windows下安装Elasticsearch以及Java应用
一、下载elasticsearch-7.3.1-windows-x86_64安装包放置指定盘下
解压目录如下:

配置环境变量:

去到bin目录下点击elasticsearch.bat启动,或是%ES_HOME%\bin\elasticsearch.bat启动都可以,然后浏览器访问:127.0.0.1:9200,如下即安装成功

二、安装Head插件(head是ES的集群管理工具,可以用于数据的浏览和查询)
由于ES是一款开源软件,被托管在Git上,所以如要使用必须先要安装Git,通过Git获取elasticsearc-head
由于运行elasticsearc-head会使用到grunt,而grunt需要npm包管理器,所以nodejs也是必须要安装的
2.1、安装nodejs
下载对应自己系统对应的 Node.js 版本,地址:https://nodejs.org/zh-cn/
放置到指定盘进行安装,选定安装地址,一路next就可以了
安装完成查看是否安装成功:
node -v 查看node版本
npm -v 查看npm版本
如下图既是安装成功

安装完成后,文件目录如下图

环境配置
此处的环境配置主要配置的是 npm 安装的全局模块所在的路径,以及缓存cache的路径,之所以要配置,是因为以后在执行类似:npm install express [-g] (后面的可选参数-g,g代表global全局安装的意思)的安装语句时,会将安装的模块安装到【C:\Users\用户名\AppData\Roaming\npm】路径中,占C盘空间。
例如:我希望将全模块所在路径和缓存路径放在我node.js安装的文件夹中,则在我的安装目录下创建两个文件夹【node_global】及【node_cache】如下图:

设置全局目录和缓存目录,创建完两个空文件夹之后,打开cmd命令窗口,输入
npm config set prefix "D:\nodejs\node_globall"
npm config set cache "D:\nodejs\node_cache"

环境变量配置:

编辑path变量:

测试
npm install express -g # -g是全局安装的意思

注:如果安装时不加 -g 参数,则安装的模块就会安装在当前路径下,上例若不加 -g 参数,则 express 模块会安装在 C:\Users\yi081目录下的 【node_modules】目录下,目录若不存在会自动生成。

最新express版本中将命令工具分家出来了(项目地址:https://github.com/expressjs/generator),所以还需要安装一个命令工具,命令如下:
npm install -g express-generator
然后打开我们的安装目录发现 express 被安装在了全局目录下,如下图:

使用express创建一个工程,输入命令:express helloworld

转到 helloworld 目录下,命令:cd helloworld ; npm start

装载 node 包管理器,执行命令:npm install

启动 helloworld,输入命令:npm start,如下图,新创建的 helloworld 已经运行在3000端口上

在浏览器中输入地址:http://localhost:3000/,如下图
 标题
标题
2.2、安装Git
根据自己的版本需要下载Git放置到指定盘安装


创建开始菜单目录名称,默认git,不需要修改

选择git使用的编辑器



行末换行符转换,使用默认值




Install 安装

检测安装成功,任意窗口或桌面都可以右键,出现下面两个选项即可

点击Git Bash Here,显示终端

安装成功
2.3、安装head插件
下载地址:https://github.com/mobz/elasticsearch-head;点击clone or download按钮,点击download zip进行下载。下载完毕后解压到任意路径上,别放在elasticsearch安装路径上

安装grunt
运行head需要借助grunt命令,因此需要安装grunt,输入命令 cd D:\nodejs(你安装nodejs的路径) 进入nodejs的根目录下,然后执行指令 npm install -g grunt -cli 进行安装grunt。

安装pathomjs
输入命令 cd D:\head(你安装head的路径) 进入head的根目录下,然后执行命令:npm install 进行安装pathomjs(安装时间较长)。如果出现Error关键字,则有可能是网络不顺畅。

运行head
最后,什么都别关,还没结束呢,在刚刚的命令窗口执行运行命令 grunt server,启动head服务,如下所示则为启动成功。(可以到head根目录下修改Gruntfile.js文件的启动端口,默认是9100)

然后去修改elasticsearch的配置文件,elasticsearch安装目录/config/elasticsearch.yml,打开文件后在末端另起一行分别顶格添加如下两行红色字体文本,保存后重启elasticsearch.bat。
1 http.cors.enabled: true
2 http.cors.allow-origin: "*"
用head访问elasticsearch
浏览器访问 http://localhost:9100 (head的服务端口),访问成功

将D:\eshead\elasticsearch-head-master下的Gruntfile.js文件中的connect-->server-->options下面添加hostname:'*',允许所有IP可以访问:

将D:\eshead\elasticsearch-head-master\_site下的app.js文件中的
this.base_uri=this.config.base_uri||this.prefs.get("app-base_uri")||"http://localhost:9200";
修改为
this.base_uri=this.config.base_uri||this.prefs.get("app-base_uri")||"http://192.168.8.8:9200";
![]()
三、安装kibana(kibana类似于head,但是kibana功能更强大,使用的用户更多)
下载与你安装的ES版本一致的kibana到指定文件夹解压缩,然后到bin文件夹下启动

kibana.yml中设置server.host: "0.0.0.0",同一网络可被其他机器访问
访问localhost:5601

四、安装分词器ik
访问 https://github.com/medcl/elasticsearch-analysis-ik 找 releases 找到对应的 es 版本,下载到指定文件夹解压缩
将pom.xml中的版本号改为跟你的ES版本相同

然后在此目录下打开dos窗口,执行命令mvn clean package进行打包

打包后会发现上边的目录就多一个target文件夹了
然后进入\target\releases下可以看到打的zip包

然后先在你所安装es的所在目录下的的plugins下创建analysis-ik文件夹,然后将上面的zip包拷贝到新建的该文件夹下解压缩

最后重新启动elasticsearch,可以启动说明安装成功
五、使用kibana实现基本CURD操作
新增索引:


新增默认配置索引:

查看索引:


查看所有索引:GET _all/_settings
在索引下添加文档:

不指定文档ID的时候用post:

查询文档(需要知道文档ID):GET /lib/user/1
查看文档的指定字段:GET /lib/user/1?_source=age,about
修改文档:
1、使用put直接覆盖之前的文档

2、直接修改用post

删除文档:DELETE /lib/user/1
删除索引:DELETE lib
使用Multi get API实现批量获取文档:

批量获取文档指定字段:

获取同索引同类型下的不同文档:


使用Bulk API实现批量操作
Bulk会把将要处理的数据载入内存中,所以数量是有限制的,取决于硬件、文档大小以及复杂性、索引以及搜索的负载,一般建议是1000-5000个文档,大小建议5-15MB,默认不能超过100MB,可以在ES 的配置文件(elastcsearch.yml)中配置
批量添加文档:

批量修改和删除文档:

版本控制
Elasticsearch采用了乐观锁来保证数据的一致性,即当用户对document(文档,即关系数据库中表里的一条数据)进行操作时,并不需要对该document做加锁、解锁的操作,只需要指定要操作的版本即可。当版本号一致时,Elasticsearch会允许该操作顺利进行,而当版本号存在冲突时,Elasticsearch会提示冲突并抛出异常(VersionConflictEngineException)。
Elasticsearch的版本号的取值范围为1到2^63-1。

内部版本控制:使用的时_version。
外部版本控制:elasticsearch在处理外部版本号时会与内部版本号的处理有些不同。它不再是检查_version是否与请求中指定的数据相同,而是检查当前的_version是否比指定的数值小。如果请求成功,那么外部的版本号就会被存储到文档中的_version中。
为了保持_version与外部版本控制的数据一致,使用version_type=external,当使用外部版本控制时,版本号要大于已有的版本号才可以成功修改

查询(ES7版本之后):GET /myindex/_mapping
GET /yangsir/_doc/_search?q=post_date:2019-09-19
当查询日期类型时,必须是精确查询
Object数据类型以及手动创建mapping


查询操作注意事项:
Query查询关键字,当精确查询的时候使用term或者是terms,模糊查询的时候使用match,因为match是使用分词查找的:

Multi_match可以同时查询多个字段:

Match_phrase短语匹配查询:

_source控制返回字段:


使用groovy脚本执行partial update



![]()

重建索引且保证应用程序不用重启


Eclipse下使用ES
Eclipse新建maven项目,并添加依赖:
编写Junit测试类:


//添加文档
/**
* "{"+
* "\"id\":\"1\","+
* "\"title\":\"Java设计模式之装饰模式\","+
* "\"content\":\"在不必改变原类文件和使用继承的情况下,动态的扩展一个对象的功能\","+
* "\"postdate\":\"2019-09-24\","+
* "\"url\":\"csdn.net/79239072\""+
* "}"
*/
第一步:去kibana中新建索引及mapping



将连接方式提取:

修改文档:

Upsert操作(当修改操作没有对应的ID的时候执行新增操作):

批量操作文档:


查询删除:

查询所有:
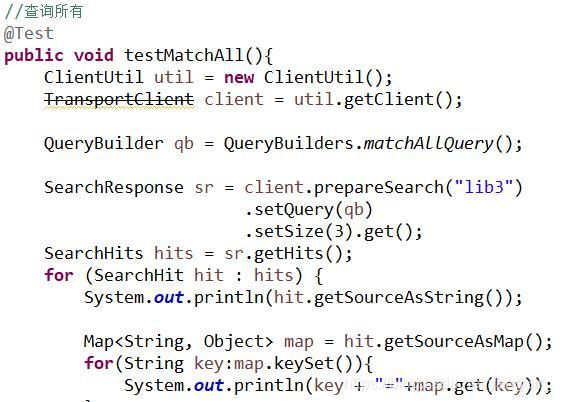









聚合查询:


组合查询:




集群管理:

添加ik分词器依赖:
利用ik分词器获取分词结果:

Kibana分页查询:

删除整个类型:

问题解决:

出现这个问题是由于Lucene版本与elasticsearch的版本依赖不一致导致,解决方式如下:
通过head查看已经依赖的ES对应的Lucene版本

或是在DOS命令使用:curl -XGET localhost:9200

在项目pom.xml里面添加对应的依赖: