Written by wanping7
from datetime import datetime
import numpy as np, pandas as pd
from datetime import datetime, timedelta
import seaborn as sns
import matplotlib.pyplot as plt
%matplotlib inline
import plotly.express as px
import plotly.graph_objects as go
from plotly.subplots import make_subplots
%config ZMQInteractiveShell.ast_node_interactivity='all'
import os, sys
import warnings
warnings.filterwarnings('ignore')
sns.set(rc={'figure.figsize':(13,7)})
sns.set_style("whitegrid")
PATH = "../data/"
结论
- 数据少量缺失(age/gender/city)
- age/gender同时为空其余有值的样本:81
- city为空其余有值的样本:22
- age为空其余有值的样本:2
- 不存在三个特征全部为空的样例
- 数据有异常(user_id存在三个用户各重复1次)
- 数据分布
- 男女比例=22:78
- 男性年龄等级由高到低前6(90%+):5->4->7->6->2->3
- 女性年龄等级由高到低前6(90%+):4->5->2->3->7->6
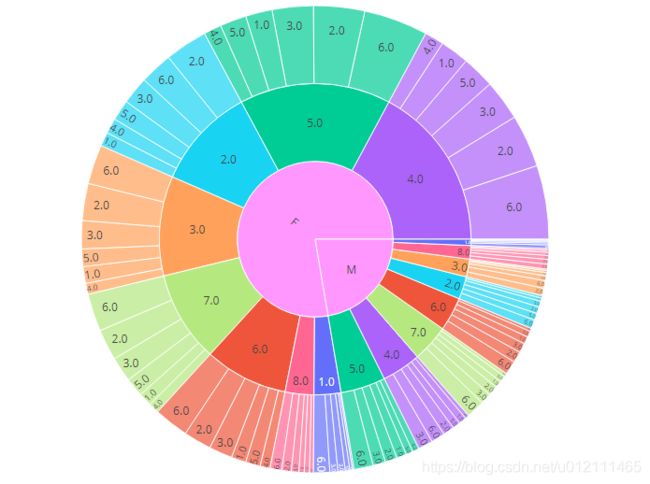
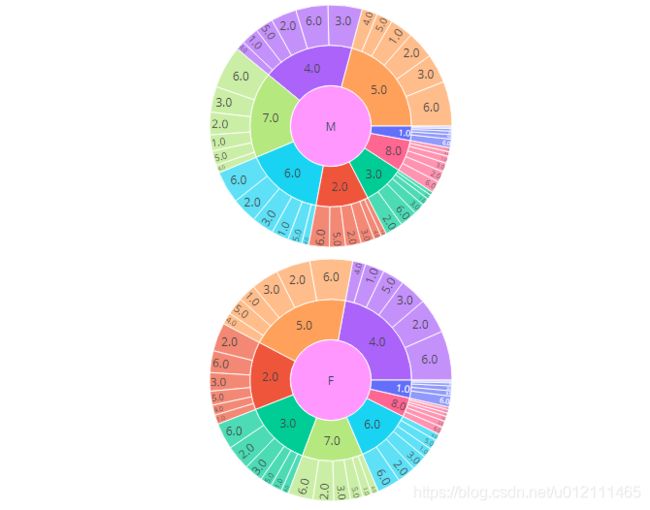
- 男性不同年龄之间的地域分布差异较大
- 女性不同年龄之间的地域分布差异较小
- 男女相同年龄之间的地域分布部分存在差异
TRAIN_PATH = PATH + "underexpose_train/"
用户特征
- underexpose_user_feat.csv
- user_id
- user_age_level
- user_gender
- user_city_level
1 缺失情况
user_feat = pd.read_csv(TRAIN_PATH + "underexpose_user_feat.csv", header=None,
names=["user_id", "user_age_level", "user_gender", "user_city_level"])
na_sta = pd.DataFrame(user_feat.isna().sum(), columns=["nan_num"])
na_sta["nan_percent(%)"] = na_sta["nan_num"]/user_feat.shape[0]
print("=======================================================>缺失情况:")
na_sta
print("=======================================================>带空值的行数:", user_feat.isnull().T.any().sum())
print("=======================================================>带空值的详情:")
print("========> age/gender/city 同时为空:", user_feat[(user_feat.user_age_level.isnull()) &
(user_feat.user_gender.isnull()) & (user_feat.user_city_level.isnull())].shape[0])
print("========> age/gender 同时为空:", user_feat[(user_feat.user_age_level.isnull()) &
(user_feat.user_gender.isnull())].shape[0])
print("========> city 为空其余特征有值:", user_feat[~(user_feat.user_age_level.isnull()) &
~(user_feat.user_gender.isnull()) & (user_feat.user_city_level.isnull())].shape[0])
print("========> age 为空其余特征有值:", user_feat[(user_feat.user_age_level.isnull()) &
~(user_feat.user_gender.isnull()) & ~(user_feat.user_city_level.isnull())].shape[0])
print("=======================================================>数据预览:")
user_feat.head(2)
=======================================================>缺失情况:
|
nan_num |
nan_percent(%) |
| user_id |
0 |
0.000000 |
| user_age_level |
83 |
0.012226 |
| user_gender |
81 |
0.011931 |
| user_city_level |
22 |
0.003241 |
=======================================================>带空值的行数: 105
=======================================================>带空值的详情:
========> age/gender/city 同时为空: 0
========> age/gender 同时为空: 81
========> city 为空其余特征有值: 22
========> age 为空其余特征有值: 2
=======================================================>数据预览:
|
user_id |
user_age_level |
user_gender |
user_city_level |
| 0 |
17 |
8.0 |
M |
4.0 |
| 1 |
26 |
7.0 |
M |
2.0 |
2 用户重复
print("===================================>查看用户id数:")
print("================> 未去重用户数:", user_feat.shape[0])
print("================> 去重用户数: ", pd.unique(user_feat.user_id).shape[0])
print("===================================>查看重复id用户:")
user_feat.user_id.value_counts()[user_feat.user_id.value_counts()>1]
print("===================================>取出重复用户id的数据:")
user_feat[(user_feat.user_id == 32152) | (user_feat.user_id == 23453) | (user_feat.user_id == 14818)]
===================================>查看用户id数:
================> 未去重用户数: 6789
================> 去重用户数: 6786
===================================>查看重复id用户:
32152 2
23453 2
14818 2
Name: user_id, dtype: int64
===================================>取出重复用户id的数据:
|
user_id |
user_age_level |
user_gender |
user_city_level |
| 1466 |
14818 |
3.0 |
M |
3.0 |
| 1467 |
14818 |
2.0 |
M |
3.0 |
| 5733 |
23453 |
5.0 |
F |
2.0 |
| 5734 |
23453 |
5.0 |
F |
5.0 |
| 6513 |
32152 |
1.0 |
F |
6.0 |
| 6514 |
32152 |
2.0 |
F |
6.0 |
3 数据分布
性别与年龄
age_agg = user_feat.user_age_level.value_counts().reset_index()
age_agg.columns = ["user_age_level", "count_"]
gender_agg = user_feat.user_gender.value_counts().reset_index()
gender_agg.columns = ["user_gender", "count_"]
age_gender_agg = user_feat[["user_age_level", "user_gender"]].groupby(["user_age_level", "user_gender"]).size().reset_index()
age_gender_agg.columns = ["user_age_level", "user_gender", "count_"]
fig = make_subplots(rows=2, cols=2, specs=[[{'type':'domain'}, {'type':'domain'}],
[{'type':'domain'}, {'type':'domain'}]])
x = fig.add_trace(go.Pie(values=age_agg.count_.values, labels=age_agg.user_age_level.values, title='年龄等级'), 1, 1)
x = fig.add_trace(go.Pie(values=gender_agg.count_.values, labels=gender_agg.user_gender.values, title='性别'), 1, 2)
x = fig.add_trace(go.Pie(values=age_gender_agg[age_gender_agg.user_gender=="M"].count_.values,
labels=age_gender_agg[age_gender_agg.user_gender=="M"].user_age_level.values,
title='男性年龄等级'), 2, 1)
x = fig.add_trace(go.Pie(values=age_gender_agg[age_gender_agg.user_gender=="F"].count_.values,
labels=age_gender_agg[age_gender_agg.user_gender=="F"].user_age_level.values,
title='女性年龄等级'), 2, 2)
x = fig.update_traces(hole=.4, textposition='inside', textinfo='percent+label')
y = fig.update_layout(
grid= dict(columns=2, rows=2),
autosize=False,
width=700,
height=400,
margin = dict(t=0, l=200, r=0, b=0)
)
fig.show()

性别、年龄与城市
age_gender_city_agg = user_feat[["user_age_level", "user_gender", "user_city_level"]
].groupby(["user_age_level", "user_gender", "user_city_level"]).size().reset_index()
age_gender_city_agg.columns = ["user_age_level", "user_gender", "user_city_level", "count_"]
age_gender_city_agg["user_age_level"] = age_gender_city_agg["user_age_level"].astype(str)
age_gender_city_agg["user_city_level"] = age_gender_city_agg["user_city_level"].astype(str)
agg_genderM_city_agg = age_gender_city_agg[age_gender_city_agg.user_gender=="M"]
agg_genderF_city_agg = age_gender_city_agg[age_gender_city_agg.user_gender=="F"]
fig1 = px.sunburst(agg_genderM_city_agg, path=["user_gender", 'user_age_level', 'user_city_level'],
values='count_',
color='user_age_level')
fig1.update_layout(
grid= dict(columns=2, rows=1),
autosize=False,
width=800,
height=250,
margin = dict(t=0, l=200, r=0, b=0)
)
fig2 = px.sunburst(agg_genderF_city_agg, path=["user_gender", 'user_age_level', 'user_city_level'],
values='count_',
color='user_age_level')
fig2.update_layout(
grid= dict(columns=2, rows=1),
autosize=False,
width=800,
height=250,
margin = dict(t=0, l=200, r=0, b=0)
)
整体分布
fig3 = px.sunburst(age_gender_city_agg, path=["user_gender", 'user_age_level', 'user_city_level'],
values='count_',
color='user_age_level')
fig3.update_layout(
grid= dict(columns=2, rows=1),
autosize=False,
width=800,
height=500,
margin = dict(t=0, l=200, r=0, b=0)
)