对数似然比相似度
最近在看mahout的相似性度量时,对其中的对数似然比相似度颇为好奇,由于书本上完全没有涉及到对数似然比相似度的计算原理,只是提供了一个函数接口,因此决定深入了解一下这个对数似然比相似度。下面mahout中的源码:
public static double logLikelihoodRatio(int k11, int k12, int k21, int k22) {
double rowEntropy = entropy(k11, k12) + entropy(k21, k22);
double columnEntropy = entropy(k11, k21) + entropy(k12, k22);
double matrixEntropy = entropy(k11, k12, k21, k22);
return 2 * (matrixEntropy - rowEntropy - columnEntropy);
}
public static double entropy(int... elements) {
double sum = 0;
for (int element : elements) {
sum += element;
}
double result = 0.0;
for (int x : elements) {
if (x < 0) {
throw new IllegalArgumentException(
"Should not have negative count for entropy computation: (" + x + ')');
}
int zeroFlag = (x == 0 ? 1 : 0);
result += x * Math.log((x + zeroFlag) / sum);
}
return -result;
}我以一个实际的例子来介绍一下其中的计算过程:假设有商品全集I={a,b,c,d,e,f},其中A用户偏好商品{a,b,c},B用户偏好商品{b,d},那么有如下矩阵:
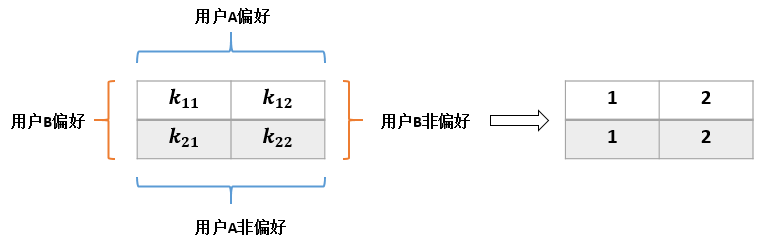
- k11 表示用户A和用户B的共同偏好的商品数量,显然只有商品b,因此值为1
- k12 表示用户A的特有偏好,即商品{a,c},因此值为2
- k21 表示用户B的特有偏好,即商品d,因此值为1
- k22 表示用户A、B的共同非偏好,有商品{e,f},值为2
此外我们还定义以下变量 N=k11+k12+k21+k22 ,即总商品数量。
计算步骤如下:
计算行熵
rowEntropy=k11+k12N(k11k11+k12logk11k11+k12+k12k11+k12logk12k11+k12)+k21+k22N(k21k21+k22logk21k21+k22+k22k21+k22logk22k21+k22)
注:代码中 k11+k12与k21+k22均被约掉了,分母N也省去了计算列熵
columEntropy=k11+k21N(k11k11+k21logk11k11+k21+k21k11+k21logk21k11+k21)+k12+k22N(k12k12+k22logk12k12+k22+k22k12+k22logk22k12+k22)计算矩阵熵
matrixEntropy=k11Nlogk11N+k12Nlogk12N+k21Nlogk21N+k22Nlogk22N
注意:以上熵的计算均没有加负号,后面会讲到原因计算相似度
UserSimilarity=2∗(matrixEntropy−rowEntropy−columnEntropy)
如何来解释这个相似度的计算方式呢?我们先来看看行熵、列熵和矩阵熵分别代表什么含义:行熵以用户A的偏好和非偏好来划分商品空间,很明显它是一个条件熵,我个人认为相对合理的解释是对于一个商品,在给定它是否属于A偏好的条件下,预测商品属于 k11、k12、k21、k22 四个空间中哪一个空间的不确定度;同理,列熵则代表给定商品是否属于B偏好的条件下,预测商品属于 k11、k12、k21、k22 四个空间中哪一个空间的不确定度;矩阵熵则表示在没有任何条件下,预测商品属于四个空间中哪一个空间的不确定度。我们以下图来看:

在给定A偏好与否的条件,预测商品属于哪一个空间的不确定度为 S1+S2 ;在给定B偏好与否的条件下,不确定度为 S2+S3 ;在不给定任何条件下,预测商品属于哪一个空间的不确定度为 S1+S2+S3 。我的理解这个 S2 表示的就是给定A、B偏好条件下的公共的不确定度,其表达的就是如果A喜欢某个商品,对B也具有协同效应;如果B喜欢某个商品,对A也具有协同效应,这种公共不确定度或者说是关联其实反映的就是A用户与B用户的相似程度。由于前面计算熵的时候没有加上负号,步骤四中正好得到一个 (−S2) ,就变成正数了,至于为什么乘上2及 1N 去哪里了我也不清楚,但这只是一种幅度变换,不影响相对关系。
当然参考论文Accurate methods for the statistics of surprise and coincidence,我们还可以从相关性的角度去解释这个对数似然比相似度。我们假设A偏好空间和A非偏好空间中概率分布满足二项分布,并进行如下假设:
假设用户B的喜好与用户1独立无关 L(H1)
用户B喜欢一个商品的概率P=k11+k21k11+k12+k21+k22
形成A偏好空间这种分布的概率就为
Ck11k11+k12∗Pk11∗(1−P)k12
形成A非偏好空间这种分布的概率为
Ck21k21+k22∗Pk21∗(1−P)k22
形成第一幅图中矩阵块分布的概率即为上面两个概率的乘积
L(H1)=Ck11k11+k12∗Pk11∗(1−P)k12∗Ck21k21+k22∗Pk21∗(1−P)k22假设用户B的喜好与用户1相关 L(H2)
在A偏好空间,用户B喜欢一个商品的概率为
P1=k11k11+k12
形成A偏好空间这种分布的概率就为
Ck11k11+k12∗Pk111∗(1−P1)k12
在A非偏好空间,用户B喜欢一个商品的概率为
P2=k21k21+k22
形成A非偏好空间这种分布的概率就为
Ck21k21+k22∗Pk212∗(1−P2)k22
形成第一幅图中矩阵块分布的概率即为上面两个概率的乘积
L(H1)=Ck11k11+k12∗Pk111∗(1−P1)k12∗Ck21k21+k22∗Pk212∗(1−P2)k22
用户A、B的相似度就为
式中 −2log 和卡方检验渐近有关,上述假设是按照用户A来划分空间,按用户B来划分空间也可以得到相同的结论,最终计算出来的结果与采用上面行熵、列熵、矩阵熵计算出来的结果一致,表明对数似然比相似度其实反映的就是用户之间喜欢物品的相关性。