《深入剖析Tomcat 》第4章 tomcat的默认连接器
4.1 简介
第三章的连接器只是一个学习版,是为了介绍tomcat的默认连接器而写。第四章会深入讨论下tomcat的默认连接器(这里指的是tomcat4的默认连接器,现在该连接器已经不推荐使用,而是被Coyote取代)。
tomcat的连接器是一个独立的模块,可被插入到servlet容器中。目前已经有很多连接器的实现,包括Coyote,mod_jk,mod_jk2,mod_webapp等。tomcat的连接器需要满足以下要求:
(1)实现org.apache.catalina.Connector接口;
(2)负责创建实现了org.apache.catalina.Request接口的request对象;
(3)负责创建实现了org.apache.catalina.Response接口的response对象。
tomcat4的连接器与第三章实现的连接器类似,等待http请求,创建request和response对象,调用org.apache.catalina.Container的invoke方法将request对象和response对象传入container。在invoke方法中,container负责载入servlet类,调用其call方法,管理session,记录日志等工作
tomcat的默认连接器中有一些优化操作没有在chap3的连接器中实现。首先是提供了一个对象池,避免频繁创建一些创佳代价高昂的对象。其次,默认连接器中很多地方使用了字符数组而非字符串。
本章的程序是实现一个使用默认连接器的container。但,本章的重点不在于container,而是connector。另一个需要注意的是,默认的connector实现了HTTP1.1,也可以服务HTTP1.0和HTTP0.9的客户端。
本章以HTTP1.1的3个新特性开始,这对于理解默认connector的工作机理很重要。然后,要介绍org.apache.catalina.Connector接口。
4.2 HTTP1.1的新特性
4.2.1 持久化连接
在http1.1之前,当服务器端将请求的资源返回后,就会断开与客户端的连接。但是,网页上会包含一些其他资源,如图片,applet等。因此,客户端请求资源后,浏览器还需要下载页面引用的 资源。如果页面和资源使用是通过不同的连接下载的,那么整个处理过程会很慢。因此,HTTP1.1引入了持久化连接。
使用持久化连接,当客户端下载页面后,服务器并不会立刻关闭连接,而是等待浏览器请求页面要引用的页面资源。这样,页面和资源使用同一个连接下载,这样就节省很多的工作和时间。
HTTP1.1中默认使用持久化连接,而客户端也可以主动使用。方法是在请求头中加入下面信息:
connection: keep-alive
4.2.2 编码
建立了持久化连接后,服务器可以使用该连接发送多个资源,而客户端也可以使用该连接发送多个请求。发送方在发送消息时就要附带上发送内容的长度,这样,接收方才能知道如何解释这些字节。但,通常的情况是,发送方并不知道要发送多少字节。例如,container可以在接收到一些字节后就向客户端返回一些信息,而不必等所有的字节都接收后再返回响应。因此,必须有某种方法告诉接收方如何解释字节流。
其实,即使没有发出多个请求,服务器或客户端也不需要知道有多少字节要发送。在HTTP1.0中,服务器可以不管content-length头信息,尽管往连接中写响应内容就行。这种情况下,客户端就一直读内容,直到读方法返回-1,此时表示已经没有更多信息了。
在HTTP1.1中,使用了一个特殊的头信息,transfer-encoding,表明字节流按照块发送。每个块的长度以16进制表示,后跟CRLF,然后是发送的内容。每次事务以一个0长度的块为结束标识。
例如,你想发送两个块,一个29字节,一个9字节。发送格式如下:
4.2.3 状态码100的使用
在HTTP1.1中,客户端在发送请求体之前,可能会先向服务器端发送这样的头信息:
Expect: 100-continue
然后等待服务器端的确认。
当客户端准备发送一个较长的请求体,而不确定服务端是否会接收时,就可能会发送上面的头信息。而服务器若是可以接受,则可以对此头信息进行响应,返回:
HTTP/1.1 100 Continue
注意,返回内容后面要加上CRLF。
4.3 Connector接口
tomcat的connector必须实现org.apache.catalina.Connector接口。该接口有很多方法,最重要的是getContainer,setContainer,createRequest和createResponse。
setContainer方法用于将connector和container联系起来,getContainer则可以返回响应的container,createRequest和createResponse则分别负责创建request和response对象。
org.apache.catalina.connector.http.HttpConnector类是Connector接口的一个实现,将在下一章讨论。响应的uml图如下所示:
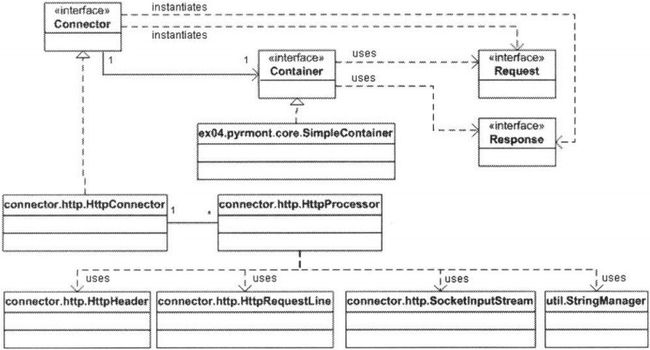
图表 7 默认连接器的uml示意图
注意,connector和container是一对一的关系,而connector和processor是一对多的关系。
4.4 HttpConnector类
在第三章中,已经实现了一个与org.apache.catalina.connector.http.HttpConnector类似的简化版connector。它实现了org.apache.catalina.Connector接口,java.lang.Runnable接口(确保在自己的线程中运行)和org.apache.catalina.Lifecycle接口。Lifecycle接口用于维护每个实现了该接口的tomcat的组件的生命周期。
Lifecycle具体内容将在第六章介绍。实现了Lifecycle接口后,当创建一个HttpConnector实例后,就应该调用其initialize方法和start方法。在组件的整个生命周期内,这两个方法只应该被调用一次。下面要介绍一些与第三章不同的功能:创建ServerSocket,维护HttpProcessor池,提供Http请求服务。
4.4.1 创建ServerSocket
HttpConnector的initialize方法会调用一个私有方法open,返回一个java.net.ServerSocket实例,赋值给成员变量serverSocket。这里并没有直接调用ServerSocket的构造方法,而是用过open方法调用ServerSocket的一个工厂方法来实现。具体的实现方式可参考ServerSocketFactory类和DefaultServerSocketFactory类(都在org.apache.catalina.net包内)。
4.4.2 维护HttpProcessor对象池
在第三章的程序中,每次使用HttpProcessor时,都会创建一个实例。而在tomcat的默认connector中,使用了一个HttpProcessor的对象池, 其中的每个对象都在其自己的线程中使用。因此,connector可同时处理多个http请求。
HttpConnector维护了一个HttpProcessor的对象池,避免了频繁的创建HttpProcessor对象。该对象池使用java.io.Stack实现。
在HttpConnector中,创建的HttpProcessor数目由两个变量决定:minProcessors和maxProcessors。
protected int minProcessors = 5;
private int maxProcessors = 20;
默认情况下,minProcessors=5,maxProcessors=20,可通过其setter方法修改。
初始化的时候,HttpConnector会创建minProcessors个HttpProcessor对象。若不够用就继续创建,直到到达maxProcessors个。此时,若还不够,则后达到的http请求将被忽略。若是不希望对maxProcessors进行限制,可以将其置为负数。此外,变量curProcessors表示当前已有的HttpProcessor实例数目。
下面是start方法中初始化HttpProcessor对象的代码:
其中newProcessor方法负责创建HttpProcessor实例,并将curProcessors加1。recycle方法将新创建的HttpProcessor对象入栈。
每个HttpProcessor对象负责解析请求行和请求头,填充request对象。因此,每个HttpProcessor对象都关联一个request对象和response对象。HttpProcessor的构造函数会调用HttpConnector的createRequest方法和createResponse方法。
4.4.3 提供Http请求服务
HttpConnector类的主要业务逻辑在其run方法中(例如第三章的程序中那样)。run方法中维持一个循环体,该循环体内,服务器等待http请求,直到HttpConnector对象回收。
对于每个http请求,通过调用其私有方法createProcessor获得一个HttpProcessor对象。这里,实际上是从HttpProcessor的对象池中拿一个对象。
注意,若是此时对象池中已经没有空闲的HttpProcessor实例可用,则createProcessor返回null。此时,服务器会直接关闭该连接,忽略该请求。如代码所示:
若是createProcessor方法返回不为空,则调用该HttpProcessor实例的assign方法,并将客户端socket对象作为参数传入:
这时,HttpProcessor实例开始读取socket的输入流,解析http请求。这里有一个重点,assign方法必须立刻返回,不能等待HttpProcessor实例完成解析再返回,这样才能处理后续的http请求。由于每个HttpProcessor都可以使用它自己的线程进行处理,所以这并不难实现。
4.5 HttpProcessor类
HttpProcessor类与第三章中的实现相类似。本章讨论下它的assign方法是如何实现异步功能的(即可同时处理多个http请求)。
在第三章中,HttpProcessor类运行在其自己的线程中。在处理下一个请求之前,它必须等待当前请求的处理完成。下面是第三章中的HttpConnector类的run方法的部分代码:
可以process方法是同步的。但是在tomcat的默认连接器中,HttpProcessor实现了java.lang.Runnable接口,每个HttpProcessor的实例都可以在其自己的线程中运行,成为“处理器线程”(“processor thread”)。HttpConnector创建每个HttpProcessor实例时,都会调用其start方法,启动其处理器线程。下面的代码显示了tomcat默认connector的HttpProcessor实例的run方法:
这个循环体做的事是:获取socket,处理它,调用connector的recycle方法将当前的HttpProcessor入栈。recycle方法的实现是:
注意,循环体在执行到await方法时会暂停当前处理器线程的控制流,直到获取到一个新的socket。换句话说,在HttpConnector调用HttpProcessor实例的assign方法前,程序会一直等下去。但是,assign方法并不是在当前线程中执行的,而是在HttpConnector的run方法中被调用的。这里称HttpConnector实例所在的线程为连接器线程(connector thread)。那么,assign方法是如何通知await方法它已经被调用了呢?方法是使用一个成为available的boolean变量和java.lang.Object的wait和notifyAll方法。
注意,wait方法会暂停本对象所在的当前线程,使其处于等待状态,直到另一线程调用了该对象的notify或notifyAll方法。
下面是HttpProcessor的assign方法和await方法的实现代码:
当处理器线程刚刚启动时,available值为false,线程在循环体内wait,直到任意一个线程调用了notify或notifyAll方法。也就是说,调用wait方法会使线程暂定,直到连接器线程调用HttpProcessor实例的notify或notifyAll方法。
当一个新socket被设置后,连接器线程调用HttpProcessor的assign方法。此时available变量的值为false,会跳过循环体,该socket对象被设置到HttpProcessor实例的socket变量中。然后连接器变量设置了available为true,调用notifyAll方法,唤醒处理器线程。此时available的值为true,跳出循环体,将socket对象赋值给局部变量,将available设置为false,调用notifyAll方法,并将给socket返回。
为什么await方法要使用一个局部变量保存socket对象的引用,而不返回实例的socket变量呢?是因为在当前socket被处理完之前,可能会有新的http请求过来,产生新的socket对象将其覆盖。
为什么await方法要调用notifyAll方法?考虑这种情况,当available变量的值还是true时,有一个新的socket达到。在这种情况下,连接器线程会在assign方法的循环体中暂停,直到处理器线程调用notifyAll方法。
4.6 request对象
默认连接器中的http request对象由org.apache.catalina.Request接口表示。该接口直接集成自RequestBase类,RequestBase是HttpRequest的父类。最终的实现类是HttpRequestImpl,继承自HttpRequest。与第三章的类关系类似,本章中也有外观类,RequestFacade和HttpRequestFacade。响应的uml示意图如下:
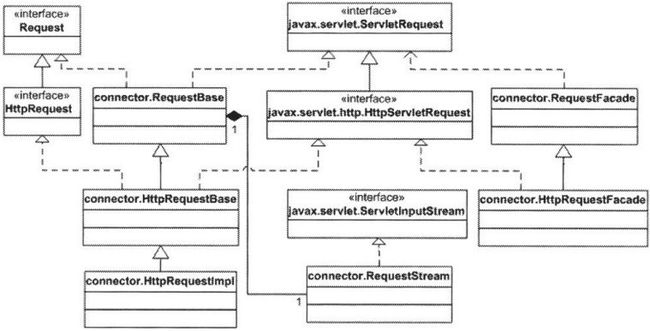
图表 8 Request接口及相关类的UML示意图
图表 8 Request接口及相关类的UML示意图
注意,图中报名包括javax.servlet和javax.servlet.http,其余类的报名均是org.apache.catalina,只是被省略掉了。
4.7 response对象
uml示意图如下:
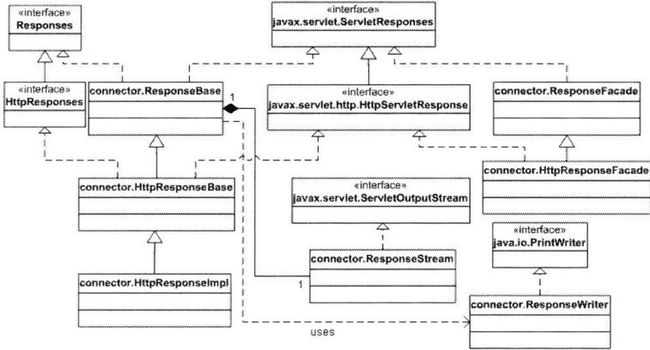
图表 9 Response接口及其相关类UML示意图
4.8 处理request对象
在这一点上,你已经知道了request对象和response对象,以及HttpConnector是如何创建它们的。本节中,将着重讨论HttpProcessor类的process方法。process方法做了三件事,解析连接,解析请求,解析请求头。
process使用一个boolean变量ok来表示在处理过程中是否有错误发生,以及一个boolean变量finishResponse来表示是否应该调用Response接口的finishResponse方法。
此外,process还是了实例的其他一些boolean变量,如keepAlive,stopped和http11。keepAlive表明该连接是否是持久化连接,stopped表明HttpProcessor实例是否被connector终止,这样的话processor也应该停止。http11表明客户端发来的请求是否支持HTTP/1.1
与第三章类似,SocketInputStream实例用于包装socket输入流。注意,SocketInputStream的构造函数也接受缓冲区的大小为参数,该参数来自connector,而不是HttpProcessor的一个局部变量。因为对默认connector的使用者来说,HttpProcessor是不可见的。如下面的代码所示:
然后是一个while循环,不断的读取输入流内容,直到HttpProcessor实例被终止,或处理过程报异常,或连接被断开。代码如下:
在循环体内,process方法现将finishResponse设置为true,获取输出流,执行一些request和response对象的初始化操作。
parseConnection方法获取请求所使用的协议,其值可以是HTTP 0.9, HTTP 1.0或HTTP 1.1。若值为HTTP 1.0,则将keepAlive置为false,因此HTTP 1.0不支持持久化连接。若是在http请求头中找到发现“Expect: 100-continue”,则parseHeaders设置sendAck为true。若请求协议为HTTP 1.1,会对调用ackRequest方法对“Expect: 100-continue”请求头响应。此外,还会检查是否允许分块。
4.8.1 解析连接
parseConnection从socket接收internet地址,将其赋值给HttpRequestImpl对象。此外,还要检查是否使用了代理,将socket对象赋值给request对象。代码如下:
4.8.2 解析request
与第三章的程序类似。
4.8.3 解析请求头
默认connector的parseHeaders方法是用了org.apache.catalina.connector.http包内的HttpHeader类和DefaultHeader类。HttpHeader类表示一个http请求中的请求头。这里与第三章不同的是,这里并没有使用字符串,而是使用了字符数组来避免代价高昂的字符串操作。DefaultHeaders类是一个final类,包含了字符数组形式的标准http请求头:
4.9 简单的container程序
这里重在展示如何使用默认的connector。程序包括两个类:ex04.pyrmont.core.SimpleContainer类和ex04 pyrmont.startup.Bootstrap类。SimpleContainer类继承自org.apache.catalina.Container,这样就可以金额默认的connector进行关联。Bootstrap用于启动程序。
这里仅仅给出了invoke方法的实现。invoke方法会创建一个class loader,载入servlet类,调用servlet的service方法。与第三章中的ServletProcessor类的process方法类似。

Boorstrap类的main方法创建org.apache.catalina.connector.http.HttpConnector类和SimpleContainer类的实例,然后调用connector的setContainer方法将connector和container关联。接下来调用connector的initialize和start方法。
转载请注明出处【http://sishuok.com/forum/blogPost/list/0/4082.html】