Pytorch学习笔记【14】:自编码(autoencoder)
一. 什么是自编码
自编码是什么呢?就是说假如我们需要训练的数据量非常大,那么 神经网络的压力是很大的,所以我们可以 将其压缩一下,再解压,通过对比解压之后的和原来的 数据,反向传播去训练,训练好之后,我们再需要 用到这批数据,就 只需用压缩之后的数据即可,这样就大大减小了神经网络的训练压力,增加了训练效率。看下图就明白了:


二. 简单自编码模型实现(以手写数字数据集为例子)
1. 代码
import torch
import torch.nn as nn
import torch.utils.data as Data
import torchvision
import numpy as np
import matplotlib.pyplot as plt
from mpl_toolkits.mplot3d import Axes3D
from matplotlib import cm
# 定义一些参数
EPOCH = 10
BATCH_SIZE = 64
LR = 0.005
DOWNLOAD_MNIST = False
N_TEST_IMG = 5
# 加载数据集
train_data = torchvision.datasets.MNIST(
root = './mnist', # 数据集下载目录
train=True, # 下载训练集
transform=torchvision.transforms.ToTensor(), # 转换成Tensor数据
download=DOWNLOAD_MNIST, # 这里我定义为False,因为我已经有这个数据集了,你没有的话,要设置为True
)
# 画出一个例子
# print(train_data.train_data.size()) # (60000, 28, 28)
# print(train_data.train_labels.size()) # (60000)
# plt.imshow(train_data.train_data[2].numpy(), cmap='gray')
# plt.title('%i' % train_data.train_labels[2])
# plt.show()
# 加载数据集
train_loader = Data.DataLoader(dataset=train_data,batch_size=BATCH_SIZE,shuffle=True)
class AutoEncoder(nn.Module):
def __init__(self):
super(AutoEncoder, self).__init__()
# 定义压缩层
self.encoder = nn.Sequential(
nn.Linear(28*28,128),
nn.Tanh(),
nn.Linear(128,64),
nn.Tanh(),
nn.Linear(64,12),
nn.Tanh(),
nn.Linear(12,3),
)
# 定义解码
self.decoder = nn.Sequential(
nn.Linear(3,12),
nn.Tanh(),
nn.Linear(12,64),
nn.Tanh(),
nn.Linear(64,128),
nn.Tanh(),
nn.Linear(128,28*28),
nn.Sigmoid(), # 使它在(0,1)的范围里面
)
def forward(self,x):
encoded = self.encoder(x)
decoded = self.decoder(encoded)
return encoded,decoded
autoencoder = AutoEncoder()
optimizer = torch.optim.Adam(autoencoder.parameters(), lr=LR)
loss_func = nn.MSELoss()
# initialize figure
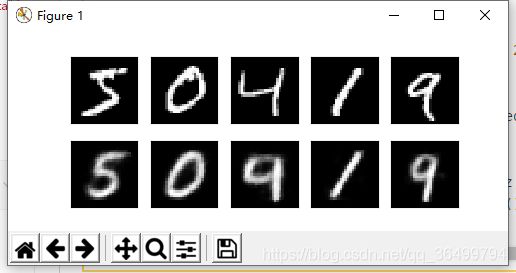
f, a = plt.subplots(2, N_TEST_IMG, figsize=(5, 2))
plt.ion() # continuously plot
# original data (first row) for viewing
view_data = train_data.train_data[:N_TEST_IMG].view(-1, 28*28).type(torch.FloatTensor)/255.
for i in range(N_TEST_IMG):
a[0][i].imshow(np.reshape(view_data.data.numpy()[i], (28, 28)), cmap='gray'); a[0][i].set_xticks(()); a[0][i].set_yticks(())
for epoch in range(EPOCH):
for step, (x, b_label) in enumerate(train_loader):
# b_x和b_y实际上是同样的数据,就是用x去压缩再解码看和原来的x的差别,再反向传播进行训练。
b_x = x.view(-1, 28*28) # batch x, shape (batch, 28*28)
b_y = x.view(-1, 28*28) # batch y, shape (batch, 28*28)
encoded, decoded = autoencoder(b_x)
loss = loss_func(decoded, b_y) # mean square error
optimizer.zero_grad() # clear gradients for this training step
loss.backward() # backpropagation, compute gradients
optimizer.step() # apply gradients
if step % 100 == 0:
print('Epoch: ', epoch, '| train loss: %.4f' % loss.data.numpy())
# plotting decoded image (second row)
_, decoded_data = autoencoder(view_data)
for i in range(N_TEST_IMG):
a[1][i].clear()
a[1][i].imshow(np.reshape(decoded_data.data.numpy()[i], (28, 28)), cmap='gray')
a[1][i].set_xticks(()); a[1][i].set_yticks(())
plt.draw(); plt.pause(0.05)
plt.ioff()
plt.show()
# visualize in 3D plot
view_data = train_data.train_data[:200].view(-1, 28*28).type(torch.FloatTensor)/255.
encoded_data, _ = autoencoder(view_data)
fig = plt.figure(2); ax = Axes3D(fig)
X, Y, Z = encoded_data.data[:, 0].numpy(), encoded_data.data[:, 1].numpy(), encoded_data.data[:, 2].numpy()
values = train_data.train_labels[:200].numpy()
for x, y, z, s in zip(X, Y, Z, values):
c = cm.rainbow(int(255*s/9)); ax.text(x, y, z, s, backgroundcolor=c)
ax.set_xlim(X.min(), X.max()); ax.set_ylim(Y.min(), Y.max()); ax.set_zlim(Z.min(), Z.max())
plt.show()
2. 运行结果