- 实时数据流计算引擎Flink和Spark剖析
程小舰
flinkspark数据库kafkahadoop
在过去几年,业界的主流流计算引擎大多采用SparkStreaming,随着近两年Flink的快速发展,Flink的使用也越来越广泛。与此同时,Spark针对SparkStreaming的不足,也继而推出了新的流计算组件。本文旨在深入分析不同的流计算引擎的内在机制和功能特点,为流处理场景的选型提供参考。(DLab数据实验室w.x.公众号出品)一.SparkStreamingSparkStreamin
- Spark SQL架构及高级用法
Aurora_NeAr
sparksql架构
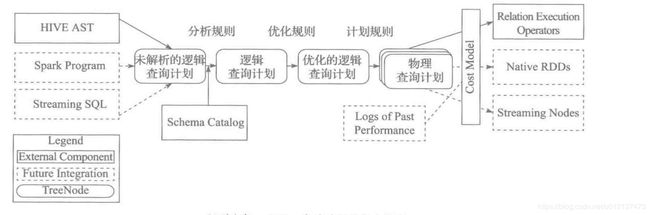
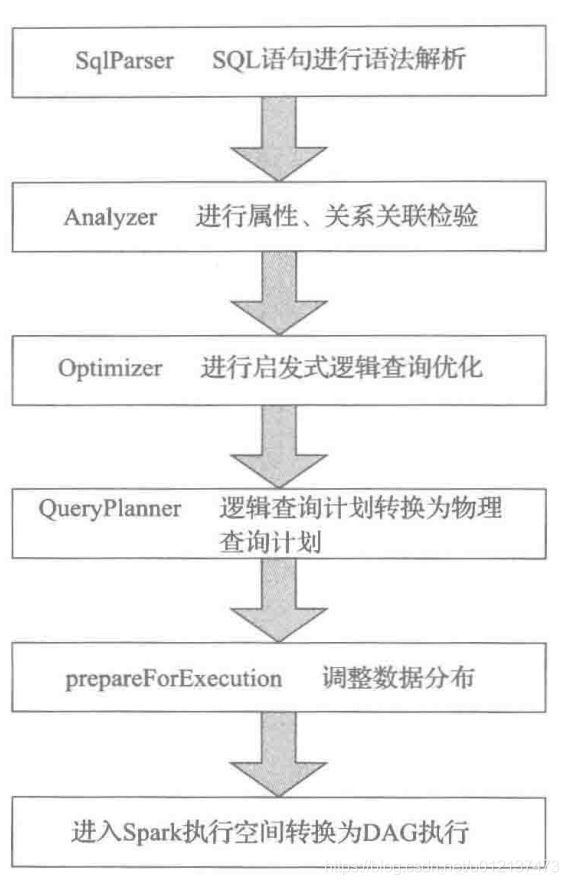
SparkSQL架构概述架构核心组件API层(用户接口)输入方式:SQL查询;DataFrame/DatasetAPI。统一性:所有接口最终转换为逻辑计划树(LogicalPlan),进入优化流程。编译器层(Catalyst优化器)核心引擎:基于规则的优化器(Rule-BasedOptimizer,RBO)与成本优化器(Cost-BasedOptimizer,CBO)。处理流程:阶段输入输出关键动
- Hive详解
一:Hive的历史价值1,Hive是Hadoop上的KillerApplication,Hive是Hadoop上的数据仓库,Hive同时兼具有数据仓库中的存储引擎和查询引擎的作用;而SparkSQL是一个更加出色和高级的查询引擎,所以在现在企业级应用中SparkSQL+Hive成为了业界使用大数据最为高效和流行的趋势。2,Hive是Facebook的推出,主要是为了让不动Java代码编程的人员也能
- 全面对比,深度解析 Ignite 与 Spark
xaio7biancheng
经常有人拿Ignite和Spark进行比较,然后搞不清两者的区别和联系。Ignite和Spark,如果笼统归类,都可以归于内存计算平台,然而两者功能上虽然有交集,并且Ignite也会对Spark进行支持,但是不管是从定位上,还是从功能上来说,它们差别巨大,适用领域有显著的区别。本文从各个方面对此进行对比分析,供各位技术选型参考。一、综述Ignite和Spark都为Apache的顶级开源项目,遵循A
- ignite redis_全面对比,深度解析 Ignite 与 Spark
weixin_39997696
igniteredis
经常有人拿Ignite和Spark进行比较,然后搞不清两者的区别和联系。Ignite和Spark,如果笼统归类,都可以归于内存计算平台,然而两者功能上虽然有交集,并且Ignite也会对Spark进行支持,但是不管是从定位上,还是从功能上来说,它们差别巨大,适用领域有显著的区别。本文从各个方面对此进行对比分析,供各位技术选型参考。一、综述Ignite和Spark都为Apache的顶级开源项目,遵循A
- 数据写入因为汉字引发的异常
qq_40841339
sparkhadoophivehivehadoop数据仓库
spark数据写hive表,发生查询分区异常问题异常:251071241926.49ERRORHive:MelaException(message.Exceptionthrownwhenexeculingquey.SELECTDISTINCT‘orgapache.hadop.hivemelastore.modelMpartionAs"NUCLEUSTYPE,AONCREATETIME,AO.LAS
- 语言合成模型Spark-TTS-0.5B学习笔记
tutgxuzyj
spark学习笔记
语言合成模型Spark-TTS-0.5B学习笔记语言合成是通过计算机技术将文字信息转换为自然流畅的语音输出,模拟人类语音。一、下载Spark-TTS-0.5B项目下载链接:https://github.com/SparkAudio/Spark-TTS.git注:需要科学网络。进入Spark-TTS文件夹,启动命令行窗口。创建Conda环境:condacreate-nsparktts-ypython
- Spark-TTS 使用
时间自由
AI人工智能
1.开发背景上一章节使用了MegaTTS3实现文本转语音,但是后面才发现只能使用官方的语言包,没看到克隆功能,所以重新找了一个可以克隆语音的开源模型。2.开发需求在Ubuntu下实现Spark-TTS的部署,实现官方语音克隆,根据自定义文本输出语音。3.开发环境Ubuntu20.04+Conda+Spark-TTS+RTX5060TI4.实现步骤4.1安装环境#创建环境python版本建议3.10
- Spark 的监控和性能调优高度依赖其内置的工具:【 Spark Web UI 和 Spark History Server】
csdn_tom_168
大数据spark大数据核心监控性能调优工具
Spark的监控和性能调优高度依赖其内置的SparkWebUI和SparkHistoryServer。它们是诊断作业性能瓶颈、资源利用率、错误原因和优化机会的最重要工具。一、SparkWebUI(DriverWebUI)当一个Spark应用程序(SparkContext)运行时,Driver进程会启动一个Web服务器,默认端口是4040(如果4040被占用,则尝试4041,4042等)。这是实时监
- 黑猴子的家:Spark RDD 编程进阶 之 广播变量
黑猴子的家
广播变量用来高效分发较大的对象。向所有工作节点发送一个较大的只读值,以供一个或多个Spark操作使用。比如,如果你的应用需要向所有节点发送一个较大的只读查询表,甚至是机器学习算法中的一个很大的特征向量,广播变量用起来都很顺手。传统方式下,Spark会自动把闭包中所有引用到的变量发送到工作节点上。虽然这很方便,但也很低效。原因有二:首先,默认的任务发射机制是专门为小任务进行优化的;其次,事实上你可能
- 开源项目ESP-SparkBot: ESP32-S3 大模型 AI 桌面机器人(复刻分享)
Qsm_lambda
机器人aiAI编程
一、前言ESP-SparkBot是官方大佬,乐鑫小铁匠开源在立创开源硬件平台的项目,此贴是用于分享与记录复刻过程。开源地址:(ESP-SparkBot-立创开源硬件平台(oshwhub.com))千人讨论Q群362367052二、项目简介ESP-SparkBot是⼀款基于ESP32-S3,集成语⾳交互、图像识别、遥控操作和多媒体功能于⼀体的智能设备。它不仅可以通过语⾳助⼿实现
- 数据科学与大数据技术专业的核心课程体系及发展路径全解析
YangYang9YangYan
大数据
CDA数据分析师证书含金量高,适应了未来数字化经济和AI发展趋势,难度不高,行业认可度高,对于找工作很有帮助。一、课程体系三维地图二、核心课程能力矩阵课程模块关键技能行业应用场景工具链分布式计算Spark调优用户行为日志分析AWSEMR/Databricks数据挖掘特征工程金融反欺诈模型Scikit-learn实时数据处理Flink窗口计算物联网设备监控Kafka+Flink数据治理元数据管理企业
- SpringBoot与ApacheSpark、MyBatis实战整合
KENYCHEN奉孝
spring实站大全java开发语言mybatisspring
基于SpringBoot和ApacheSpark开发的实例以下是基于SpringBoot和ApacheSpark整合开发的实用示例分类及关键点,涵盖数据处理、机器学习、实时分析等场景。每个示例均提供核心思路和代码片段(Markdown格式)。数据处理与ETL示例1:CSV文件读取与处理SparkSessionspark=SparkSession.builder().appName("CSVProc
- INVALID_COLUMN_NAME _AS_PATH
sparksql异常[INVALID_COLUMN_NAME_AS_PATH]ThedatasourceHiveFileFormatcannotsavethecolumnmin(birth_date)becauseitsnamecontainssomecharactersthatarenotallowedinfilepaths.Piease,useanallastorenameidemosqlSE
- Hive/Spark小文件解决方案(企业级实战)–参数和SQL优化
陆水A
大数据hivehadoopsparkpython
重点是后面的参数优化一、小文件的定义在Hadoop的上下文中,小文件的定义是相对于Hadoop分布式文件系统(HDFS)的块(Block)大小而言的。HDFS是Hadoop生态系统中的核心组件之一,它设计用于存储和处理大规模数据集。在HDFS中,数据被分割成多个块,每个块的大小是固定的,这个大小在Hadoop的不同版本和配置中可能有所不同,但常见的默认块大小包括128MB、256MB等。基于这个背
- Spark核心--RDD介绍
陆水A
大数据spark大数据分布式
一、RDD的介绍rdd弹性分布式数据集是spark框架自己封装的数据类型,用来管理内存数据数据集:rdd数据的格式类似Python中[]。hive中的该结构[]叫数组rdd提供算子(方法)方便开发人员进行调用计算数据在pysaprk中本质是定义一个rdd类型用来管理和计算内存数据分布式:rdd可以时使用多台机器的内存资源完成计算弹性:可以通过分区将数据分成多份234,每份数据对应一个task线程处
- C++与Hive、Spark、libhdfs、ACID交互技巧
KENYCHEN奉孝
C++开发语言springC++hivespark
C++与Hive交互的实例以下是C++与Hive交互的实例代码片段,涵盖连接、查询、数据操作等常见场景。假设使用libhdfs或thrift接口实现,部分示例需要结合Hive环境配置。基础连接与查询示例1:通过Thrift连接HiveServer2#include#include#includeusingnamespaceapache::thrift;usingnamespaceapache::h
- 全面的Spark学习资料合集:从基础到高级应用
本文还有配套的精品资源,点击获取简介:Spark是一个受到数据科学界青睐的大数据处理框架,以其高效、易用和可扩展性著称。本资料合集包括了Spark的基础学习材料、实战案例分析和高级应用实践,内容覆盖从Scala编程语言基础到Spark核心功能使用,再到大数据领域的实际应用。适合不同层次的学习者深入学习Spark,无论是初学者还是有经验的开发者,都能从中找到有价值的学习资源,帮助理解和掌握Spark
- 一文带你理清Spark Core调优的方方面面
即将秃头的Java程序员
前言本文的注意事项观看本文前,可以先百度搜索一下Spark程序的十大开发原则看看哦文章虽然很长,可并不是什么枯燥乏味的内容,而且都是面试时的干货(我觉得)可以结合PC端的目录食用,可以直接跳转到你想要的那部分内容图非常的重要,是文章中最有价值的部分。如果不是很重要的图一般不会亲手画,特别是本文2.2.6的图非常重要此文会很大程度上借鉴美团的文章分享内容和Spark官方资料去进行说明,也会结合笔者自
- AI系统Spark原理与代码实战案例讲解
AI天才研究院
AI大模型企业级应用开发实战AgenticAI实战AI人工智能与大数据计算科学神经计算深度学习神经网络大数据人工智能大型语言模型AIAGILLMJavaPython架构设计AgentRPA
AI系统Spark原理与代码实战案例讲解作者:禅与计算机程序设计艺术/ZenandtheArtofComputerProgramming关键词:Spark、大数据处理、分布式计算、机器学习、数据挖掘、实时流处理1.背景介绍1.1问题的由来在大数据时代,海量数据的高效处理和分析已成为各行各业的迫切需求。传统的数据处理方式难以应对数据量激增、数据类型多样化以及实时性要求高等挑战。为了解决这些问题,Ap
- Spark大数据处理讲课笔记4.8 Spark SQL典型案例
酒城译痴无心剑
#Spark基础学习笔记(1)spark笔记sql
文章目录零、本讲学习目标一、使用SparkSQL实现词频统计(一)提出任务(二)实现任务1、准备数据文件2、创建Maven项目3、修改源程序目录4、添加依赖和设置源程序目录5、创建日志属性文件6、创建HDFS配置文件7、创建词频统计单例对象8、启动程序,查看结果9、词频统计数据转化流程图二、使用SparkSQL计算总分与平均分(一)提出任务(二)完成任务1、准备数据文件2、新建Maven项目3、修
- 手撕Spark之WordCount RDD执行流程
啊Abu
Sparkspark
手撕Spark之WordCountRDD执行流程文章目录手撕Spark之WordCountRDD执行流程写在前面软件环境代码过程分析写在前面一个Spark程序在初始化的时候会构造DAGScheduler、TaskSchedulerImpl、MapOutTrackerMaster等对象,DAGScheduler主要负责生成DAG、启动Job、提交Stage等操作,TaskSchedulerImpl主
- 【大数据学习 | Spark-Core】RDD的概念与Spark任务的执行流程
Vez'nan的幸福生活
大数据sparkoraclesqljson
1.RDD的设计背景在实际应用中,存在许多迭代式计算,这些应用场景的共同之处是,不同计算阶段之间会重用中间结果,即一个阶段的输出结果会作为下一个阶段的输入。但是,目前的MapReduce框架都是把中间结果写入到HDFS中,带来了大量的数据复制、磁盘IO和序列化开销。显然,如果能将结果保存在内存当中,就可以大量减少IO。RDD就是为了满足这种需求而出现的,它提供了一个抽象的数据架构,我们不必担心底层
- 第84课:StreamingContext、DStream、Receiver深度剖析
chengnidi5193
StreamingContext、DStream、Receiver深度剖析编写人:姜伟、唐陈昊、龚湄燕本课分成四部分讲解,第一部分对StreamingContext功能及源码剖析;第二部分对DStream功能及源码剖析;第三部分对Receiver功能及源码剖析;最后一部分将StreamingContext、DStream、Receiver结合起来分析其流程。1、通过SparkStreaming对象
- Hbase BulkLoad用法
kikiki2
要导入大量数据,Hbase的BulkLoad是必不可少的,在导入历史数据的时候,我们一般会选择使用BulkLoad方式,我们还可以借助Spark的计算能力将数据快速地导入。使用方法导入依赖包compilegroup:'org.apache.spark',name:'spark-sql_2.11',version:'2.3.1.3.0.0.0-1634'compilegroup:'org.apach
- Python 大数据分析(二)
绝不原创的飞龙
默认分类默认分类
原文:annas-archive.org/md5/5058e6970bd2a8d818ecc1f7f8fef74a译者:飞龙协议:CCBY-NC-SA4.0第六章:第五章处理缺失值和相关性分析学习目标到本章结束时,你将能够:使用PySpark检测和处理数据中的缺失值描述变量之间的相关性计算PySpark中两个或多个变量之间的相关性使用PySpark创建相关矩阵在本章中,我们将使用Iris数据集处理
- DolphinScheduler 如何高效调度 AnalyticDB on Spark 作业?
DolphinScheduler社区
spark大数据分布式
DolphinScheduler是一个分布式易扩展的可视化DAG工作流任务调度开源系统,能高效地执行和管理大数据流程。用户可以在DolphinSchedulerWeb界面轻松创建、编辑和调度云原生数据仓库AnalyticDBMySQL版的Spark作业。前提条件AnalyticDBforMySQL集群的产品系列为企业版、基础版或湖仓版。AnalyticDBforMySQL集群中已创建Job型资源组
- 【Spark征服之路-3.7-Spark-SQL核心编程(六)】
qq_46394486
sparksqlajax
数据加载与保存:通用方式:SparkSQL提供了通用的保存数据和数据加载的方式。这里的通用指的是使用相同的API,根据不同的参数读取和保存不同格式的数据,SparkSQL默认读取和保存的文件格式为parquet加载数据:spark.read.load是加载数据的通用方法。如果读取不同格式的数据,可以对不同的数据格式进行设定。spark.read.format("…")[.option("…")].
- 深入解析 Spark:关键问题与答案汇总
※尘
sqlhivespark
在大数据处理领域,Spark凭借其高效的计算能力和丰富的功能,成为了众多开发者和企业的首选框架。然而,在使用Spark的过程中,我们会遇到各种各样的问题,从性能优化到算子使用等。本文将围绕Spark的一些核心问题进行详细解答,帮助大家更好地理解和运用Spark。Spark性能优化策略Spark性能优化是提升作业执行效率的关键,主要可以从以下几个方面入手:首先,资源配置优化至关重要。合理设置Exec
- spark on yarn
不辉放弃
pyspark大数据开发
SparkonYARN是指将Spark应用程序运行在HadoopYARN集群上,借助YARN的资源管理和调度能力来管理Spark的计算资源。这种模式能充分利用现有Hadoop集群资源,简化集群管理,是企业中常用的Spark部署方式。核心角色•Spark应用:包含Driver进程和Executor进程。Driver负责任务调度、逻辑处理;Executor负责执行具体任务并存储数据。•YARN组件:◦
- 设计模式介绍
tntxia
设计模式
设计模式来源于土木工程师 克里斯托弗 亚历山大(http://en.wikipedia.org/wiki/Christopher_Alexander)的早期作品。他经常发表一些作品,内容是总结他在解决设计问题方面的经验,以及这些知识与城市和建筑模式之间有何关联。有一天,亚历山大突然发现,重复使用这些模式可以让某些设计构造取得我们期望的最佳效果。
亚历山大与萨拉-石川佳纯和穆雷 西乐弗斯坦合作
- android高级组件使用(一)
百合不是茶
androidRatingBarSpinner
1、自动完成文本框(AutoCompleteTextView)
AutoCompleteTextView从EditText派生出来,实际上也是一个文本编辑框,但它比普通编辑框多一个功能:当用户输入一个字符后,自动完成文本框会显示一个下拉菜单,供用户从中选择,当用户选择某个菜单项之后,AutoCompleteTextView按用户选择自动填写该文本框。
使用AutoCompleteTex
- [网络与通讯]路由器市场大有潜力可挖掘
comsci
网络
如果国内的电子厂商和计算机设备厂商觉得手机市场已经有点饱和了,那么可以考虑一下交换机和路由器市场的进入问题.....
这方面的技术和知识,目前处在一个开放型的状态,有利于各类小型电子企业进入
&nbs
- 自写简单Redis内存统计shell
商人shang
Linux shell统计Redis内存
#!/bin/bash
address="192.168.150.128:6666,192.168.150.128:6666"
hosts=(${address//,/ })
sfile="staticts.log"
for hostitem in ${hosts[@]}
do
ipport=(${hostitem
- 单例模式(饿汉 vs懒汉)
oloz
单例模式
package 单例模式;
/*
* 应用场景:保证在整个应用之中某个对象的实例只有一个
* 单例模式种的《 懒汉模式》
* */
public class Singleton {
//01 将构造方法私有化,外界就无法用new Singleton()的方式获得实例
private Singleton(){};
//02 申明类得唯一实例
priva
- springMvc json支持
杨白白
json springmvc
1.Spring mvc处理json需要使用jackson的类库,因此需要先引入jackson包
2在spring mvc中解析输入为json格式的数据:使用@RequestBody来设置输入
@RequestMapping("helloJson")
public @ResponseBody
JsonTest helloJson() {
- android播放,掃描添加本地音頻文件
小桔子
最近幾乎沒有什麽事情,繼續鼓搗我的小東西。想在項目中加入一個簡易的音樂播放器功能,就像華為p6桌面上那麼大小的音樂播放器。用過天天動聽或者QQ音樂播放器的人都知道,可已通過本地掃描添加歌曲。不知道他們是怎麼實現的,我覺得應該掃描設備上的所有文件,過濾出音頻文件,每個文件實例化為一個實體,記錄文件名、路徑、歌手、類型、大小等信息。具體算法思想,
- oracle常用命令
aichenglong
oracledba常用命令
1 创建临时表空间
create temporary tablespace user_temp
tempfile 'D:\oracle\oradata\Oracle9i\user_temp.dbf'
size 50m
autoextend on
next 50m maxsize 20480m
extent management local
- 25个Eclipse插件
AILIKES
eclipse插件
提高代码质量的插件1. FindBugsFindBugs可以帮你找到Java代码中的bug,它使用Lesser GNU Public License的自由软件许可。2. CheckstyleCheckstyle插件可以集成到Eclipse IDE中去,能确保Java代码遵循标准代码样式。3. ECLemmaECLemma是一款拥有Eclipse Public License许可的免费工具,它提供了
- Spring MVC拦截器+注解方式实现防止表单重复提交
baalwolf
spring mvc
原理:在新建页面中Session保存token随机码,当保存时验证,通过后删除,当再次点击保存时由于服务器端的Session中已经不存在了,所有无法验证通过。
1.新建注解:
? 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18
- 《Javascript高级程序设计(第3版)》闭包理解
bijian1013
JavaScript
“闭包是指有权访问另一个函数作用域中的变量的函数。”--《Javascript高级程序设计(第3版)》
看以下代码:
<script type="text/javascript">
function outer() {
var i = 10;
return f
- AngularJS Module类的方法
bijian1013
JavaScriptAngularJSModule
AngularJS中的Module类负责定义应用如何启动,它还可以通过声明的方式定义应用中的各个片段。我们来看看它是如何实现这些功能的。
一.Main方法在哪里
如果你是从Java或者Python编程语言转过来的,那么你可能很想知道AngularJS里面的main方法在哪里?这个把所
- [Maven学习笔记七]Maven插件和目标
bit1129
maven插件
插件(plugin)和目标(goal)
Maven,就其本质而言,是一个插件执行框架,Maven的每个目标的执行逻辑都是由插件来完成的,一个插件可以有1个或者几个目标,比如maven-compiler-plugin插件包含compile和testCompile,即maven-compiler-plugin提供了源代码编译和测试源代码编译的两个目标
使用插件和目标使得我们可以干预
- 【Hadoop八】Yarn的资源调度策略
bit1129
hadoop
1. Hadoop的三种调度策略
Hadoop提供了3中作业调用的策略,
FIFO Scheduler
Fair Scheduler
Capacity Scheduler
以上三种调度算法,在Hadoop MR1中就引入了,在Yarn中对它们进行了改进和完善.Fair和Capacity Scheduler用于多用户共享的资源调度
2. 多用户资源共享的调度
- Nginx使用Linux内存加速静态文件访问
ronin47
Nginx是一个非常出色的静态资源web服务器。如果你嫌它还不够快,可以把放在磁盘中的文件,映射到内存中,减少高并发下的磁盘IO。
先做几个假设。nginx.conf中所配置站点的路径是/home/wwwroot/res,站点所对应文件原始存储路径:/opt/web/res
shell脚本非常简单,思路就是拷贝资源文件到内存中,然后在把网站的静态文件链接指向到内存中即可。具体如下:
- 关于Unity3D中的Shader的知识
brotherlamp
unityunity资料unity教程unity视频unity自学
首先先解释下Unity3D的Shader,Unity里面的Shaders是使用一种叫ShaderLab的语言编写的,它同微软的FX文件或者NVIDIA的CgFX有些类似。传统意义上的vertex shader和pixel shader还是使用标准的Cg/HLSL 编程语言编写的。因此Unity文档里面的Shader,都是指用ShaderLab编写的代码,然后我们来看下Unity3D自带的60多个S
- CopyOnWriteArrayList vs ArrayList
bylijinnan
java
package com.ljn.base;
import java.util.ArrayList;
import java.util.Iterator;
import java.util.List;
import java.util.concurrent.CopyOnWriteArrayList;
/**
* 总述:
* 1.ArrayListi不是线程安全的,CopyO
- 内存中栈和堆的区别
chicony
内存
1、内存分配方面:
堆:一般由程序员分配释放, 若程序员不释放,程序结束时可能由OS回收 。注意它与数据结构中的堆是两回事,分配方式是类似于链表。可能用到的关键字如下:new、malloc、delete、free等等。
栈:由编译器(Compiler)自动分配释放,存放函数的参数值,局部变量的值等。其操作方式类似于数据结构中
- 回答一位网友对Scala的提问
chenchao051
scalamap
本来准备在私信里直接回复了,但是发现不太方便,就简要回答在这里。 问题 写道 对于scala的简洁十分佩服,但又觉得比较晦涩,例如一例,Map("a" -> List(11,111)).flatMap(_._2),可否说下最后那个函数做了什么,真正在开发的时候也会如此简洁?谢谢
先回答一点,在实际使用中,Scala毫无疑问就是这么简单。
- mysql 取每组前几条记录
daizj
mysql分组最大值最小值每组三条记录
一、对分组的记录取前N条记录:例如:取每组的前3条最大的记录 1.用子查询: SELECT * FROM tableName a WHERE 3> (SELECT COUNT(*) FROM tableName b WHERE b.id=a.id AND b.cnt>a. cnt) ORDER BY a.id,a.account DE
- HTTP深入浅出 http请求
dcj3sjt126com
http
HTTP(HyperText Transfer Protocol)是一套计算机通过网络进行通信的规则。计算机专家设计出HTTP,使HTTP客户(如Web浏览器)能够从HTTP服务器(Web服务器)请求信息和服务,HTTP目前协议的版本是1.1.HTTP是一种无状态的协议,无状态是指Web浏览器和Web服务器之间不需要建立持久的连接,这意味着当一个客户端向服务器端发出请求,然后We
- 判断MySQL记录是否存在方法比较
dcj3sjt126com
mysql
把数据写入到数据库的时,常常会碰到先要检测要插入的记录是否存在,然后决定是否要写入。
我这里总结了判断记录是否存在的常用方法:
sql语句: select count ( * ) from tablename;
然后读取count(*)的值判断记录是否存在。对于这种方法性能上有些浪费,我们只是想判断记录记录是否存在,没有必要全部都查出来。
- 对HTML XML的一点认识
e200702084
htmlxml
感谢http://www.w3school.com.cn提供的资料
HTML 文档中的每个成分都是一个节点。
节点
根据 DOM,HTML 文档中的每个成分都是一个节点。
DOM 是这样规定的:
整个文档是一个文档节点
每个 HTML 标签是一个元素节点
包含在 HTML 元素中的文本是文本节点
每一个 HTML 属性是一个属性节点
注释属于注释节点
Node 层次
- jquery分页插件
genaiwei
jqueryWeb前端分页插件
//jquery页码控件// 创建一个闭包 (function($) { // 插件的定义 $.fn.pageTool = function(options) { var totalPa
- Mybatis与Ibatis对照入门于学习
Josh_Persistence
mybatisibatis区别联系
一、为什么使用IBatis/Mybatis
对于从事 Java EE 的开发人员来说,iBatis 是一个再熟悉不过的持久层框架了,在 Hibernate、JPA 这样的一站式对象 / 关系映射(O/R Mapping)解决方案盛行之前,iBaits 基本是持久层框架的不二选择。即使在持久层框架层出不穷的今天,iBatis 凭借着易学易用、
- C中怎样合理决定使用那种整数类型?
秋风扫落叶
c数据类型
如果需要大数值(大于32767或小于32767), 使用long 型。 否则, 如果空间很重要 (如有大数组或很多结构), 使用 short 型。 除此之外, 就使用 int 型。 如果严格定义的溢出特征很重要而负值无关紧要, 或者你希望在操作二进制位和字节时避免符号扩展的问题, 请使用对应的无符号类型。 但是, 要注意在表达式中混用有符号和无符号值的情况。
&nbs
- maven问题
zhb8015
maven问题
问题1:
Eclipse 中 新建maven项目 无法添加src/main/java 问题
eclipse创建maevn web项目,在选择maven_archetype_web原型后,默认只有src/main/resources这个Source Floder。
按照maven目录结构,添加src/main/ja
- (二)androidpn-server tomcat版源码解析之--push消息处理
spjich
javaandrodipn推送
在 (一)androidpn-server tomcat版源码解析之--项目启动这篇中,已经描述了整个推送服务器的启动过程,并且把握到了消息的入口即XmppIoHandler这个类,今天我将继续往下分析下面的核心代码,主要分为3大块,链接创建,消息的发送,链接关闭。
先贴一段XmppIoHandler的部分代码
/**
* Invoked from an I/O proc
- 用js中的formData类型解决ajax提交表单时文件不能被serialize方法序列化的问题
中华好儿孙
JavaScriptAjaxWeb上传文件FormData
var formData = new FormData($("#inputFileForm")[0]);
$.ajax({
type:'post',
url:webRoot+"/electronicContractUrl/webapp/uploadfile",
data:formData,
async: false,
ca
- mybatis常用jdbcType数据类型
ysj5125094
mybatismapperjdbcType
MyBatis 通过包含的jdbcType
类型
BIT FLOAT CHAR