基于MTCNN+FaceNet实现人脸识别
文章目录
- 1、技术背景
- 2、设计方案
- 3、步骤
- 4、测试结果
- 5、测试分析
- 6、参考文献
1、技术背景
环境:Win10、Python3.6、anaconda3、pycharm
技术:FaceNet、MTCNN
2、设计方案
①设计与实现思路
第一步是获得可用于身份认证的人脸图像,并处理图片,解决不同光照条件导致的差异和其他差异;第二步是人脸检测,就是给一幅图像,找出图像中所有人脸的位置,通常用一个矩形框框起来;第三步是人脸对齐,将不同姿态的人脸图像转换成规范的图形,根据关键点进行平移、压缩、旋转等变换;第四步是特征提取,把人脸识别用特征向量表达用于识别;最后一步是识别与验证,将知道的人脸的特征与库里的人脸进行对比,找到最像的人脸,然后与设置的阈值进行对比,如果大于设置的阈值就是这个人脸,如果小于,这个人就不在库里。流程图:

②MTCNN原理简述
MTCNN是多任务级联CNN的人脸检测深度学习模型,该模型中综合考虑了人脸边框回归和面部关键点检测,MTCNN算法是一种基于深度学习的人脸检测和人脸对齐方法,它可以同时完成人脸检测和人脸对齐的任务,相比于传统的算法,它的性能更好,检测速度更快;MTCNN算法包含三个子网络: P-Net、R-Net、0-Net, 这三个网络对人脸的处理依次从粗到细;在使用这三个子网络之前,需要使用图像金字塔将原始图像缩放到不同的尺度,然后将不同尺度的图像送入这三个子网络中进行训练,目的是为了可以检测到不同大小的人脸,从而实现多尺度目标检测。MTCNN的网络整体架构如下图所示:
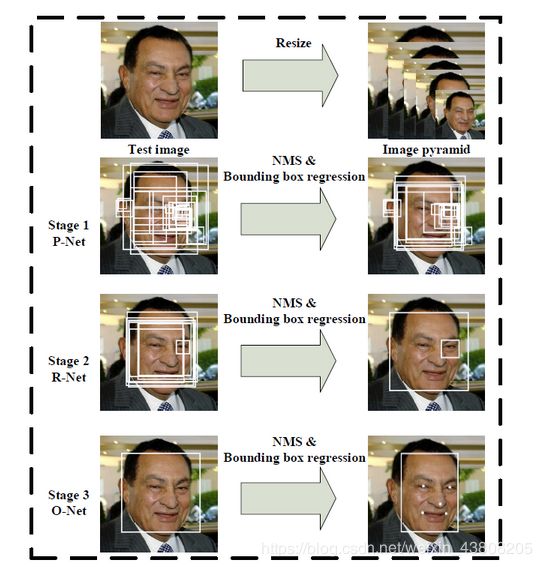
③MTCNN人脸检测的步骤
a.使用P-Net生成候选窗和边框回归向量,P-Net的输入是个12x12x3的RGB图像,在训练的时候,该网络要判断这个图像中是否存在人脸,并且给出人脸框的回归和人脸关键点定位;
b.由于P_Net的检测时比较粗略,所以使用R-Net进一步优化,R-Net和P-Net类似,不过这一步的输入是前面P-Net生成的边界框,每个边界框的大小都是24x24x3,可以通过缩放得到,网络的输出和P-Net是样的,这一步的目的主要是为了去除大量的非人脸框;
c.最后使用O-Net输出最终的人脸框和特征点位置,和第二步类似,只不过在测试输出的时候多了关键点位置的输出。
④FaceNet原理简介
FaceNet主要用于验证,人脸是否为同一个人,通过人脸识别这个人是谁。FaceNet的主要思想是把人脸图像映射到一个多维空间,通过空间距离表示人脸的相似度。同个人脸图像的空间距离比较小,不同人脸图像的空间距离比较大。这样通过人脸图像的空间映射就可以实现人脸识别,FaceNet中采用基于深度神经网络的图像映射方法和基于triplets (三联子)的loss函数训练神经网络,网络直接输出为128维度的向量空间。FaceNet的网络结构如下图所示,其中Batch表示人脸的训练数据,接下来是深度卷积神经网络,然后采用L2归一化操作,得到人脸图像的特征表示,最后为三元组(Triplet Loss)的损失函数。

⑤FaceNet工作流程
a.在mini-batch开始的时候,从训练数据集中抽样人脸照片。比如每一个batch抽样多少人,每个人抽样多少张图片,这样会得到要抽样的人脸照片;
b.计算这些抽样图片在网络模型中得到的embedding,这样通过计算图片的embedding之间的欧式距离得到三元组了;
c.根据得到的三元组,计算triplet-loss,进行模型优化,更新embedding。
⑥MTCNN+FaceNet模型实现
a.通过MTCNN人脸检测模型,从照片中提取人脸图像;
b.把人脸图像输入到FaceNet,计算Embedding的特征向量;
c.比较特征向量间的欧式距离,判断是否为同一人,例如当特征距离小于1的时候认为是同一个人,特征距离大于1的时候认为是不同人。
d. 实现流程图

3、步骤
①项目结构

其中face_data存放的是图片数据;model_data存放的是模型参数,有facenet和mtcnn的模型参数,需要自己在网上下载;net存放的是facenet架构和mtcnn架构,也需要自己下载。
②加入人脸数据文件
将需要进行检测的人脸图片放进指定个文件夹中,每个人脸只需要放一张,并标记好每张图片的名字。
③开始人脸检测和人脸识别,运行face_recognize脚本文件,这个脚本文件将调用matcnn脚本文件和inception脚本文件,mtenn脚本文件经过三个网络,将人脸的位置和关键点标记出来, inception脚本文件为facenet架构。
face_recognize.py
import cv2
import os
import numpy as np
from net.mtcnn import mtcnn
import utils.utils as utils
from net.inception import InceptionResNetV1
PROJECT_ROOT = os.path.dirname(os.path.realpath(__file__))
class face_rec():
def __init__(self):
# 创建mtcnn对象
# 检测图片中的人脸
self.mtcnn_model = mtcnn()
# 门限函数
self.threshold = [0.5, 0.8, 0.9]
# 载入facenet
# 将检测到的人脸转化为128维的向量
self.facenet_model = InceptionResNetV1()
# model.summary()
model_path = './model_data/facenet_keras.h5'
self.facenet_model.load_weights(model_path)
# -----------------------------------------------#
# 对数据库中的人脸进行编码
# known_face_encodings中存储的是编码后的人脸
# known_face_names为人脸的名字
# -----------------------------------------------#
face_list = os.listdir("face_dataset")
self.known_face_encodings = []
self.known_face_names = []
for face in face_list:
name = face.split(".")[0]
data_path = os.path.join("./face_dataset/" , face)
img = cv2.imread(data_path)
img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
# 检测人脸
rectangles = self.mtcnn_model.detectFace(img, self.threshold)
# 转化成正方形
rectangles = utils.rect2square(np.array(rectangles))
# facenet要传入一个160x160的图片
rectangle = rectangles[0]
# 记下他们的landmark
landmark = (np.reshape(rectangle[5:15], (5, 2)) - np.array([int(rectangle[0]), int(rectangle[1])])) / (
rectangle[3] - rectangle[1]) * 160
crop_img = img[int(rectangle[1]):int(rectangle[3]), int(rectangle[0]):int(rectangle[2])]
crop_img = cv2.resize(crop_img, (160, 160))
new_img, _ = utils.Alignment_1(crop_img, landmark)
new_img = np.expand_dims(new_img, 0)
# 将检测到的人脸传入到facenet的模型中,实现128维特征向量的提取
face_encoding = utils.calc_128_vec(self.facenet_model, new_img)
self.known_face_encodings.append(face_encoding)
self.known_face_names.append(name)
def recognize(self, draw):
# -----------------------------------------------#
# 人脸识别
# 先定位,再进行数据库匹配
# -----------------------------------------------#
height, width, _ = np.shape(draw)
draw_rgb = cv2.cvtColor(draw, cv2.COLOR_BGR2RGB)
# 检测人脸
rectangles = self.mtcnn_model.detectFace(draw_rgb, self.threshold)
if len(rectangles) == 0:
return
# 转化成正方形
rectangles = utils.rect2square(np.array(rectangles, dtype=np.int32))
rectangles[:, 0] = np.clip(rectangles[:, 0], 0, width)
rectangles[:, 1] = np.clip(rectangles[:, 1], 0, height)
rectangles[:, 2] = np.clip(rectangles[:, 2], 0, width)
rectangles[:, 3] = np.clip(rectangles[:, 3], 0, height)
# -----------------------------------------------#
# 对检测到的人脸进行编码
# -----------------------------------------------#
face_encodings = []
for rectangle in rectangles:
landmark = (np.reshape(rectangle[5:15], (5, 2)) - np.array([int(rectangle[0]), int(rectangle[1])])) / (
rectangle[3] - rectangle[1]) * 160
crop_img = draw_rgb[int(rectangle[1]):int(rectangle[3]), int(rectangle[0]):int(rectangle[2])]
crop_img = cv2.resize(crop_img, (160, 160))
new_img, _ = utils.Alignment_1(crop_img, landmark)
new_img = np.expand_dims(new_img, 0)
face_encoding = utils.calc_128_vec(self.facenet_model, new_img)
face_encodings.append(face_encoding)
face_names = []
for face_encoding in face_encodings:
# 取出一张脸并与数据库中所有的人脸进行对比,计算得分
matches = utils.compare_faces(self.known_face_encodings, face_encoding, tolerance=0.9)
name = "Unknown"
# 找出距离最近的人脸
face_distances = utils.face_distance(self.known_face_encodings, face_encoding)
# 取出这个最近人脸的评分
best_match_index = np.argmin(face_distances)
if matches[best_match_index]:
name = self.known_face_names[best_match_index]
face_names.append(name)
if name != "Unknown":
print('------------------------------')
print('识别成功!欢迎'+name+'!')
print('------------------------------')
else:
print('------------------------------')
print('抱歉无法验证您的身份!')
print('------------------------------')
rectangles = rectangles[:, 0:4]
# -----------------------------------------------#
# 画框~!~
# -----------------------------------------------#
for (left, top, right, bottom), name in zip(rectangles, face_names):
cv2.rectangle(draw, (left, top), (right, bottom), (0, 0, 255), 2)
font = cv2.FONT_HERSHEY_SIMPLEX
cv2.putText(draw, name, (left, bottom - 15), font, 0.75, (255, 255, 255), 2)
return draw
if __name__ == "__main__":
dududu = face_rec()
# 加载视频文件
# video_capture = cv2.VideoCapture("./222.mp4")
# 打开摄像头
video_capture = cv2.VideoCapture(0)
while True:
ret, draw = video_capture.read()
dududu.recognize(draw)
cv2.imshow('Video', draw)
if cv2.waitKey(20) & 0xFF == ord('q'):
break
video_capture.release()
cv2.destroyAllWindows()
4、测试结果

如果识别成功,将输出识别成功!在人脸的下方会显示名字。
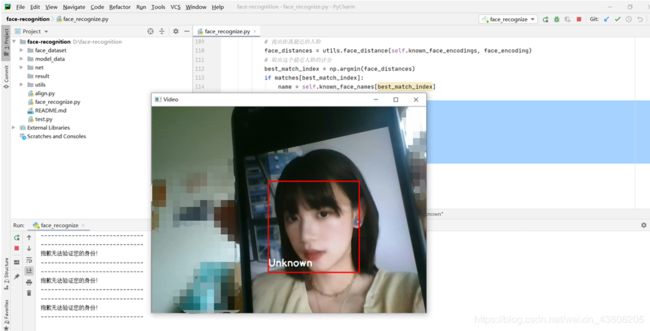
如果识别失败,会提示抱歉无法识别,并且将在人脸下方显示Unknown。

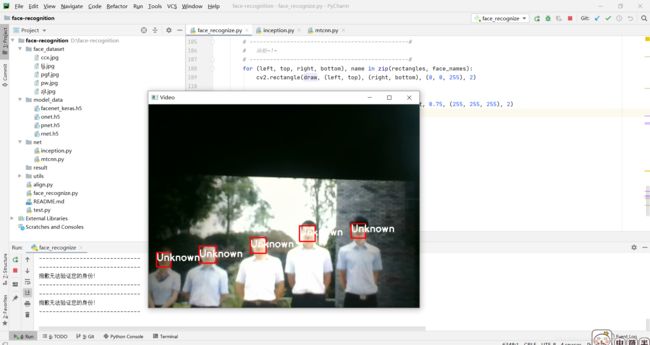

可以看到多人或者带上口罩也可以识别,说明这个效果还是很不错的。
5、测试分析
基于MTCNN和FaceNet实现人脸识别的这种方法识别精度特别高,出现识别错误的几率很小很小,并且带上口罩也可以识别成功。这个模型思路也比较简单,主要思路就是先利用MTCNN进行人脸识别检测,然后用FaceNet进行人脸识别,FaceNet可以看成提取人脸特征的CNN网络,这个特征就是embadding,有了人脸特征embadding,最后就只需要与库里面的人脸特征进行相似性比较,就完成人脸识别了。
6、参考文献
①https://blog.csdn.net/guyuealian/article/details/84896733#%EF%BC%881%EF%BC%89%E5%88%B6%E4%BD%9C%E4%BA%BA%E8%84%B8%E6%95%B0%E6%8D%AE%E5%9B%BE%E5%BA%93%EF%BC%9A
②http://www.uml.org.cn/ai/201806124.asp