《深入浅出计算机组成原理》专栏阅读笔记之处理器
文章目录
- 数据通路
- 为什么循环嵌套的改变会影响性能?
- 异常和中断
- CISC和RISC
- GPU
- FPGA、ASIC和TPU
- 虚拟机
数据通路
计算机每执行一条指令的过程,可以分解成这样几个步骤

- Fetch(取得指令),也就是从 PC 寄存器里找到对应的指令地址,根据指令地址从内存里把具体的指令,加载到指令寄存器中,然后把 PC 寄存器自增,好在未来执行下一条指令。
- Decode(指令译码),也就是根据指令寄存器里面的指令,解析成要进行什么样的操作,是 R、I、J 中的哪一种指令,具体要操作哪些寄存器、数据或者内存地址。
- Execute(执行指令),也就是实际运行对应的 R、I、J 这些特定的指令,进行算术逻辑操作、数据传输或者直接的地址跳转。
- 重复进行 1~3 的步骤。
这样的步骤,其实就是一个永不停歇的“Fetch - Decode - Execute”的循环,我们把这个循环称之为指令周期(Instruction Cycle)
- 对于一个指令周期来说,我们取出一条指令,然后执行它,至少需要两个 CPU 周期。取出指令至少需要一个 CPU 周期,执行至少也需要一个 CPU 周期,复杂的指令则需要更多的 CPU 周期。
CPU 内部的操作速度很快,但是访问内存的速度却要慢很多。每一条指令都需要从内存里面加载而来,所以我们一般把从内存里面读取一条指令的最短时间,称为
CPU 周期。
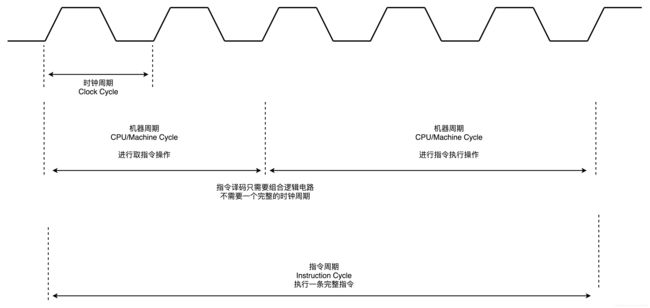
- 一个指令周期,包含多个 CPU 周期,而一个 CPU 周期包含多个时钟周期。
- 指令译码器将输入的机器码,解析成不同的操作码和操作数,然后传输给 ALU 进行计算.
- CPU的功能完成需要的4 种基本电路:ALU 这样的组合逻辑电路、用来存储数据的锁存器和 D 触发器电路、用来实现 PC 寄存器的计数器电路,以及用来解码和寻址的译码器电路。
- CPU 的主频是由一个晶体振荡器来实现的,而这个晶体振荡器生成的电路信号,就是我们的时钟信号。
CPU 的流水线设计,分别是结构冒险(Structural Hazard)、数据冒险(Data Hazard)以及控制冒险(Control Hazard)。

- 现代的 CPU 虽然没有在内存层面进行对应的拆分,却在 CPU 内部的高速缓存部分进行了区分,把高速缓存分成了指令缓存(Instruction Cache)和数据缓存(Data Cache)两部分。
现代 Intel 的 CPU 的乱序执行的过程中,只有指令的执行阶段是乱序的,后面的内存访问和数据写回阶段都仍然是顺序的。这种保障内存数据访问顺序的模型,叫作强内存模型(Strong Memory Model)
为什么循环嵌套的改变会影响性能?
状态机由状态寄存器和组合逻辑电路构成,能够根据控制信号按照预先设定的状态进行状态转移,是协调相关信号动作、完成特定操作的控制中心。
- cmp:cmp 指令比较了前后两个操作数的值,这里的 DWORD PTR 代表操作的数据类型是 32 位的整数,而[rbp-0x4]则是一个寄存器的地址。所以,第一个操作数就是从寄存器里拿到的变量 r 的值。第二个操作数 0x0 就是我们设定的常量 0 的 16 进制表示。cmp 指令的比较结果,会存入到条件码寄存器当中去。
- jle: jle 跳转的地址,在这条指令之前的地址 14,而非 if…else 编译出来的跳转指令之后。往前跳转使得条件满足的时候,PC 寄存器会把指令地址设置到之前执行过的指令位置,重新执行之前执行过的指令,直到条件不满足,顺序往下执行 jle 之后的指令,整个循环才结束。
- jne: jne 指令,是 jump if not equal 的意思,它会查看对应的零标志位。
- jmp : jmp 的无条件跳转指令。
控制冒险(Control Harzard):为了确保能取到正确的指令,而不得不进行等待延迟的情况。
public class Demo15 {
public static void main(String args[]) {
long start = System.currentTimeMillis();
for (int i = 0; i < 100; i++) {
for (int j = 0; j <1000; j ++) {
for (int k = 0; k < 10000; k++) {
}
}
}
long end = System.currentTimeMillis();
System.out.println("Time spent is " + (end - start));
start = System.currentTimeMillis();
for (int i = 0; i < 10000; i++) {
for (int j = 0; j <1000; j ++) {
for (int k = 0; k < 100; k++) {
}
}
}
end = System.currentTimeMillis();
System.out.println("Time spent is " + (end - start) + "ms");
}
}
- 这样两次运行,花费的时间是一样的么?结果应该会让你大吃一惊。
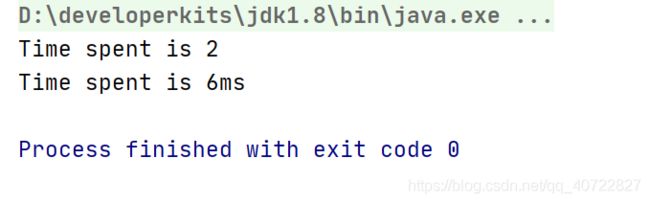
- 同样循环了十亿次,第一段程序只花了 2 毫秒,而第二段程序则花了 6 毫秒,足足多了 3 倍。
- 这个差异就来自指令执行时候的分支预测。for 循环其实也是利用 cmp 和 jle 这样先比较后跳转的指令来实现的。
- 每一次for循环都有一个 cmp 和 jle 指令。每一个 jle 就意味着,要比较条件码寄存器的状态,决定是顺序执行代码,还是要跳转到另外一个地址。也就是说,在每一次循环发生的时候,都会有一次“分支”。
分支预测策略最简单的一个方式,自然是“假定分支不发生”。

代码实例
//test2.c
#include<stdio.h>
int main()
{
int a = 0;
for (int i = 0; i < 3; i++)
{
a += i;
}
return a;
}
[root@iZwz9d92f8g67ucc81xt2aZ local]# gcc -g -c test2.c -std=gnu99
[root@iZwz9d92f8g67ucc81xt2aZ local]# objdump -d -M intel -S test2.o
test2.o: file format elf64-x86-64
Disassembly of section .text:
0000000000000000 <main>:
#include<stdio.h>
int main()
{
0: 55 push rbp
1: 48 89 e5 mov rbp,rsp
int a = 0;
4: c7 45 fc 00 00 00 00 mov DWORD PTR [rbp-0x4],0x0
for (int i = 0; i < 3; i++)
b: c7 45 f8 00 00 00 00 mov DWORD PTR [rbp-0x8],0x0
12: eb 0a jmp 1e <main+0x1e>
{
a += i;
14: 8b 45 f8 mov eax,DWORD PTR [rbp-0x8]
17: 01 45 fc add DWORD PTR [rbp-0x4],eax
for (int i = 0; i < 3; i++)
1a: 83 45 f8 01 add DWORD PTR [rbp-0x8],0x1
1e: 83 7d f8 02 cmp DWORD PTR [rbp-0x8],0x2
22: 7e f0 jle 14 <main+0x14>
}
return a;
24: 8b 45 fc mov eax,DWORD PTR [rbp-0x4]
}
27: 5d pop rbp
28: c3 ret
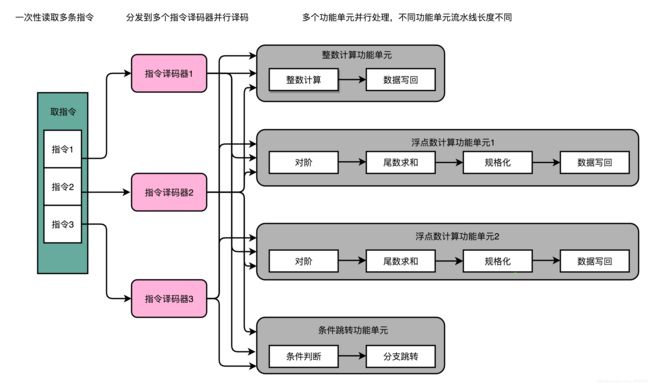
- 这种 CPU 设计,我们叫作多发射(Mulitple Issue)和超标量(Superscalar)。
SIMD,中文叫作单指令多数据流(Single Instruction Multiple Data)
SISD,中文叫作单指令单数据(Single Instruction Single Data)
MIMD,中文叫作多指令多数据(Multiple Instruction Multiple Dataa)
MMX,中文叫作矩阵数学扩展 (Matrix Math eXtensions )
异常和中断
异常,最有意思的一点就是,它其实是一个硬件和软件组合到一起的处理过程。异常的前半生,也就是异常的发生和捕捉,是在硬件层面完成的。但是异常的后半生,也就是说,异常的处理,其实是由软件来完成的。
- 异常代码里,I/O 发出的信号的异常代码,是由操作系统来分配的,也就是由软件来设定的。而像加法溢出这样的异常代码,则是由 CPU 预先分配好的,也就是由硬件来分配的。这又是另一个软件和硬件共同组合来处理异常的过程。
- CPU 在拿到了异常码之后,会先把当前的程序执行的现场,保存到程序栈里面,然后根据异常码查询,找到对应的异常处理程序,最后把后续指令执行的指挥权,交给这个异常处理程序。

异常可以由硬件触发,也可以由软件触发。平时会碰到哪些异常呢?
- 第一种异常叫中断(Interrupt)。顾名思义,自然就是程序在执行到一半的时候,被打断了。这个打断执行的信号,来自于 CPU 外部的 I/O 设备。
- 第二种异常叫陷阱(Trap)。陷阱,其实是我们程序员“故意“主动触发的异常。最常见的一类陷阱,发生在我们的应用程序调用系统调用的时候,也就是从程序的用户态切换到内核态的时候。应用程序通过系统调用去读取文件、创建进程,其实也是通过触发一次陷阱来进行的。这是因为,我们用户态的应用程序没有权限来做这些事情,需要把对应的流程转交给有权限的异常处理程序来进行。
- 第三种异常叫故障(Fault)。它和陷阱的区别在于,陷阱是我们开发程序的时候刻意触发的异常,而故障通常不是。
- 第四种异常叫中止(Abort)。当 CPU 遇到了故障,但是恢复不过来的时候,程序就不得不中止了。
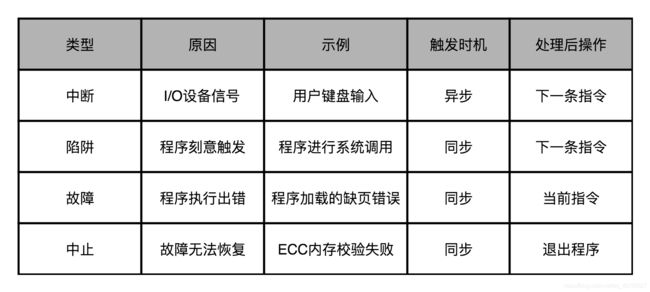
故障和陷阱、中断的一个重要区别是,故障在异常程序处理完成之后,仍然回来处理当前的指令,而不是去执行程序中的下一条指令。因为当前的指令因为故障的原因并没有成功执行完成。
CISC和RISC
CPU 的指令集里的机器码是固定长度还是可变长度,也就是复杂指令集(Complex Instruction Set Computing,简称 CISC)和精简指令集(Reduced Instruction Set Computing,简称 RISC)这两种风格的指令集一个最重要的差别。


程序的 CPU 执行时间 = 指令数 × CPI × Clock Cycle Time
- CISC 的架构,其实就是通过优化指令数,来减少 CPU 的执行时间。而 RISC 的架构,其实是在优化 CPI。因为指令比较简单,需要的时钟周期就比较少。
GPU
- 一个基于多边形建模的三维图形的渲染过程。这个渲染过程需要经过顶点处理、图元处理、栅格化、片段处理以及像素操作这 5 个步骤。这 5 个步骤把存储在内存里面的多边形数据变成了渲染在屏幕上的画面。

FPGA、ASIC和TPU
FPGA,也就是现场可编程门阵列(Field-Programmable Gate Array),解决了我们前面说的想要设计硬件的问题。我们可以像软件一样对硬件编程,可以反复烧录,还有海量的门电路,可以组合实现复杂的芯片功能。
ASIC(Application-Specific Integrated Circuit),也就是专用集成电路
TPU 的模块图和对应的芯片布局图

- 一个深度学习的推断过程,是由很多层的计算组成的。而每一个层(Layer)的计算过程,就是先进行矩阵乘法,再进行累加,接着调用激活函数,最后进行归一化和池化。这里的硬件设计呢,就是把整个流程变成一套固定的硬件电路。这也是一个 ASIC 的典型设计思路,其实就是把确定的程序指令流程,变成固定的硬件电路。
黑格尔说,“世上没有无缘无故的爱,也没有无缘无故的恨”。
虚拟机
虚拟机(Virtual Machine)技术,其实就是指在现有硬件的操作系统上,能够模拟一个计算机系统的技术。而模拟一个计算机系统,最简单的办法,其实不能算是虚拟机技术,而是一个模拟器(Emulator)。
- 把原先的操作系统叫作宿主机(Host),把能够有能力去模拟指令执行的软件,叫作模拟器(Emulator),而实际运行在模拟器上被“虚拟”出来的系统呢,我们叫客户机(Guest VM)。
你知道的越多,你不知道的越多。
有道无术,术尚可求,有术无道,止于术。
如有其它问题,欢迎大家留言,我们一起讨论,一起学习,一起进步