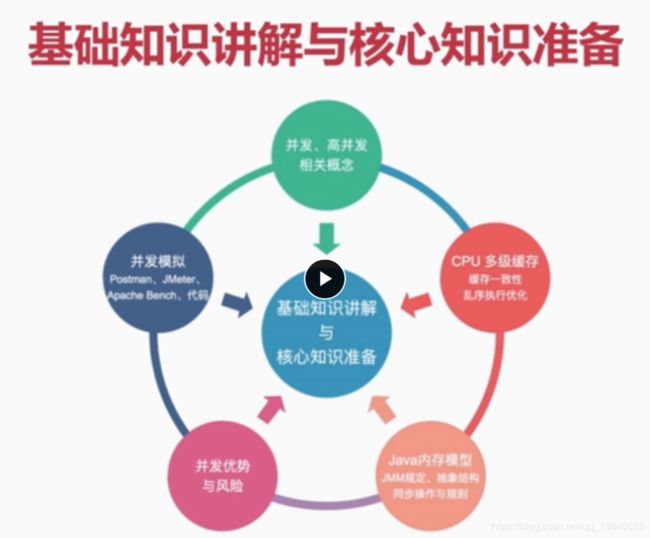
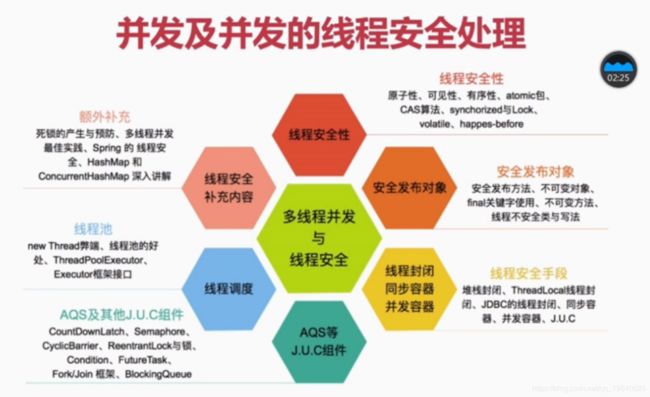
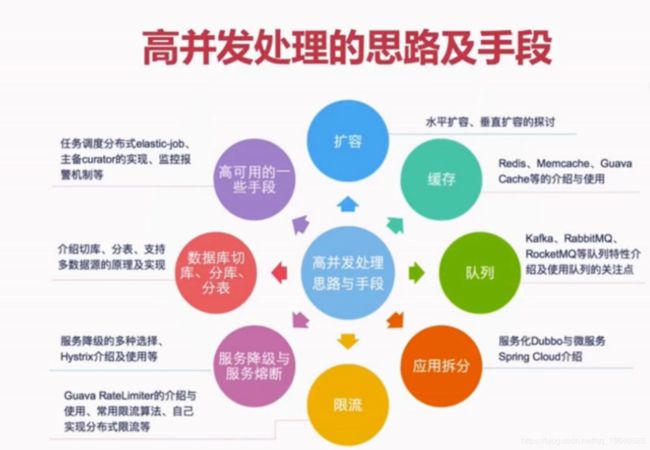
Java并发编程与高并发笔记
ExecutorService 线程池
CountDownLatch 线程阻塞
Semaphore 信号量
线程安全性
何种调度方式,不需要任何额外的同步或协同,都能表现出正确的行为
原子性、
AtomicInteger:一个死循环内不断的修改目标值,直到修改成功;竞争不激烈修改成功率很高,否则修改失败率很高
jvm把Long、Double读操作和写操作拆成两个32位的操作
AtomicLong: 依靠底层的cas来保障原子性的更新数据,在要添加或者减少的时候,会使用死循环不断地cas到特定的值,从而达到更新数据的目的
LongAdder:在AtomicLong的基础上将单点的更新压力分散到各个节点,在低并发的时候通过对base的直接更新可以很好的保障和AtomicLong的性能基本保持一致,而在高并发的时候通过分散提高了性能。
缺点是LongAdder在统计的时候如果有并发更新,可能导致统计的数据有误差。
可见性、
导致共享变量在线程间不可见的原因
线程交叉执行
重排序结合线程交叉执行
共享变量更新后的值没有在工作内存与主存间及时更新
有序性
原则
线程终结规则
对象终结规则
原子性-锁
synchronized:依赖JVM
修饰代码块:大括号括起来的代码,作用于调用的对象
修饰方法:整个方法,作用于调用的对象
修饰静态方法:整个静态方法,作用于所有的对象
修饰类:括号括起来的部分,作用于所有对象
Lock:依赖特殊的CPU指令,代码实现,ReentrantLock
原子性-比对
synchronized:不可中断锁,适合竞争不激烈,可读性好
Lock:可中断锁,多样化同步,竞争激烈时能维持常态
Atomic:竞争激烈时能维持常态,比Lock性能好;只能同步一个值
不可变
final、Collections.unmodifiableMap、ImmutableList、ImmutableSet、ImmutableMap
线程封闭
Ad-hoc线程封闭:程序控制实现,最糟糕,忽略
堆栈封闭:局部变量,无并发问题
ThreadLocal线程封闭:特别好的封闭方法
线程不安全类
StringBuilder-->StringBuffer(线程安全)
SimpleDateFormat-->DateTimeFormatter(线程安全)
ArrayList、HashSet、HashMap、Hashtable(线程安全)
线程安全-同步容器
ArrayList-->Vector、Stack
HashMap-->Hashtable(key/value不能为null)
Collections.synchronizedXXX(List、Set、Map)
线程安全--并发容器J.U.C
ArrayList->CopyOnWriteArrayList
HashSet、TreeSet->CopyOnWriteArraySet、ConcurrentSkipListSet
HashMap、TreeMap->ConcurrentHashMap、ConcurrentSkipListMap
线程限制:一个被线程限制的对象,由线程独占,并且只能被占有它的线程修改
共享只读:一个共享只读的对象,在没有额外同步的情况下,可以被多个线程并发访问,但是如何线程都不能修改它
线程安全对象:一个线程安全的对象或者容器,在内部通过同步机制来保证线程安全,所以其他线程无需额外的同步就可以通过公共接口随意访问它
被守护对象:被守护对象只能通过获取特定的锁来访问
AQS同步组件
CountDownLatch:闭锁,通过一个计数来保证线程是否需要堵塞
Semaphore:控制同一时间并发线程的数目[备注:if (semaphore.tryAcquire(5000, TimeUnit.MILLISECONDS)) {//等待5秒内,尝试获取一个许可]
CyclicBarrier:跟Semaphore相似
ReentrantLock:
synchronized是基于JVM层面实现的,而Lock是基于JDK层面实现的
对于使用者的直观体验上Lock是比较复杂的,需要lock和realse,如果忘记释放锁就会产生死锁的问题,所以,通常需要在finally中进行锁的释放。但是synchronized的使用十分简单,只需要对自己的方法或者关注的同步对象或类使用synchronized关键字即可。但是对于锁的粒度控制比较粗,同时对于实现一些锁的状态的转移比较困难
ReentrantLock支持两种锁模式,公平锁和非公平锁。默认的实现是非公平的
写操作必须在没有读锁存在的时候,才能进行写同步操作
线程数量少量synchronized,线程数量不断增加,不可估量ReentrantLock
Condition:Condition的使用方式是比较简单的,需要注意的是使用Condition的等待/通知需要提前获取到与Condition对象关联的锁,Condition对象由Lock对象创建
使用场景:线程A执行到某个点的时候,因为某个条件condition不满足,需要线程A暂停;等到线程B修改了条件condition,使condition满足了线程A的要求时,A再继续执行。
FutureTask:在使用java实现异步时最常用到的一个类,我们可以向线程池提交一个Callable,并通过future对象获取执行结果
Fork/Join框架:用于并行执行任务的框架,是一个把大任务分割成若干个小任务,最终汇总每个小任务结果后得到大任务结果的框架
BlockingQueue:
ArrayBlockingQueue:初始化的时候指定大小,指定了就不能再变,先进先出,最先插入的数据在尾部,移除的数据在头部
DelayQueue:使用场景定时关闭连接,超时处理
LinkedBlockingQueue:配置可选,初始化时指定了大小是有边界的,不指定大小就是无边界的
PriorityBlockingQueue:有更新级的阻塞队列,没有边界的队列
SynchronousQueue:内部只能容纳一个元素,当插入一个元素后,队列就会被阻塞,无界非缓存的队列
线程池
new Thread弊端
每次new Thread新建对象,性能差
线程缺乏统一管理,可能无限制的新建线程,相互竞争,有可能占用过多系统资源导致死机或OOM
缺少更多功能,如更多执行、定期执行、线程中断
线程池的好处
重用存在的线程,减少对象创建、消亡的开销,性能佳
可有效控制最大并发线程数,提高系统资源利用率,同时可以避免过多资源竞争,避免阻塞
提供定时执行、定期执行、单线程、并发数控制等功能
线程池-ThreadPooIExecutor
corePooISize:核心线程数量
maximumPooISize:线程最大线程数
workQueue:阻塞队列,存储等待执行的任务,很重要,会对线程池运行过程产生重大影响
keepAliveTime:线程没有任务执行时最多保持多久时间终止
unit:keepAliveTime的时间单位
threadFactory:线程工厂,用来创建线程
rejectHandler:当拒绝处理任务时的策略
execute():提交任务,交给线程池执行
submit():提交任务,能够放回执行结果execute+Future
shutdown():关闭线程池,等待任务都执行完
shutdownNow():关闭线程池,不等待任务执行完
getTaskCount():线程池已执行和未执行的任务总数
getCompletedTaskCount():已完成的任务数量
getPooISize():线程池当前的线程数量
getActiveCount():当前线程池中正在执行的线程数量
线程池-Executor框架接口
Executors.newCachedThreadPool:可缓存的线程池,如果线程池数量超过数据需要,没有可回收线程,则新建线程
Executors.newFixedThredPool:创建定长的线程池,可控制线程的最大并发数,超过的线程会在等待
Executors.newScheduledThreadPool:创建定长的线程池,支持定时,周期性任务执行
Executors.newSingleThreadExecutor:创建单线程化的线程池,只会用唯一的线程来执行任务,先进先出,优先级处理
线程池-合理配置
CPU密集型任务,就需要尽量压榨CPU,参考值可以设为NCPU+1
IO密集型任务,参考值可以设置为2*NCPU
死锁-必要条件
互斥条件:锁对进程所分配的排它性使用,在一段时间内,某资源只能由一个资源在使用,其他资源在请求资源,只能等待
请求和保持条件:进程至少保持着一个资源,但又提出了新的资源请求,而该资源已在被其他资源占用,此时请求进程阻塞,但又以自己和其他进程保持着不放
不剥夺条件:进程已获得资源在未使用完前不能被剥夺,在使用完时自己释放
环路等待条件:
多线程并发最佳实践
使用本地变量
使用不可变类
最小化锁的作用域范围:S=1/(1-a+a/n)
使用线程池的Executor,而不是直接new Thread执行
宁可使用同步也不要使用线程的wait和notify
使用BlockingQueue实现生产-消费模式
使用并发集合而不是加了锁的同步集合
使用Semaphore创建有界的访问
宁可使用同步代码块,也不使用同步的方法
避免使用静态变量
HashMap:采用了链地址法,也就是数组+链表的方式
高并发解决方案
扩容
垂直扩容(纵向扩展):提高系统部件能力
水平扩容(横向扩展):增加更多系统成员来实现
扩容-数据库
读操作扩展:memcache、redis、CDN等缓存
写操作扩展:Cassandra、Hbase等
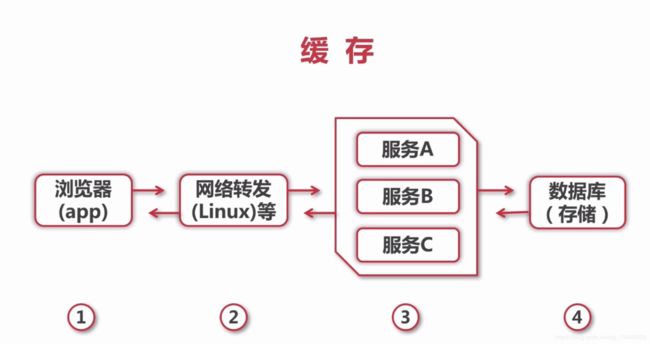
缓存特征
命中率:命中数/(命中数+没有命中数)
最大元素(空间)
清空策略:FIFO(先进先出),LFU(最小使用策略),LRU,过期时间,随机等
缓存命中率影响因素
业务场景和业务需求
缓存的设计(粒度和策略)
缓存容量和基础设施
缓存分类和应用场景
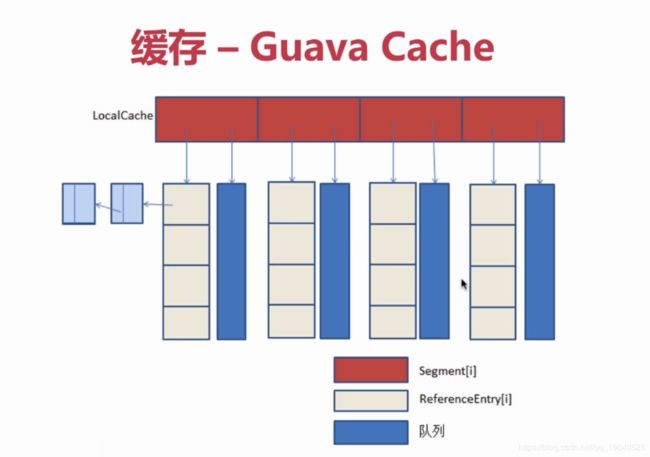
本地缓存:编程实现(成员变量、局部变量、静态变量)、Guava Cache
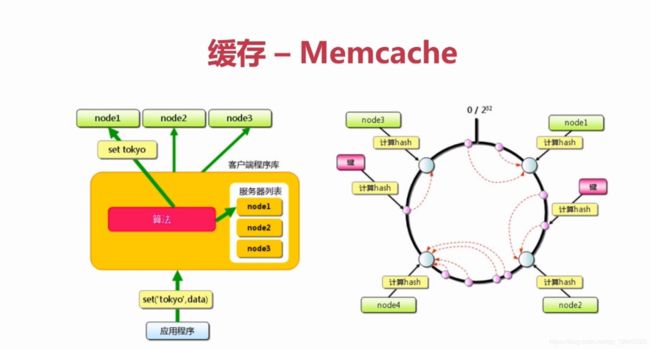
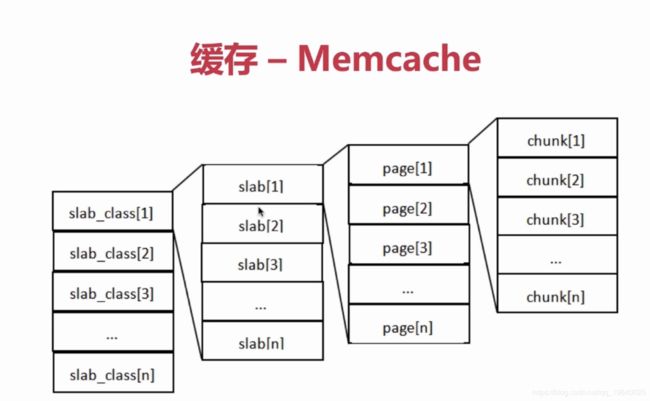
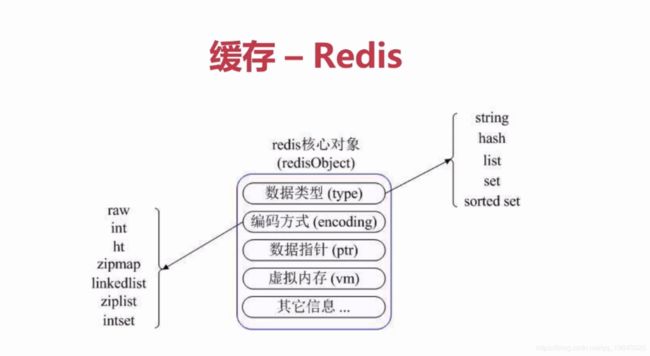
分布式缓存:Memcache、Redis
消息队列
Kafka:快速持久化,高吞吐
RabbitMQ
应用拆分-原则
业务优先
循序渐进
兼顾技术:重构、分层
可靠测试
应用限流
计数器法、滑动窗口、漏桶算法、令牌桶算法
服务降级与服务熔断
服务降级、服务熔断
共性:目的。最终表现、粒度、自治
区别:触发原因、管理目标层次、实现方式
服务降级分类
自动降级:超时、失败次数、故障、限流
人工降级:秒杀、双11大促等
服务降级要考虑的问题
核心服务、非核心服务
是否支持降级,降级策略
业务放通场景,策略
Hystrix
在通过第三方客户端访问(通常是通过网络)依赖服务出现高延迟或者失败时,为系统提供保护和控制
在分布式系统中防止级联失败
快速失败(Fail fast)同时能快速恢复
提供失败回退(Fallback)和优雅的服务降级机制
数据库切库、分库、分表
数据库瓶颈:
单个库数据量太大(1T~2T):分库
单个数据库服务器压力过大、读写瓶颈:多个库
单个表数据量过大:分表
数据库切库
切库的基础及实际运用:读写分类
自定义注解完成数据库切库-代码实现
数据库支持多个数据源与分库
支持多数据源、分库
数据库分表
什么时候考虑分表
横向(水平)分表与纵向(垂直)分表
数据库分表:mybatis分表插件shardbatis2.0
高可用的一些手段
任务调度系统分布式:elastic-job+zookeeper
主备切换:apache curator+zookeeper分布式锁实现
监控报警机制