前提下,进行精准推送,增高用户黏性。
随着视频网站的不断增多,为了更好的满足客户体验度,电影推荐可以很好的解决这一问题。根据电影的种类、评分,再加上用户的性别、年龄等信息,进行多维度数据分析,实现推荐用户可能喜欢的电影,实现推荐同类型的电影,建立客户个性化推荐系统,给用户以良好的
进行分类,然后分析推荐效果,并针对用户的行为数据不断完善用户画像;
该项是典型社交类的好友推荐设计开发项目。该系统是在用户的角度,快速的找到与自己志趣相投的以及很可能成为好友的用户。项目包括二度好友推荐,拥有共同圈子、共同兴趣的好友,浏览过个人主页等个性化的推荐策略;购物达人、博览群圈、随即标签的非个性化推荐。无论是新用户还是老用户,都能在系统迅速的建立起自己的社交圈,提高了用户黏度。
该项目是典型的电商推荐项目,该系统主要是是为用户推荐商品,使用户更开速的找到自己想要购买的以及用户可能会消费的商品,本项目基于用户历史行为包括用户的浏览、收藏、分享、购买等行为,对用户的每一个行为给予相应的权重,应用协同过滤进行个性化推荐;通过历史销量、近期销量排行、收藏数等指标进行非个性化推荐,通过用户默认收货地址进行店铺推荐的过滤
2、项目架构与技术点
项目架构:Flume + Kafka +HDFS + Spark Streaming + Spark SQL + HBase+ TensorFlow
1、使用flume收集日志数据,将用户行为数据采集到HDFS
2、通过Flume将用户行为数据采集到HDFS;
3、Kafka对接Flume将用户行为日志收集到消息队列;
4、Spark Streaming实时处理Kafka发送来的点击日志,实时更新特征、实时更新召回集;
1.通过Flume获取点击流日志数据,以及通过sqoop获取mysql中静态数据;
2.将数据保存到hdfs中,构建hive数据仓库;
3.通过spark读取数据文件,进行数据的处理;
4.最终将数据保存到Hbase中,保存到hbase和redis中
5、spark离线保存tfrecords文件
6、采用TensorFlow estimator进模型训练
7、TF serving进行模型部署
10、物品文本的关键词、主题词构建,TFIDF、TextRank使用
11、文本向量word2vec计算
12、标签存储进Hbase,并将标签和历史标签进行对比,根据衰减系数进行合并
3、项目业务拓展:
社交类推荐、电商推荐商品、资讯类推荐、
4、书籍资料网站推荐
书籍
《推荐系统系统与深度学习》
《百面机器学习》
《机器学习》-周志华
资料网站论文:
- RecSys:https://recsys.acm.org/best-papers/
了解最新推荐系统论文动态,模型变化特点。每年学习几篇新新结构
面试题、推荐问题社区:
- 实习|美团机器学习算法岗实习四面面经(推荐系统方向)https://zhuanlan.zhihu.com/p/65034443?utm_source=wechat_session&utm_medium=social&utm_oi=752139001741201408
- 在你做推荐系统的过程中都遇到过什么坑?https://www.zhihu.com/question/32218407/answer/588762146?utm_source=wechat_session&utm_medium=social&utm_oi=752139001741201408
- 2019校招|算法面经+春秋招总结(含BAT TM W等):https://zhuanlan.zhihu.com/p/47150666?utm_source=wechat_session&utm_medium=social&utm_oi=752139001741201408
- 2019秋招|算法岗面经(阿里头条网易爱奇艺等)https://zhuanlan.zhihu.com/p/45287109?utm_source=wechat_session&utm_medium=social&utm_oi=752139001741201408