利用Python爬取翻译网站的翻译功能
现在我想分享一个利用Python技术,爬取一个翻译网站的翻译功能的小代码。
首先隆重介绍我们今天将要爬取的网站:http://fy.iciba.com/
咱们用Python中的urllib模块的功能进行爬取

众所周知,在爬虫的准备工作中我呢吧需要确定咱们爬取网站的url
那么,这个翻译网站的url如何确定呢?
我们进入网站,并单击F12打开开发者工具(这里我们用的谷歌浏览器)

这个网站的翻译功能分为两个部分:英译汉 汉译英
然后我决定先翻译两个单词玩玩!翻译的同事不关闭开发者工具,观察其变化。
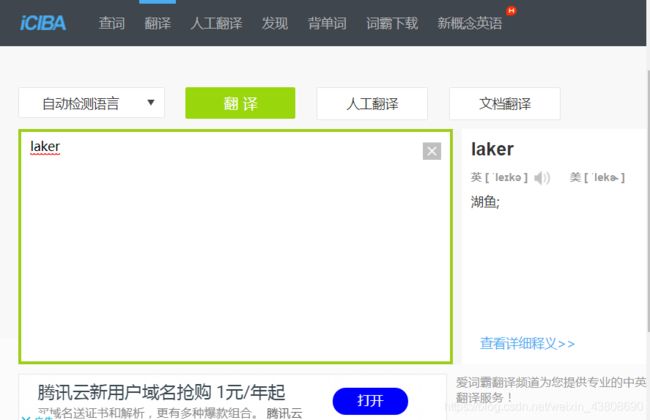
事实证明这个网站的翻译能力还有待加强,毕竟每一个NBA球迷都知道laker是湖人的意思嘛!
在翻译的过程中我们发现他有一个地方在每一次翻译的时候都会增加一个:ajax.php?a=fy

打开这两个都可以在下面的Form Data中找到我们想要检索的单词

这个时候

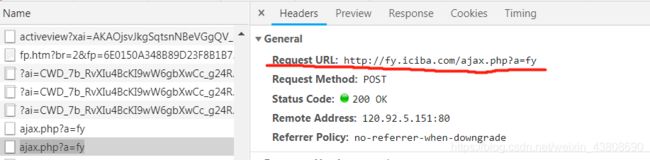
我们发现这里的Request URL 是一个常量,每次的搜索时都不会改变,改变的部分仅限于底部的Form Data,所以我们可以确定这个搜索网站的base_url就是:
![]()
你小子啦!!
落实为代码就是
#确定URL
base_url="http://fy.iciba.com/ajax.php?a=fy"
data={
"f":"auto",
"t":"auto",
"w":word
}
data_str=parse.urlencode(data)
# url=base_url+data_str
得到了URL就可以进行下一步伪装和封装了。
这两部分在一起说是因为基本没有难点,只需要根据书写规范填就好了。
伪装部分:这里我们需要伪装成浏览器访问这个网页

我们需要的伪装信息可以在开发者工具中的这里找到。
#伪装
header={"User-Agent":" Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/71.0.3578.98 Safari/537.36"}
封装部分用代码表示为:
#封装
response=request.Request(url=base_url,headers=header,data=bytes(data_str,encoding="utf-8"))
req=request.urlopen(response).read().decode("utf-8")
以上,我们初步将这个网页整个爬取下来了。现在我们需要在Python中将这个翻译的功能移植过来,这里我们定义了一个类——fanyi() 翻译类中我们定义一个函数——translate 来完成我们翻译功能的移植
在这个网站中他的翻译功能分为两部分:英译汉 汉译英
那么很明显这两个功能需要分开来实现,我们现在在网站中分别让他翻译英语和汉语,来观察他的变化:翻译的同时打印翻译所得的翻译数据。
通过翻译单词“red”和汉语“红色的”,我们发现:
#中译英
#{'status': 1, 'content': {'from': 'zh-CN', 'to': 'en-US', 'out': 'red', 'vendor': 'ciba', 'err_no': 0}}
#英译中
#{'status': 0, 'content': {'ph_en': 'red', 'ph_am': 'rɛd', 'ph_en_mp3': 'http://res.iciba.com/resource/amp3/oxford/0/3b/57/3b577c8f5bfa2cc523fac83910773295.mp3', 'ph_am_mp3': 'http://res.iciba.com/resource/amp3/1/0/bd/a9/bda9643ac6601722a28f238714274da4.mp3', 'ph_tts_mp3': 'http://res-tts.iciba.com/b/d/a/bda9643ac6601722a28f238714274da4.mp3', 'word_mean': ['adj. 红色的;(脸)涨红的;烧红的;红头发的;', 'n. 红色;红衣服;红颜料;红葡萄酒;']}}
我们发现状态码’status’,在中译英时状态码为1,英译中时为0,。

根据这个规律,我们可以进行判断了。代码如下
trans_word = translate(word)
current_state=trans_word["status"]
#在这里判断中译英
if current_state==1:
current_content=trans_word["content"]
print(current_content["out"])
#否则则汉译英
else:
current_content0=trans_word["content"]
print(current_content0["word_mean"])
以上就是全部的逻辑思路,将思路与代码封装为一个类——fanyi中,代码如下:
from urllib import request,parse
import json
class fanyi():
def translate(word):
#确定URL
base_url="http://fy.iciba.com/ajax.php?a=fy"
data={
"f":"auto",
"t":"auto",
"w":word
}
data_str=parse.urlencode(data)
# url=base_url+data_str
#伪装
header={"User-Agent":" Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/71.0.3578.98 Safari/537.36"}
#封装
response=request.Request(url=base_url,headers=header,data=bytes(data_str,encoding="utf-8"))
req=request.urlopen(response).read().decode("utf-8")
obj=json.loads(req)
return obj
if __name__ == '__main__':
word = input("请输入需要翻译的词句:")
#print(trans_word)
#中译英
#{'status': 1, 'content': {'from': 'zh-CN', 'to': 'en-US', 'out': 'red', 'vendor': 'ciba', 'err_no': 0}}
#英译中
#{'status': 0, 'content': {'ph_en': 'red', 'ph_am': 'rɛd', 'ph_en_mp3': 'http://res.iciba.com/resource/amp3/oxford/0/3b/57/3b577c8f5bfa2cc523fac83910773295.mp3', 'ph_am_mp3': 'http://res.iciba.com/resource/amp3/1/0/bd/a9/bda9643ac6601722a28f238714274da4.mp3', 'ph_tts_mp3': 'http://res-tts.iciba.com/b/d/a/bda9643ac6601722a28f238714274da4.mp3', 'word_mean': ['adj. 红色的;(脸)涨红的;烧红的;红头发的;', 'n. 红色;红衣服;红颜料;红葡萄酒;']}}
trans_word = translate(word)
current_state=trans_word["status"]
#在这里判断中译英
if current_state==1:
current_content=trans_word["content"]
print(current_content["out"])
#否则则汉译英
else:
current_content0=trans_word["content"]
print(current_content0["word_mean"])
fanyi()
运行后的效果如下:


运用爬虫的技术将翻译功能就这么从网站移植到了我们的Pycharm上了,是不是很简单?
以上