Python学习_100Days
第16-20天--Python进阶
- 数据机构和算法
- 引言
- 排序算法(选择、冒泡和归并)和查找算法(顺序和折半)
- 排序算法
- 使用生成式(推导式)语法
- 嵌套的列表
- heapq、itertools等的用法
- collection工具下的模块类
- 常用算法
- 函数的使用方式
- 将函数视为“一等公民”
- 高阶函数的用法(`filter`、`map`以及它们的替代品)
- 位置参数、可变参数、关键字参数、命名关键字参数
- 参数的元信息(代码可读性问题)
- 匿名函数和内联函数的用法(`lambda`函数)
- 闭包和作用域问题
- 装饰器函数(使用装饰器和取消装饰器)
- 面向对象相关知识
- 面向对象三大支柱:继承,封装和多态
- 迭代器和生成器
- 并发编程
数据机构和算法
引言
- 算法:解决问题的方法和步骤
- 评价算法的好坏:渐进时间复杂度和渐进空间复杂度
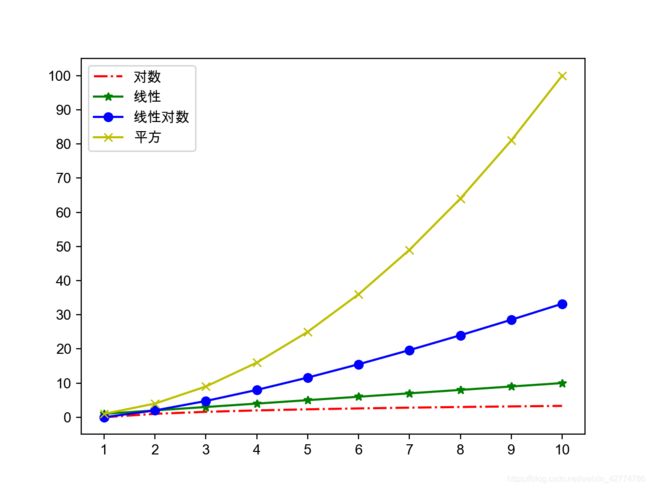
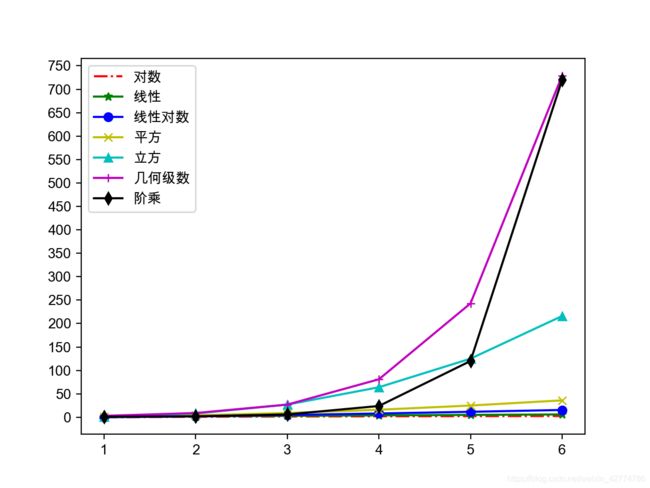
- 渐进时间复杂度的大O标记:
- 常量时间复杂度-布隆过滤器/哈希存储
- 对数时间复杂度-折半查找(二分查找)
- 线性时间复杂度-顺序查找/桶排序
- 对数线性时间复杂度-高级排序算法(归并排序、快速排序)
- 平方时间复杂度-简单排序算法(选择排序、插入排序、冒泡排序)
- 立方时间复杂度-Floyd算法 / 矩阵乘法运算
- 几何级数时间复杂度-汉诺塔
- 阶乘时间复杂度-旅行经销商问题-NP问题
排序算法(选择、冒泡和归并)和查找算法(顺序和折半)
排序算法
- 简单选择排序
def select_sort(origin_items, comp=lambda x, y: x < y):
"""简单选择排序"""
items = origin_items[:]
for i in range(len(items) - 1):
min_index = i
for j in range(i + 1, len(items)):
if comp(items[j], items[min_index]):
min_index = j
items[i], items[min_index] = items[min_index], items[i]
return items**注:lambda函数的使用:参考关于Python中的lambda,这篇阅读量10万+的文章可能是你见过的最完整的讲解
2. 冒泡排序
def bubble_sort(origin_items, comp=lambda x, y: x > y):
"""高质量冒泡排序(搅拌排序)"""
items = origin_items[:]
for i in range(len(items) - 1):
swapped = False
for j in range(i, len(items) - 1 - i):
if comp(items[j], items[j + 1]):
items[j], items[j + 1] = items[j + 1], items[j]
swapped = True
if swapped:
swapped = False
for j in range(len(items) - 2 - i, i, -1):
if comp(items[j - 1], items[j]):
items[j], items[j - 1] = items[j - 1], items[j]
swapped = True
if not swapped:
break
return items- 归并排序
def merge_sort(items, comp=lambda x, y: x <= y):
"""归并排序(分治法)"""
if len(items) < 2:
return items[:]
mid = len(items) // 2
left = merge_sort(items[:mid], comp)
right = merge_sort(items[mid:], comp)
return merge(left, right, comp)
def merge(items1, items2, comp):
"""合并(将两个有序的列表合并成一个有序的列表)"""
items = []
index1, index2 = 0, 0
while index1 < len(items1) and index2 < len(items2):
if comp(items1[index1], items2[index2]):
items.append(items1[index1])
index1 += 1
else:
items.append(items2[index2])
index2 += 1
items += items1[index1:]
items += items2[index2:]
return items使用生成式(推导式)语法
prices = {
'AAPL': 191.88,
'GOOG': 1186.96,
'IBM': 149.24,
'ORCL': 48.44,
'ACN': 166.89,
'FB': 208.09,
'SYMC': 21.29
}
# 用股票价格大于100元的股票构造一个新的字典
prices2 = {key: value for key, value in prices.items() if value > 100}
print(prices2)注:
- 生成式语法可以用来生成列表、集合和字典。
- 列表推导式是将所有的值一次性加载到内存中
生成器是将列表推导式的[]改成(),不会将所有的值一次性加载到内存中,延迟计算,一次返回一个结果,它不会一次生成所有的结果,这对大数据量处理,非常有用
嵌套的列表
names = ['关羽', '张飞', '赵云', '马超', '黄忠']
courses = ['语文', '数学', '英语']
# 录入五个学生三门课程的成绩
# 错误 - 参考http://pythontutor.com/visualize.html#mode=edit
# scores = [[None] * len(courses)] * len(names)
scores = [[None] * len(courses) for _ in range(len(names))]
for row, name in enumerate(names):
for col, course in enumerate(courses):
scores[row][col] = float(input(f'请输入{name}的{course}成绩: '))
print(scores)heapq、itertools等的用法
"""
从列表中找出最大的或最小的N个元素
堆结构(大根堆/小根堆)
"""
import heapq
list1 = [34, 25, 12, 99, 87, 63, 58, 78, 88, 92]
list2 = [
{'name': 'IBM', 'shares': 100, 'price': 91.1},
{'name': 'AAPL', 'shares': 50, 'price': 543.22},
{'name': 'FB', 'shares': 200, 'price': 21.09},
{'name': 'HPQ', 'shares': 35, 'price': 31.75},
{'name': 'YHOO', 'shares': 45, 'price': 16.35},
{'name': 'ACME', 'shares': 75, 'price': 115.65}
]
print(heapq.nlargest(3, list1))
print(heapq.nsmallest(3, list1))
print(heapq.nlargest(2, list2, key=lambda x: x['price']))
print(heapq.nlargest(2, list2, key=lambda x: x['shares']))"""
迭代工具 - 排列 / 组合 / 笛卡尔积
"""
import itertools
itertools.permutations('ABCD')
itertools.combinations('ABCDE', 3)
itertools.product('ABCD', '123')collection工具下的模块类
"""
找出序列中出现次数最多的元素
"""
from collections import Counter
words = [
'look', 'into', 'my', 'eyes', 'look', 'into', 'my', 'eyes',
'the', 'eyes', 'the', 'eyes', 'the', 'eyes', 'not', 'around',
'the', 'eyes', "don't", 'look', 'around', 'the', 'eyes',
'look', 'into', 'my', 'eyes', "you're", 'under'
]
counter = Counter(words)
print(counter.most_common(3))常用算法
- 穷举法 - 又称为暴力破解法,对所有的可能性进行验证,直到找到正确答案。
- 贪婪法 - 在对问题求解时,总是做出在当前看来最好的选择,不追求最优解,快速找到满意解。
- 把一个复杂的问题分成两个或更多的相同或相似的子问题,再把子问题分成更小的子问题,直到可以直接求解的程度,最后将子问题的解进行合并得到原问题的解。
- 回溯法 - 回溯法又称为试探法,按选优条件向前搜索,当搜索到某一步发现原先选择并不优或达不到目标时,就退回一步重新选择。
- 动态规划 - 基本思想也是将待求解问题分解成若干个子问题,先求解并保存这些子问题的解,避免产生大量的重复运算。
- 穷举法例子:百钱百鸡和五人分鱼。
# 公鸡5元一只 母鸡3元一只 小鸡1元三只
# 用100元买100只鸡 问公鸡/母鸡/小鸡各多少只
for x in range(20):
for y in range(33):
z = 100 - x - y
if 5 * x + 3 * y + z // 3 == 100 and z % 3 == 0:
print(x, y, z)
# A、B、C、D、E五人在某天夜里合伙捕鱼 最后疲惫不堪各自睡觉
# 第二天A第一个醒来 他将鱼分为5份 扔掉多余的1条 拿走自己的一份
# B第二个醒来 也将鱼分为5份 扔掉多余的1条 拿走自己的一份
# 然后C、D、E依次醒来也按同样的方式分鱼 问他们至少捕了多少条鱼
fish = 6
while True:
total = fish
enough = True
for _ in range(5):
if (total - 1) % 5 == 0:
total = (total - 1) // 5 * 4
else:
enough = False
break
if enough:
print(fish)
break
fish += 5- 贪婪法例子:假设小偷有一个背包,最多能装20公斤赃物,他闯入一户人家,发现如下表所示的物品。很显然,他不能把所有物品都装进背包,所以必须确定拿走哪些物品,留下哪些物品。
| 名称 | 价格(美元) | 重量(kg) |
|---|---|---|
| 电脑 | 200 | 20 |
| 收音机 | 20 | 4 |
| 钟 | 175 | 10 |
| 花瓶 | 50 | 2 |
| 书 | 10 | 1 |
| 油画 | 90 | 9 |
"""
贪婪法:在对问题求解时,总是做出在当前看来是最好的选择,不追求最优解,快速找到满意解。
输入:
20 6
电脑 200 20
收音机 20 4
钟 175 10
花瓶 50 2
书 10 1
油画 90 9
"""
class Thing(object):
"""物品"""
def __init__(self, name, price, weight):
self.name = name
self.price = price
self.weight = weight
@property
def value(self):
"""价格重量比"""
return self.price / self.weight
def input_thing():
"""输入物品信息"""
#input() 接收多个用户输入需要与split()结合使用
#str.split(str="", num=string.count(str)) # str是分隔符(默认为所有的空字符,包括空格、换行(\n)、制表符(\t)等),num是分隔次数
name_str, price_str, weight_str = input().split()
return name_str, int(price_str), int(weight_str)
def main():
"""主函数"""
max_weight, num_of_things = map(int, input().split())
all_things = []
for _ in range(num_of_things):
all_things.append(Thing(*input_thing()))
all_things.sort(key=lambda x: x.value, reverse=True)
total_weight = 0
total_price = 0
for thing in all_things:
if total_weight + thing.weight <= max_weight:
print(f'小偷拿走了{thing.name}')
total_weight += thing.weight
total_price += thing.price
print(f'总价值: {total_price}美元')
if __name__ == '__main__':
main()说明:
- input() 接收多个用户输入需要与split()结合使用;str.split(str="", num=string.count(str)) # str是分隔符(默认为所有的空字符,包括空格、换行(\n)、制表符(\t)等),num是分隔次数
- Python内置高阶函数map的用法
- python*的用法
- 分冶法例子:快速排序
"""
快速排序 - 选择枢轴对元素进行划分,左边都比枢轴小右边都比枢轴大
"""
def quick_sort(origin_items, comp=lambda x, y: x <= y):
items = origin_items[:]
_quick_sort(items, 0, len(items) - 1, comp)
return items
def _quick_sort(items, start, end, comp):
if start < end:
pos = _partition(items, start, end, comp)
_quick_sort(items, start, pos - 1, comp)
_quick_sort(items, pos + 1, end, comp)
def _partition(items, start, end, comp):
pivot = items[end]
i = start - 1
for j in range(start, end):
if comp(items[j], pivot):
i += 1
items[i], items[j] = items[j], items[i]
items[i + 1], items[end] = items[end], items[i + 1]
return i + 1- 回溯法例子:骑士巡逻。
"""
递归回溯法:叫称为试探法,按选优条件向前搜索,当搜索到某一步,发现原先选择并不优或达不到目标时,就退回一步重新选择,比较经典的问题包括骑士巡逻、八皇后和迷宫寻路等。
"""
import sys
import time
SIZE = 5
total = 0
def print_board(board):
for row in board:
for col in row:
print(str(col).center(4), end='')
print()
def patrol(board, row, col, step=1):
if row >= 0 and row < SIZE and \
col >= 0 and col < SIZE and \
board[row][col] == 0:
board[row][col] = step
if step == SIZE * SIZE:
global total
total += 1
print(f'第{total}种走法: ')
print_board(board)
patrol(board, row - 2, col - 1, step + 1)
patrol(board, row - 1, col - 2, step + 1)
patrol(board, row + 1, col - 2, step + 1)
patrol(board, row + 2, col - 1, step + 1)
patrol(board, row + 2, col + 1, step + 1)
patrol(board, row + 1, col + 2, step + 1)
patrol(board, row - 1, col + 2, step + 1)
patrol(board, row - 2, col + 1, step + 1)
board[row][col] = 0
def main():
board = [[0] * SIZE for _ in range(SIZE)]
patrol(board, SIZE - 1, SIZE - 1)
if __name__ == '__main__':
main()- 动态规划:例一斐波那契数列(不使用动态规划将是几何级数复杂度)
"""
动态规划 - 适用于有重叠子问题和最优子结构性质的问题
使用动态规划方法所耗时间往往远少于朴素解法(用空间换取时间)
"""
def fib(num, temp={}):
"""用递归计算Fibonacci数"""
if num in (1, 2):
return 1
try:
return temp[num]
except KeyError:
temp[num] = fib(num - 1) + fib(num - 2)
return temp[num]- 动态规划例子2:子列表元素之和的最大值。(使用动态规划可以避免二重循环)
说明:子列表指的是列表中索引(下标)连续的元素构成的列表;列表中的元素是int类型,可能包含正整数、0、负整数;程序输入列表中的元素,输出子列表元素求和的最大值,例如:
输入:1 -2 3 5 -3 2
输出:8
输入:0 -2 3 5 -1 2
输出:9
输入:-9 -2 -3 -5 -3
输出:-2
def main():
items = list(map(int, input().split()))
size = len(items)
overall, partial = {}, {}
overall[size - 1] = partial[size - 1] = items[size - 1]
for i in range(size - 2, -1, -1):
partial[i] = max(items[i], partial[i + 1] + items[i])
overall[i] = max(partial[i], overall[i + 1])
print(overall[0])
if __name__ == '__main__':
main()函数的使用方式
将函数视为“一等公民”
- 函数可以赋值给变量
- 函数可以作为函数的参数
- 函数可以作为函数的返回值
高阶函数的用法(filter、map以及它们的替代品)
items1 = list(map(lambda x: x ** 2, filter(lambda x: x % 2, range(1, 10))))
items2 = [x ** 2 for x in range(1, 10) if x % 2]位置参数、可变参数、关键字参数、命名关键字参数
参数的元信息(代码可读性问题)
匿名函数和内联函数的用法(lambda函数)
闭包和作用域问题
-
Python搜索变量的LEGB顺序(Local --> Embedded --> Global --> Built-in)
-
global和nonlocal关键字的作用
global:声明或定义全局变量(要么直接使用现有的全局作用域的变量,要么定义一个变量放到全局作用域)。
nonlocal:声明使用嵌套作用域的变量(嵌套作用域必须存在该变量,否则报错)。
装饰器函数(使用装饰器和取消装饰器)
例子:输出函数执行时间的装饰器。
def record_time(func):
"""自定义装饰函数的装饰器"""
@wraps(func)
def wrapper(*args, **kwargs):
start = time()
result = func(*args, **kwargs)
print(f'{func.__name__}: {time() - start}秒')
return result
return wrapper如果装饰器不希望跟print函数耦合,可以编写带参数的装饰器。
from functools import wraps
from time import time
def record(output):
"""自定义带参数的装饰器"""
def decorate(func):
@wraps(func)
def wrapper(*args, **kwargs):
start = time()
result = func(*args, **kwargs)
output(func.__name__, time() - start)
return result
return wrapper
return decoratefrom functools import wraps
from time import time
class Record():
"""自定义装饰器类(通过__call__魔术方法使得对象可以当成函数调用)"""
def __init__(self, output):
self.output = output
def __call__(self, func):
@wraps(func)
def wrapper(*args, **kwargs):
start = time()
result = func(*args, **kwargs)
self.output(func.__name__, time() - start)
return result
return wrapper说明:由于对带装饰功能的函数添加了@wraps装饰器,可以通过func.__wrapped__方式获得被装饰之前的函数或类来取消装饰器的作用。
例子:用装饰器来实现单例模式。
from functools import wraps
def singleton(cls):
"""装饰类的装饰器"""
instances = {}
@wraps(cls)
def wrapper(*args, **kwargs):
if cls not in instances:
instances[cls] = cls(*args, **kwargs)
return instances[cls]
return wrapper
@singleton
class President():
"""总统(单例类)"""
pass说明:上面的代码中用到了闭包(closure),不知道你是否已经意识到了。还没有一个小问题就是,上面的代码并没有实现线程安全的单例,如果要实现线程安全的单例应该怎么做呢?
from functools import wraps
from threading import Lock
def singleton(cls):
"""线程安全的单例装饰器"""
instances = {}
locker = Lock()
@wraps(cls)
def wrapper(*args, **kwargs):
if cls not in instances:
with locker:
if cls not in instances:
instances[cls] = cls(*args, **kwargs)
return instances[cls]
return wrapper面向对象相关知识
面向对象三大支柱:继承,封装和多态
- 工资结算系统
"""
月薪结算系统 - 部门经理每月15000 程序员每小时200 销售员1800底薪加销售额5%提成
"""
from abc import ABCMeta, abstractmethod
class Employee(metaclass=ABCMeta):
"""员工(抽象类)"""
def __init__(self, name):
self.name = name
@abstractmethod
def get_salary(self):
"""结算月薪(抽象方法)"""
pass
class Manager(Employee):
"""部门经理"""
def get_salary(self):
return 15000.0
class Programmer(Employee):
"""程序员"""
def __init__(self, name, working_hour=0):
self.working_hour = working_hour
super().__init__(name)
def get_salary(self):
return 200.0 * self.working_hour
class Salesman(Employee):
"""销售员"""
def __init__(self, name, sales=0.0):
self.sales = sales
super().__init__(name)
def get_salary(self):
return 1800.0 + self.sales * 0.05
class EmployeeFactory():
"""创建员工的工厂(工厂模式 - 通过工厂实现对象使用者和对象之间的解耦合)"""
@staticmethod
def create(emp_type, *args, **kwargs):
"""创建员工"""
emp_type = emp_type.upper()
emp = None
if emp_type == 'M':
emp = Manager(*args, **kwargs)
elif emp_type == 'P':
emp = Programmer(*args, **kwargs)
elif emp_type == 'S':
emp = Salesman(*args, **kwargs)
return emp
def main():
"""主函数"""
emps = [
EmployeeFactory.create('M', '曹操'),
EmployeeFactory.create('P', '荀彧', 120),
EmployeeFactory.create('P', '郭嘉', 85),
EmployeeFactory.create('S', '典韦', 123000),
]
for emp in emps:
print('%s: %.2f元' % (emp.name, emp.get_salary()))
if __name__ == '__main__':
main()
- 类与类之间的关系
- is-a关系:继承
- has-a关系:关联 / 聚合 / 合成
- use-a关系:依赖
"""
经验:符号常量总是优于字面常量,枚举类型是定义符号常量的最佳选择
"""
from enum import Enum, unique
import random
@unique
class Suite(Enum):
"""花色"""
SPADE, HEART, CLUB, DIAMOND = range(4)
def __lt__(self, other):
return self.value < other.value
class Card():
"""牌"""
def __init__(self, suite, face):
"""初始化方法"""
self.suite = suite
self.face = face
def show(self):
"""显示牌面"""
suites = ['♠️', '♥️', '♣️', '♦️']
faces = ['', 'A', '2', '3', '4', '5', '6', '7', '8', '9', '10', 'J', 'Q', 'K']
return f'{suites[self.suite.value]} {faces[self.face]}'
def __str__(self):
return self.show()
def __repr__(self):
return self.show()
class Poker():
"""扑克"""
def __init__(self):
self.index = 0
self.cards = [Card(suite, face)
for suite in Suite
for face in range(1, 14)]
def shuffle(self):
"""洗牌(随机乱序)"""
random.shuffle(self.cards)
self.index = 0
def deal(self):
"""发牌"""
card = self.cards[self.index]
self.index += 1
return card
@property
def has_more(self):
return self.index < len(self.cards)
class Player():
"""玩家"""
def __init__(self, name):
self.name = name
self.cards = []
def get_one(self, card):
"""摸一张牌"""
self.cards.append(card)
def sort(self, comp=lambda card: (card.suite, card.face)):
"""整理手上的牌"""
self.cards.sort(key=comp)
def main():
"""主函数"""
poker = Poker()
poker.shuffle()
players = [Player('东邪'), Player('西毒'), Player('南帝'), Player('北丐')]
while poker.has_more:
for player in players:
player.get_one(poker.deal())
for player in players:
player.sort()
print(player.name, end=': ')
print(player.cards)
if __name__ == '__main__':
main()说明:上面的代码中使用了Emoji字符来表示扑克牌的四种花色,在某些不支持Emoji字符的系统上可能无法显示。
- 对象的复制(深复制/深拷贝/深度克隆和浅复制/浅拷贝/影子克隆)
- 垃圾回收、循环引用和弱引用
Python使用了自动化内存管理,这种管理机制以引用计数为基础,同时也引入了标记-清除和分代收集两种机制为辅的策略。
typedef struct_object {
/* 引用计数 */
int ob_refcnt;
/* 对象指针 */
struct_typeobject *ob_type;
} PyObject;
/* 增加引用计数的宏定义 */
#define Py_INCREF(op) ((op)->ob_refcnt++)
/* 减少引用计数的宏定义 */
#define Py_DECREF(op) \ //减少计数
if (--(op)->ob_refcnt != 0) \
; \
else \
__Py_Dealloc((PyObject *)(op))
导致引用计数+1的情况:
- 对象被创建,例如a = 23
- 对象被引用,例如b = a
- 对象被作为参数,传入到一个函数中,例如f(a)
- 对象作为一个元素,存储在容器中,例如list1 = [a, a]
导致引用计数-1的情况:
- 对象的别名被显式销毁,例如del a
- 对象的别名被赋予新的对象,例如a = 24
- 一个对象离开它的作用域,例如f函数执行完毕时,f函数中的局部变量(全局变量不会)
- 对象所在的容器被销毁,或从容器中删除对象
引用计数可能会导致循环引用问题,而循环引用会导致内存泄露,如下面的代码所示。为了解决这个问题,Python中引入了“标记-清除”和“分代收集”。在创建一个对象的时候,对象被放在第一代中,如果在第一代的垃圾检查中对象存活了下来,该对象就会被放到第二代中,同理在第二代的垃圾检查中对象存活下来,该对象就会被放到第三代中。
# 循环引用会导致内存泄露 - Python除了引用技术还引入了标记清理和分代回收
# 在Python 3.6以前如果重写__del__魔术方法会导致循环引用处理失效
# 如果不想造成循环引用可以使用弱引用
list1 = []
list2 = []
list1.append(list2)
list2.append(list1)
以下情况会导致垃圾回收:
- 调用gc.collect()
- gc模块的计数器达到阀值
- 程序退出
如果循环引用中两个对象都定义了__del__方法,gc模块不会销毁这些不可达对象,因为gc模块不知道应该先调用哪个对象的__del__方法,这个问题在Python 3.6中得到了解决。
也可以通过weakref模块构造弱引用的方式来解决循环引用的问题。
魔法属性和方法(请参考《Python魔法方法指南》)
有几个小问题请大家思考:
- 自定义的对象能不能使用运算符做运算?
- 自定义的对象能不能放到set中?能去重吗?
- 自定义的对象能不能作为dict的键?
- 自定义的对象能不能使用上下文语法?
- 混入
自定义字典限制只有在指定的key不存在时才能在字典中设置键值对。
class SetOnceMappingMixin:
"""自定义混入类"""
__slots__ = ()
def __setitem__(self, key, value):
if key in self:
raise KeyError(str(key) + ' already set')
return super().__setitem__(key, value)
class SetOnceDict(SetOnceMappingMixin, dict):
"""自定义字典"""
pass
my_dict= SetOnceDict()
try:
my_dict['username'] = 'jackfrued'
my_dict['username'] = 'hellokitty'
except KeyError:
pass
print(my_dict)
- 元编程和元类
实现单例模式
import threading
class SingletonMeta(type):
"""自定义元类"""
def __init__(cls, *args, **kwargs):
cls.__instance = None
cls.__lock = threading.Lock()
super().__init__(*args, **kwargs)
def __call__(cls, *args, **kwargs):
if cls.__instance is None:
with cls.__lock:
if cls.__instance is None:
cls.__instance = super().__call__(*args, **kwargs)
return cls.__instance
class President(metaclass=SingletonMeta):
"""总统(单例类)"""
pass
- 面向对象设计原则
- 单一职责原则 (SRP)- 一个类只做该做的事情(类的设计要高内聚)
- 开闭原则 (OCP)- 软件实体应该对扩展开发对修改关闭
- 依赖倒转原则(DIP)- 面向抽象编程(在弱类型语言中已经被弱化)
- 里氏替换原则(LSP) - 任何时候可以用子类对象替换掉父类对象
- 接口隔离原则(ISP)- 接口要小而专不要大而全(Python中没有接口的概念)
- 合成聚合复用原则(CARP) - 优先使用强关联关系而不是继承关系复用代码
- 最少知识原则(迪米特法则,LoD)- 不要给没有必然联系的对象发消息
说明:上面加粗的字母放在一起称为面向对象的SOLID原则。
- GoF设计模式
- 创建型模式:单例、工厂、建造者、原型
- 结构型模式:适配器、门面(外观)、代理
- 行为型模式:迭代器、观察者、状态、策略
例:可插拔的哈希算法
class StreamHasher():
"""哈希摘要生成器(策略模式)"""
def __init__(self, alg='md5', size=4096):
self.size = size
alg = alg.lower()
self.hasher = getattr(__import__('hashlib'), alg.lower())()
def __call__(self, stream):
return self.to_digest(stream)
def to_digest(self, stream):
"""生成十六进制形式的摘要"""
for buf in iter(lambda: stream.read(self.size), b''):
self.hasher.update(buf)
return self.hasher.hexdigest()
def main():
"""主函数"""
hasher1 = StreamHasher()
with open('Python-3.7.1.tgz', 'rb') as stream:
print(hasher1.to_digest(stream))
hasher2 = StreamHasher('sha1')
with open('Python-3.7.1.tgz', 'rb') as stream:
print(hasher2(stream))
if __name__ == '__main__':
main()
迭代器和生成器
-
和迭代器相关的魔术方法(
__iter__和__next__) -
两种创建生成器的方式(生成器表达式和
yield关键字)
def fib(num):
"""生成器"""
a, b = 0, 1
for _ in range(num):
a, b = b, a + b
yield a
class Fib(object):
"""迭代器"""
def __init__(self, num):
self.num = num
self.a, self.b = 0, 1
self.idx = 0
def __iter__(self):
return self
def __next__(self):
if self.idx < self.num:
self.a, self.b = self.b, self.a + self.b
self.idx += 1
return self.a
raise StopIteration()
并发编程
Python中实现并发编程的三种方案:多线程、多进程和异步I/O。并发编程的好处在于可以提升程序的执行效率以及改善用户体验;坏处在于并发的程序不容易开发和调试,同时对其他程序来说它并不友好。
- 多线程:Python中提供了Thread类并辅以Lock、Condition、Event、Semaphore和Barrier。Python中有GIL来防止多个线程同时执行本地字节码,这个锁对于CPython是必须的,因为CPython的内存管理并不是线程安全的,因为GIL的存在多线程并不能发挥CPU的多核特性。
"""
面试题:进程和线程的区别和联系?
进程 - 操作系统分配内存的基本单位 - 一个进程可以包含一个或多个线程
线程 - 操作系统分配CPU的基本单位
并发编程(concurrent programming)
1. 提升执行性能 - 让程序中没有因果关系的部分可以并发的执行
2. 改善用户体验 - 让耗时间的操作不会造成程序的假死
"""
import glob
import os
import threading
from PIL import Image
PREFIX = 'thumbnails'
def generate_thumbnail(infile, size, format='PNG'):
"""生成指定图片文件的缩略图"""
file, ext = os.path.splitext(infile)
file = file[file.rfind('/') + 1:]
outfile = f'{PREFIX}/{file}_{size[0]}_{size[1]}.{ext}'
img = Image.open(infile)
img.thumbnail(size, Image.ANTIALIAS)
img.save(outfile, format)
def main():
"""主函数"""
if not os.path.exists(PREFIX):
os.mkdir(PREFIX)
for infile in glob.glob('images/*.png'):
for size in (32, 64, 128):
# 创建并启动线程
threading.Thread(
target=generate_thumbnail,
args=(infile, (size, size))
).start()
if __name__ == '__main__':
main()
多个线程竞争资源的情况
"""
多线程程序如果没有竞争资源处理起来通常也比较简单
当多个线程竞争临界资源的时候如果缺乏必要的保护措施就会导致数据错乱
说明:临界资源就是被多个线程竞争的资源
"""
import time
import threading
from concurrent.futures import ThreadPoolExecutor
class Account(object):
"""银行账户"""
def __init__(self):
self.balance = 0.0
self.lock = threading.Lock()
def deposit(self, money):
# 通过锁保护临界资源
with self.lock:
new_balance = self.balance + money
time.sleep(0.001)
self.balance = new_balance
class AddMoneyThread(threading.Thread):
"""自定义线程类"""
def __init__(self, account, money):
self.account = account
self.money = money
# 自定义线程的初始化方法中必须调用父类的初始化方法
super().__init__()
def run(self):
# 线程启动之后要执行的操作
self.account.deposit(self.money)
def main():
"""主函数"""
account = Account()
# 创建线程池
pool = ThreadPoolExecutor(max_workers=10)
futures = []
for _ in range(100):
# 创建线程的第1种方式
# threading.Thread(
# target=account.deposit, args=(1, )
# ).start()
# 创建线程的第2种方式
# AddMoneyThread(account, 1).start()
# 创建线程的第3种方式
# 调用线程池中的线程来执行特定的任务
future = pool.submit(account.deposit, 1)
futures.append(future)
# 关闭线程池
pool.shutdown()
for future in futures:
future.result()
print(account.balance)
if __name__ == '__main__':
main()
修改上面的程序,启动5个线程向账户中存钱,5个线程从账户中取钱,取钱时如果余额不足就暂停线程进行等待。为了达到上述目标,需要对存钱和取钱的线程进行调度,在余额不足时取钱的线程暂停并释放锁,而存钱的线程将钱存入后要通知取钱的线程,使其从暂停状态被唤醒。可以使用threading模块的Condition来实现线程调度,该对象也是基于锁来创建的,代码如下所示:
"""
多个线程竞争一个资源 - 保护临界资源 - 锁(Lock/RLock)
多个线程竞争多个资源(线程数>资源数) - 信号量(Semaphore)
多个线程的调度 - 暂停线程执行/唤醒等待中的线程 - Condition
"""
from concurrent.futures import ThreadPoolExecutor
from random import randint
from time import sleep
import threading
class Account():
"""银行账户"""
def __init__(self, balance=0):
self.balance = balance
lock = threading.Lock()
self.condition = threading.Condition(lock)
def withdraw(self, money):
"""取钱"""
with self.condition:
while money > self.balance:
self.condition.wait()
new_balance = self.balance - money
sleep(0.001)
self.balance = new_balance
def deposit(self, money):
"""存钱"""
with self.condition:
new_balance = self.balance + money
sleep(0.001)
self.balance = new_balance
self.condition.notify_all()
def add_money(account):
while True:
money = randint(5, 10)
account.deposit(money)
print(threading.current_thread().name,
':', money, '====>', account.balance)
sleep(0.5)
def sub_money(account):
while True:
money = randint(10, 30)
account.withdraw(money)
print(threading.current_thread().name,
':', money, '<====', account.balance)
sleep(1)
def main():
account = Account()
with ThreadPoolExecutor(max_workers=10) as pool:
for _ in range(5):
pool.submit(add_money, account)
pool.submit(sub_money, account)
if __name__ == '__main__':
main()
- 多线程
多进程:多进程可以有效的解决GIL的问题,实现多进程主要的类是Process,其他辅助的类跟threading模块中的类似,进程间共享数据可以使用管道、套接字等,在multiprocessing模块中有一个Queue类,它基于管道和锁机制提供了多个进程共享的队列。下面是官方文档上关于多进程和进程池的一个示例。
"""
多进程和进程池的使用
多线程因为GIL的存在不能够发挥CPU的多核特性
对于计算密集型任务应该考虑使用多进程
time python3 example22.py
real 0m11.512s
user 0m39.319s
sys 0m0.169s
使用多进程后实际执行时间为11.512秒,而用户时间39.319秒约为实际执行时间的4倍
这就证明我们的程序通过多进程使用了CPU的多核特性,而且这台计算机配置了4核的CPU
"""
import concurrent.futures
import math
PRIMES = [
1116281,
1297337,
104395303,
472882027,
533000389,
817504243,
982451653,
112272535095293,
112582705942171,
112272535095293,
115280095190773,
115797848077099,
1099726899285419
] * 5
def is_prime(n):
"""判断素数"""
if n % 2 == 0:
return False
sqrt_n = int(math.floor(math.sqrt(n)))
for i in range(3, sqrt_n + 1, 2):
if n % i == 0:
return False
return True
def main():
"""主函数"""
with concurrent.futures.ProcessPoolExecutor() as executor:
for number, prime in zip(PRIMES, executor.map(is_prime, PRIMES)):
print('%d is prime: %s' % (number, prime))
if __name__ == '__main__':
main()
说明:多线程和多进程的比较。
以下情况需要使用多线程:
- 程序需要维护许多共享的状态(尤其是可变状态),Python中的列表、字典、集合都是线程安全的,所以使用线程而不是进程维护共享状态的代价相对较小。
- 程序会花费大量时间在I/O操作上,没有太多并行计算的需求且不需占用太多的内存。
以下情况需要使用多进程:
- 程序执行计算密集型任务(如:字节码操作、数据处理、科学计算)。
- 程序的输入可以并行的分成块,并且可以将运算结果合并。
- 程序在内存使用方面没有任何限制且不强依赖于I/O操作(如:读写文件、套接字等)。
- 异步处理:从调度程序的任务队列中挑选任务,该调度程序以交叉的形式执行这些任务,我们并不能保证任务将以某种顺序去执行,因为执行顺序取决于队列中的一项任务是否愿意将CPU处理时间让位给另一项任务。异步任务通常通过多任务协作处理的方式来实现,由于执行时间和顺序的不确定,因此需要通过回调式编程或者future对象来获取任务执行的结果。Python 3通过asyncio模块和await和async关键字(在Python 3.7中正式被列为关键字)来支持异步处理。
"""
异步I/O - async / await
"""
import asyncio
def num_generator(m, n):
"""指定范围的数字生成器"""
yield from range(m, n + 1)
async def prime_filter(m, n):
"""素数过滤器"""
primes = []
for i in num_generator(m, n):
flag = True
for j in range(2, int(i ** 0.5 + 1)):
if i % j == 0:
flag = False
break
if flag:
print('Prime =>', i)
primes.append(i)
await asyncio.sleep(0.001)
return tuple(primes)
async def square_mapper(m, n):
"""平方映射器"""
squares = []
for i in num_generator(m, n):
print('Square =>', i * i)
squares.append(i * i)
await asyncio.sleep(0.001)
return squares
def main():
"""主函数"""
loop = asyncio.get_event_loop()
future = asyncio.gather(prime_filter(2, 100), square_mapper(1, 100))
future.add_done_callback(lambda x: print(x.result()))
loop.run_until_complete(future)
loop.close()
if __name__ == '__main__':
main()
说明:上面的代码使用get_event_loop函数获得系统默认的事件循环,通过gather函数可以获得一个future对象,future对象的add_done_callback可以添加执行完成时的回调函数,loop对象的run_until_complete方法可以等待通过future对象获得协程执行结果。
Python中有一个名为aiohttp的三方库,它提供了异步的HTTP客户端和服务器,这个三方库可以跟asyncio模块一起工作,并提供了对Future对象的支持。Python 3.6中引入了async和await来定义异步执行的函数以及创建异步上下文,在Python 3.7中它们正式成为了关键字。下面的代码异步的从5个URL中获取页面并通过正则表达式的命名捕获组提取了网站的标题。
import asyncio
import re
import aiohttp
PATTERN = re.compile(r'\(?P.*)\<\/title\>')
async def fetch_page(session, url):
async with session.get(url, ssl=False) as resp:
return await resp.text()
async def show_title(url):
async with aiohttp.ClientSession() as session:
html = await fetch_page(session, url)
print(PATTERN.search(html).group('title'))
def main():
urls = ('https://www.python.org/',
'https://git-scm.com/',
'https://www.jd.com/',
'https://www.taobao.com/',
'https://www.douban.com/')
loop = asyncio.get_event_loop()
tasks = [show_title(url) for url in urls]
loop.run_until_complete(asyncio.wait(tasks))
loop.close()
if __name__ == '__main__':
main()
</code></pre>
<p>说明:异步I/O与多进程的比较。<br> 当程序不需要真正的并发性或并行性,而是更多的依赖于异步处理和回调时,asyncio就是一种很好的选择。如果程序中有大量的等待与休眠时,也应该考虑asyncio,它很适合编写没有实时数据处理需求的Web应用服务器。</p>
<p>Python还有很多用于处理并行任务的三方库,例如:joblib、PyMP等。实际开发中,要提升系统的可扩展性和并发性通常有垂直扩展(增加单个节点的处理能力)和水平扩展(将单个节点变成多个节点)两种做法。可以通过消息队列来实现应用程序的解耦合,消息队列相当于是多线程同步队列的扩展版本,不同机器上的应用程序相当于就是线程,而共享的分布式消息队列就是原来程序中的Queue。消息队列(面向消息的中间件)的最流行和最标准化的实现是AMQP(高级消息队列协议),AMQP源于金融行业,提供了排队、路由、可靠传输、安全等功能,最著名的实现包括:Apache的ActiveMQ、RabbitMQ等。</p>
<p>要实现任务的异步化,可以使用名为Celery的三方库。Celery是Python编写的分布式任务队列,它使用分布式消息进行工作,可以基于RabbitMQ或Redis来作为后端的消息代理。</p>
</div>
</div>
</div>
</div>
</div>
<!--PC和WAP自适应版-->
<div id="SOHUCS" sid="1294268242449211392"></div>
<script type="text/javascript" src="/views/front/js/chanyan.js"></script>
<!-- 文章页-底部 动态广告位 -->
<div class="youdao-fixed-ad" id="detail_ad_bottom"></div>
</div>
<div class="col-md-3">
<div class="row" id="ad">
<!-- 文章页-右侧1 动态广告位 -->
<div id="right-1" class="col-lg-12 col-md-12 col-sm-4 col-xs-4 ad">
<div class="youdao-fixed-ad" id="detail_ad_1"> </div>
</div>
<!-- 文章页-右侧2 动态广告位 -->
<div id="right-2" class="col-lg-12 col-md-12 col-sm-4 col-xs-4 ad">
<div class="youdao-fixed-ad" id="detail_ad_2"></div>
</div>
<!-- 文章页-右侧3 动态广告位 -->
<div id="right-3" class="col-lg-12 col-md-12 col-sm-4 col-xs-4 ad">
<div class="youdao-fixed-ad" id="detail_ad_3"></div>
</div>
</div>
</div>
</div>
</div>
</div>
<div class="container">
<h4 class="pt20 mb15 mt0 border-top">你可能感兴趣的:(Python)</h4>
<div id="paradigm-article-related">
<div class="recommend-post mb30">
<ul class="widget-links">
<li><a href="/article/1950233451282100224.htm"
title="python 读excel每行替换_Python脚本操作Excel实现批量替换功能" target="_blank">python 读excel每行替换_Python脚本操作Excel实现批量替换功能</a>
<span class="text-muted">weixin_39646695</span>
<a class="tag" taget="_blank" href="/search/python/1.htm">python</a><a class="tag" taget="_blank" href="/search/%E8%AF%BBexcel%E6%AF%8F%E8%A1%8C%E6%9B%BF%E6%8D%A2/1.htm">读excel每行替换</a>
<div>Python脚本操作Excel实现批量替换功能大家好,给大家分享下如何使用Python脚本操作Excel实现批量替换。使用的工具Openpyxl,一个处理excel的python库,处理excel,其实针对的就是WorkBook,Sheet,Cell这三个最根本的元素~明确需求原始excel如下我们的目标是把下面excel工作表的sheet1表页A列的内容“替换我吧”批量替换为B列的“我用来替换的</div>
</li>
<li><a href="/article/1950208107430866944.htm"
title="python笔记14介绍几个魔法方法" target="_blank">python笔记14介绍几个魔法方法</a>
<span class="text-muted">抢公主的大魔王</span>
<a class="tag" taget="_blank" href="/search/python/1.htm">python</a><a class="tag" taget="_blank" href="/search/python/1.htm">python</a>
<div>python笔记14介绍几个魔法方法先声明一下各位大佬,这是我的笔记。如有错误,恳请指正。另外,感谢您的观看,谢谢啦!(1).__doc__输出对应的函数,类的说明文档print(print.__doc__)print(value,...,sep='',end='\n',file=sys.stdout,flush=False)Printsthevaluestoastream,ortosys.std</div>
</li>
<li><a href="/article/1950204954295726080.htm"
title="Anaconda 和 Miniconda:功能详解与选择建议" target="_blank">Anaconda 和 Miniconda:功能详解与选择建议</a>
<span class="text-muted">古月฿</span>
<a class="tag" taget="_blank" href="/search/python%E5%85%A5%E9%97%A8/1.htm">python入门</a><a class="tag" taget="_blank" href="/search/python/1.htm">python</a><a class="tag" taget="_blank" href="/search/conda/1.htm">conda</a>
<div>Anaconda和Miniconda详细介绍一、Anaconda的详细介绍1.什么是Anaconda?Anaconda是一个开源的包管理和环境管理工具,在数据科学、机器学习以及科学计算领域发挥着关键作用。它以Python和R语言为基础,为用户精心准备了大量预装库和工具,极大地缩短了搭建数据科学环境的时间。对于那些想要快速开展数据分析、模型训练等工作的人员来说,Anaconda就像是一个一站式的“数</div>
</li>
<li><a href="/article/1950204701714739200.htm"
title="环境搭建 | Python + Anaconda / Miniconda + PyCharm 的安装、配置与使用" target="_blank">环境搭建 | Python + Anaconda / Miniconda + PyCharm 的安装、配置与使用</a>
<span class="text-muted"></span>
<div>本文将分别介绍Python、Anaconda/Miniconda、PyCharm的安装、配置与使用,详细介绍Python环境搭建的全过程,涵盖Python、Pip、PythonLauncher、Anaconda、Miniconda、Pycharm等内容,以官方文档为参照,使用经验为补充,内容全面而详实。由于图片太多,就先贴一个无图简化版吧,详情请查看Python+Anaconda/Minicond</div>
</li>
<li><a href="/article/1950202938265759744.htm"
title="你竟然还在用克隆删除?Conda最新版rename命令全攻略!" target="_blank">你竟然还在用克隆删除?Conda最新版rename命令全攻略!</a>
<span class="text-muted">曦紫沐</span>
<a class="tag" taget="_blank" href="/search/Python%E5%9F%BA%E7%A1%80%E7%9F%A5%E8%AF%86/1.htm">Python基础知识</a><a class="tag" taget="_blank" href="/search/conda/1.htm">conda</a><a class="tag" taget="_blank" href="/search/%E8%99%9A%E6%8B%9F%E7%8E%AF%E5%A2%83%E7%AE%A1%E7%90%86/1.htm">虚拟环境管理</a>
<div>文章摘要Conda虚拟环境管理终于迎来革命性升级!本文揭秘Conda4.9+版本新增的rename黑科技,彻底告别传统“克隆+删除”的繁琐操作。从命令解析到实战案例,手把手教你如何安全高效地重命名Python虚拟环境,附带版本检测、环境迁移、故障排查等进阶技巧,助你提升开发效率10倍!一、颠覆认知:Conda居然自带重命名功能?很多开发者仍停留在“Conda无法直接重命名环境”的认知阶段,实际上自</div>
</li>
<li><a href="/article/1950202054706262016.htm"
title="centos7安装配置 Anaconda3" target="_blank">centos7安装配置 Anaconda3</a>
<span class="text-muted"></span>
<div>Anaconda是一个用于科学计算的Python发行版,Anaconda于Python,相当于centos于linux。下载[root@testsrc]#mwgethttps://mirrors.tuna.tsinghua.edu.cn/anaconda/archive/Anaconda3-5.2.0-Linux-x86_64.shBegintodownload:Anaconda3-5.2.0-L</div>
</li>
<li><a href="/article/1950202054219722752.htm"
title="Pandas:数据科学的超级瑞士军刀" target="_blank">Pandas:数据科学的超级瑞士军刀</a>
<span class="text-muted">科技林总</span>
<a class="tag" taget="_blank" href="/search/DeepSeek%E5%AD%A6AI/1.htm">DeepSeek学AI</a><a class="tag" taget="_blank" href="/search/%E4%BA%BA%E5%B7%A5%E6%99%BA%E8%83%BD/1.htm">人工智能</a>
<div>**——从零基础到高效分析的进化指南**###**一、Pandas诞生:数据革命的救世主****2010年前的数据分析噩梦**:```python#传统Python处理表格数据data=[]forrowincsv_file:ifrow[3]>100androw[2]=="China":data.append(float(row[5])#代码冗长易错!```**核心痛点**:-Excel处理百万行崩</div>
</li>
<li><a href="/article/1950195876991397888.htm"
title="【Jupyter】个人开发常见命令" target="_blank">【Jupyter】个人开发常见命令</a>
<span class="text-muted">TIM老师</span>
<a class="tag" taget="_blank" href="/search/%23/1.htm">#</a><a class="tag" taget="_blank" href="/search/Pycharm/1.htm">Pycharm</a><a class="tag" taget="_blank" href="/search/%26amp%3B/1.htm">&</a><a class="tag" taget="_blank" href="/search/VSCode/1.htm">VSCode</a><a class="tag" taget="_blank" href="/search/python/1.htm">python</a><a class="tag" taget="_blank" href="/search/Jupyter/1.htm">Jupyter</a>
<div>1.查看python版本importsysprint(sys.version)2.ipynb/py文件转换jupyternbconvert--topythonmy_file.ipynbipynb转换为mdjupyternbconvert--tomdmy_file.ipynbipynb转为htmljupyternbconvert--tohtmlmy_file.ipynbipython转换为pdfju</div>
</li>
<li><a href="/article/1950194363237724160.htm"
title="用 Python 开发小游戏:零基础也能做出《贪吃蛇》" target="_blank">用 Python 开发小游戏:零基础也能做出《贪吃蛇》</a>
<span class="text-muted"></span>
<div>本文专为零基础学习者打造,详细介绍如何用Python开发经典小游戏《贪吃蛇》。无需复杂编程知识,从环境搭建到代码编写、功能实现,逐步讲解核心逻辑与操作。涵盖Pygame库的基础运用、游戏界面设计、蛇的移动与食物生成规则等,让新手能按步骤完成开发,同时融入SEO优化要点,帮助读者轻松入门Python游戏开发,体验从0到1做出游戏的乐趣。一、为什么选择用Python开发《贪吃蛇》对于零基础学习者来说,</div>
</li>
<li><a href="/article/1950193733681082368.htm"
title="基于Python的AI健康助手:开发与部署全攻略" target="_blank">基于Python的AI健康助手:开发与部署全攻略</a>
<span class="text-muted">AI算力网络与通信</span>
<a class="tag" taget="_blank" href="/search/AI%E7%AE%97%E5%8A%9B%E7%BD%91%E7%BB%9C%E4%B8%8E%E9%80%9A%E4%BF%A1%E5%8E%9F%E7%90%86/1.htm">AI算力网络与通信原理</a><a class="tag" taget="_blank" href="/search/AI%E4%BA%BA%E5%B7%A5%E6%99%BA%E8%83%BD%E5%A4%A7%E6%95%B0%E6%8D%AE%E6%9E%B6%E6%9E%84/1.htm">AI人工智能大数据架构</a><a class="tag" taget="_blank" href="/search/python/1.htm">python</a><a class="tag" taget="_blank" href="/search/%E4%BA%BA%E5%B7%A5%E6%99%BA%E8%83%BD/1.htm">人工智能</a><a class="tag" taget="_blank" href="/search/%E5%BC%80%E5%8F%91%E8%AF%AD%E8%A8%80/1.htm">开发语言</a><a class="tag" taget="_blank" href="/search/ai/1.htm">ai</a>
<div>基于Python的AI健康助手:开发与部署全攻略关键词:Python、AI健康助手、机器学习、自然语言处理、Flask、部署、健康管理摘要:本文将详细介绍如何使用Python开发一个AI健康助手,从需求分析、技术选型到核心功能实现,再到最终部署上线的完整过程。我们将使用自然语言处理技术理解用户健康咨询,通过机器学习模型提供个性化建议,并展示如何用Flask框架构建Web应用接口。文章包含大量实际代</div>
</li>
<li><a href="/article/1950192849786040320.htm"
title="AI人工智能中的数据挖掘:提升智能决策能力" target="_blank">AI人工智能中的数据挖掘:提升智能决策能力</a>
<span class="text-muted"></span>
<div>AI人工智能中的数据挖掘:提升智能决策能力关键词:数据挖掘、人工智能、机器学习、智能决策、数据分析、特征工程、模型优化摘要:本文深入探讨了数据挖掘在人工智能领域中的核心作用,重点分析了如何通过数据挖掘技术提升智能决策能力。文章从基础概念出发,详细介绍了数据挖掘的关键算法、数学模型和实际应用场景,并通过Python代码示例展示了数据挖掘的全流程。最后,文章展望了数据挖掘技术的未来发展趋势和面临的挑战</div>
</li>
<li><a href="/article/1950192217708621824.htm"
title="lesson20:Python函数的标注" target="_blank">lesson20:Python函数的标注</a>
<span class="text-muted">你的电影很有趣</span>
<a class="tag" taget="_blank" href="/search/python/1.htm">python</a><a class="tag" taget="_blank" href="/search/%E5%BC%80%E5%8F%91%E8%AF%AD%E8%A8%80/1.htm">开发语言</a>
<div>目录引言:为什么函数标注是现代Python开发的必备技能一、函数标注的基础语法1.1参数与返回值标注1.2支持的标注类型1.3Python3.9+的重大改进:标准集合泛型二、高级标注技巧与最佳实践2.1复杂参数结构标注2.2函数类型与回调标注2.3变量注解与类型别名三、静态类型检查工具应用3.1mypy:最流行的类型检查器3.2Pyright与IDE集成3.3运行时类型验证四、函数标注的工程价值与</div>
</li>
<li><a href="/article/1950190325960077312.htm"
title="Jupyter Notebook:数据科学的“瑞士军刀”" target="_blank">Jupyter Notebook:数据科学的“瑞士军刀”</a>
<span class="text-muted">a小胡哦</span>
<a class="tag" taget="_blank" href="/search/%E6%9C%BA%E5%99%A8%E5%AD%A6%E4%B9%A0%E5%9F%BA%E7%A1%80/1.htm">机器学习基础</a><a class="tag" taget="_blank" href="/search/%E4%BA%BA%E5%B7%A5%E6%99%BA%E8%83%BD/1.htm">人工智能</a><a class="tag" taget="_blank" href="/search/%E6%9C%BA%E5%99%A8%E5%AD%A6%E4%B9%A0/1.htm">机器学习</a>
<div>在数据科学的世界里,JupyterNotebook是一个不可或缺的工具,它就像是数据科学家手中的“瑞士军刀”,功能强大且灵活多变。今天,就让我们一起深入了解这个神奇的工具。一、JupyterNotebook是什么?JupyterNotebook是一个开源的Web应用程序,它允许你创建和共享包含实时代码、方程、可视化和解释性文本的文档。它支持多种编程语言,其中Python是最常用的语言之一。Jupy</div>
</li>
<li><a href="/article/1950187554129113088.htm"
title="Django学习笔记(一)" target="_blank">Django学习笔记(一)</a>
<span class="text-muted"></span>
<div>学习视频为:pythondjangoweb框架开发入门全套视频教程一、安装pipinstalldjango==****检查是否安装成功django.get_version()二、django新建项目操作1、新建一个项目django-adminstartprojectproject_name2、新建APPcdproject_namedjango-adminstartappApp注:一个project</div>
</li>
<li><a href="/article/1950185789447008256.htm"
title="Python 程序设计讲义(26):字符串的用法——字符的编码" target="_blank">Python 程序设计讲义(26):字符串的用法——字符的编码</a>
<span class="text-muted">睿思达DBA_WGX</span>
<a class="tag" taget="_blank" href="/search/Python/1.htm">Python</a><a class="tag" taget="_blank" href="/search/%E8%AE%B2%E4%B9%89/1.htm">讲义</a><a class="tag" taget="_blank" href="/search/python/1.htm">python</a><a class="tag" taget="_blank" href="/search/%E5%BC%80%E5%8F%91%E8%AF%AD%E8%A8%80/1.htm">开发语言</a>
<div>Python程序设计讲义(26):字符串的用法——字符的编码目录Python程序设计讲义(26):字符串的用法——字符的编码一、字符的编码二、`ASCII`编码三、`Unicode`编码四、使用`ord()`函数查询一个字符对应的`Unicode`编码五、使用`chr()`函数查询一个`Unicode`编码对应的字符六、`Python`字符串的特征一、字符的编码计算机默认只能处理二进制数,而不能处</div>
</li>
<li><a href="/article/1950183898780594176.htm"
title="【Python】pypinyin-汉字拼音转换工具" target="_blank">【Python】pypinyin-汉字拼音转换工具</a>
<span class="text-muted">鸟哥大大</span>
<a class="tag" taget="_blank" href="/search/Python/1.htm">Python</a><a class="tag" taget="_blank" href="/search/python/1.htm">python</a><a class="tag" taget="_blank" href="/search/%E8%87%AA%E7%84%B6%E8%AF%AD%E8%A8%80%E5%A4%84%E7%90%86/1.htm">自然语言处理</a>
<div>文章目录1.主要功能2.安装3.常用API3.1拼音风格3.2核心API3.2.1pypinyin.pinyin()3.2.2pypinyin.lazy_pinyin()3.2.3pypinyin.load_single_dict()3.2.4pypinyin.load_phrases_dict()3.2.5pypinyin.slug()3.3注册新的拼音风格4.基本用法4.1库导入4.2基本汉字</div>
</li>
<li><a href="/article/1950183268448006144.htm"
title="python编程第十四课:数据可视化" target="_blank">python编程第十四课:数据可视化</a>
<span class="text-muted">小小源助手</span>
<a class="tag" taget="_blank" href="/search/Python%E4%BB%A3%E7%A0%81%E5%AE%9E%E4%BE%8B/1.htm">Python代码实例</a><a class="tag" taget="_blank" href="/search/%E4%BF%A1%E6%81%AF%E5%8F%AF%E8%A7%86%E5%8C%96/1.htm">信息可视化</a><a class="tag" taget="_blank" href="/search/python/1.htm">python</a><a class="tag" taget="_blank" href="/search/%E5%BC%80%E5%8F%91%E8%AF%AD%E8%A8%80/1.htm">开发语言</a>
<div>Python数据可视化:让数据“开口说话”在当今数据爆炸的时代,数据可视化已成为探索数据规律、传达数据信息的关键技术。Python凭借其丰富的第三方库,为数据可视化提供了强大而灵活的解决方案。本文将带你深入了解Matplotlib库的基础绘图、Seaborn库的高级可视化以及交互式可视化工具Plotly,帮助你通过图表清晰地展示数据背后的故事。一、Matplotlib库基础绘图Matplotlib</div>
</li>
<li><a href="/article/1950180118999658496.htm"
title="Python数据可视化:用代码绘制数据背后的故事" target="_blank">Python数据可视化:用代码绘制数据背后的故事</a>
<span class="text-muted">AAEllisonPang</span>
<a class="tag" taget="_blank" href="/search/Python/1.htm">Python</a><a class="tag" taget="_blank" href="/search/%E4%BF%A1%E6%81%AF%E5%8F%AF%E8%A7%86%E5%8C%96/1.htm">信息可视化</a><a class="tag" taget="_blank" href="/search/python/1.htm">python</a><a class="tag" taget="_blank" href="/search/%E5%BC%80%E5%8F%91%E8%AF%AD%E8%A8%80/1.htm">开发语言</a>
<div>引言:当数据会说话在数据爆炸的时代,可视化是解锁数据价值的金钥匙。Python凭借其丰富的可视化生态库,已成为数据科学家的首选工具。本文将带您从基础到高级,探索如何用Python将冰冷数字转化为引人入胜的视觉叙事。一、基础篇:二维可视化的艺术表达1.1Matplotlib:可视化领域的瑞士军刀importmatplotlib.pyplotaspltimportnumpyasnpx=np.linsp</div>
</li>
<li><a href="/article/1950179614320029696.htm"
title="python学习笔记(汇总)" target="_blank">python学习笔记(汇总)</a>
<span class="text-muted">朕的剑还未配妥</span>
<a class="tag" taget="_blank" href="/search/python%E5%AD%A6%E4%B9%A0%E7%AC%94%E8%AE%B0%E6%95%B4%E7%90%86/1.htm">python学习笔记整理</a><a class="tag" taget="_blank" href="/search/python/1.htm">python</a><a class="tag" taget="_blank" href="/search/%E5%AD%A6%E4%B9%A0/1.htm">学习</a><a class="tag" taget="_blank" href="/search/%E5%BC%80%E5%8F%91%E8%AF%AD%E8%A8%80/1.htm">开发语言</a>
<div>文章目录一.基础知识二.python中的数据类型三.运算符四.程序的控制结构五.列表六.字典七.元组八.集合九.字符串十.函数十一.解决bug一.基础知识print函数字符串要加引号,数字可不加引号,如print(123.4)print('小谢')print("洛天依")还可输入表达式,如print(1+3)如果使用三引号,print打印的内容可不在同一行print("line1line2line</div>
</li>
<li><a href="/article/1950175199089455104.htm"
title="PDF转Markdown - Python 实现方案与代码" target="_blank">PDF转Markdown - Python 实现方案与代码</a>
<span class="text-muted">Eiceblue</span>
<a class="tag" taget="_blank" href="/search/Python/1.htm">Python</a><a class="tag" taget="_blank" href="/search/Python/1.htm">Python</a><a class="tag" taget="_blank" href="/search/PDF/1.htm">PDF</a><a class="tag" taget="_blank" href="/search/pdf/1.htm">pdf</a><a class="tag" taget="_blank" href="/search/python/1.htm">python</a><a class="tag" taget="_blank" href="/search/%E5%BC%80%E5%8F%91%E8%AF%AD%E8%A8%80/1.htm">开发语言</a><a class="tag" taget="_blank" href="/search/vscode/1.htm">vscode</a>
<div>PDF作为广泛使用的文档格式,转换为轻量级标记语言Markdown后,可无缝集成到技术文档、博客平台和版本控制系统中,提高内容的可编辑性和可访问性。本文将详细介绍如何使用国产Spire.PDFforPython库将PDF文档转换为Markdown格式。技术优势:精准保留原始文档结构(段落/列表/表格)完整提取文本和图像内容无需Adobe依赖的纯Python实现支持Linux/Windows/mac</div>
</li>
<li><a href="/article/1950174441992417280.htm"
title="使用Python和Gradio构建实时数据可视化工具" target="_blank">使用Python和Gradio构建实时数据可视化工具</a>
<span class="text-muted">PythonAI编程架构实战家</span>
<a class="tag" taget="_blank" href="/search/%E4%BF%A1%E6%81%AF%E5%8F%AF%E8%A7%86%E5%8C%96/1.htm">信息可视化</a><a class="tag" taget="_blank" href="/search/python/1.htm">python</a><a class="tag" taget="_blank" href="/search/%E5%BC%80%E5%8F%91%E8%AF%AD%E8%A8%80/1.htm">开发语言</a><a class="tag" taget="_blank" href="/search/ai/1.htm">ai</a>
<div>使用Python和Gradio构建实时数据可视化工具关键词:Python、Gradio、数据可视化、实时数据、Web应用、交互式界面、数据科学摘要:本文将详细介绍如何使用Python和Gradio框架构建一个实时数据可视化工具。我们将从基础概念开始,逐步深入到核心算法实现,包括数据处理、可视化技术以及Gradio的交互式界面设计。通过实际项目案例,读者将学习如何创建一个功能完整、响应迅速的实时数据</div>
</li>
<li><a href="/article/1950174315609649152.htm"
title="Python Gradio:实现交互式图像编辑" target="_blank">Python Gradio:实现交互式图像编辑</a>
<span class="text-muted">PythonAI编程架构实战家</span>
<a class="tag" taget="_blank" href="/search/Python%E7%BC%96%E7%A8%8B%E4%B9%8B%E9%81%93/1.htm">Python编程之道</a><a class="tag" taget="_blank" href="/search/python/1.htm">python</a><a class="tag" taget="_blank" href="/search/%E5%BC%80%E5%8F%91%E8%AF%AD%E8%A8%80/1.htm">开发语言</a><a class="tag" taget="_blank" href="/search/ai/1.htm">ai</a>
<div>PythonGradio:实现交互式图像编辑关键词:Python,Gradio,交互式图像编辑,计算机视觉,深度学习,图像处理,Web应用摘要:本文将深入探讨如何使用Python的Gradio库构建交互式图像编辑应用。我们将从基础概念开始,逐步介绍Gradio的核心功能,并通过实际代码示例展示如何实现各种图像处理功能。文章将涵盖图像滤镜应用、对象检测、风格迁移等高级功能,同时提供完整的项目实战案例</div>
</li>
<li><a href="/article/1950174063116742656.htm"
title="数据可视化:数据世界的直观呈现" target="_blank">数据可视化:数据世界的直观呈现</a>
<span class="text-muted">卢政权1</span>
<a class="tag" taget="_blank" href="/search/%E4%BF%A1%E6%81%AF%E5%8F%AF%E8%A7%86%E5%8C%96/1.htm">信息可视化</a><a class="tag" taget="_blank" href="/search/%E6%95%B0%E6%8D%AE%E5%88%86%E6%9E%90/1.htm">数据分析</a><a class="tag" taget="_blank" href="/search/%E6%95%B0%E6%8D%AE%E6%8C%96%E6%8E%98/1.htm">数据挖掘</a>
<div>在当今数字化浪潮中,数据呈爆炸式增长。数据可视化作为一种强大的技术手段,能够将复杂的数据转化为直观的图形、图表等形式,让数据背后的信息一目了然。无论是在商业决策、科学研究还是日常数据分析中,数据可视化都发挥着极为重要的作用。它帮助我们快速理解数据的分布、趋势、关联等特征,从而为进一步的分析和行动提供有力支持。接下来,我们将深入探讨数据可视化的奥秘,并通过代码示例展示其实际应用。一、Python数据</div>
</li>
<li><a href="/article/1950172300749893632.htm"
title="Python 程序设计讲义(25):循环结构——嵌套循环" target="_blank">Python 程序设计讲义(25):循环结构——嵌套循环</a>
<span class="text-muted"></span>
<div>Python程序设计讲义(25):循环结构——嵌套循环目录Python程序设计讲义(25):循环结构——嵌套循环一、嵌套循环的执行流程二、嵌套循环对应的几种情况1、内循环和外循环互不影响2、外循环迭代影响内循环的条件3、外循环迭代影响内循环的循环体嵌套循环是指在一个循环体中嵌套另一个循环。while循环中可以嵌入另一个while循环或for循环。反之,也可以在for循环中嵌入另一个for循环或wh</div>
</li>
<li><a href="/article/1950166498563649536.htm"
title="基于Python引擎的PP-OCR模型库推理" target="_blank">基于Python引擎的PP-OCR模型库推理</a>
<span class="text-muted">张欣-男</span>
<a class="tag" taget="_blank" href="/search/python/1.htm">python</a><a class="tag" taget="_blank" href="/search/ocr/1.htm">ocr</a><a class="tag" taget="_blank" href="/search/%E5%BC%80%E5%8F%91%E8%AF%AD%E8%A8%80/1.htm">开发语言</a><a class="tag" taget="_blank" href="/search/PaddleOCR/1.htm">PaddleOCR</a><a class="tag" taget="_blank" href="/search/PaddlePaddle/1.htm">PaddlePaddle</a>
<div>基于Python引擎的PP-OCR模型库推理1.文本检测模型推理#下载超轻量中文检测模型:wgethttps://paddleocr.bj.bcebos.com/PP-OCRv3/chinese/ch_PP-OCRv3_det_infer.tartarxfch_PP-OCRv3_det_infer.tarpython3tools/infer/predict_det.py--image_dir=".</div>
</li>
<li><a href="/article/1950158807220940800.htm"
title="一个开源AI牛马神器 | AiPy,平替Manus,装完直接上手写Python!" target="_blank">一个开源AI牛马神器 | AiPy,平替Manus,装完直接上手写Python!</a>
<span class="text-muted">Agent加载失败</span>
<a class="tag" taget="_blank" href="/search/%E4%BA%BA%E5%B7%A5%E6%99%BA%E8%83%BD/1.htm">人工智能</a><a class="tag" taget="_blank" href="/search/python/1.htm">python</a><a class="tag" taget="_blank" href="/search/%E5%BC%80%E6%BA%90/1.htm">开源</a><a class="tag" taget="_blank" href="/search/%E7%AE%97%E6%B3%95/1.htm">算法</a><a class="tag" taget="_blank" href="/search/AI%E7%BC%96%E7%A8%8B/1.htm">AI编程</a>
<div>还记得三个月前那个在闲鱼被炒到万元邀请码的Manus吗?现在你点官网,直接提示「所在地区不可用」了它走了,但更香的国产开源项目出现了:AiPy(爱派)。主打一个极致简化的AIAgent理念:别搞什么插件市场、Agent路由,直接给AI一个Python解释器,让它用自然语言写代码干活。听起来狠活?实际体验更狠:•完全本地化,界面傻瓜式操作,支持自然语言生成&执行Python任务;•数据清洗、文档总结</div>
</li>
<li><a href="/article/1950158303287898112.htm"
title="零数学基础理解AI核心概念:梯度下降可视化实战" target="_blank">零数学基础理解AI核心概念:梯度下降可视化实战</a>
<span class="text-muted">九章云极AladdinEdu</span>
<a class="tag" taget="_blank" href="/search/%E4%BA%BA%E5%B7%A5%E6%99%BA%E8%83%BD/1.htm">人工智能</a><a class="tag" taget="_blank" href="/search/gpu%E7%AE%97%E5%8A%9B/1.htm">gpu算力</a><a class="tag" taget="_blank" href="/search/%E6%B7%B1%E5%BA%A6%E5%AD%A6%E4%B9%A0/1.htm">深度学习</a><a class="tag" taget="_blank" href="/search/pytorch/1.htm">pytorch</a><a class="tag" taget="_blank" href="/search/python/1.htm">python</a><a class="tag" taget="_blank" href="/search/%E8%AF%AD%E8%A8%80%E6%A8%A1%E5%9E%8B/1.htm">语言模型</a><a class="tag" taget="_blank" href="/search/opencv/1.htm">opencv</a>
<div>点击“AladdinEdu,同学们用得起的【H卡】算力平台”,H卡级别算力,按量计费,灵活弹性,顶级配置,学生专属优惠。用Python动画演示损失函数优化过程,数学公式具象化读者收获:直观理解模型训练本质,破除"数学恐惧症"当盲人登山者摸索下山路径时,他本能地运用了梯度下降算法。本文将用动态可视化技术,让你像感受重力一样理解AI训练的核心原理——无需任何数学公式推导。一、梯度下降:AI世界的"万有</div>
</li>
<li><a href="/article/1950141538352820224.htm"
title="2025.07 Java入门笔记01" target="_blank">2025.07 Java入门笔记01</a>
<span class="text-muted">殷浩焕</span>
<a class="tag" taget="_blank" href="/search/%E7%AC%94%E8%AE%B0/1.htm">笔记</a>
<div>一、熟悉IDEA和Java语法(一)LiuCourseJavaOOP1.一直在用C++开发,python也用了些,Java是真的不熟,用什么IDE还是问的同事;2.一开始安装了jdk-23,拿VSCode当编辑器,在cmd窗口编译运行,也能玩;但是想正儿八经搞项目开发,还是需要IDE;3.安装了IDEA社区版:(1)IDE通常自带对应编程语言的安装包,例如IDEA自带jbr-21(和jdk是不同的</div>
</li>
<li><a href="/article/1950138256133779456.htm"
title="响应式编程实践:Spring Boot WebFlux构建高性能非阻塞服务" target="_blank">响应式编程实践:Spring Boot WebFlux构建高性能非阻塞服务</a>
<span class="text-muted">fanxbl957</span>
<a class="tag" taget="_blank" href="/search/Web/1.htm">Web</a><a class="tag" taget="_blank" href="/search/spring/1.htm">spring</a><a class="tag" taget="_blank" href="/search/boot/1.htm">boot</a><a class="tag" taget="_blank" href="/search/%E5%90%8E%E7%AB%AF/1.htm">后端</a><a class="tag" taget="_blank" href="/search/java/1.htm">java</a>
<div>博主介绍:Java、Python、js全栈开发“多面手”,精通多种编程语言和技术,痴迷于人工智能领域。秉持着对技术的热爱与执着,持续探索创新,愿在此分享交流和学习,与大家共进步。全栈开发环境搭建运行攻略:多语言一站式指南(环境搭建+运行+调试+发布+保姆级详解)感兴趣的可以先收藏起来,希望帮助更多的人响应式编程实践:SpringBootWebFlux构建高性能非阻塞服务一、引言在当今数字化时代,互</div>
</li>
<li><a href="/article/1950134096558616576.htm"
title="Python STL概念学习与代码实践" target="_blank">Python STL概念学习与代码实践</a>
<span class="text-muted">体制教科书</span>
<div>本文还有配套的精品资源,点击获取简介:通过”py_stl_learning”项目,学习者可以使用Python实现和理解C++STL的概念,包括数据结构、算法、容器适配器、模板和泛型容器等。Python中的列表、集合、字典等数据结构与STL中的vector、set、map等类似,而Python的itertools和functools模块提供了STL风格的算法功能。Python通过其面向对象的特性以及</div>
</li>
<li><a href="/article/120.htm"
title="web前段跨域nginx代理配置" target="_blank">web前段跨域nginx代理配置</a>
<span class="text-muted">刘正强</span>
<a class="tag" taget="_blank" href="/search/nginx/1.htm">nginx</a><a class="tag" taget="_blank" href="/search/cms/1.htm">cms</a><a class="tag" taget="_blank" href="/search/Web/1.htm">Web</a>
<div>nginx代理配置可参考server部分
server {
listen 80;
server_name localhost;
</div>
</li>
<li><a href="/article/247.htm"
title="spring学习笔记" target="_blank">spring学习笔记</a>
<span class="text-muted">caoyong</span>
<a class="tag" taget="_blank" href="/search/spring/1.htm">spring</a>
<div>一、概述
a>、核心技术 : IOC与AOP
b>、开发为什么需要面向接口而不是实现
接口降低一个组件与整个系统的藕合程度,当该组件不满足系统需求时,可以很容易的将该组件从系统中替换掉,而不会对整个系统产生大的影响
c>、面向接口编口编程的难点在于如何对接口进行初始化,(使用工厂设计模式) </div>
</li>
<li><a href="/article/374.htm"
title="Eclipse打开workspace提示工作空间不可用" target="_blank">Eclipse打开workspace提示工作空间不可用</a>
<span class="text-muted">0624chenhong</span>
<a class="tag" taget="_blank" href="/search/eclipse/1.htm">eclipse</a>
<div>做项目的时候,难免会用到整个团队的代码,或者上一任同事创建的workspace,
1.电脑切换账号后,Eclipse打开时,会提示Eclipse对应的目录锁定,无法访问,根据提示,找到对应目录,G:\eclipse\configuration\org.eclipse.osgi\.manager,其中文件.fileTableLock提示被锁定。
解决办法,删掉.fileTableLock文件,重</div>
</li>
<li><a href="/article/501.htm"
title="Javascript 面向对面写法的必要性?" target="_blank">Javascript 面向对面写法的必要性?</a>
<span class="text-muted">一炮送你回车库</span>
<a class="tag" taget="_blank" href="/search/JavaScript/1.htm">JavaScript</a>
<div>现在Javascript面向对象的方式来写页面很流行,什么纯javascript的mvc框架都出来了:ember
这是javascript层的mvc框架哦,不是j2ee的mvc框架
我想说的是,javascript本来就不是一门面向对象的语言,用它写出来的面向对象的程序,本身就有些别扭,很多人提到js的面向对象首先提的是:复用性。那么我请问你写的js里有多少是可以复用的,用fu</div>
</li>
<li><a href="/article/628.htm"
title="js array对象的迭代方法" target="_blank">js array对象的迭代方法</a>
<span class="text-muted">换个号韩国红果果</span>
<a class="tag" taget="_blank" href="/search/array/1.htm">array</a>
<div>1.forEach 该方法接受一个函数作为参数, 对数组中的每个元素
使用该函数 return 语句失效
function square(num) {
print(num, num * num);
}
var nums = [1,2,3,4,5,6,7,8,9,10];
nums.forEach(square);
2.every 该方法接受一个返回值为布尔类型</div>
</li>
<li><a href="/article/755.htm"
title="对Hibernate缓存机制的理解" target="_blank">对Hibernate缓存机制的理解</a>
<span class="text-muted">归来朝歌</span>
<a class="tag" taget="_blank" href="/search/session/1.htm">session</a><a class="tag" taget="_blank" href="/search/%E4%B8%80%E7%BA%A7%E7%BC%93%E5%AD%98/1.htm">一级缓存</a><a class="tag" taget="_blank" href="/search/%E5%AF%B9%E8%B1%A1%E6%8C%81%E4%B9%85%E5%8C%96/1.htm">对象持久化</a>
<div>在hibernate中session一级缓存机制中,有这么一种情况:
问题描述:我需要new一个对象,对它的几个字段赋值,但是有一些属性并没有进行赋值,然后调用
session.save()方法,在提交事务后,会出现这样的情况:
1:在数据库中有默认属性的字段的值为空
2:既然是持久化对象,为什么在最后对象拿不到默认属性的值?
通过调试后解决方案如下:
对于问题一,如你在数据库里设置了</div>
</li>
<li><a href="/article/882.htm"
title="WebService调用错误合集" target="_blank">WebService调用错误合集</a>
<span class="text-muted">darkranger</span>
<a class="tag" taget="_blank" href="/search/webservice/1.htm">webservice</a>
<div> Java.Lang.NoClassDefFoundError: Org/Apache/Commons/Discovery/Tools/DiscoverSingleton
调用接口出错,
一个简单的WebService
import org.apache.axis.client.Call;import org.apache.axis.client.Service;
首先必不可</div>
</li>
<li><a href="/article/1009.htm"
title="JSP和Servlet的中文乱码处理" target="_blank">JSP和Servlet的中文乱码处理</a>
<span class="text-muted">aijuans</span>
<a class="tag" taget="_blank" href="/search/Java+Web/1.htm">Java Web</a>
<div>JSP和Servlet的中文乱码处理
前几天学习了JSP和Servlet中有关中文乱码的一些问题,写成了博客,今天进行更新一下。应该是可以解决日常的乱码问题了。现在作以下总结希望对需要的人有所帮助。我也是刚学,所以有不足之处希望谅解。
一、表单提交时出现乱码:
在进行表单提交的时候,经常提交一些中文,自然就避免不了出现中文乱码的情况,对于表单来说有两种提交方式:get和post提交方式。所以</div>
</li>
<li><a href="/article/1136.htm"
title="面试经典六问" target="_blank">面试经典六问</a>
<span class="text-muted">atongyeye</span>
<a class="tag" taget="_blank" href="/search/%E5%B7%A5%E4%BD%9C/1.htm">工作</a><a class="tag" taget="_blank" href="/search/%E9%9D%A2%E8%AF%95/1.htm">面试</a>
<div>题记:因为我不善沟通,所以在面试中经常碰壁,看了网上太多面试宝典,基本上不太靠谱。只好自己总结,并试着根据最近工作情况完成个人答案。以备不时之需。
以下是人事了解应聘者情况的最典型的六个问题:
1 简单自我介绍
关于这个问题,主要为了弄清两件事,一是了解应聘者的背景,二是应聘者将这些背景信息组织成合适语言的能力。
我的回答:(针对技术面试回答,如果是人事面试,可以就掌</div>
</li>
<li><a href="/article/1263.htm"
title="contentResolver.query()参数详解" target="_blank">contentResolver.query()参数详解</a>
<span class="text-muted">百合不是茶</span>
<a class="tag" taget="_blank" href="/search/android/1.htm">android</a><a class="tag" taget="_blank" href="/search/query%28%29%E8%AF%A6%E8%A7%A3/1.htm">query()详解</a>
<div>收藏csdn的博客,介绍的比较详细,新手值得一看 1.获取联系人姓名
一个简单的例子,这个函数获取设备上所有的联系人ID和联系人NAME。
[java]
view plain
copy
public void fetchAllContacts() {
</div>
</li>
<li><a href="/article/1390.htm"
title="ora-00054:resource busy and acquire with nowait specified解决方法" target="_blank">ora-00054:resource busy and acquire with nowait specified解决方法</a>
<span class="text-muted">bijian1013</span>
<a class="tag" taget="_blank" href="/search/oracle/1.htm">oracle</a><a class="tag" taget="_blank" href="/search/%E6%95%B0%E6%8D%AE%E5%BA%93/1.htm">数据库</a><a class="tag" taget="_blank" href="/search/kill/1.htm">kill</a><a class="tag" taget="_blank" href="/search/nowait/1.htm">nowait</a>
<div> 当某个数据库用户在数据库中插入、更新、删除一个表的数据,或者增加一个表的主键时或者表的索引时,常常会出现ora-00054:resource busy and acquire with nowait specified这样的错误。主要是因为有事务正在执行(或者事务已经被锁),所有导致执行不成功。
1.下面的语句</div>
</li>
<li><a href="/article/1517.htm"
title="web 开发乱码" target="_blank">web 开发乱码</a>
<span class="text-muted">征客丶</span>
<a class="tag" taget="_blank" href="/search/spring/1.htm">spring</a><a class="tag" taget="_blank" href="/search/Web/1.htm">Web</a>
<div>以下前端都是 utf-8 字符集编码
一、后台接收
1.1、 get 请求乱码
get 请求中,请求参数在请求头中;
乱码解决方法:
a、通过在web 服务器中配置编码格式:tomcat 中,在 Connector 中添加URIEncoding="UTF-8";
1.2、post 请求乱码
post 请求中,请求参数分两部份,
1.2.1、url?参数,</div>
</li>
<li><a href="/article/1644.htm"
title="【Spark十六】: Spark SQL第二部分数据源和注册表的几种方式" target="_blank">【Spark十六】: Spark SQL第二部分数据源和注册表的几种方式</a>
<span class="text-muted">bit1129</span>
<a class="tag" taget="_blank" href="/search/spark/1.htm">spark</a>
<div>Spark SQL数据源和表的Schema
case class
apply schema
parquet
json
JSON数据源 准备源数据
{"name":"Jack", "age": 12, "addr":{"city":"beijing&</div>
</li>
<li><a href="/article/1771.htm"
title="JVM学习之:调优总结 -Xms -Xmx -Xmn -Xss" target="_blank">JVM学习之:调优总结 -Xms -Xmx -Xmn -Xss</a>
<span class="text-muted">BlueSkator</span>
<a class="tag" taget="_blank" href="/search/-Xss/1.htm">-Xss</a><a class="tag" taget="_blank" href="/search/-Xmn/1.htm">-Xmn</a><a class="tag" taget="_blank" href="/search/-Xms/1.htm">-Xms</a><a class="tag" taget="_blank" href="/search/-Xmx/1.htm">-Xmx</a>
<div>
堆大小设置JVM 中最大堆大小有三方面限制:相关操作系统的数据模型(32-bt还是64-bit)限制;系统的可用虚拟内存限制;系统的可用物理内存限制。32位系统下,一般限制在1.5G~2G;64为操作系统对内存无限制。我在Windows Server 2003 系统,3.5G物理内存,JDK5.0下测试,最大可设置为1478m。典型设置:
java -Xmx355</div>
</li>
<li><a href="/article/1898.htm"
title="jqGrid 各种参数 详解(转帖)" target="_blank">jqGrid 各种参数 详解(转帖)</a>
<span class="text-muted">BreakingBad</span>
<a class="tag" taget="_blank" href="/search/jqGrid/1.htm">jqGrid</a>
<div>
jqGrid 各种参数 详解 分类:
源代码分享
个人随笔请勿参考
解决开发问题 2012-05-09 20:29 84282人阅读
评论(22)
收藏
举报
jquery
服务器
parameters
function
ajax
string </div>
</li>
<li><a href="/article/2025.htm"
title="读《研磨设计模式》-代码笔记-代理模式-Proxy" target="_blank">读《研磨设计模式》-代码笔记-代理模式-Proxy</a>
<span class="text-muted">bylijinnan</span>
<a class="tag" taget="_blank" href="/search/java/1.htm">java</a><a class="tag" taget="_blank" href="/search/%E8%AE%BE%E8%AE%A1%E6%A8%A1%E5%BC%8F/1.htm">设计模式</a>
<div>声明: 本文只为方便我个人查阅和理解,详细的分析以及源代码请移步 原作者的博客http://chjavach.iteye.com/
import java.lang.reflect.InvocationHandler;
import java.lang.reflect.Method;
import java.lang.reflect.Proxy;
/*
* 下面</div>
</li>
<li><a href="/article/2152.htm"
title="应用升级iOS8中遇到的一些问题" target="_blank">应用升级iOS8中遇到的一些问题</a>
<span class="text-muted">chenhbc</span>
<a class="tag" taget="_blank" href="/search/ios8/1.htm">ios8</a><a class="tag" taget="_blank" href="/search/%E5%8D%87%E7%BA%A7iOS8/1.htm">升级iOS8</a>
<div>1、很奇怪的问题,登录界面,有一个判断,如果不存在某个值,则跳转到设置界面,ios8之前的系统都可以正常跳转,iOS8中代码已经执行到下一个界面了,但界面并没有跳转过去,而且这个值如果设置过的话,也是可以正常跳转过去的,这个问题纠结了两天多,之前的判断我是在
-(void)viewWillAppear:(BOOL)animated
中写的,最终的解决办法是把判断写在
-(void</div>
</li>
<li><a href="/article/2279.htm"
title="工作流与自组织的关系?" target="_blank">工作流与自组织的关系?</a>
<span class="text-muted">comsci</span>
<a class="tag" taget="_blank" href="/search/%E8%AE%BE%E8%AE%A1%E6%A8%A1%E5%BC%8F/1.htm">设计模式</a><a class="tag" taget="_blank" href="/search/%E5%B7%A5%E4%BD%9C/1.htm">工作</a>
<div> 目前的工作流系统中的节点及其相互之间的连接是事先根据管理的实际需要而绘制好的,这种固定的模式在实际的运用中会受到很多限制,特别是节点之间的依存关系是固定的,节点的处理不考虑到流程整体的运行情况,细节和整体间的关系是脱节的,那么我们提出一个新的观点,一个流程是否可以通过节点的自组织运动来自动生成呢?这种流程有什么实际意义呢?
这里有篇论文,摘要是:“针对网格中的服务</div>
</li>
<li><a href="/article/2406.htm"
title="Oracle11.2新特性之INSERT提示IGNORE_ROW_ON_DUPKEY_INDEX" target="_blank">Oracle11.2新特性之INSERT提示IGNORE_ROW_ON_DUPKEY_INDEX</a>
<span class="text-muted">daizj</span>
<a class="tag" taget="_blank" href="/search/oracle/1.htm">oracle</a>
<div>insert提示IGNORE_ROW_ON_DUPKEY_INDEX
转自:http://space.itpub.net/18922393/viewspace-752123
在 insert into tablea ...select * from tableb中,如果存在唯一约束,会导致整个insert操作失败。使用IGNORE_ROW_ON_DUPKEY_INDEX提示,会忽略唯一</div>
</li>
<li><a href="/article/2533.htm"
title="二叉树:堆" target="_blank">二叉树:堆</a>
<span class="text-muted">dieslrae</span>
<a class="tag" taget="_blank" href="/search/%E4%BA%8C%E5%8F%89%E6%A0%91/1.htm">二叉树</a>
<div> 这里说的堆其实是一个完全二叉树,每个节点都不小于自己的子节点,不要跟jvm的堆搞混了.由于是完全二叉树,可以用数组来构建.用数组构建树的规则很简单:
一个节点的父节点下标为: (当前下标 - 1)/2
一个节点的左节点下标为: 当前下标 * 2 + 1
&</div>
</li>
<li><a href="/article/2660.htm"
title="C语言学习八结构体" target="_blank">C语言学习八结构体</a>
<span class="text-muted">dcj3sjt126com</span>
<a class="tag" taget="_blank" href="/search/c/1.htm">c</a>
<div>为什么需要结构体,看代码
# include <stdio.h>
struct Student //定义一个学生类型,里面有age, score, sex, 然后可以定义这个类型的变量
{
int age;
float score;
char sex;
}
int main(void)
{
struct Student st = {80, 66.6,</div>
</li>
<li><a href="/article/2787.htm"
title="centos安装golang" target="_blank">centos安装golang</a>
<span class="text-muted">dcj3sjt126com</span>
<a class="tag" taget="_blank" href="/search/centos/1.htm">centos</a>
<div>#在国内镜像下载二进制包
wget -c http://www.golangtc.com/static/go/go1.4.1.linux-amd64.tar.gz
tar -C /usr/local -xzf go1.4.1.linux-amd64.tar.gz
#把golang的bin目录加入全局环境变量
cat >>/etc/profile<</div>
</li>
<li><a href="/article/2914.htm"
title="10.性能优化-监控-MySQL慢查询" target="_blank">10.性能优化-监控-MySQL慢查询</a>
<span class="text-muted">frank1234</span>
<a class="tag" taget="_blank" href="/search/%E6%80%A7%E8%83%BD%E4%BC%98%E5%8C%96/1.htm">性能优化</a><a class="tag" taget="_blank" href="/search/MySQL%E6%85%A2%E6%9F%A5%E8%AF%A2/1.htm">MySQL慢查询</a>
<div>1.记录慢查询配置
show variables where variable_name like 'slow%' ; --查看默认日志路径
查询结果:--不用的机器可能不同
slow_query_log_file=/var/lib/mysql/centos-slow.log
修改mysqld配置文件:/usr /my.cnf[一般在/etc/my.cnf,本机在/user/my.cn</div>
</li>
<li><a href="/article/3041.htm"
title="Java父类取得子类类名" target="_blank">Java父类取得子类类名</a>
<span class="text-muted">happyqing</span>
<a class="tag" taget="_blank" href="/search/java/1.htm">java</a><a class="tag" taget="_blank" href="/search/this/1.htm">this</a><a class="tag" taget="_blank" href="/search/%E7%88%B6%E7%B1%BB/1.htm">父类</a><a class="tag" taget="_blank" href="/search/%E5%AD%90%E7%B1%BB/1.htm">子类</a><a class="tag" taget="_blank" href="/search/%E7%B1%BB%E5%90%8D/1.htm">类名</a>
<div>
在继承关系中,不管父类还是子类,这些类里面的this都代表了最终new出来的那个类的实例对象,所以在父类中你可以用this获取到子类的信息!
package com.urthinker.module.test;
import org.junit.Test;
abstract class BaseDao<T> {
public void </div>
</li>
<li><a href="/article/3168.htm"
title="Spring3.2新注解@ControllerAdvice" target="_blank">Spring3.2新注解@ControllerAdvice</a>
<span class="text-muted">jinnianshilongnian</span>
<a class="tag" taget="_blank" href="/search/%40Controller/1.htm">@Controller</a>
<div>@ControllerAdvice,是spring3.2提供的新注解,从名字上可以看出大体意思是控制器增强。让我们先看看@ControllerAdvice的实现:
@Target(ElementType.TYPE)
@Retention(RetentionPolicy.RUNTIME)
@Documented
@Component
public @interface Co</div>
</li>
<li><a href="/article/3295.htm"
title="Java spring mvc多数据源配置" target="_blank">Java spring mvc多数据源配置</a>
<span class="text-muted">liuxihope</span>
<a class="tag" taget="_blank" href="/search/spring/1.htm">spring</a>
<div>转自:http://www.itpub.net/thread-1906608-1-1.html
1、首先配置两个数据库
<bean id="dataSourceA" class="org.apache.commons.dbcp.BasicDataSource" destroy-method="close&quo</div>
</li>
<li><a href="/article/3422.htm"
title="第12章 Ajax(下)" target="_blank">第12章 Ajax(下)</a>
<span class="text-muted">onestopweb</span>
<a class="tag" taget="_blank" href="/search/Ajax/1.htm">Ajax</a>
<div>index.html
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN" "http://www.w3.org/TR/xhtml1/DTD/xhtml1-transitional.dtd">
<html xmlns="http://www.w3.org/</div>
</li>
<li><a href="/article/3549.htm"
title="BW / Universe Mappings" target="_blank">BW / Universe Mappings</a>
<span class="text-muted">blueoxygen</span>
<a class="tag" taget="_blank" href="/search/BO/1.htm">BO</a>
<div>
BW Element
OLAP Universe Element
Cube Dimension
Class
Charateristic
A class with dimension and detail objects (Detail objects for key and desription)
Hi</div>
</li>
<li><a href="/article/3676.htm"
title="Java开发熟手该当心的11个错误" target="_blank">Java开发熟手该当心的11个错误</a>
<span class="text-muted">tomcat_oracle</span>
<a class="tag" taget="_blank" href="/search/java/1.htm">java</a><a class="tag" taget="_blank" href="/search/%E5%A4%9A%E7%BA%BF%E7%A8%8B/1.htm">多线程</a><a class="tag" taget="_blank" href="/search/%E5%B7%A5%E4%BD%9C/1.htm">工作</a><a class="tag" taget="_blank" href="/search/%E5%8D%95%E5%85%83%E6%B5%8B%E8%AF%95/1.htm">单元测试</a>
<div>#1、不在属性文件或XML文件中外化配置属性。比如,没有把批处理使用的线程数设置成可在属性文件中配置。你的批处理程序无论在DEV环境中,还是UAT(用户验收
测试)环境中,都可以顺畅无阻地运行,但是一旦部署在PROD 上,把它作为多线程程序处理更大的数据集时,就会抛出IOException,原因可能是JDBC驱动版本不同,也可能是#2中讨论的问题。如果线程数目 可以在属性文件中配置,那么使它成为</div>
</li>
<li><a href="/article/3803.htm"
title="推行国产操作系统的优劣" target="_blank">推行国产操作系统的优劣</a>
<span class="text-muted">yananay</span>
<a class="tag" taget="_blank" href="/search/windows/1.htm">windows</a><a class="tag" taget="_blank" href="/search/linux/1.htm">linux</a><a class="tag" taget="_blank" href="/search/%E5%9B%BD%E4%BA%A7%E6%93%8D%E4%BD%9C%E7%B3%BB%E7%BB%9F/1.htm">国产操作系统</a>
<div>最近刮起了一股风,就是去“国外货”。从应用程序开始,到基础的系统,数据库,现在已经刮到操作系统了。原因就是“棱镜计划”,使我们终于认识到了国外货的危害,开始重视起了信息安全。操作系统是计算机的灵魂。既然是灵魂,为了信息安全,那我们就自然要使用和推行国货。可是,一味地推行,是否就一定正确呢?
先说说信息安全。其实从很早以来大家就在讨论信息安全。很多年以前,就据传某世界级的网络设备制造商生产的交</div>
</li>
</ul>
</div>
</div>
</div>
<div>
<div class="container">
<div class="indexes">
<strong>按字母分类:</strong>
<a href="/tags/A/1.htm" target="_blank">A</a><a href="/tags/B/1.htm" target="_blank">B</a><a href="/tags/C/1.htm" target="_blank">C</a><a
href="/tags/D/1.htm" target="_blank">D</a><a href="/tags/E/1.htm" target="_blank">E</a><a href="/tags/F/1.htm" target="_blank">F</a><a
href="/tags/G/1.htm" target="_blank">G</a><a href="/tags/H/1.htm" target="_blank">H</a><a href="/tags/I/1.htm" target="_blank">I</a><a
href="/tags/J/1.htm" target="_blank">J</a><a href="/tags/K/1.htm" target="_blank">K</a><a href="/tags/L/1.htm" target="_blank">L</a><a
href="/tags/M/1.htm" target="_blank">M</a><a href="/tags/N/1.htm" target="_blank">N</a><a href="/tags/O/1.htm" target="_blank">O</a><a
href="/tags/P/1.htm" target="_blank">P</a><a href="/tags/Q/1.htm" target="_blank">Q</a><a href="/tags/R/1.htm" target="_blank">R</a><a
href="/tags/S/1.htm" target="_blank">S</a><a href="/tags/T/1.htm" target="_blank">T</a><a href="/tags/U/1.htm" target="_blank">U</a><a
href="/tags/V/1.htm" target="_blank">V</a><a href="/tags/W/1.htm" target="_blank">W</a><a href="/tags/X/1.htm" target="_blank">X</a><a
href="/tags/Y/1.htm" target="_blank">Y</a><a href="/tags/Z/1.htm" target="_blank">Z</a><a href="/tags/0/1.htm" target="_blank">其他</a>
</div>
</div>
</div>
<footer id="footer" class="mb30 mt30">
<div class="container">
<div class="footBglm">
<a target="_blank" href="/">首页</a> -
<a target="_blank" href="/custom/about.htm">关于我们</a> -
<a target="_blank" href="/search/Java/1.htm">站内搜索</a> -
<a target="_blank" href="/sitemap.txt">Sitemap</a> -
<a target="_blank" href="/custom/delete.htm">侵权投诉</a>
</div>
<div class="copyright">版权所有 IT知识库 CopyRight © 2000-2050 E-COM-NET.COM , All Rights Reserved.
<!-- <a href="https://beian.miit.gov.cn/" rel="nofollow" target="_blank">京ICP备09083238号</a><br>-->
</div>
</div>
</footer>
<!-- 代码高亮 -->
<script type="text/javascript" src="/static/syntaxhighlighter/scripts/shCore.js"></script>
<script type="text/javascript" src="/static/syntaxhighlighter/scripts/shLegacy.js"></script>
<script type="text/javascript" src="/static/syntaxhighlighter/scripts/shAutoloader.js"></script>
<link type="text/css" rel="stylesheet" href="/static/syntaxhighlighter/styles/shCoreDefault.css"/>
<script type="text/javascript" src="/static/syntaxhighlighter/src/my_start_1.js"></script>
</body>
</html>