从浏览器渲染原理谈性能优化(2017版)
随着技术的革新,我们有了越来越多的方案去提升页面性能,因此在2019年进行了本篇文章的更新。更新内容包括:
1、网络通信部分的细节化,包括:
- 网络时延、tcp简述
- HTTP个协议间差别及如何对应优化
- HTTP2将对原有优化方案存在那些影响等
2、性能优化方案的增加与说明,包括:
- 资源预取
- 通用优化方案
- 针对页面渲染规则的优化方案(js、css)
- 如何借助chrome进行性能分析与优化
- 附录
3、附录:相关博客推荐
如果你对这些细节更感兴趣,请移步
https://blog.csdn.net/riddle1981/article/details/90756332
而如果你更关心浏览器渲染原理而非性能优化方案,以下为正文:
前言
| 以前学习浏览器的渲染机制时,对浏览器的渲染概念就是html解析成DOM,css形成样式规则。两者共同构建渲染树。浏览器根据渲染树的样式进行布局和渲染。后来再次回过头去看这些概念时发现很多知识点都是非常深的。 比如浏览器如何解析CSS形成样式树,那么浏览器究竟如何解析?了解这些并非没有意义,比如当了解css解析是自右向左后,就知道在写css样式时应该避免嵌套。了解解析顺序就知道如何缩短首屏时间提高用户体验。所以决定将这段时间的所学整理出来形成知识体系。有些的不足和不到位的地方还请大家不吝指正或提出建议 |
一、关于浏览器渲染的容易误解点总结
| 关于浏览器渲染机制已经是老生常谈,如果你想了解[请点这里](http://blog.csdn.net/riddle1981/article/details/76380177),而且网上现有资料中有非常多的优秀资料对此进行阐述。遗憾的是网上的资料良莠不齐,经常在不同的文档中对同一件事的描述出现了极大的差异。怀着严谨求学的态度经过大量资料的查阅和请教,将会在后文总结出一个完整的流程。在这里将会就一些我自己理解存疑的地方写出来 |
1、DOM树的构建是文档加载完成开始的?
DOM树的构建是从接受到文档开始的 一边会进行将字节转化为字符 字符转化为标记 标记构建dom树
这个过程被分为标记化和树构建
而这是一个渐进的过程。为达到更好的用户体验,呈现引擎会力求尽快将内容显示在屏幕上。它不必等到整个 HTML 文档解析完毕之后,就会开始构建呈现树和设置布局。在不断接收和处理来自网络的其余内容的同时,呈现引擎会将部分内容解析并显示出来。
参考文档:http://taligarsiel.com/Projects/howbrowserswork1.htm
2、渲染树是在DOM树和CSS样式树构建完毕才开始构建的吗?
这三个过程在实际进行的时候又不是完全独立,而是会有交叉。会造成一边加载,一边解析,一边渲染的工作现象。
参考文档:http://www.jianshu.com/p/2d522fc2a8f8
3、css的标签嵌套越多,越容易定位到元素
css的解析是自右至左逆向解析的,嵌套越多越增加浏览器的工作量,而不会越快。
因为如果正向解析,例如「div div p em」,我们首先就要检查当前元素到 html 的整条路径,找到最上层的 div,再往下找,如果遇到不匹配就必须回到最上层那个 div,往下再去匹配选择器中的第一个 div,回溯若干次才能确定匹配与否,效率很低。
逆向匹配则不同,如果当前的 DOM 元素是 div,而不是 selector 最后的 em,那只要一步就能排除。只有在匹配时,才会不断向上找父节点进行验证。
打个比方 p span.showing
你认为从一个p元素下面找到所有的span元素并判断是否有class showing快,还是找到所有的span元素判断是否有class showing并且包括一个p父元素快
参考文档:http://www.imooc.com/code/4570
二、页面渲染的完整流程
| 当浏览器拿到HTTP报文时呈现引擎将开始解析 HTML 文档,并将各标记逐个转化成“内容树”上的 DOM 节点。同时也会解析外部 CSS 文件以及样式元素中的样式数据。HTML 中这些带有视觉指令的样式信息将用于创建另一个树结构:呈现树。浏览器将根据呈现树进行布局绘制。 |
以上就是页面渲染的大致流程。那么浏览器从用户输入网址之后到底做了什么呢?以下将会进行一个完整的梳理。鉴于本文是前端向的所以梳理内容会有所偏重。而从输入到呈现可以分为两个部分:网络通信和页面渲染
我们首先来看网络通信部分:
1、用户输入url并敲击回车。
**2、进行DNS解析。**如果用户输入的是ip地址则直接进入第三条。但去记录毫无规律且冗长的ip地址显然不是易事,所以通常都是输入的域名,此时就会进行dns解析。所谓DNS(Domain Name System)指域名系统。因特网上作为域名和IP地址相互映射的一个分布式数据库,能够使用户更方便的访问互联网,而不用去记住能够被机器直接读取的IP数串。通过主机名,最终得到该主机名对应的IP地址的过程叫做域名解析(或主机名解析)。这个过程如下所示:
浏览器会首先搜索浏览器自身的DNS缓存(缓存时间比较短,大概只有2分钟左右,且只能容纳1000条缓存)。
- 如果浏览器自身缓存找不到则会查看系统的DNS缓存,如果找到且没有过期则停止搜索解析到此结束.
- 而如果本机没有找到DNS缓存,则浏览器会发起一个DNS的系统调用,就会向本地配置的首选DNS服务器发起域名解析请求(通过的是UDP协议向DNS的53端口发起请求,这个请求是递归的请求,也就是运营商的DNS服务器必须得提供给我们该域名的IP地址),运营商的DNS服务器首先查找自身的缓存,找到对应的条目,且没有过期,则解析成功。
- 如果没有找到对应的条目,则有运营商的DNS代我们的浏览器发起迭代DNS解析请求,它首先是会找根域的DNS的IP地址(这个DNS服务器都内置13台根域的DNS的IP地址),找打根域的DNS地址,就会向其发起请求(请问www.xxxx.com这个域名的IP地址是多少啊?)
- 根域发现这是一个顶级域com域的一个域名,于是就告诉运营商的DNS我不知道这个域名的IP地址,但是我知道com域的IP地址,你去找它去,于是运营商的DNS就得到了com域的IP地址,又向com域的IP地址发起了请求(请问www.xxxx.com这个域名的IP地址是多少?),com域这台服务器告诉运营商的DNS我不知道www.xxxx.com这个域名的IP地址,但是我知道xxxx.com这个域的DNS地址,你去找它去,于是运营商的DNS又向linux178.com这个域名的DNS地址(这个一般就是由域名注册商提供的,像万网,新网等)发起请求(请问www.xxxx.com这个域名的IP地址是多少?),这个时候xxxx.com域的DNS服务器一查,诶,果真在我这里,于是就把找到的结果发送给运营商的DNS服务器,这个时候运营商的DNS服务器就拿到了www.xxxx.com这个域名对应的IP地址,并返回给Windows系统内核,内核又把结果返回给浏览器,终于浏览器拿到了www.xxxx.com对应的IP地址,这次dns解析圆满成功。
3、发起TCP的3次握手
拿到域名对应的IP地址之后,User-Agent(一般是指浏览器)会以一个随机端口(1024< 端口 < 65535)向服务器的WEB程序(常用的有httpd,nginx等)80端口发起TCP的连接请求。这个连接请求(原始的http请求经过TCP/IP4层模型的层层封包)到达服务器端后(这中间通过各种路由设备,局域网内除外),进入到网卡,然后是进入到内核的TCP/IP协议栈(用于识别该连接请求,解封包,一层一层的剥开),还有可能要经过Netfilter防火墙(属于内核的模块)的过滤,最终到达WEB程序,最终建立了TCP/IP的连接。
4、建立TCP连接后发起http请求
5、服务器端响应http请求,浏览器得到html代码。以下为响应报文格式:
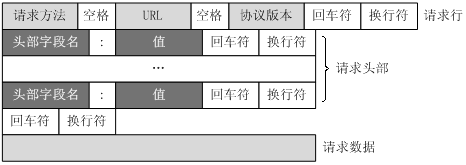
| 以上是网络通信部分,接下来将会对页面渲染部分进行叙述。当浏览器拿到html后是如何进行页面渲染的 |
-
当浏览器拿到HTML文档时首先会进行HTML文档解析,构建DOM树。
-
遇到css样式如link标签或者style标签时开始解析css,构建样式树。HTML解析构建和CSS的解析是相互独立的并不会造成冲突,因此我们通常将css样式放在head中,让浏览器尽早解析css。
-
当html的解析遇到script标签会怎样呢?答案是停止DOM树的解析开始下载js。**因为js是会阻塞html解析的,是阻塞资源。其原因在于js可能会改变html现有结构。**例如有的节点是用js动态构建的,在这种情况下就会停止dom树的构建开始下载解析js。脚本在文档的何处插入,就在何处执行。当 HTML 解析器遇到一个 script 标记时,它会暂停构建 DOM,将控制权移交给 JavaScript 引擎;等 JavaScript 引擎运行完毕,浏览器会从中断的地方恢复 DOM 构建。而因此就会推迟页面首绘的时间。**可以在首绘不需要js的情况下用async和defer实现异步加载。这样js就不会阻塞html的解析了。**当HTML解析完成后,浏览器会将文档标注为交互状态,并开始解析那些处于“deferred”模式的脚本,也就是那些应在文档解析完成后才执行的脚本。然后,文档状态将设置为“完成”,一个“加载”事件将随之触发。注意,异步执行是指下载。执行js时仍然会阻塞。
-
在得到DOM树和样式树后就可以进行渲染树的构建了。应注意的是渲染树和 DOM 元素相对应的,但并非一一对应。比如非可视化的 DOM 元素不会插入呈现树中,例如“head”元素。如果元素的 display 属性值为“none”,那么也不会显示在呈现树中(但是 visibility 属性值为“hidden”的元素仍会显示)
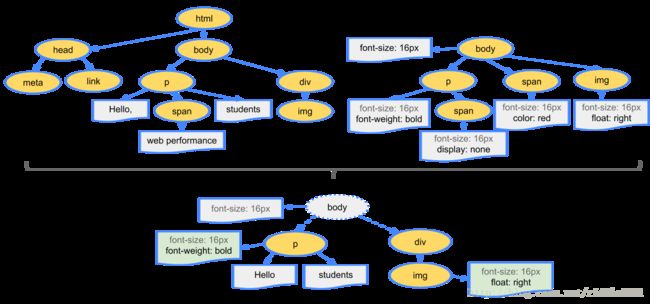
-
渲染树构建完毕后将会进行布局。布局使用流模型的Layout算法。所谓流模型,即是指Layout的过程只需进行一遍即可完成,后出现在流中的元素不会影响前出现在流中的元素,Layout过程只需从左至右从上至下一遍完成即可。但实际实现中,流模型会有例外。Layout是一个递归的过程,每个节点都负责自己及其子节点的Layout。Layout结果是相对父节点的坐标和尺寸。其过程可以简述为:
父节点确定自己的宽度 父节点完成子节点放置,确定其相对坐标 节点确定自己的宽度和高度 父节点根据所有的子节点高度计算自己的高度 -
此时renderTree已经构建完毕,不过浏览器渲染树引擎并不直接使用渲染树进行绘制,为了方便处理定位(裁剪),溢出滚动(页内滚动),CSS转换/不透明/动画/滤镜,蒙版或反射,Z (Z排序)等,浏览器需要生成另外一棵树 - 层树。因此绘制过程如下:
获取 DOM 并将其分割为多个层(RenderLayer)
将每个层栅格化,并独立的绘制进位图中
将这些位图作为纹理上传至 GPU
复合多个层来生成最终的屏幕图像(终极layer)。
三、HTML及CSS样式的解析
| HTML解析是一个将字节转化为字符,字符解析为标记,标记生成节点,节点构建树的过程。。CSS样式的解析则由于复杂的样式层叠而变得复杂。对此不同的渲染引擎在处理上有所差异,后文将会就这点进行详细讲解 |
1、HTML的解析分为标记化和树构建两个阶段
标记化算法:
是词法分析过程,将输入内容解析成多个标记。HTML标记包括起始标记、结束标记、属性名称和属性值。标记生成器识别标记,传递给树构造器,然后接受下一个字符以识别下一个标记;如此反复直到输入的结束。
该算法的输出结果是 HTML 标记。该算法使用状态机来表示。每一个状态接收来自输入信息流的一个或多个字符,并根据这些字符更新下一个状态。当前的标记化状态和树结构状态会影响进入下一状态的决定。这意味着,即使接收的字符相同,对于下一个正确的状态也会产生不同的结果,具体取决于当前的状态。
树构建算法
在树构建阶段,以 Document 为根节点的 DOM 树也会不断进行修改,向其中添加各种元素。
标记生成器发送的每个节点都会由树构建器进行处理。规范中定义了每个标记所对应的 DOM 元素,这些元素会在接收到相应的标记时创建。这些元素不仅会添加到 DOM 树中,还会添加到开放元素的堆栈中。此堆栈用于纠正嵌套错误和处理未关闭的标记。其算法也可以用状态机来描述。这些状态称为“插入模式”。
以下将会举一个例子来分析这两个阶段:
Hello world
标记化:初始状态是数据状态。遇到字符 < 时,状态更改为“标记打开状态”。接收一个 a-z字符会创建“起始标记”,状态更改为“标记名称状态”。这个状态会一直保持到接收> 字符。在此期间接收的每个字符都会附加到新的标记名称上。在本例中,我们创建的标记是 html 标记。们会再次保持这个状态,直到接收 >。然后将发送新的标记,并回到“数据状态”。