CRF(条件随机场)知识整理
目录
- CRF(条件随机场)知识整理
- 一、马尔科夫网络
- 1.1 无向图和团
- 1.2 马尔科夫网络的概念
- 1.3 吉布斯分布(Gibbs distribution)
- 1.4 Hammersley-Clifford定理
- 二、条件随机场的概念
- 2.1 一般定义
- 2.2 线性链条件随机场
- 2.3 特征函数
- 三、前向后向算法
- 3.1 前向向量
- 3.2 后向变量
- 3.3 归一化因子的计算
- 四、参数估计
- 4.1 参数梯度
- 4.2 优化算法
- 五、可用的工具
CRF(条件随机场)知识整理
HMM建模序列学习问题时,由于引入了状态序列的马尔可夫性假设,限制了上下文特征的提取,相比之下,条件随机场(CRF)模型可以提供更多的上下文信息,且相比最大熵模型(MEM),它也有效规避了标记偏置问题(具体请查看最大熵模型相关资料)。
一、马尔科夫网络
在马尔科夫链中,随机变量在时间上顺序产生,构成一个随机过程,那么,能不能将马尔科夫链的概念扩展到空间上呢?假设存在一组随机变量,它们之间存在着一些边连接,是否能假设它们所满足的马尔科夫性呢?
1.1 无向图和团
我们先简要回顾无向图的一些概念,在图论中,图由节点(node)集合和边(edge)集合构成,记作 G = ( V , E ) G=(V,E) G=(V,E), V = { x 1 , … , x n } V=\{x_1,\dots,x_n\} V={x1,…,xn}表示顶点集合, E = { ( x i , x j ) ∣ x i → x j } E=\{(x_i,x_j)|x_i \rightarrow x_j\} E={(xi,xj)∣xi→xj}为边集合, x i → x j x_i \rightarrow x_j xi→xj表示节点 x i x_i xi能到达节点 x j x_j xj,在无向图中有 x i → x j x_i \rightarrow x_j xi→xj等价于 x j → x i x_j \rightarrow x_i xj→xi。
完全图指任意节点之间均存在一条边连接的无向图。一个无向图的子图指图节点集合和边集合的子集。无向图的完全子图称为一个团(clique)。
对于团,我们可以定义其节点上的非负函数,称为势函数。引入符号,记图 C = ( V 1 , E 1 ) C=(V_1,E_1) C=(V1,E1)为一个团,其中 V 1 = { x 1 , … , x n } V_1=\{x_1,\dots,x_n\} V1={x1,…,xn}为节点变量,定义非负函数 ϕ c ( x 1 , … , x n ) \phi_c(x_1,\dots,x_n) ϕc(x1,…,xn),它称为团 C C C的势函数或势能函数,简记作 ϕ c ( x c ) \phi_c(\bold{x}_c) ϕc(xc)。
到这里,可能会有些疑惑,势函数究竟具有怎样的物理意义呢?我个人理解,势函数描述了网络处于某种状态时的某一指标,可能是能量,如果将网络节点视为随机变量,并对势函数做归一化处理,也可将其视作概率。
1.2 马尔科夫网络的概念
现在,我们来回答本部分一开始提出的问题,在马尔科夫链中,我们假设的马尔科夫性认为当前时刻的随机变量分布仅与上一时刻的随机变量相关,如果给定一个无环网络,每个节点均代表一个随机变量,我们是否可假设该节点的概率分布仅与其邻居节点相关呢?这样,我们就得到了马尔科夫网络的基本定义,给定一个由随机变量构成的网络 G = ( V , E ) G=(V,E) G=(V,E),节点 x i ∈ V x_i\in V xi∈V的条件分布满足:
p ( x i ∣ G ∖ { x i } ) = p ( x i ∣ N i ) p(x_i|G \setminus \{x_i \})=p(x_i|N_i) p(xi∣G∖{xi})=p(xi∣Ni)
这里, N i N_i Ni表示节点 x i x_i xi的邻居节点集。那么,马尔科夫网络这样的性质带来了怎样的好处和便利呢?我们先来看一种新颖的分布函数。
1.3 吉布斯分布(Gibbs distribution)
上面提到过,团的势函数经过归一化后可以视为一种概率分布,现在我们来具体审视这种观点。同样,我们给定一个无环的随机网络(节点是随机变量) G G G,它可以分解为一些团(事实上都可以做到),团集合记作 C = { c 1 , … , c m } C=\{ c_1, \dots,c_m \} C={c1,…,cm}。在其上定义势函数 { ϕ c 1 ( x c 1 ) , … , ϕ c m ( x c m ) } \{ \phi_{c_1}(\bold{x}_{c_1}),\dots,\phi_{c_m}(\bold{x}_{c_m}) \} {ϕc1(xc1),…,ϕcm(xcm)},则函数
Φ ( G ) = 1 Z ϕ ∏ i = 1 m ϕ c i ( x c i ) \Phi(G)=\frac{1}{\bold{Z}_{\phi}}\prod_{i=1}^m \phi_{c_i}(\bold{x}_{c_i}) Φ(G)=Zϕ1i=1∏mϕci(xci)
称为吉布斯分布。
这里,记 x = x c 1 ∪ ⋯ ∪ x c m \bold{x}=\bold{x}_{c_1}\cup\dots\cup\bold{x}_{c_m} x=xc1∪⋯∪xcm,
Z ϕ = ∑ x ∏ i = 1 m ϕ c i ( x c i ) \bold{Z}_\phi = \sum_{\bold{x}}\prod_{i=1}^m \phi_{c_i}(\bold{x}_{c_i}) Zϕ=x∑i=1∏mϕci(xci)
为归一化因子。
1.4 Hammersley-Clifford定理
下面我们来探究马尔科夫网络和吉布斯分布之间的关系。事实上,正如转移矩阵和初始分布完全描述了马尔科夫链的概率信息,吉布斯分布描述了马尔科夫网络的概率信息,我们自然要问,是不是任意给定的马尔科夫网络都能找到一个吉布斯分布与之对应?如果一个网络存在吉布斯分布,那么这个网络是否是马尔科夫网络呢?答案是肯定的,Hammersley-Clifford定理证明了马尔科夫网络和吉布斯分布之间的等价关系,该定理的证明过于复杂,请参考HC定理证明。
二、条件随机场的概念
上述马尔科夫网络又称作马尔科夫随机场。它考虑的是联合分布,而在序列学习问题中,我们通常都是给定观测序列,求状态序列的分布,因而,能否对条件分布也做类似假设呢?
2.1 一般定义
如果对条件分布也做类似假设,我们便得到了条件随机场的基本概念。与马尔科夫随机场不同的是,在条件随机场中我们考虑两组随机变量集,记为 Y Y Y和 X X X,且 Y Y Y构成一个随机网络 G G G,我们对条件分布 p ( Y ∣ X ) p(Y|X) p(Y∣X)做如下假设,
p ( Y v ∣ X , G ∖ Y v ) = p ( Y v ∣ X , Y w ∈ N v ) p(Y_v|X,G \setminus Y_v)=p(Y_v|X,Y_w\in N_v) p(Yv∣X,G∖Yv)=p(Yv∣X,Yw∈Nv)
这一假设类似于马尔科夫随机场中的假设,不同的是给定了另一组随机变量 X X X,我们大可不必理会它的作用,将其看做具有确定的状态即可。
2.2 线性链条件随机场
在NLP中,我们依然习惯于构建链式的模型,这一模型更适合于序列学习的情境,且具备更少的参数。基本假设如下
p ( Y i ∣ X , Y ∖ Y i ) = p ( Y i ∣ X , Y i − 1 , Y i + 1 ) p(Y_i|X, Y\setminus Y_i)=p(Y_i|X,Y_{i-1},Y_{i+1}) p(Yi∣X,Y∖Yi)=p(Yi∣X,Yi−1,Yi+1)
在线性链条件随机场中,我们可以考虑更加简单的团和势函数形式,最简单的团有 Y i − 1 Y_{i-1} Yi−1和 Y i Y_i Yi构成,我们定义的势函数也具备更加简单的形式,即 ϕ ( Y i − 1 , Y i , X ) \phi(Y_{i-1},Y_i,X) ϕ(Yi−1,Yi,X),注意这里由于是关于 X X X的条件分布,所以所有势函数都是关于整个序列 X X X的函数。条件随机场的结构图如下,
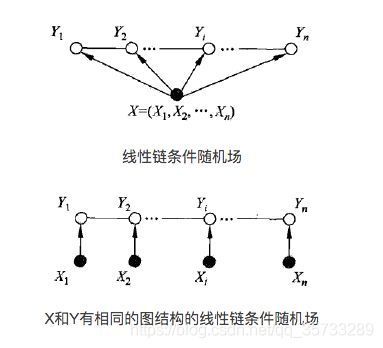
接下来,我们引入条件随机场(在接下来的部分,我们使用术语“条件随机场”时默认为“线性链条件随机场”)的吉布斯分布,这一过程称为参数化,我们重新规范以下符号以便于和序列学习中的符号一致,设标记序列为 s = { s 1 , … , s T } \bold{s}=\{s_1,\dots,s_T\} s={s1,…,sT},其中 s t ∈ S s_t \in S st∈S,观测序列为 o = { o 1 , … , o T } \bold{o}=\{o_1,\dots,o_T \} o={o1,…,oT},其中 o t ∈ W = { w i } ∣ i = 1 N o_t\in W=\{ w_i\}|_{i=1}^N ot∈W={wi}∣i=1N,则吉布斯分布为,
p ( s ∣ o ) = 1 Z o exp [ ∑ t = 1 T ∑ k λ k f k ( s t − 1 , s t , o , t ) ] p(\bold{s}|\bold{o})=\frac{1}{Z_o}\exp \left[ \sum_{t=1}^T\sum_{k} \lambda_kf_k(s_{t-1},s_t,\bold{o},t) \right] p(s∣o)=Zo1exp[t=1∑Tk∑λkfk(st−1,st,o,t)]
这里, Z o = ∑ s ∈ S T exp [ ∑ t = 1 T ∑ k λ k f k ( s t − 1 , s t , o , t ) ] Z_o=\sum_{\bold{s}\in S^T}\exp \left[ \sum_{t=1}^T\sum_{k} \lambda_kf_k(s_{t-1},s_t,\bold{o},t) \right] Zo=s∈ST∑exp[t=1∑Tk∑λkfk(st−1,st,o,t)]为归一化因子, f k ( s t − 1 , s t , o , t ) f_k(s_{t-1},s_t,\bold{o},t) fk(st−1,st,o,t)称为特征函数, λ k \lambda_k λk是权重参数,它是定义势函数的关键所在,接下来,我们探讨一下特征函数的具体含义。
2.3 特征函数
要想理解特征函数,我们需要从标记序列和观测序列本身的含义考虑,也就是说在不同的模型应用场景下,特征函数的定义有着不同的方法,我们这里拿命名实体识别(NER)任务来举例,这一任务中,观测序列为单词序列,标记序列为当前词汇所属的命名实体类别(例如地区、人名、非实体等)。通常我们将特征函数定义为二值函数,简单来说,就是当 s t − 1 , s t s_{t-1},s_t st−1,st满足某一条件且观测序列 o \bold{o} o满足某一条件时,取1,否则取0。根据标记序列是否存在上下文联系,我们将特征函数又可以分类为两类,一类是Unigram特征,该特征和观测序列以及当前的状态 s t s_t st相关;另一类是Bigram特征,该特征和观测序列以及 s t − 1 s_{t-1} st−1和 s t s_t st均相关。即
∑ k λ k f k ( s t − 1 , s t , o , t ) = ∑ k μ k l k ( s t − 1 , s t , o , t ) + v k m k ( s t , o , t ) \sum_{k} \lambda_kf_k(s_{t-1},s_t,\bold{o},t) =\sum_{k}\mu_kl_k(s_{t-1},s_t,\bold{o},t)+v_km_k(s_t,\bold{o},t) k∑λkfk(st−1,st,o,t)=k∑μklk(st−1,st,o,t)+vkmk(st,o,t)
举一个具体的例子,有如下一个简单的标记序列和观测序列,
“Confidence in the pound is widely expected”
“B O B I O O O”
第一行为观测序列,第二行为标记序列,我们可以定义如下的一个特征函数,
v ( s t , o , t ) = 1 v(s_{t},\bold{o},t)=1 v(st,o,t)=1,若 s t = s_t= st=’B’且 o t = o_t= ot=’Confidence’,否则为0。类似的,我们可以对词典中的每个单词都定义一个类似的特征函数。因此,给定一个语料库,我们无法给出所有特征函数的具体形式,但我们可以给出特征模板(具体请查看CRF++框架的使用教程)并且增加一个特征筛选程序。
显然,在定义了特征函数后,我们下一步需要做的就是推导CRF的训练过程。
三、前向后向算法
同样,条件随机场也面临组合爆炸的问题,但幸运的是条件随机场与隐马尔科夫模型之间存在结构相似性,于是我们考虑是否可以类似地定义前向变量和后向变量,用动态规划的方法来简化计算
3.1 前向向量
与HMM理论不同的是,在CRF中我们参数化了概率分布,推导的基本技术是吉布斯分布和团分解,在分布函数里,归一化因子 Z o Z_o Zo看起来似乎非常难以处理,由于它是一个常数,我们可以暂时不考虑它。
值得注意的是,在CRF理论中同样存在着状态(标签)的转移,因而我们是否可以类似地定义一个状态转移矩阵呢?答案是显然的,引入下面的符号
M t ( y i , y j ∣ o ) = exp [ ∑ k λ k f k ( s t − 1 = y i , s t = y j , o , t ) ] M_t(y_i,y_j|\bold{o})=\exp\left[ \sum_k \lambda_k f_k(s_{t-1}=y_i,s_t=y_j,\bold{o},t)\right] Mt(yi,yj∣o)=exp[k∑λkfk(st−1=yi,st=yj,o,t)]
它代表了非归一化的转移概率,简记为 M t ( o ) M_t(\bold{o}) Mt(o)。当然,为了书写方便,这里我们将两种特征函数合并。为了规范化,我们在原序列 s \bold{s} s中引入两个额外标记 s 0 s_0 s0和 s T + 1 s_{T+1} sT+1,其状态索引分别为start和stop。我们定义一个向量序列 α t ( o ) ∈ R N \alpha_t(\bold{o})\in \mathbb{R}^N αt(o)∈RN, N N N为标签数,当 t = 0 t=0 t=0时,其第 i i i个元素 α 0 ( i ∣ o ) \alpha_0(i|\bold{o}) α0(i∣o)满足满足
α 0 ( i ∣ o ) = { 1 , i = s t a r t 0 , o t h e r \alpha_0(i|\bold{o})=\left \{ \begin{aligned} &1,\quad i=start \\ &0, \quad other \end{aligned} \right. α0(i∣o)={1,i=start0,other
且 α t ( o ) \alpha_t(\bold{o}) αt(o)满足如下的迭代式,
α t ( o ) = α t − 1 ( o ) M t ( o ) \alpha_t(\bold{o})=\alpha_{t-1}(\bold{o})M_t(\bold{o}) αt(o)=αt−1(o)Mt(o)
稍加分析可知, α t ( j ∣ o ) \alpha_t(j|\bold{o}) αt(j∣o)的概率意义是非规范化的 ∑ s 1 , … , s t − 1 p ( s 1 , … , s t − 1 , s t = y j ∣ o ) \sum_{s_1,\dots,s_{t-1}}p(s_1,\dots,s_{t-1},s_t=y_j|\bold{o}) ∑s1,…,st−1p(s1,…,st−1,st=yj∣o)。事实上,上面的递推式之所以成立,其本质是由吉布斯分布的形式决定的。上述向量 α t ( o ) \alpha_t(\bold{o}) αt(o)称为前向向量。
3.2 后向变量
类似地,我们定义后向向量 β t ( o ) \beta_t(\bold{o}) βt(o),其初始化为
β T + 1 ( i ∣ o ) = { 1 , i = e n d 0 , o t h e r \beta_{T+1}(i|\bold{o})=\left \{ \begin{aligned} &1,\quad i=end \\ &0, \quad other \end{aligned} \right. βT+1(i∣o)={1,i=end0,other
它的递推式为
β t ( o ) T = M t + 1 ( o ) β t + 1 ( o ) \beta_t(\bold{o})^T=M_{t+1}(\bold{o})\beta_{t+1}(\bold{o}) βt(o)T=Mt+1(o)βt+1(o)
稍加分析,其概率意义为 ∑ s t + 1 , … , s T + 1 p ( s t = y j , s t + 1 , … , s T + 1 ∣ o ) \sum_{s_{t+1},\dots,s_{T+1}}p(s_t=y_j,s_{t+1},\dots,s_{T+1}|\bold{o}) ∑st+1,…,sT+1p(st=yj,st+1,…,sT+1∣o)。
3.3 归一化因子的计算
接下来,我们考虑归一化因子 Z o Z_o Zo的计算,根据前向向量的定义,有
α T + 1 ( o ) = α 0 ( o ) M 1 ( o ) … M T + 1 ( o ) \alpha_{T+1}(\bold{o})=\alpha_0(\bold{o})M_1(\bold{o})\dots M_{T+1}(\bold{o}) αT+1(o)=α0(o)M1(o)…MT+1(o)
且 α T + 1 ( o ) \alpha_{T+1}(\bold{o}) αT+1(o)具有概率意义 ∑ s ∈ S T p ( s , s T + 1 = y j ∣ o ) \sum_{\bold{s}\in S^T}p(\bold{s},s_{T+1}=y_j|\bold{o}) ∑s∈STp(s,sT+1=yj∣o),而我们又知道 s T + 1 = y s t o p s_{T+1}=y_{stop} sT+1=ystop,因而 α T + 1 ( o ) \alpha_{T+1}(\bold{o}) αT+1(o)的第 s t o p stop stop个元素应当被归一化为1,也就是说矩阵
M 1 ( o ) … M T + 1 ( o ) M_1(\bold{o})\dots M_{T+1}(\bold{o}) M1(o)…MT+1(o)
的 ( s t a r t , s t o p ) (start, stop) (start,stop)处的元素为归一化因子,记作
Z o = ( M 1 ( o ) … M T + 1 ( o ) ) ( s t a r t , s t o p ) Z_o = \left( M_1(\bold{o})\dots M_{T+1}(\bold{o}) \right)_{(start, stop)} Zo=(M1(o)…MT+1(o))(start,stop)
有了归一化因子的计算,我们能够推得下面这个重要结论,
p ( s t = y i ∣ o ) = ∑ s 1 … s t − 1 , s t + 1 , … , s T p ( s ∣ o ) = α t ( i ∣ o ) β t ( i ∣ o ) Z o \begin{aligned} p(s_t=y_i|\bold{o})&=\sum_{s_1\dots s_{t-1},s_{t+1},\dots,s_T}p(\bold{s}|\bold{o}) &= \frac{\alpha_t(i|\bold{o})\beta_t(i|\bold{o})}{Z_o} \end{aligned} p(st=yi∣o)=s1…st−1,st+1,…,sT∑p(s∣o)=Zoαt(i∣o)βt(i∣o)
至此,训练模型前的一些准备工作已经完毕。
四、参数估计
接下来我们推导参数估计的方法,与HMM不同的是,CRF的训练是有监督的,即同时给定了训练集 { ( s , o ) } \{ (\bold{s},\bold{o})\} {(s,o)}。
4.1 参数梯度
我们首先构造如下的对数似然函数,其中参数为 Λ = ( λ 1 , … , λ k , … ) \Lambda=(\lambda_1,\dots,\lambda_k,\dots) Λ=(λ1,…,λk,…)
L ( Λ ) = log p ( s ∣ o ) = ∑ t = 1 T ∑ k λ k f k ( s t − 1 , s t , o , t ) − log ( Z o ) \begin{aligned} L(\Lambda)&=\log p(\bold{s|o})\\ &=\sum_{t=1}^T\sum_{k}\lambda_kf_k(s_{t-1},s_t,\bold{o},t)-\log(Z_o) \end{aligned} L(Λ)=logp(s∣o)=t=1∑Tk∑λkfk(st−1,st,o,t)−log(Zo)
为了减少过拟合,我们这里引入 l 2 l_2 l2正则项,当然,也可以引入 l 1 l_1 l1正则。于是,有
L ( Λ ) = ∑ t = 1 T ∑ k λ k f k ( s t − 1 , s t , o , t ) − log ( Z o ) − ∑ k λ k 2 2 σ 2 L(\Lambda)=\sum_{t=1}^T\sum_{k}\lambda_kf_k(s_{t-1},s_t,\bold{o},t)-\log(Z_o)-\sum_{k}\frac{\lambda_k^2}{2\sigma^2} L(Λ)=t=1∑Tk∑λkfk(st−1,st,o,t)−log(Zo)−k∑2σ2λk2
现在,我们求偏导数,得
∂ L ∂ λ k = ∑ t = 1 T f k ( s t − 1 , s t , o , t ) − ∑ t = 1 T p ( s ∣ o ) f k ( s t − 1 , s t , o , t ) − λ k σ 2 \frac{\partial L}{\partial \lambda_k} =\sum_{t=1}^Tf_k(s_{t-1},s_t,\bold{o},t)-\sum_{t=1}^Tp(\bold{s}|\bold{o})f_k(s_{t-1},s_t,\bold{o},t)-\frac{\lambda_k}{\sigma^2} ∂λk∂L=t=1∑Tfk(st−1,st,o,t)−t=1∑Tp(s∣o)fk(st−1,st,o,t)−σ2λk
引入期望的记号,上式第一项为
E [ f k ] = ∑ t = 1 T f k ( s t − 1 , s t , o , t ) E[f_k]=\sum_{t=1}^Tf_k(s_{t-1},s_t,\bold{o},t) E[fk]=t=1∑Tfk(st−1,st,o,t)
第二项为,
E ~ s ∣ o [ f k ] = ∑ t = 1 T p ( s ∣ o ) f k ( s t − 1 , s t , o , t ) \widetilde E_{\bold{s|o}}[f_k]=\sum_{t=1}^Tp(\bold{s}|\bold{o})f_k(s_{t-1},s_t,\bold{o},t) E s∣o[fk]=t=1∑Tp(s∣o)fk(st−1,st,o,t)
因此,梯度可以简记为
∂ L ∂ λ k = E [ f k ] − E ~ s ∣ o [ f k ] − ∑ k λ k σ 2 \frac{\partial L}{\partial \lambda_k} =E[f_k]-\widetilde E_{\bold{s|o}}[f_k]-\sum_k\frac{\lambda_k}{\sigma^2} ∂λk∂L=E[fk]−E s∣o[fk]−k∑σ2λk
由于 p ( s ∣ o ) p(\bold{s|o}) p(s∣o)的存在,上面的梯度很难求零点,因而也就难以得出CRF解的解析形式。
4.2 优化算法
需要说明的是,CRF的似然函数为凸函数,因而存在全局最优,我们考虑利用数值算法进行求解,比较快速的是牛顿法,但由于这里参数较多,内存开销较大,因而考虑拟牛顿法,性能较好的是L-BFGS算法,其基本原理可以参考我的另一个博客L-BFGS优化算法基本原理,它类似于一个黑盒子,需要传入变量值和梯度值就可以进行迭代运算。
五、可用的工具
CRF++是一个比较轻量级,速度也较快的线性链条件随机场工具,由C++语言实现,同时具有python接口。
[参考资料]
[1]: John Lafferty, Andrew McCallum, Fernando Pereira.Conditional Random Fields: Probabilistic Models for Segmenting and Labeling Sequence Data