使用Node.js爬取双色球十六年来所有中奖号码
准备工作
网上Node.js爬虫教程一大堆,本例使用了最常见的request + cheerio依赖库。使用npm安装即可:
npm install request
npm install cheerio
为方便爬虫,找一个好一点的网站来采集数据是很有必要的,本例使用的是中彩网,打开控制台我们可以看到实际数据在iframe中,打开实际网址http://kaijiang.zhcw.com/zhcw/html/ssq/list.html,发现每一页的数据只改变URL 中list后的数字,所以我们在爬取的过程中只需要每次改变这个数字就行了。

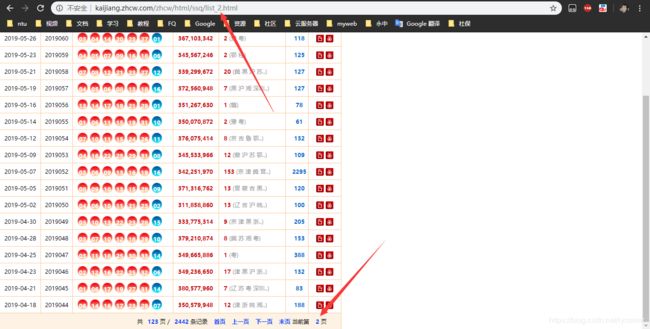
爬取网页源码
首先我们利用request依赖库写一个爬取网页源码的函数,设置一个headers来模拟浏览器,由于爬取是一个异步的过程,所以我们使用一个callback回调函数来做后续的处理。
const request = require('request')
function getHTML(url, callback) {
const options = {
url: url,
// 设置一个浏览器头
headers: {
"Accept": "application/json, text/javascript, */*; q=0.01",
"X-Requested-With": "XMLHttpRequest",
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/59.0.3071.115 Safari/537.36",
"Content-Type": "application/x-www-form-urlencoded; charset=UTF-8"
}
}
request(options, function (err, res) {
if (!err) {
callback && callback(res.body)
} else {
console.log(err);
flag = false
callback && callback('')
}
})
}分析网页源码
打开控制台,可以看到从第三个tr开始包含了我们实际想要的数据:在每个tr中,第一个td里是日期,第二个td里是期号,第三个td里是包含每个号码的em,用该网站来爬取双色球的号码还是挺清晰明了的

在代码通过使用cheerio可以对网页源码像JQuery一样进行快速的分析,像这样即可快速的筛选出所有的tr,可以参考cheerio文档
const cheerio = require('cheerio')
const $ = cheerio.load(html)
const tr = $('tr')将数据写入文件
使用Node.js内置的fs模块即可
function writeFile(filename, data) {
fs.writeFile(filename, data, {flag: "a+"}, err => err && console.log(err))
}整合
将上述几个要点整合在一起
main.js
const cheerio = require('cheerio'),
request = require('request'),
fs = require('fs'),
path = require('path')
let flag = true // 爬虫终止条件
const filename = path.resolve(__dirname, '..', 'data.txt') // 输出文件位置
function getHTML(url, callback) {
const options = {
url: url,
// 设置一个浏览器头
headers: {
"Accept": "application/json, text/javascript, */*; q=0.01",
"X-Requested-With": "XMLHttpRequest",
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/59.0.3071.115 Safari/537.36",
"Content-Type": "application/x-www-form-urlencoded; charset=UTF-8"
}
}
request(options, function (err, res) {
if (!err) {
callback && callback(res.body)
} else {
console.log(err);
flag = false
callback && callback('')
}
})
}
function writeFile(filename, data) {
fs.writeFile(filename, data, {flag: "a+"}, err => err && console.log(err))
}
function handle(html) {
try {
const $ = cheerio.load(html)
const tr = $('tr')
if (tr.find('td').length === 0) { // 爬取结束
flag = false
return
}
tr.each(function (i) {
if (i > 1) { // 从第二行开始才是有效数据
const td = $(this).find('td')
const date = td.eq(0).text() // 日期
const id = td.eq(1).text() // 期号
if (!id) return // 末行,退出循环
let str = date + ' ' + id + ' ' // 用于写入文件的每期字符串
const td2 = td.eq(2) // 本期所有号码的td
const em = td2.find('em')
em.each(function (j) {
str = str + em.eq(j).text() + ' '
})
str += '\n' // 加个换行
writeFile(filename, str)
}
})
} catch (e) {
console.log(e)
flag = false
}
}
let page = 1
let t = setInterval(function () {
if (flag) {
console.log('开始爬取第' + page + '页');
getHTML(`http://kaijiang.zhcw.com/zhcw/html/ssq/list_${page}.html`, handle)
page++
} else {
console.log('爬取结束');
clearInterval(t)
}
}, 500) // 间隔0.5s爬取一次
程序会将爬取到的数据写入上级目录下的data.txt中,目前一共只有123页,只花费一分钟左右就可以全部爬完了。所有代码算上空行80行不到,还是比较简洁的。
进一步处理
由于每次爬取都是异步的,所以每期号码在文件中顺序可能会出现偏差,我们利用Excel对数据进一步处理,全选data.txt里的数据,然后直接复制到Excel中,现在所有数据都在一列中,我们将它分列,选中整个A列,点击数据-分列,选择空格符号-勾选空格就行了。

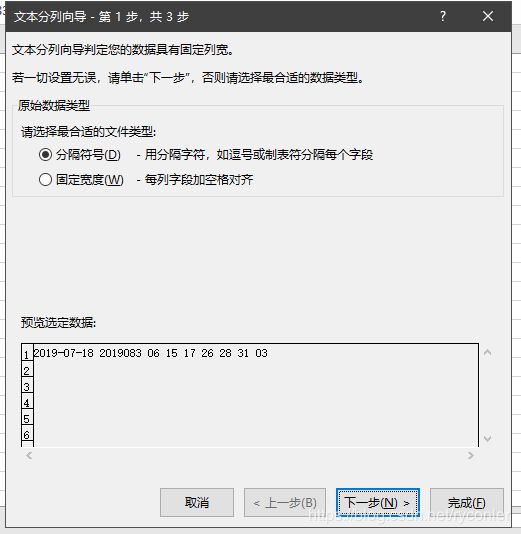


然后点击排序,对列B(期号)进行一个降序排序就行了,剩下的要对彩票数据进行怎样分析,就看你自己个人造化了。
最后附上
源代码:https://github.com/Ryconler/ssq_spider.git