爬虫入门:python+pycharm,豆瓣电影信息,短评,分页爬取,mysql数据库连接
本文爬虫实现的功能:
随便在豆瓣网站中选择一部电影,获取影片详细信息,并自动获取该影片的短评链接,再跳转到短评页面,获取各位观众的影评,最后将爬取的数据存储到数据库中。
开发环境:
python3 + pycharm +WIN +mysql
步骤展示:
1.选取某一 影片,爬取该影片部分信息
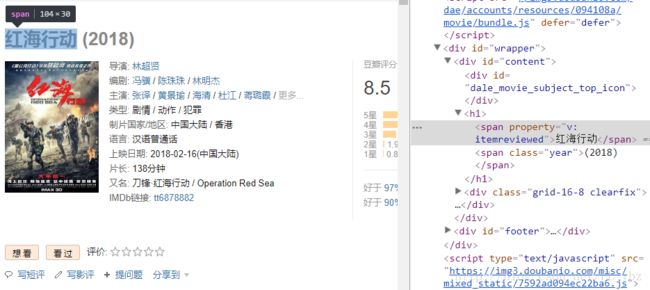
2.下拉到该影片的短评区,爬取全部评论的链接
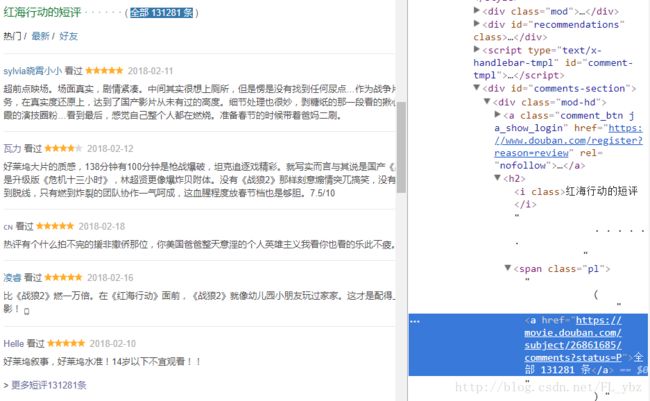
3. 通过部分手段跳转到全部链接的页面,并获取全部的短评

代码展示:
利用requests,beautifulSoup,re模块实现爬取功能,爬取的数据先复制到本地(通
过os模块实现),最后通过pymysql实现数据的导入
1.步骤一所需的代码(爬取影片部分信息)
(需要了解beautifulSoup,不懂的请点这)
def get_movie_comment(movie_url):
(soup,res) = get_soup(movie_url)
f = open("F:\\SpiderDB\\movie.txt", "a",encoding='utf-8')
for items in soup.select('#content'):
#print(items)
movie_name = items.select('span')[0].text
print(movie_name)
f.write(movie_name + ",")
for info in soup.select('#info'):
#print(info)
director = info.select('.attrs')[0].text
print(director)
editor = info.select('.attrs')[1].text
actors = info.select('.attrs')[2].text.strip()
actor = actors.split("/")[0:2]
actor = ''.join(actor)
#print(actor)
style = ' '.join([style.text for style in info.select('span[property="v:genre"]')]) # python 简洁一行
#print(style)
time = info.select('span[property="v:initialReleaseDate"]')[0].text
time = re.split('\(',time)[0]
#print(time)
2.步骤二所需的代码(获取短评链接)
按下F12观察全部短评的源码位置,如下图


comment_url = items.select('.mod-hd span.pl a')[0]['href'] 3.步骤三所需的代码
获取到全部短评首页链接后,观察该链接的不同(同其他页面的评论比较)
短评首页的链接:
https://movie.douban.com/subject/26861685/comments?start=0其他页面短评首页的链接:
https://movie.douban.com/subject/26861685/comments?start=20可见不同之处就是红色字体的地方,将红色字体处的数字替换就可实现分页,观察到页之间相差20
代码如下:
for i in range(20,200,20): # 从start=20开始,间隔为20
new_url = comment_url.replace("status=P","start={}").format(i)
#print(new_url)
get_comment(new_url)通过get_comment函数获取各个页面的短评信息
代码如下:(需用到正则表达式,亲自行搜索)
def get_comment(comment_url):
(soup2, res2) = get_soup(comment_url)
f = open("F:\\SpiderDB\\comment.txt", "a",encoding='utf-8')
for sc in soup2.select('.mod-bd'):
#print(sc)
for i in range(0,18):
commor = sc.select('.comment-info a')[i].text
stars = re.findall(r'', res2.text)[i]
comment = sc.select('p')[i].text.strip()
f.write(commor + ",")
f.write(stars + ",")
f.write(comment)
f.write("\n")
f.close()最后将爬取的数据导入本地文档和数据库中,这里就不详讲,需要全部源码的请
点这,
最后成果展示:
短评爬取数据:

电影爬取数据:

代码比较简单,以后会继续完善的,想要源码的请点击蓝色字体哦!!!