【集群】corosync+pacemaker+iscsi+pcs
1、基础环境
vip(虚拟IP):192.168.100.222
iscsi(存储):192.168.100.200
node1(节点一):192.168.100.192
node2(节点二):192.168.100.195
新建highgo操作系统用户,要求三台机器highgo用户的uid、gid相同
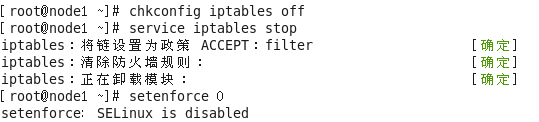
2、三台机器均关闭防火墙和SELINUX (以node1为例)
3、三台机器均SSH互信 (以iscsi为例)
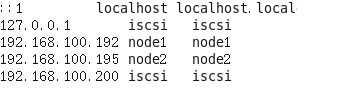
(1)修改/etc/hosts
(2)root用户执行

(3)highgo用户执行

4、ISCSI配置
(1)服务器端(iscsi)
>>>首先安装scsi-target-utils:
yum -y install scsi-target-utils
>>>编辑/etc/tgt/targets.conf,添加:(/dev/sda是新添加的用来共享的磁盘,为原生的未经过格式化的盘)
<target iqn.201605.dev:server.target1>
backing-store /dev/sda
</target>
>>>启动服务,并配置开机自启动:
service tgtd start
chkconfig tgtd on(2)客户端(node1、node2)
>>>首先安装iscsi-initiator-utils
yum -y install iscsi-initiator-utils
>>>编辑/etc/iscsi/initiatorname.iscsi,添加:
InitiatorName=iqn.201605.dev:server.target1
>>>配置服务:
chkconfig iscsi on
chkconfig iscsid on
service iscsi restart
service iscsid restart启动服务时出现失败的情况,正常

5、安装数据库(node1、node2)
node1安装过程:
(1)创建目录(挂载点)
mkdir /install/hgdb -p(2)发现服务器端有磁盘共享,并登录
![]()

(3)查询本地多一块磁盘

(4)格式化磁盘并挂载
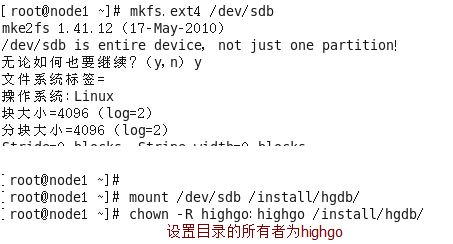
注意:若挂载时出现以下错误,即为没有格式化磁盘所致
![]()
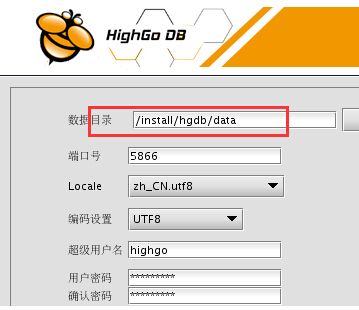
(5)切换到highgo登录系统,执行安装
>>>编辑.bash_profile,添加:
export HG_HOME=/home/highgo/hgdb注意:数据目录的选择,即将data目录置于共享磁盘中
(6)安装完成后,注销highgo,切换回root,执行关闭数据库服务、设置开机不自动启动数据库服务、卸载挂载的目录
service hgdb-se2.0.4 stop
chkconfig hgdb-se2.0.4 off
umount /install/hgdbnode2安装过程:
(1)创建目录(挂载点)
mkdir /install/hgdb -p(2)发现服务器端有磁盘共享,并登录
![]()

(3)挂载磁盘
![]()
注意:/dev/sdb为共享磁盘,在node1安装数据库时已经格式化并将data目录置于其下,此时只需要挂载即可看到data目录
(4)切换到highgo登录系统,执行安装
注意:不作为系统服务安装(这样安装时不会有data目录选项出现)
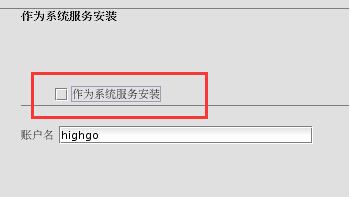
(5)注销highgo,切换回root,执行卸载挂载的目录
umount /install/hgdb6、HA配置
(1)node1、node2安装
yum -y install pacemaker corosync pcs(2)在一个节点配置文件,并将文件拷贝到另一节点(以node1为例)
密钥文件:
corosync-keygen
scp /etc/corosync/authkey root@node1:/etc/corosynccorosync.conf文件:
cd /etc/corosync
cp corosync.conf.example corosync.conf
vi corosync.conf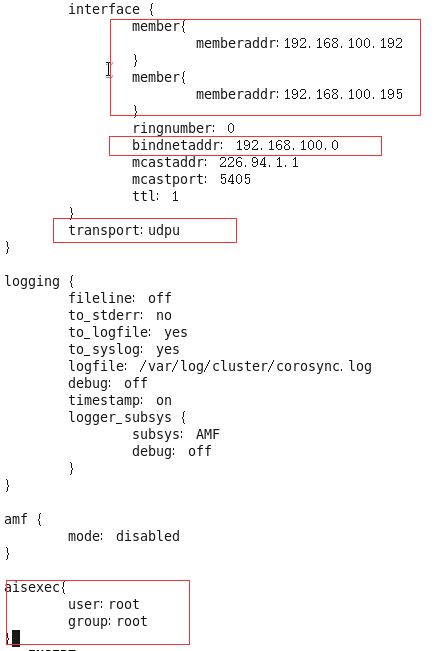
pacemaker服务启动脚本:
cd service.d
vi pcmd
corosync、pacemaker服务启停:
chkconfig corosync on
service corosync start
chkcofig pacemaker off
servicepacemaker stop7、集群资源配置
首先启动服务:service corosync start (node1、node2)查看集群状态:
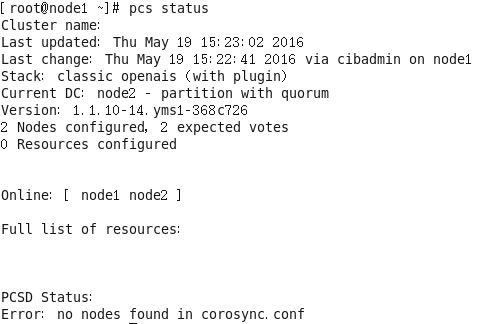
在一个节点上完成资源的配置即可
任何情况集群资源继续运行
pcs property set no-quorum-policy=ignore
禁用stonith
pcs property set stonith-enabled=false配置vip
pcs resource create vip ocf:heartbeat:IPaddr params ip="192.168.100.222" nic="eth0" cidr_netmask="24" op monitor interval=20s timeout=30s查看集群状态
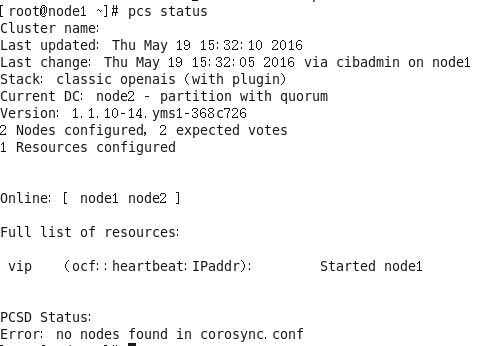
配置sdisk(共享存储)
pcs resource create sdisk ocf:heartbeat:Filesystem params device="/dev/sdb" directory="/install/hgdb " fstype="ext4" op start timeout=60s op stop timeout=60s op monitor interval=20s timeout=60s查看集群状态

配置数据库服务
pcs resource create dbserver ocf:heartbeat:pgsql params pghost=192.168.100.222 pgport=5866 pgdba=highgo pgctl=/home/highgo/hgdb/bin/pg_ctl start_opt="-D /install/hgdb/data" psql=/home/highgo/hgdb/bin/psql pgdata=/install/hgdb/data monitor_user=highgo monitor_password=highgo123 op start timeout=120s interval=120s op stop timeout=120s interval=120s op status timeout=60s interval=60s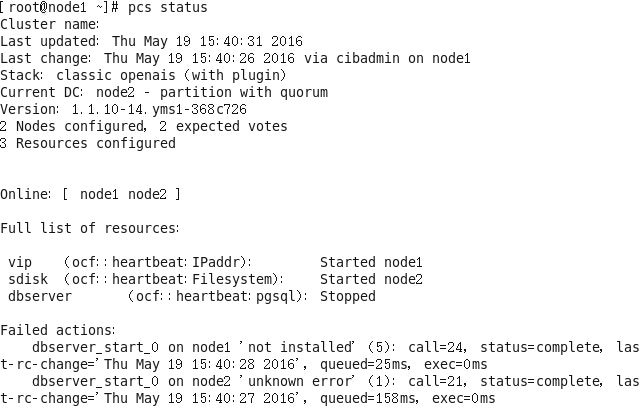
配置三个资源在一个组
pcs resource group add hgdb_group sdisk
pcs resource group add hgdb_group vip
pcs resource group add hgdb_group dbserver
配置资源在两节点中的优先级
pcs constraint location sdisk prefers node1=50
pcs constraint location sdisk prefers node2=40
pcs constraint location vip prefers node1=50
pcs constraint location vip prefers node2=40
pcs constraint location dbserver prefers node1=50
pcs constraint location dbserver prefers node2=40配置资源在节点中的启动顺序
pcs constraint order start vip then start sdisk then start dbserver配置psql文件(node1、node2)
vi /usr/lib/ocf/resource.d/heartbeat/pgsql![]()

需要确认的错误情况及解决方法:
node1重启corosync服务时,出现下面的状况,而node2可以重启

查看日志文件
![]()
切换到highgo用户重新启动停止了服务(之前安装完数据库停掉服务后有新修改postgresql.conf和pg_hba.conf文件,设置了远程访问),再重启corosync服务成功
查看集群状态

8、验证
(1)正常状态下
在node1用虚拟ip可访问数据库

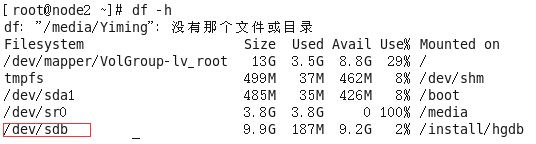
查看共享盘挂载情况

(2)模拟node1崩溃
此时在node2能用虚拟ip访问数据库

集群状态
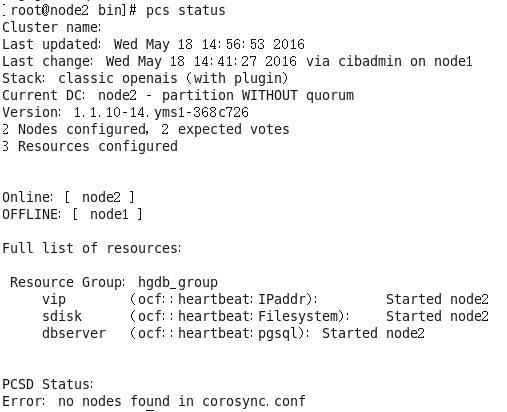
共享盘挂载
注意:
在配置前最好设置NetworkManager服务stop,更改system eth0为eth0因为配置vip时为eth0,怕会找不到设备,然后重启network服务