多途径采集人脸并利用简单CNN网络构建简易人脸识别系统
最近入门了一下OpenCV以及TensorFlow的一些简单的内容,加上之前了解的一些关于网络数据采集的基础内容,由此产生做一个多途径采集人脸构造入门级的人脸识别系统的想法。
代码已上传到GitHub上:https://github.com/Chaphlagical/Facial-Recognition.git
准备:python 3.6,dlib, python-opencv, tensorflow, numpy, os, sys, random, sklearn
相关库函数请参照网上其他博客或教程进行安装
注意:该项目根文件夹命名为Simple_CNN_Facial_recognition(详见GitHub上代码)
一、人脸图像采集
(一)从摄像头采集人脸图像训练集(保存为~/Simple_CNN_Facial_recognition/get_faces/get_faces_from_camera.py)
注意:获取的头像信息会保存在~/Simple_CNN_Facial_recognition/training_material/name下(name为你输入的名称)
import cv2
import dlib
import os
import sys
import random
number=input("Input number of faces:")
output_dir=os.path.dirname(os.getcwd())+'/training_material'
input_dir=os.path.dirname(os.getcwd())+'/source_videos'
size=64
if not os.path.exists(output_dir):
os.makedirs(output_dir)
def count_dirs(path):
count=0
for dir in os.listdir(path):
count+=1
return count
#改变图片亮度与对比度
def relight (img,light=1,bias=0):
w=img.shape[1]
h=img.shape[0]
#image=[]
for i in range(0,w):
for j in range(0,h):
for c in range(3):
tmp=int(img[j,i,c]*light+bias)
if tmp>255:
tmp=255
elif tmp<0:
tmp=0
img[j,i,c]=tmp
return img
#使用dlib自带的frontal_face_detector作为特征提取器
detector=dlib.get_frontal_face_detector()
index=1
def get_faces_from_videoes(ranges,path,out_path):
camera=cv2.VideoCapture(path)#获取视频文件
global index
while True:
try:
if (index < ranges):
print('Being processed picture %s' % index)
if os.path.exists(out_path + '/' + str(index) + '.jpg'):
index+=1
print('picture %s is already exit'%index)
pass
# 从摄像头读取照片
success, img = camera.read()
if not camera.read():
break
# 转为灰度图
gray_img = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
# 使用detector进行人脸检测
dets = detector(gray_img, 1)
if not len(dets):
# print('Can`t get face.')
cv2.imshow('img', img)
key = cv2.waitKey(1) & 0xff
if key == 27:
sys.exit(0)
pass
for i, d in enumerate(dets):
x1 = d.top() if d.top() > 0 else 0
y1 = d.bottom() if d.bottom() > 0 else 0
x2 = d.left() if d.left() > 0 else 0
y2 = d.right() if d.right() > 0 else 0
face = img[x1:y1, x2:y2]
# 调整图片的尺寸
face = cv2.resize(face, (size, size))
face = relight(face, random.uniform(0.5, 1.5), random.randint(-50, 50))
cv2.rectangle(img, (x2, x1), (y2, y1), (255, 0, 0), 3)
cv2.imshow('image', img)
if not os.path.exists(out_path):
os.makedirs(out_path)
cv2.imwrite(out_path + '/' + str(index) + '.jpg', face)
key = cv2.waitKey(1) & 0xff
if key == 27:
sys.exit(0)
index += 1
else:
break
except:
break
for dir in os.listdir(input_dir):
dirs = output_dir + '/' + dir
index=1
for x in os.listdir(input_dir+'/'+dir):
video_path=input_dir+'/'+dir+'/'+x
get_faces_from_videoes(12000,video_path,dirs)(二)从视频文件中采集人脸图像训练集(保存为~/Simple_CNN_Facial_recognition/get_faces/get_faces_from_video.py)
注意:该代码采集的视频源来自~/Simple_CNN_Facial_recognition/source_videos文件夹中,并保存于~/Simple_CNN_Facial_recognition/training_material/name下
import cv2
import dlib
import os
import sys
import random
number=int(input("Input number of faces:"))
output_dir=os.path.dirname(os.getcwd())+'/training_material'
input_dir=os.path.dirname(os.getcwd())+'/source_videos'
size=64
if not os.path.exists(output_dir):
os.makedirs(output_dir)
def count_dirs(path):
count=0
for dir in os.listdir(path):
count+=1
return count
#改变图片亮度与对比度
def relight (img,light=1,bias=0):
w=img.shape[1]
h=img.shape[0]
#image=[]
for i in range(0,w):
for j in range(0,h):
for c in range(3):
tmp=int(img[j,i,c]*light+bias)
if tmp>255:
tmp=255
elif tmp<0:
tmp=0
img[j,i,c]=tmp
return img
#使用dlib自带的frontal_face_detector作为特征提取器
detector=dlib.get_frontal_face_detector()
index=1
def get_faces_from_videoes(ranges,path,out_path):
camera=cv2.VideoCapture(path)#获取视频文件
global index
while True:
try:
if (index <= ranges):
print('Being processed picture %s' % index)
if os.path.exists(out_path + '/' + str(index) + '.jpg'):
index+=1
print('picture %s is already exit'%index)
pass
# 从摄像头读取照片
success, img = camera.read()
if not camera.read():
break
# 转为灰度图
gray_img = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
# 使用detector进行人脸检测
dets = detector(gray_img, 1)
if not len(dets):
# print('Can`t get face.')
cv2.imshow('img', img)
key = cv2.waitKey(1) & 0xff
if key == 27:
sys.exit(0)
pass
for i, d in enumerate(dets):
x1 = d.top() if d.top() > 0 else 0
y1 = d.bottom() if d.bottom() > 0 else 0
x2 = d.left() if d.left() > 0 else 0
y2 = d.right() if d.right() > 0 else 0
face = img[x1:y1, x2:y2]
# 调整图片的尺寸
face = cv2.resize(face, (size, size))
face = relight(face, random.uniform(0.5, 1.5), random.randint(-50, 50))
cv2.rectangle(img, (x2, x1), (y2, y1), (255, 0, 0), 3)
cv2.imshow('image', img)
if not os.path.exists(out_path):
os.makedirs(out_path)
cv2.imwrite(out_path + '/' + str(index) + '.jpg', face)
key = cv2.waitKey(1) & 0xff
if key == 27:
sys.exit(0)
index += 1
else:
print("full!")
break
except:
print("Error!")
break
for dir in os.listdir(input_dir):
dirs = output_dir + '/' + dir
index=1
for x in os.listdir(input_dir+'/'+dir):
video_path=input_dir+'/'+dir+'/'+x
get_faces_from_videoes(number,video_path,dirs)(三)从图片文件中采集人脸图像训练集(保存为~/Simple_CNN_Facial_recognition/get_faces/get_faces_from_photo.py)
注意:该代码采集的视频源来自~/Simple_CNN_Facial_recognition/source_photos文件夹中,并保存于~/Simple_CNN_Facial_recognition/training_material/name下
import cv2
import dlib
import os
import sys
import random
input_path=os.path.dirname(os.getcwd())+'/source_photos'
output_path=os.path.dirname(os.getcwd())+'/training_material'
size=64
def count_dirs(path):
count=0
for dir in os.listdir(path):
count+=1
return count
#改变图片亮度与对比度
def relight (img,light=1,bias=0):
w=img.shape[1]
h=img.shape[0]
#image=[]
for i in range(0,w):
for j in range(0,h):
for c in range(3):
tmp=int(img[j,i,c]*light+bias)
if tmp>255:
tmp=255
elif tmp<0:
tmp=0
img[j,i,c]=tmp
return img
#使用dlib自带的frontal_face_detector作为特征提取器
detector=dlib.get_frontal_face_detector()
def get_faces_from_photos(photo_path,out_path,name):
img=cv2.imread(photo_path)
try:
# 转为灰度图
gray_img = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
# 使用detector进行人脸检测
dets = detector(gray_img, 1)
if not len(dets):
print('Can`t get face.')
pass
for i, d in enumerate(dets):
x1 = d.top() if d.top() > 0 else 0
y1 = d.bottom() if d.bottom() > 0 else 0
x2 = d.left() if d.left() > 0 else 0
y2 = d.right() if d.right() > 0 else 0
face = img[x1:y1, x2:y2]
# 调整图片的尺寸与对比度
face = cv2.resize(face, (size, size))
face = relight(face, random.uniform(0.5, 1.5), random.randint(-50, 50))
if not os.path.exists(out_path):
os.makedirs(out_path)
if i==0:
cv2.imwrite(out_path + '/' +name, face)
print('Being processed %s' % name)
else:
cv2.imwrite(out_path + '/' + name+str(i)+'.jpg', face)
print('Being processed %s' % name+str(i))
except:
print('Error!')
pass
for dir in os.listdir(input_path):
dirs = output_path + '/' + dir
for name in os.listdir(input_path+'/'+dir):
photo_path=input_path+'/'+dir+'/'+name
get_faces_from_photos(photo_path,dirs,name)(四)从百度图片网站上采集人脸图像训练集(保存为~/Simple_CNN_Facial_recognition/get_faces/get_faces_from_Internet.py)
注意:该代码采集的图片会临时存放在~/Simple_CNN_Facial_recognition/DownLoad_picture文件夹中,并保存于~/Simple_CNN_Facial_recognition/training_material/name下(name为搜索的Keyword),处理完自动删除~/Simple_CNN_Facial_recognition/DownLoad_picture中的内容
import re
import requests
import cv2
import dlib
import sys
import os
#定义索引
index=1
ranges=int(input("Input number:"))
detector = dlib.get_frontal_face_detector()
#从网络上获取人像
def dowmloadPic(html, keyword,input_dir,output_dir):
global index
pic_url = re.findall('"objURL":"(.*?)",', html, re.S)
print('找到关键词:' + keyword + '的图片,现在开始下载图片...')
for each in pic_url:
print('正在下载第' + str(index) + '张图片,图片地址:' + str(each))
try:
pic = requests.get(each, timeout=10)
except requests.exceptions.ConnectionError:
print('【错误】当前图片无法下载')
continue
dir = os.path.dirname(os.getcwd())+'/DownLoad_picture/' + keyword + '.jpg'#存放到临时文件夹
fp = open(dir, 'wb')
fp.write(pic.content)
fp.close()
try:
# 从文件读取图片
img = cv2.imread(dir)
while(os.path.exists(output_dir + '/' + str(index) + '.jpg')):
index+=1#避免重复
if(index>ranges):
break
# 转为灰度图片
gray_img = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
# 使用detector进行人脸检测 dets为返回的结果
dets = detector(gray_img, 1)
if not len(dets):
print("找不到人脸!")
os.remove(dir)
pass
# 使用enumerate 函数遍历序列中的元素以及它们的下标
# 下标i为人脸序号
# left:人脸左边距离图片左边界的距离 ;right:人脸右边距离图片左边界的距离
# top:人脸上边距离图片上边界的距离 ;bottom:人脸下边距离图片上边界的距离
for i, d in enumerate(dets):
x1 = d.top() if d.top() > 0 else 0
y1 = d.bottom() if d.bottom() > 0 else 0
x2 = d.left() if d.left() > 0 else 0
y2 = d.right() if d.right() > 0 else 0
face = img[x1:y1, x2:y2]
# 调整图片的尺寸为64x64
face = cv2.resize(face, (size, size))
# 保存图片
cv2.imwrite(output_dir + '/' + str(index) + '.jpg', face)
index += 1
os.remove(dir)
except:
pass
if (index > ranges):
break
input_dir = os.path.dirname(os.getcwd())+'/DownLoad_picture'
size = 64
if not os.path.exists(input_dir):
os.makedirs(input_dir)
def main():
word = input("Input key word: ")
picture_dir=os.path.dirname(os.getcwd())+'/training_material/'+str(word)
if not os.path.exists(picture_dir):
os.makedirs(picture_dir)
for pn in range(0,1000,20):
url = 'http://image.baidu.com/search/flip?tn=baiduimage&ie=utf-8&word='+word+'&pn='+str(pn)+'&gsm=3c&ct=&ic=0&lm=-1&width=0&height=0'
if (index > ranges):
break
result = requests.get(url)
dowmloadPic(result.text, word,input_dir,picture_dir)
main()至此,我们已经完成了人脸采集的主要操作途径了
其实,我们还需要一个陌生人头像数据进行分类,大家可以在我的github上的training_material中的unknow得到(切记其他人脸数据也要放在文件夹中)
二、构造CNN训练网络
为了避免代码重写,用一个文件~/Simple_CNN_Facial_recognition/CNN_training/create_CNN_network.py来定义和初始化CNN网络
import tensorflow as tf
import cv2
import numpy as np
import os
import random
import sys
from sklearn.model_selection import train_test_split
#设置tensorflow日志级别(可忽略)
os.environ['TF_CPP_MIN_LOG_LEVEL'] = '2'
#训练图片集位置
data_path = os.path.dirname(os.getcwd())+'/training_material'
#图片规格统一64x64
size=64
#初始化图像,标签列表
imgs=[]
labs=[]
#字符串转整数
def str2num(init):
num = 0
for i in init:
i = int(ord(i))
num = num + i
return num
#计算path路径下的文件和文件夹数目
def count_dir(path):
count = 0
for dir in os.listdir(path):
count += 1
return count
#计算数据集分类数dir_num
dir_num = count_dir(data_path)
#获取图像填充大小
def getPaddingSize(img):
h, w, _ = img.shape
top, bottom, left, right = (0, 0, 0, 0)
longest = max(h, w)
if w < longest:
tmp = longest - w
left = tmp // 2
right = tmp - left
elif h < longest:
tmp = longest - h
top = tmp // 2
bottom = tmp - top
else:
pass
return top, bottom, left, right
#生成标签列表way
way = []
for lab in os.listdir(data_path):
way.append(data_path + '/' + lab)
#读取图像信息
def readData(path, h=size, w=size):#获取单个文件夹下的图像信息
for filename in os.listdir(path):
if filename.endswith('.jpg'):
filename = path + '/' + filename
img = cv2.imread(filename)
top, bottom, left, right = getPaddingSize(img)
# 将图片放大, 扩充图片边缘部分
img = cv2.copyMakeBorder(img, top, bottom, left, right, cv2.BORDER_CONSTANT, value=[0, 0, 0])
img = cv2.resize(img, (h, w))
imgs.append(img)
labs.append(str2num(path))
#从data_path下获取图像信息
for lab in os.listdir(data_path):
readData(data_path + '/' + lab)
#将标签排列成单位矩阵
def select_lab(lab,dir_num):
a = []
x = []
for i in range(dir_num):
x.append(0)
for i in range(dir_num):
x[i] = 1
a.append(x[:])
x[i] = 0
for i in range(dir_num):
if lab == str2num(way[i]):
return a[i]
#将图像与标签信息转化成矩阵形式
imgs = np.asarray(imgs, np.float32)
labs = np.array([select_lab(lab, dir_num) for lab in labs])
# 随机划分测试集与训练集
train_x,test_x,train_y,test_y = train_test_split(imgs, labs, test_size=0.05, random_state=random.randint(0,100))
# 参数:图片数据的总数,图片的高、宽、通道
train_x = train_x.reshape(train_x.shape[0], size, size, 3)
test_x = test_x.reshape(test_x.shape[0], size, size, 3)
# 将数据转换成小于1的数
train_x = train_x.astype('float32')/255.0
test_x = test_x.astype('float32')/255.0
#输出训练测试集数
print('train size:%s, test size:%s' % (len(train_x), len(test_x)))
# 每次取100张图片作为数据快
batch_size = 100
num_batch = len(train_x) // batch_size
#设置占位符
x = tf.placeholder(tf.float32, [None, size, size, 3],name='x')
y_ = tf.placeholder(tf.int32, [None, dir_num],name='y_')
#防止过拟合设置
keep_prob_5 = tf.placeholder(tf.float32)
keep_prob_75 = tf.placeholder(tf.float32)
#设置CNN网络的相关构造函数
#变权
def weightVariable(shape):
init = tf.random_normal(shape, stddev=0.01)
return tf.Variable(init)
#偏差
def biasVariable(shape):
init = tf.random_normal(shape)
return tf.Variable(init)
#卷积
def conv2d(x, W):
return tf.nn.conv2d(x, W, strides=[1,1,1,1], padding='SAME')
#池化
def maxPool(x):
return tf.nn.max_pool(x, ksize=[1,2,2,1], strides=[1,2,2,1], padding='SAME')
#一定概率丢弃数据,防止过拟合
def dropout(x, keep):
return tf.nn.dropout(x, keep)
#构建CNN神经网络
# 第一层
def cnnlayer():
W1 = weightVariable([3,3,3,32]) # 卷积核大小(3,3), 输入通道(3), 输出通道(32)
b1 = biasVariable([32])
# 卷积
conv1 = tf.nn.relu(conv2d(x, W1) + b1)
# 池化
pool1 = maxPool(conv1)
# 减少过拟合,随机让某些权重不更新
drop1 = dropout(pool1, keep_prob_5)
# 第二层
W2 = weightVariable([3,3,32,64])
b2 = biasVariable([64])
conv2 = tf.nn.relu(conv2d(drop1, W2) + b2)
pool2 = maxPool(conv2)
drop2 = dropout(pool2, keep_prob_5)
# 第三层
W3 = weightVariable([3,3,64,64])
b3 = biasVariable([64])
conv3 = tf.nn.relu(conv2d(drop2, W3) + b3)
pool3 = maxPool(conv3)
drop3 = dropout(pool3, keep_prob_5)
# 全连接层
Wf = weightVariable([8*8*64, 512])
bf = biasVariable([512])
drop3_flat = tf.reshape(drop3, [-1, 8*8*64])
dense = tf.nn.relu(tf.matmul(drop3_flat, Wf) + bf)
dropf = dropout(dense, keep_prob_75)
# 输出层
Wout = weightVariable([512,dir_num])
bout = weightVariable([dir_num])
out = tf.add(tf.matmul(dropf, Wout), bout)
return out
#训练函数
def cnnTrain():
out = cnnlayer()
cross_entropy = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits(logits=out, labels=y_))
train_step = tf.train.AdamOptimizer(0.01).minimize(cross_entropy)
# 比较标签是否相等,再求的所有数的平均值,tf.cast(强制转换类型)
accuracy = tf.reduce_mean(tf.cast(tf.equal(tf.argmax(out, 1), tf.argmax(y_, 1)), tf.float32))
# 将loss与accuracy保存以供tensorboard使用
tf.summary.scalar('loss', cross_entropy)
tf.summary.scalar('accuracy', accuracy)
merged_summary_op = tf.summary.merge_all()
# 数据保存器的初始化
saver = tf.train.Saver()
with tf.Session() as sess:
sess.run(tf.global_variables_initializer())
summary_writer = tf.summary.FileWriter('./tmp', graph=tf.get_default_graph())
for n in range(1000):
# 每次取128(batch_size)张图片
for i in range(num_batch):
batch_x = train_x[i*batch_size : (i+1)*batch_size]
batch_y = train_y[i*batch_size : (i+1)*batch_size]
# 开始训练数据,同时训练三个变量,返回三个数据
_,loss,summary = sess.run([train_step, cross_entropy, merged_summary_op],
feed_dict={x:batch_x,y_:batch_y, keep_prob_5:0.5,keep_prob_75:0.75})
summary_writer.add_summary(summary, n*num_batch+i)
# 打印损失
print(n*num_batch+i, loss)
if (n*num_batch+i) % 100 == 0:
# 获取测试数据的准确率
acc = accuracy.eval({x:test_x, y_:test_y, keep_prob_5:1.0, keep_prob_75:1.0})
print(n*num_batch+i, acc)
# 准确率大于0.97时保存并退出,可修改
if acc > 0.98 and n > 2:
print("acc=%s"%acc)
saver.save(sess, os.path.dirname(os.getcwd())+'/model/train.model.ckpt', global_step=n*num_batch+i)#将模型保存在model下
sess.close()
sys.exit(0)
print('accuracy less than %s, exited!'%accuracy)>>>import create_CNN_network as CNN
>>>CNN.cnnTrain()也可以新建一个.py文件~/Simple_CNN_Facial_recognition/CNN_training/train.py
import create_CNN_network as CNN
CNN.cnnTrain()调源代码中的准确率等参数,运行训练,得到模型会保存在~/Simple_CNN_Facial_recognition/model下
至此,我们已经完成了CNN的构建和训练了
三、开始测试
main.py保存在~/Simple_CNN_Facial_recognition/main下
import tensorflow as tf
import cv2
import numpy as np
import os
import random
import sys
from sklearn.model_selection import train_test_split
import glob
import string
import dlib
#添加CNN生成代码的路径
sys.path.append(os.path.dirname(os.getcwd())+'/CNN_training')
import create_CNN_network as CNN
size=64
#生成索引字典
def named_dict(path):
dirs=os.listdir(path)
name_dict={}
test={}
for i in range(len(dirs)):
test={i:dirs[i]}
name_dict.update(test)
test.clear()
test={None:'no faces'}
name_dict.update(test)
return name_dict
name_dict=named_dict(CNN.data_path)
output = CNN.cnnlayer()
predict = tf.argmax(output, 1)
saver = tf.train.Saver()
sess = tf.Session()
saver.restore(sess, tf.train.latest_checkpoint(os.path.dirname(os.getcwd())+'/model'))
#获取key
def name_key(image):
res = sess.run(predict, feed_dict={CNN.x: [image / 255.0], CNN.keep_prob_5: 1.0, CNN.keep_prob_75: 1.0})[0]
return res
detector = dlib.get_frontal_face_detector()
#读取摄像头参数设为0(0为默认摄像头)
#更换摄像头:更换参数
#输入视频:参数改为视频路径
#输入图像注释此行
camera = cv2.VideoCapture(0)
while True:
_, img = camera.read()#若读取图像,注释此行
#img=cv2.imread(path) #若读取图像,反注释此行,参数输入图像路径
gray_image = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
dets = detector(gray_image, 1)
if not len(dets):
print('Can`t get face.')
cv2.imshow('img', img)
key = cv2.waitKey(30) & 0xff
if key == 27:
sys.exit(0)
for i, d in enumerate(dets):
x1 = d.top() if d.top() > 0 else 0
y1 = d.bottom() if d.bottom() > 0 else 0
x2 = d.left() if d.left() > 0 else 0
y2 = d.right() if d.right() > 0 else 0
face = img[x1:y1, x2:y2]
# 调整图片的尺寸
face = cv2.resize(face, (size, size))
cv2.rectangle(img, (x2, x1), (y2, y1), (255, 0, 0), 3)
cv2.putText(img,name_dict[name_key(face)],(x2,x1),cv2.FONT_HERSHEY_SIMPLEX,1,(0,0,255),3)
cv2.imshow('image', img)
key = cv2.waitKey(30) & 0xff
if key == 27:
sys.exit(0)
sess.close()稍加修改后运行,查看效果:
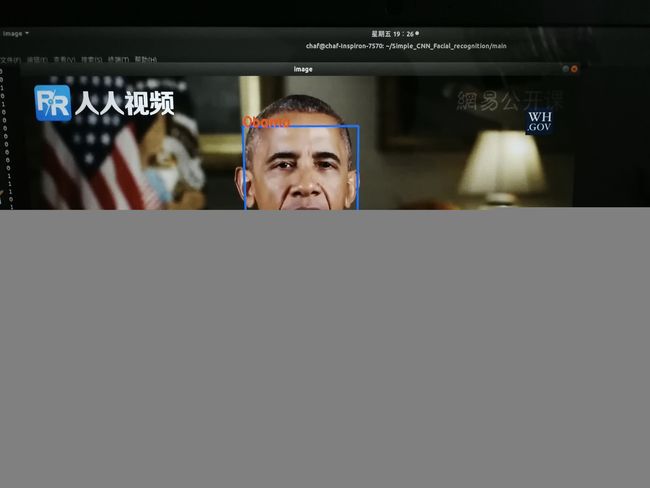
总结:
这是一个非常简单的人脸识别系统,由于深度学习自身的缺点,以及能力有限,要真正识别任意场合下同一个人的脸还是需要多样的海量数据进行训练,而且在人脸网络数据采集上没有对图像进行清洗,所以当你的小姐姐头像乱入了大叔也属正常现象。代码并非优异,还是需要多加学习,优化。
如有错误,欢迎指出,谢谢大家!