关于Python、R、VBA、SAS的生成批量变量名与动态变量引用的问题
1. 什么是动态变量?
i=1
x&i=3x&i就是动态变量。
如果x&i按照我们所想的一样,那么上述程序的结果应该是得到了一个变量x1=3
上述程序在VBA中可直接实现。
动态变量可以用于批量变量迭代,这是动态变量最重要的意义。如:
for(i in 1:100){
x&i=i
}这是时候我们快速地生成了x1:x100这100个变量,并进行了赋值。如果x&i的作用按照我们想的一样实现了的话,那么上述程序应该生成了x1=1,x2=x,x3=3...x100=100
所以问题的核心就是x&i的实现,核心的核心就是&的含义。
在SAS中,我记得连接需要加一个英文句号:
x&.i=3在VBA中,可直接用
x&i=3然而在R与Python要复杂得多。
2. Python动态变量(dynamic variable)
有一篇写的很好的博客,参见Python动态变量名定义与调用
字典方法
字典方法是Stack Overflow社区最推崇的方法,但是它不能适用于对复杂变量进行进一步的操作。它不能解决字典的value对变量名的引用。
d={}
for i in range(5):
d['x'+str(i)]=i

那么现在我们把问题复杂化一点,假设我已经有了x1-x4这么几个变量,他们都是列表。我想只留下非0的值,那么理想的伪代码如下:
x1=np.array([1,2,3,0])
x2=np.array([5,6,0,8])
x3=np.array([3,5,0,0])
x4=np.array([3,45,2,1])
for i in range(1,5):
xi=xi[xi!=0]那么字典方法应该怎么做呢?首先应该将变量全部写到字典里面去,,,然后发现首先这一步就没法做,它不能解决字典的value对变量名的引用,就是在值里面无法引用动态变量。
你打算这么做吗?
d['x'+str(i)]='x'+str(i)可是右边只返回了一个字符串,不指代xi。
命名空间法
Python中有三个函数是变量字典:locals(),globals, vars()。
他们之间的区别参见:What's the difference between globals(), locals(), and vars()?
一般使用locals,他会返回当前存在的变量,返回格式是一个字典。也就是说,如果我们先定义x1=2,那么在locals字典中就已经记录了下来,使用
loacals()['x1']就可以引用变量x1了,这就是一个普通字典格式,dict['key']=value。
好我们继续上面的问题,现在就可以很方便地解决了
x1=np.array([1,2,3,0])
x2=np.array([5,6,0,8])
x3=np.array([3,5,0,0])
x4=np.array([3,45,2,1])
for i in range(1,5):
locals()['x'+str(i)]=locals()['x'+str(i)][locals()['x'+str(i)]!=0]
print(x1,x2,x3,x4)
[1 2 3] [5 6 8] [3 5] [ 3 45 2 1]exec
在Python中同样有三个函数可以编译执行字符串语句:exec,eval,compile,详细地讲解参见
python中的exec()、eval()以及complie()
What's the difference between eval, exec, and compile?
- exec,动态执行python代码,返回值永远为None,能够同时解析字符串和python语句,这使得exec能够用于动态变量生成
- eval,只支持单个表达式,不支持赋值,返回单个表达式执行的结果。
eval('1+2')#返回3
exec('1+2')#无返回值exec可同时解析字符串和python语句,但exec的输入必须全是字符串格式。下面的语句定义了x1=2:
exec('x'+str(1)+'='+str(2))#全是字符串,以+连接虽然stack overflow上面最推崇字典法,而认为命名空间法不是一个很好的办法,因为他改变了全局变量,比如如果你之前有某个变量定义为x23,你在动态变量里面改变了x23的赋值,你可能没有注意到这一点,这可能会造成意料之外的错误。但是我认为,命名空间法非常的便捷,并且很多复杂的数据结构的时候,命名空间法师唯一可行的方法。
3. R中动态变量的引用
我最爱的R在这里确实最复杂的,&在R中是逻辑运算“和”,并不表示连接。
一般有五种方法能够实现变量批量命名:
- 对list使用setName
my_power_list=setNames( as.list( 1:5), paste0("x", 1:5) )效果是这样的:
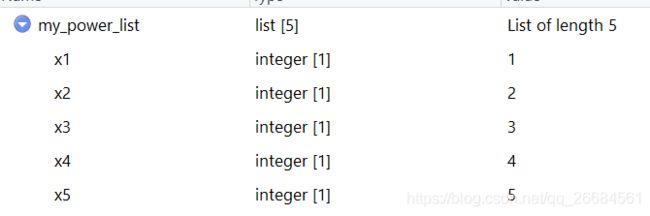
这实际上用了一个列名重命名技术而已。而且只在列表中,效果很有限。
- list2env转换全局变量
x =as.list(rnorm(100))
names(x) = paste("a", 1:100, sep = "")#列表重命名
list2env(x , envir = .GlobalEnv)#将列表变量转换为全局变量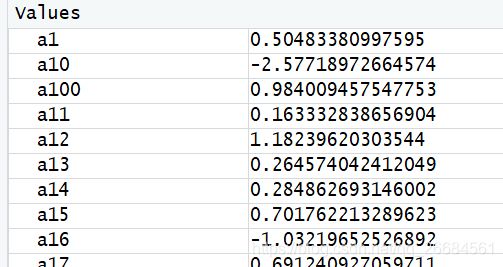
- eval(paste)解析法
vals <- rnorm(3)
n <- length(vals)
lhs <- paste("a", 1:n, sep="")
rhs <- paste("vals[",1:n,"]", sep="")
eq <- paste(paste(lhs, rhs, sep="<-"), collapse=";")
eval(parse(text=eq))其本质是生成了一段文本,然后用parse去解析,在用eval进行符号运算。
上面的三种并不是很常用,我比较喜欢下面两种:
- assign(paste)
assign(paste0("x", 1:100), 1:100)这一次性生成了100个变量:xi=i。
上面已经讲到,动态变量最重要的意义是能够利用迭代对变量进行批量运算。很遗憾,仅仅凭借上面的函数是无法实现迭代的。我们需要另外一个函数:get()。get函数和assign是一对,assign给字符赋值,get获得字符的值。
现在看一个实例。假定有一个数据集d是100行30列的,也就是说有30个变量,现在用bootstrap收集它的系数。进行100次随机抽样,每一次抽样用第一列数据对其他列进行线性回归,这样,每一次回归都会得到一次beta0~beta29,一共30个beta(还有个截距项beta0)。进行100次抽样后再回归就得到了100个不同的beta0,把这些beta0全部追加到变量beta0中。然后进行统计量的估计。也就是说,最后我们的结果是:。
d=matrix(rnorm(100*30),100,30)
d=data.frame(d)
cs=paste0('beta',1:30)
for(k in 1:30){
assign(cs[k],c())
}#要追加必给初值
for(j in 1:100){
i=sample(1:100,80,replace = F)
d1=d[i,]
model=lm(X1~.,data=d1)
for(k in 1:30){
assign(cs[k],c(get(cs[k]),coef(model)[k]))
}
}
如果不进行动态变量引用,那么我们程序可能是这样滴:
d=matrix(rnorm(100*30),100,30)
d=data.frame(d)
beta0=c()
beta1=c()
beta2=c()
beta3=c()
beta4=c()
beta5=c()
beta6=c()
beta7=c()
...
beta30=c()
for(j in 1:100){
i=sample(1:100,80,replace = F)
d1=d[i,]
model=lm(X1~.,data=d1)
beta0=c(beta0,coef(model)[1])
beta1=c(beta1,coef(model)[2])
beta2=c(beta2,coef(model)[3])
beta3=c(beta3,coef(model)[4])
beta4=c(beta4,coef(model)[5])
beta5=c(beta5,coef(model)[6])
beta6=c(beta6,coef(model)[7])
beta7=c(beta7,coef(model)[8])
...
beta30=...
}现在你知道了动态引用的重要意义了吧,没错,几十倍地精简代码!对变量进行批量迭代!
再看最后一种方法。
- globalen进行动态引用
这种方法其实是最符合x&i定义的一种方法。
e=globalenv()
name=paste0('x',1:5)
e[[name[1]]]=3似乎有点像Python的locals,但是注意:
- 必须使用一个变量指代globalen(),即,而Python中可以直接使用locals()
- 必须有一个变量,里面包含了要全局化的变量名,这和assign(paste)也一样,也需要有全部的变量名
- e后面必须是双括号
使用这种方法进行bootstrap:
e=globalenv()
cs=paste0('beta',1:30)
for(k in 1:30){
assign(cs[k],c())
}
for(j in 1:100){
i=sample(1:100,80,replace = F)
d1=d[i,]
model=lm(X1~.,data=d1)
for(k in 1:30){
e[[cs[k]]]=c(e[[cs[k]]],coef(model)[k])
}
}