【机器学习】使用Hadoop Streaming来用Python代码完成MapReduce
一,Hadoop Streaming原理
Hadoop streaming是Hadoop的一个工具, 它帮助用户创建和运行一类特殊的map/reduce作业, 这些特殊的map/reduce作业是由一些可执行文件或脚本文件充当mapper或者reducer。比如可以使用python语言来写map-reduce使用“Hadoop Streaming”来完成传统mapreduce的功能。
如下所示:
$HADOOP_HOME/bin/hadoop jar $HADOOP_HOME/hadoop-streaming.jar \
-input myInputDirs \
-output myOutputDir \
-mapper /bin/map.py \
-reducer /bin/reduce.py上述代码通过参数input,output,mapper,reducer来定义输入数据,输出数据,map文件,reduce文件。
在上面的代码中,mapper和reducer都是可执行文件,它们从标准输入读入数据(一行一行读), 并把计算结果发给标准输出。Streaming工具会创建一个Map/Reduce作业, 并把它发送给合适的集群,同时监视这个作业的整个执行过程。
如果一个可执行文件被用于mapper,则在mapper初始化时, 每一个mapper任务会把这个可执行文件作为一个单独的进程启动。 mapper任务运行时,它把输入切分成行并把每一行提供给可执行文件进程的标准输入。 同时,mapper收集可执行文件进程标准输出的内容,并把收到的每一行内容转化成key/value对,作为mapper的输出。 默认情况下,一行中第一个tab之前的部分作为key,之后的(不包括tab)作为value。 如果没有tab,整行作为key值,value值为null。
如果一个可执行文件被用于reducer,每个reducer任务会把这个可执行文件作为一个单独的进程启动。 Reducer任务运行时,它把输入切分成行并把每一行提供给可执行文件进程的标准输入。 同时,reducer收集可执行文件进程标准输出的内容,并把每一行内容转化成key/value对,作为reducer的输出。 默认情况下,一行中第一个tab之前的部分作为key,之后的(不包括tab)作为value。
二,Map和Reduce
MapReduce的好处是它可以把在内存中不能完成的事转变成可以在硬盘上高效完成。
Map-‐Reduce 对于集群的好处:
1,在多节点上冗余地存储数据,以保证数据的持续性和一直可取性
2, 将计算移向数据端,以最大程度减少数据移动
3,简单的程序模型隐藏所有的复杂度
Map,Reduce一般的流程:
Map阶段:
a, 逐个文件逐行扫描
b, 扫描的同时抽取出我们感兴趣的内容 (Keys)
Group by key
排序和洗牌
(Group by key阶段会自动的运行,不需要自己写)
Reduce阶段:
a, 聚合 、 总结 、 过滤或转换
b, 写入结果
二,词频统计的例子
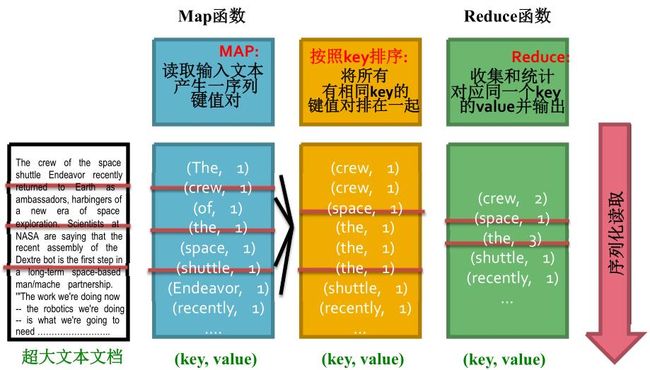
问题:有一个txt的英文文件,现在要统计文件中每个单词出现的频次。假定文件很大,不仅内存中一次是读不下文件,连文件的词和频次对(key,value)也读不下。
这类问题是很经典的MapReduce要处理的问题,将文件逐行读取,然后统计每行中单词的频率,并写到硬盘上去(map阶段做的事);然后读取硬盘上的文件,逐行的统计出现的单词(reduce阶段做的事)。如下图所示:
按照如下步骤:
1,首先要确保我们的输入和输出文件是不存在的:
hadoop fs -rmr /Mydata/input/example_1
hadoop fs -rmr /Mydata/output/example_12,创建输入文件夹并将输入文件放进去
hadoop fs -mkdir /Mydata/input/example_1
hadoop fs -put text* /Mydata/input/example_13,在本地测试一下map和reduce
为了避免错误带来的时间开销,取出少量的数据,使用Linux本地命令来模拟一下这个过程。代码如下所示:
head -20 text1.txt | python count_mapper.py | sort | python count_reducer.py
先获取文件的前20行数据,以管道的方式传递到mapper中,然后排序,最后将排序之后的数据送到reduce中。通过reduce的输出结果来判断正确与否。
4,在集群上跑数据
hadoop jar /usr/lib/hadoop-current/share/hadoop/tools/lib/hadoop-streaming-2.7.2.jar \
-file count_mapper.py \
-mapper count_mapper.py \
-file count_reducer.py \
-reducer count_reducer.py \
-input /Mydata/input/example_1 \
-output /Mydata/output/example_1
其中”-file”是将文件传递到集群上去,”-mapper”指定mapper文件,”-reducer”指定reduce文件,”-input”指定处理数据的的输入路径,”-output”指定最后文件的输出路径。
mapper和reducer文件都是python文件。mapper完成的任务是将txt文件分割成map(word,count)对,代码如下:
for line in sys.stdin:
# remove leading and trailing whitespace
line = line.strip()
# split the line into words
words = line.split()
# increase counters
for word in words:
# write the results to STDOUT (standard output);
# what we output here will be the input for the
# Reduce step, i.e. the input for reducer.py
#
# tab-delimited; the trivial word count is 1
print '%s\t%s' % (word.lower(), 1)注意:数据是从“sys.stdin”中读取的。
maper代码的作用就是对将文件中出现的单词写成一个map对。
中间的隐藏过程,其实map和reduce中间是有类似group by key的过程的,它将maper的输出中key相同的放在一起,以便于下一步reducer处理。它是自动进行的,不需要我们处理。
reducer的作用是统计相同的key出现的频率,代码如下所示:
current_word = None
current_count = 0
word = None
# input comes from STDIN
for line in sys.stdin:
# remove leading and trailing whitespace
line = line.strip()
# parse the input we got from mapper.py
word, count = line.split('\t', 1)
# convert count (currently a string) to int
try:
count = int(count)
except ValueError:
# count was not a number, so silently
# ignore/discard this line
continue
# this IF-switch only works because Hadoop sorts map output
# by key (here: word) before it is passed to the reducer
if current_word == word:
current_count += count
else:
if current_word:
# write result to STDOUT
print '%s\t%s' % (current_word, current_count)
current_count = count
current_word = word
# do not forget to output the last word if needed!
if current_word == word:
print '%s\t%s' % (current_word, current_count)