Deep Learning Based Text Classification (文本分类综述)
Deep Learning Based TextClassification: A Comprehensive Review
论文来源:https://arxiv.org/abs/2004.03705
2020年4月份的一篇文本分类相关的综述文章。
1. 前言
文本分类是NLP中一个非常经典任务(对给定的句子、查询、段落或者文档打上相应的类别标签)。其应用包括机器问答、垃圾邮件识别、情感分析、新闻分类、用户意图识别等。文本数据的来源也十分的广泛,比如网页数据、邮件内容、聊天记录、社交媒体、用户评论等。文本是是极其丰富的信息载体,然而由于文本的非结构化特性,导致从中提取有用信息具十分有挑战性。
1.1 文本分类三大方法:
(1)Rule-based methods
使用预定义的规则进行分类,需要很强的领域知识而且系统很难维护。
(2)Machine learning(data-driven) based methods
经典的机器学方法使用特征提取方法(Bow词袋等)来提取文本特征,再使用如朴素贝叶斯,SVM,HMM,Gradient Boosting Tree和随机森林等方法来进行分类。
深度学习方法通常使用的是end2end形式,比如Attetion、transformers、Bert等。
(3)Hybrid methods
基于规则和基于机器学习(深度学习)方法的混合。
1.2 文本分类的任务
(1)情感分析
给定文本,分析用户的观点并且抽取出他们的主要观点。可以是二分类,也可以是多分类任务。
(2)新闻分类
识别新闻主题,并给用户推荐相关的新闻。主要应用于推荐系统。
(3)主题分类
给定文本,抽取出其文本的一个或者多个主题。
(4)机器回答
提取式(extractive),给定问题和一堆候选答案,从中识别出正确答案。
生成式(generative),给定问题,然后生成答案。(NL2SQL)
(5)自然语言推理NLI?
文本蕴含任务,预测一个文本是否可以从另一个文本中推断出。一般包括entailment、contradiction和neutral三种关系类型
2. 文本分类-深度学习模型
回顾了应用于不同分类任务的150种深度学习框架,主要分类如下:
(1)基于前馈神经网络(Feed-Forward Neural Networks)
(2)基于循环神经网络(RNN)
(3)基于卷积神经网络(CNN)
(4)基于胶囊网络Capsule networks
(5)基于Attetion机制
(6)基于记忆增强网络(Memory-augmented networks)
(7)基于Transformers机制
(8)基于图神经网络
(9)基于孪生神经网络(Siamese Neural Network)
(10)混合神经网络(Hybrid models)
2.1 基于前馈神经网络(Feed-Forward Neural Networks)
前馈神经网络是文本分类中最简单的一类深度学习模型。该类模型通常将文本识别一个词袋,然后使用embedding模型(word2vec、Glove等)将每个词表示为一个向量。而文本可以通过将文本中的所有词的向量进行加权或者平均得到,将文本向量输入到多层前馈网络(Multi-Layer Perceptrons,MLP)最后输入到分类器(LR、Naive Bayes、SVM等)中进行分类。其代表模型Deep Average Network(DAN),DAN的结构如下:

然而DAN没有考虑词序的信息特征,因此,fastText模型引入了n-gram词袋模型,在一定程度上可以缓解这个问题。
除了词级别的特征表示,doc2vec模型可以学习固定长度文本的特征表示(如局子、段落、文档等)。doc2vec和连续词袋模型(CBOW)一样,唯一的不同是doc2vec多了一个paragraph id矩阵用来表示文本的语义信息。这样做可以引入文本全局信息,可以让文本embedding 看到不同的句子信息,同时也能保留词序依赖信息。doc2vec的结构如下:

2.2 基于循环神经网络(RNN)
基于循环神经网络将文本视为单词的序列,通过捕捉单词之间的依赖关系以及文本结构信息来进行文本分类。在众多RNN模型中
LSTM模型是最受欢迎的。原始的RNN模型容易出现梯度消失和梯度爆炸(gradient vanishing or exploding)问题,而LSTM通过引入门控单元(输入门、遗忘门、输出门)来缓解这个问题。LSTM有很多不同的变种:Tree-LSTM、Bi-LSTM、MT-LSTM。
经典的LSTM一般是单向的,每个step只能看到上文信息,无法利用下文信息,BI-LSTM的提出能够很好的同时利用当前step上下文的信息。除了链式的LSTM,还有树形结构的Tree-LSTM,研究者认为Tree-LSTM的结构和句法结构相似,能够提取更高层级的语义信息(短语、句子等)。MT-LSTM(Multi-Timescale LSTM),通过将链式的LSTM分成多组,在不同的时间段更新不同的分组,在长文本分类上效果较好。
链式LSTM和树形LSTM的结构如下:

2.3 基于卷积神经网络(CNN)
RNN通常用于具有时间序列特征数据的任务中,而CNN通常用于具有空间特征数据的任务中。由于CNN能够有效捕捉局部信息的特征
CNN也被用于文本分类任务中。
DCNN(Dynamic CNN)是最早应用CNN到文本分类任务中,DCNN使用了动态k-max pooling技术,其模型结构如下:

更为经典的应用是Kim-CNN模型,结构更为简单,如下图,仅使用一个卷积层,同时还探索了三种不同的word embedding的使用方式:
- CNN-rand,随机初始化,在模型训练中更新;
- CNN-static,使用预训练的embedding,在模型训练过程中,word embedding不参与参数更新;
- CNN-non-static,使用预训练embedding作为初始化,实际中一般固定前几轮再对参数进行更新;
- CNN-multi-channel,使用两种方式的embedding,一种参与参数更新,一种不参与更新。

除了词粒度的CNN,还有字符粒度的CNN。如Character-level CNN,其输入的是字符序列,将每个字符转换为one-hot向量,然后接上
6个卷积层(含有池化层)和3层全连接层。其结构如下:

除此之外,VDCNN(Very Deep CNN)模型还借鉴了VGG和ResNet中网络结构,在字符粒度上使用较小的卷积核取得了非常好的效果。
2.4 基于胶囊网络Capsule networks
CNN在图像和文本领域成功应用了卷积层和池化层。尽管池化的操作可以提取重要特征并且可以减小卷积操作后的复杂度,但却丢失相对位置的空间信息。为了解决这个问题,Hinton等人提出了胶囊网路(Capsule networks)。
胶囊网络在文本分类中有两种经典的结构:Capsule-A和Capsule-B,其结构如下:

下面不想看了。。。有点烦人。。。
2.5 基于Attetion机制
2.6 基于记忆增强网络(Memory-augmented networks)
2.7 基于Transformers机制
2.8 基于图神经网络
2.9 基于孪生神经网络(Siamese Neural Network)
2.10 混合神经网络(Hybrid models)
3. 文本分类数据集
(1)情感分析数据集(Sentiment Analysis Datasets)
| 数据集 | 数据集说明 | 数据量(训练/测试) |
| Yelp-2 | 来自yelp的评论数据,二分类 | 560000/38000 |
| Yelp-5 | 来自yelp的评论数据,五个类别 | 650000/50000 |
| IMDB | IMDB网站电影评论数据,二分类 | 25000/25000 |
| Movie Review | 电影评论数据,二分类 | 10662 |
| SST-1 | MR电影评论数据的扩充版,五个类别 | 8544/1101/2210 |
| SST-2 | MR电影评论数据的扩充版,二分类 | 6920/872/1821 |
| MPQA | Multi-Perspective问答数据,二分类 |
10606 |
| Amazon-2 | Amazon的商品评论数据,二分类 | 3600000/400000 |
| Amazon-5 | Amazon的商品评论数据,五个类别 | 3000000/650000 |
(2)新闻分类数据集(News Classification Datasets)
| 数据集 | 数据集说明 | 训练/测试 |
| AGNews | ComeToMyHead收集超过2000个新闻来源的数据集 | 120000/7600 |
| 20 Newsgroups | 包含20个不同主题的新闻数据 | 18821 |
| SogouNews | SogouCA和SogouCS的新闻语料 | - |
| Reuters news | 来自Reulters的新闻数据,常用的是Reuters-21578,90个类别 | 7769/3019 |
(3)主题分类数据集( Topic Classification Datasets )
| 数据集 | 数据集说明 | 训练/测试 |
| DBPedia | 来自于WikiPedia的数据集,14个类别标签 | 560000/70000 |
| Ohsumed | Medline的数据子集,医学文章摘要 | 7400 |
| EUR-Lex | 基于European Union law的数据,包含3956个种类 | 19314 |
| WOS | 来自于Web Of Science的数据,包含多个版本:WOS-46985,WOS-11967和WOS-5736 | - |
| PubMed | 来自医学和生物学的paper数据集,文档类别是MeSH中的类目 | - |
(4)问答数据集(QA Datasets)
| 数据集 | 数据集说明 | 训练/测试 |
| SQuAD | Stanford的问答数据,包含两个版本SQuAD1.1和SQuAD2.0,收集于WikiPedia的问答对 | 1.1:107785 2.0:150000 |
| MS MARCO | 来自于Microsoft,使用Bing搜索引擎获取的问答数据 | - |
| TREC-QA | 有两个版本,TREC-6和TREC-50 | 5452/500 |
| WikiQA | 开放域的问答数据集 | - |
| Quora | 问题对,检测问题对是否相同 | 400000 |
(5)自然语言推理数据集(NLIDatasets)
| 数据集 | 数据集说明 | 训练/测试 |
| SNLI | 句子对,表示句子的关系,一般有neutral,entailment,contradiction | 550152/10000/10000 |
| Multi-NLI | SNLI的扩展版本 | 433000 |
| SICK | 具有neutral,entailment,contradiction的句子关系对 | 10000 |
| MSRP | 文本相似性判断的任务数据集 | 4076/1725 |
4. 实验评估指标
文本分类常用的评估方法主要有:正确率、错误率、准确率、召回率、F1-Score。对于QA和文档排序任务有EM和MRR。
正确率(Accuracy)和错误率(Error):
![]()
![]()
准确率(Precision)、召回率(Recall)和F-Score:
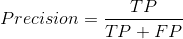
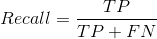
![]()
其中,使用TP表示真正例,FP表示假正例,TN表示真负例,FN表示假负例。
EM(Exact Match)是问答系统中常用的评估方法,衡量预测正确的的答案和给定的标准答案的占比。
MRR(Mean Reciprocal Rank)常用于搜索排序任务中,这里Q表示所有的query, ranki 表示第i个问题对应的标准答案的rank。

5. 挑战和机会(总结)
一句话总结:文本分类,随着很多新颖的想法(如neural embedding,attention mechanism,selft-attetion,Transformer,Bert,XLNet)的诞生,在最近几十年得到了飞快的发展。当然未来还有很多的挑战。
(1)New Datasets for More Challenging Tasks,许多新任务如QA和多轮对话
(2)Modeling Commonsense Knowledg,常识知识的建模
(3)Interpretable Deep Learning Models,深度学习模型的可解释性
(4)Memory Efficient Models,模型的效率
(5)Few-Shot and Zero-Shot Learnin,小样本和零样本的学习