Go语言微服务架构实战:第八节 微服务管理--服务发现
在微服务简介篇,我们已经介绍过微服务架构中要解决的四个基本的问题。从本节课开始我们来学习如何实现服务的管理。
为什么要使用服务发现
设想下,我们写了一些通过REST API或者Thrift API调用某个服务的代码,为了发起这个请求,代码需要知道服务实例的网络地址(IP 地址和端口号)。在传统运行在物理机器上的应用中,某个服务实例的网络地址一般是静态的,比如,代码可以从只会偶尔更新的配置文件中读取网络地址。
然而在现在流行的基于云平台的微服务应用中, 有更多如下图所示的困难问题需要去解决:
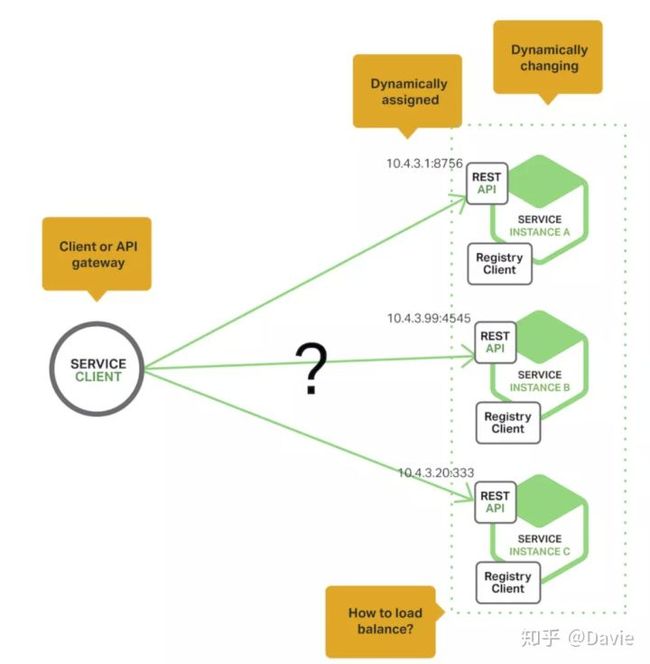
服务实例需要动态分配网络地址,而且,一组服务实例可能会因为自动扩展、失败或者升级发生动态变化,因此客户端代码应该使用更加精细的服务发现机制。
在生产实践中,主要有两种服务发现机制:客户端发现和服务端发现。我们分别来介绍这两种机制:
客户端发现模式
当我们使用客户端发现的时候,客户端负责决定可用服务实例的网络地址并且在集群中对请求负载均衡, 客户端访问服务登记表,也就是一个可用服务的数据库,然后客户端使用一种负载均衡算法选择一个可用的服务实例然后发起请求。该模式如下图所示:
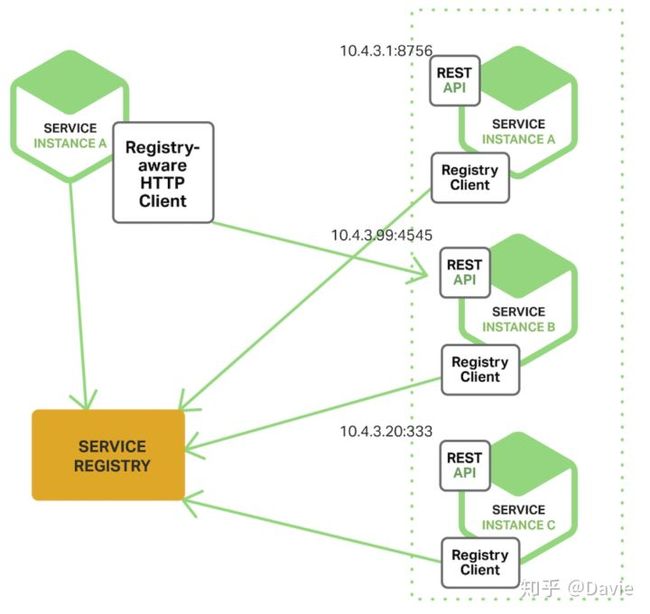
该模式和我们之前在微服务简介章节介绍的服务发现机制中的客户端机制是一样的,如图所示:
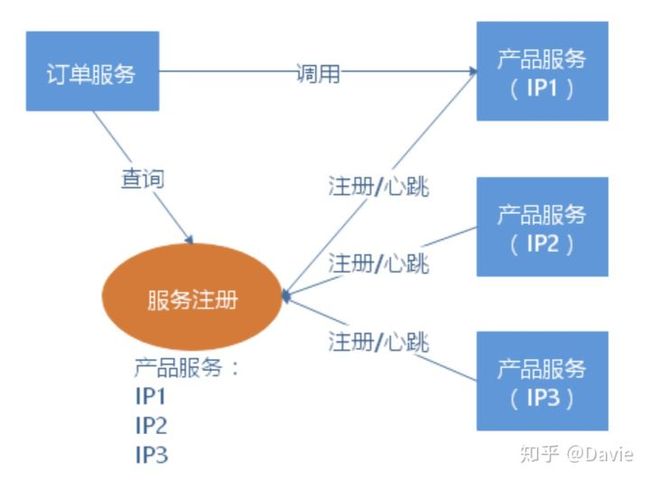
服务实例的网络地址在服务启动的时候被登记到服务注册表中 ,当实例终止服务时从服务注册表中移除。服务实例的注册一般是通过心跳机制阶段性的进行刷新。
- 客户端发现机制的优势:
- 该模式中只增加了服务注册表,整体架构也相对简单;
- 客户端可以使用更加智能的,特定于应用的负载均衡机制,如一致性哈希。
- 客户端发现机制的缺点: 客户端发发现机制中,客户端与服务注册表紧密耦合在一起,开发者必须为每一种消费服务的客户端对应的编程语言和框架版本都实现服务发现逻辑。
- 客户端发现模式的应用:往往大公司会采用客户端发现机制来实现服务的发现与注册的模式。
服务端发现模式
与客户端发现模式对应的,另外一种服务发现模式称之为服务端发现模式,整体架构如下:
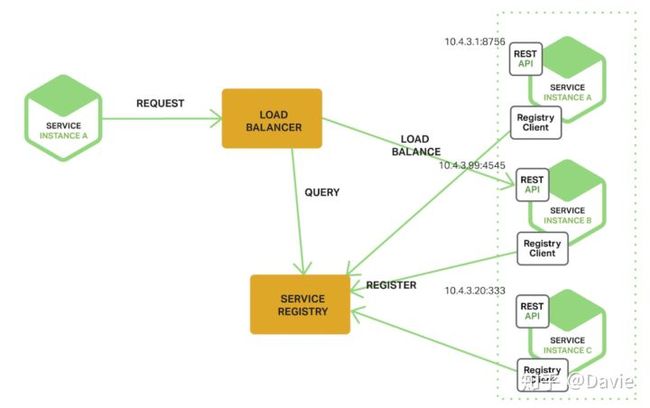
在该种模式下,客户端通过一个负载均衡器向服务发送请求,负载均衡器查询服务注册表并把请求路由到一台可用的服务实例上。和客户端发现一样,服务实例通过服务注册表进行服务的注册和注销。
同样的,服务端发下模式也有优势和缺点:
- 服务端发现模式的优点:
- 服务发现的细节对客户端来说是抽象的,客户端仅需向负载均衡器发送请求即可。
- 这种方式减少了为消费服务的不同编程语言与框架实现服务发现逻辑的麻烦。很多部署环境已经提供了该功能。
- 服务端发现模式的缺点: 除非部署环境已经提供了负载均衡器,否则这又是一个需要额外设置和管理的可高可用的系统组件。
服务注册表
服务注册表是服务发现的关键部分,它是一个包含服务实例网络地址的的数据库。一个服务注册表需要高可用和实时更新,客户端可以缓存从服务注册表获取的网络地址。然而,这样的话缓存的信息最终会过期,客户端不能再根据该信息发现服务实例。因此,服务注册表对集群中的服务实例使用复制协议来维护一致性。
举个例子:Netflix Eureka是典型的服务注册表的案例实现,它为服务实例的注册与查询提供了REST API:一个服务实例可以使用POST来注册自己的网络地址,它必须每30秒通过PUT去刷新,服务实例可以直接或者在服务实例注册超时的时候使用DELETE删除注册表中的信息,另外客户端可以使用HTTP GET获取注册实例的信息。
当然,除了Netflix Eureka以外,还有:
- etcd:一个高可用、分布式、一致性、key-value方式的存储,被用在分享配置和服务发现中。两个著名的项目使用了它:Kubernetes和Cloud Foundry。
- consul:一个发现和配置服务的工具,为客户端注册和发现服务提供了API,Consul还可以通过执行健康检查决定服务的可用性。
- Apache Zookeeper:Zookeeper是一个广泛使用、高性能的针对分布式应用的协调服务。 Apache Zookeeper本来是Hadoop的子工程,现在已经是顶级工程了。
服务注册方式
服务实例必须使用服务注册表来进行服务的注册和注销,在实践过程中有不同的方式来实现服务的注册和注销:
- self-registration模式:这种模式下,服务实例自己负责通过服务注册表对自己进行注册和注销,另外如何有必要的话,服务实例可以通过发送心跳包请求防止注册过期。该种模式的架构实现如下:
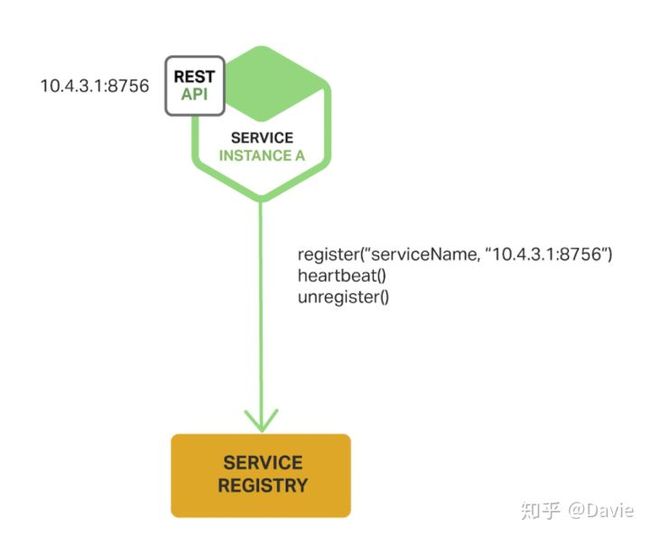
self-registration模式有一些优势也有一些劣势:优势之一是它相对简单,而且不强制使用其他的系统组件。然而,一个很大的劣势是 它使得服务实例和服务注册表强耦合 ,你必须在每一个使用服务的客户端编程语言和架构代码中实现注册逻辑。
- third-party registration模式:当使用third-party registration模式的时候,服务实例本身并不负责通过服务注册表注册自己,相反的,通过另一个被称作service registrar系统组件来处理注册。service registrar通过轮询或者订阅事件来检测一些运行实例的变化,当它检测到一个新的可用服务实例时就把该实例注册到服务注册表中去,service registrar还负责注销已经被终止的服务实例,下图展示了该模式的架构:

third-party registration模式也有一些优势和劣势:主要优势是使得服务从服务注册表中被解耦,你不必为开发者使用的每种开发语言和框架实现服务注册的逻辑,相反,服务实例的注册被一个专有服务以集中式的方式处理。该模式的劣势是,除非它被内置在部署环境中,不然这又是一个需要被设置和管理的高可用系统组件。
总结
在一个微服务应用中,一组运行的服务实例是动态变化的,实例有动态分配的网络地址,因此,为了使得客户端能够向服务发起请求,必须要要有服务发现机制。
服务发现的关键是服务注册表,服务注册表是可用服务实例的数据库,它提供了管理和查询使用的API。服务实例使用这些管理API进行服务的注册和注销,系统组件使用查询API来发现可用的服务实例。
- 客户端发现的案例:Eureka、ZooKeeper
- 服务端发现的案例:consul+nigix
我们选择Consul来进行学习。
Consul
- Consul概述consul是google开源的一个使用go语言开发的服务发现、配置管理中心服务,consul属于微服务架构的基础设置中用于发现和配置服务的一个工具。Consul提供如下的几个核心功能:
- 服务发现:Consul的某些客户端可以提供一个服务,其他客户端可以使用Consul去发现这个服务的提供者。
- 健康检查:Consul客户端可以提供一些健康检查,这些健康检查可以关联到一个指定的服务,比如心跳包的检测。
- 键值存储:应用实例可以使用Consul提供的分层键值存储,比如动态配置,特征标记,协作等。通过HTTP API的方式进行获取。
- 多数据中心:Consul对多数据中心有非常好的支持。
- 官方网站:可以访问https://www.consul.io/查看Consul的相关介绍,获取相关资料。
- 安装:在官方文档中,点击Download按钮,进入下载软件界面https://www.consul.io/downloads.html,选择自己本机系统的类型,如下图所示:
Consul最新版本是v1.5.1版本。