大数据分析技术研究报告(四)
作者:朱赛凡
四 大数据背景下数据分析挖掘技术介绍
1 Mahout与MLlib项目
数据分析挖掘主要涉及两个方面:一是数据预处理;二是数据挖掘。
在数据预处理方面,根据掌握资料来看,大型互联网公司主要以MapReduce、Storm等计算框架为主,这些平台可以较好解决大数据预处理面临并行计算和处理灵活性的问题。但是个人认为spark、tez等属于MapReduce升级版本,因此后面这些计算框架在这方面的应用会越来越广泛。
在数据挖掘算法执行方面,主要问题解决数据挖掘算法并行计算问题。早期在数据挖掘算法并行化方面项目主要是Mahout项目,该项目基于MAPREDUC 并行计算框架实现了推荐、分类等常用数据挖掘算法的并行化。
但由于数据挖掘算法存在以下两个方面特点导致基于MAPREDUCE框架来做数据数据挖掘算法执行引擎效率不高:一是机器学习算法一般比较复杂,通常需要多次迭代计算,而MapReduce框架的步步物化导致中间结果会反复的序列化和反序列化导致效率不高;二是数据与数据之间依赖特别多,在计算过程中机器与机器之间的通讯非常多,而MapReduce框架下Map与Reduce之间存在路障同步, 导致大量时间被消耗在同步等待上面,效率不高。
因此目前Mahout项目在2014年1月份在0.9版本发布后,该项目抛弃了MAPREDUCE框架,转而采用SPARK作为底层计算框架。

除Mahout项目外,SPARK自己采用SPARK专门针对机器学习领域开发MLlib项目。但是MLlib项目出现时间比较晚,因此在成熟度方面不如Mahout。
Mahout项目目前支持的数据挖掘算法如下:
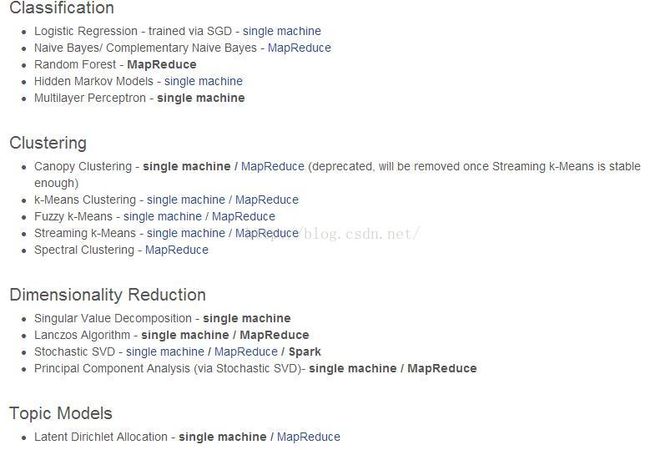
MLLib支持的数据挖掘算法包括:

2 图数据处理处理概述
在数据分析处理领域,随社交网络兴起,对图数据处理的需求越来越多。例如像Facebook和Twitter这样的社交网络,其数据天生就适合于图表示法。对图数据的处理和传统数据库处理一样,也可以分为两种类型的需求:
OLTP工作负载,能够快速低延迟访问小部分图数据。
OLAP工作负载,能够对图对象中的大部分数据进行批量分析与处理。
1) 图数据OLTP处理
(1) 图数据库分类
适合图书据OLTP处理的系统,主要是各种图数据库。从目前来看图数据库主要可以分为两类:
一是基于图存储模型的专用图数据库,如Neo4j、OrientDB、Infinite Graph等;
二是以通用KV存储系统或者关系数据库系统开发的图数据库,例如Titan系统(2013年推出)可以后端存储可以基于HBASE或者是Cassandra,Twitter公司的FlockDB图形数据库和facebook公司Tao图形数据库是基于mysql来进行开发。根据报道美国NSA就是利用2011年开源的Apache Accumulo(属于分布式KV数据库)来存储社会关系网络数据。
(2) 图数据查询
图数据查询其实就是”遍历”图(Traverse)。图数据库查询语言可以使用Gremlin、Cypher等查询语言来查询图。例如Neo4j就支持Cypher查询语言。
Cyper查询语言需要以一个节点来启动(START)查询,然后使用MATCH关键词以WHERE关键字过滤节点或者关系的属性,最后以RETRUN关键词来指定查询所返回的数据是节点、关系还是节点或者关系的属性字段。例如:
START barbara = node:nodeindex(name=”Barbara”);
MATCH(barbara)—(connected_node)
RETURNconnected_node.
(3) 两类图数据库区别
第一类与第二类图数据库区别在于以下几点:
查询功能方面
第一类图数据库可以以非常高效率方式支持复杂查询,既支持从指定起点开始,以任意深度来遍历图,并且还可以支持各种过滤。这样就可以很方便的执行各种图专用查询任务,例如“查找两个节点间所有路径或者最短路径”等。相反第二类数据库则只能支持较为简单查询,如FlockDB就只支持深度为1的关系遍历(个人认为也可以实现,只是效率不高)。
可扩展性方面
大部分第一种图形数据库都不支持分布,个人认为可能分布后这种复杂查询难以做到高效,因此可扩展性不好。而第二种由于只支持简单的图便历,一般通过采取按“边”切分的方法来进行分布存储,因此可扩展性较好。
2) 图数据OLAP处理
对图数据进行复杂分析,就需要分布式的批处理框架。例如大规模的PageRank计算。在这个领域出现并行图计算框架常见有Apache Giraph、Apache Hama、GraphLab、Pregel、GraphX等。
Pregel是Google根据BSP并行计算模型开发的图计算引擎,目前该系统没有开源。GraphX是Spark项目组基于Spark框架开发的图计算引擎;而GraphLab则是直接在MPI框架基础上开发的专用图计算引擎。
下面简单介绍几种主流并行图计算引擎。
3 并行图计算引擎
1) 基于BSP模型的Pregel引擎
简介
Pregel是Google公司开发的并行图计算引擎,主要用于实现各种机器学习算法。Pregel的输入是一个有向图,该有向图每一个顶点都有一个相应由String描述的顶点标识符。每一个顶点都有一个与之对应可修改用户自定义值。每一条有向边都和其源顶点关联,并且也拥有一个可修改的用户自定义值,并同时还记录了其目标顶点的标识符。
Pregel可以采用多种文件格式进行图的保存,比如可以用text文件、关系数据库、Bigtable。为了避免规定死一种特定文件格式,Pregel将从输入中解析出图结构的任务从图的计算过程中进行了分离。计算结果可以以任何一种格式输出并根据应用程序选择最适合的存储方式。Pregel library本身提供了很多常用文件格式的readers和writers,但是用户可以通过继承Reader和Writer类来定义他们自己的读写方式。
编写一个Pregel程序需要继承Pregel中已预定义好的一个基类——Vertex类。

用户覆写Vertex类的虚函数Compute(),该函数会在每一个超级步中对每一个顶点进行调用。预定义的Vertex类方法允许Compute()方法查询当前顶点及其边的信息,以及发送消息到其他的顶点。Compute()方法可以通过调用GetValue()方法来得到当前顶点的值,或者通过调用MutableValue()方法来修改当前顶点的值。同时还可以通过由出边的迭代器提供的方法来查看修改出边对应的值。
基于BSP的执行模型
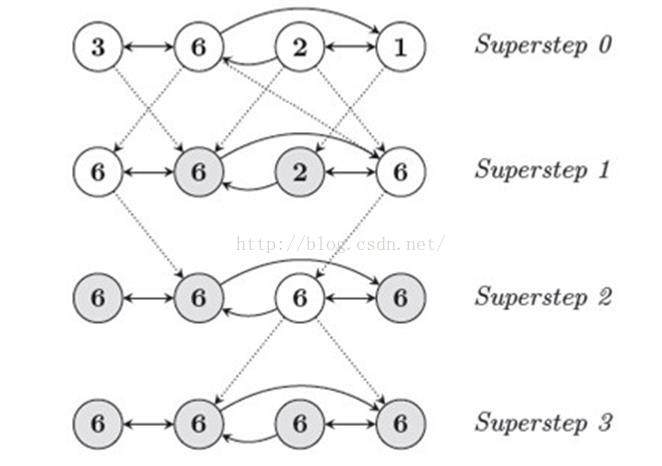
读取输入初始化该图,当图被初始化好后,运行一系列的超级步直到整个计算结束,这些超级步之间通过一些全局的同步点分隔,输出结果结束计算。
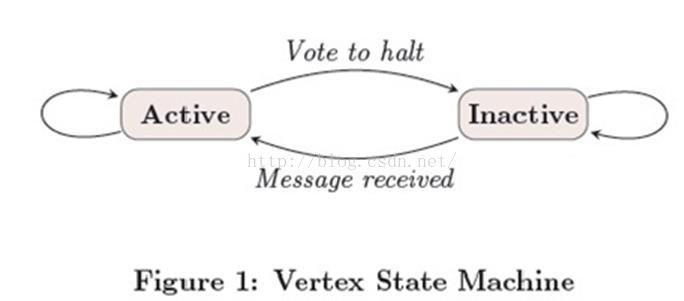
在每个超级步中,顶点的计算都是并行的,每个顶点执行相同的用于表达给定算法逻辑的用户自定义函数。每个顶点可以修改其自身及其出边的状态,接收前一个超级步(S-1)中发送给它的消息,并发送消息给其他顶点(这些消息将会在下一个超级步中被接收),甚至是修改整个图的拓扑结构。边,在这种计算模式中并不是核心对象,没有相应的计算运行在其上。
算法是否能够结束取决于是否所有的顶点都已经“vote”标识其自身已经达到“halt”状态了。在第0个超级步,所有顶点都处于active状态,所有的active顶点都会参与所有对应superstep中的计算。顶点通过将其自身的status设置成“halt”来表示它已经不再active。这就表示该顶点没有进一步的计算需要执行,除非被再次被外部触发,而Pregel框架将不会在接下来的superstep中执行该顶点,除非该顶点收到其它顶点传送的消息。如果顶点接收到消息被唤醒进入active状态,那么在随后的计算中该顶点必须显式的deactive。整个计算在所有顶点都达到“inactive”状态,并且没有message在传送的时候宣告结束。
2) graphLab
(1) 简介
GraphLab一套基于c++的开源图计算库,提供了在共享内存情况下的异步、动态和并行图计算的高层抽象API。该库采用MPI和TCPIP来实现进程间通讯,采用Pthreads实现进程内的多线程并发计算,支持从HDFS和标准文件系统中读取数据。GraphLab定义了多种用于存储图的文件格式,包括"tsv","snap", "adj" "bintsv4"。

(2) 与Pregel的不同
GraphLab不是采用BSP的严格执行模型,GraphLab的基于BSP的Pregel的典型的改进是在更好的“异步迭代计算”和“动态计算”。因此该框架计算效率比Pregel更好。
异步计算:很多重要的MLDM算法迭代更新一大批参数,图结构导致参数更新依赖其它的参数。同步系统会以上一次更新的参数基础上一次更新所有的参数(BSP模型中超级步之间市全局路障同步),而异步系统则以最近的参数作为输入来更新参数。异步迭代更新可以极大加 快MLDM算法的计算速度。因为如果采用同步计算,则存在木桶效应,整体速度取决于最慢的那台机器。在大规模云计算环境下,负载不均衡、网络不均衡、硬件差异和多租户等会导致不同 机器之间的速度存在差异。另外由于图分割不均衡,以及计算复杂性等导致各个节点计算量也不均衡。
动态计算:很多MLDM算法的迭代计算收敛都不对称,例如在参数优化是,通常很多参数在很少几次迭代中就会快速收敛,而剩下少数参数则即使经过多次迭代也会收敛很慢。因此如果我们等同更新所有的参数,则会浪费大量的时间在重复计算那些已近收敛的参数上。最近的一些计算框架部分支持动态计算,例如Pregel可以通过让某些节点跳过一些超级步来部分支持动态计算。
(3) GraphLab的计算模型
graphLab包括三个部分:数据图、更新函数、同步操作。数据图表达用户可修改 的程序状态,存储可变的用户自定义数据和计算之间依赖。更新函数通过一个scope的数据变换来表达用户对数据图的计算和操作。同步操作并发维护全局汇总。
一个点的scope代表存储在这个点上的数据 和所有与这个点相邻的点和边上的所有数据。update f (v ,s(v) ) ---> (s(v) , 边集合) 。经过一个更新函数后,新计算出 的s(v) 会被写回图,并返回一个定点集合,针对该集合的每个点再执行 f(u ,s(u))

为了更高效的并行执行,GraphLab容许GraphLab框架动态的选择执行顺序,即RemoveNext(T)的返回值。因为很多MLDM算法需要执行优先级别,因此也可以指定点的优先级,这样GraphLab会综合考虑优先级以及网络情况来调度。
(3) GraphLab的并行计算
根据领域知识,将图分割为K份,K值远大于机器数量。每个分区被称为atom, 以一个文件形式存储类似HDFS的分布式文件系统上。Atom中存储的是增加点和变的操作记录,可以通过回放的方式来重构图。
采取把点着色的方法,先保证每个点和相邻点之间的颜色都不相同。通过一个颜色一个颜色的并发执行,来实现边一致性。把这种成为颜色步,与BSP的超步模型相对应。该引擎保证在执行下一个颜色步之前,所有的修改都被传递,实现颜色步之间的路障同步。
由Master根据atom索引来计算atom的位置,并负责机器与atom之间的分配关系。然后每个机器读取atom文件来加载图。每个机器上有一个调度器负责调度属于自己的子图的点的计算。调度器负责把每个需要执行update 函数之前所需要的数据和锁准备好后,放入一个流水处理队列中,再由一个worker线程池来执行,通过一个分布式算法来确定所有机器上的调度器中的T为空,也就是整个计算结束。
3)graphX
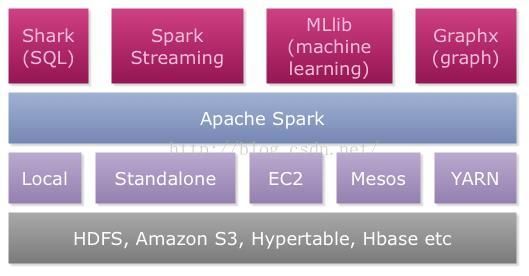
基于SPARK图形计算引擎,GraphX提供的API可以很方便的表达各种针对的转换、过滤和查询操作,但是GraphX不能直接实现迭代并行图计算算法,但是可以基于这些API用来实现各种并行图计算算法。在GraphX论文中描述了利用GraphX来实现Pregel、PowerGraph的方法。
GraphX的优势是可以很方便的与shark等进行集成,例如直接对shark查询后的结果进行图计算。

4) 总结
(1)上述计算引擎都可以以灵活方式来存储图,基本上都可以以文件方式来存储图数据,实现计算引擎与存储分离。
(2)图计算引擎都根据MDML算法特点采用专用计算模型,以提高效率。
(3) 所有图计算引擎在计算时,基本都是需要把数据都加载到内存中。(来自preglel论文:当前整个的计算状态都是驻留在内存中的。我们已经开始将一些数据存到本地磁盘,同时我们会继续在这个方向进行深入的研究,希望可以支持规模太大以至于内存无法完全存下的情况。