MapReduce Design Patterns-chapter 2
CHAPTER 2:Summarization Patterns
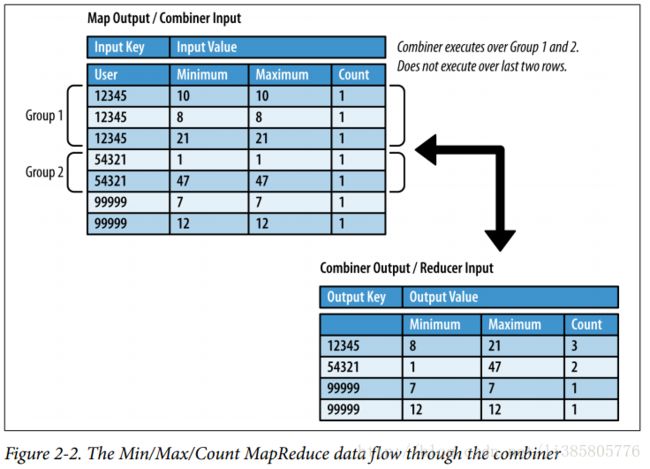
一小时内发表评论长度的最大最小以及求和
public class MinMaxCountTuple implements Writable {
private Date min = new Date();
private Date max = new Date();
private long count = 0;
private final static SimpleDateFormat frmt = new SimpleDateFormat(
"yyyy-MM-dd'T'HH:mm:ss.SSS");
public Date getMin() {
return min;
}
public void setMin(Date min) {
this.min = min;
}
public Date getMax() {
return max;
}
public void setMax(Date max) {
this.max = max;
}
public long getCount() {
return count;
}
public void setCount(long count) {
this.count = count;
}
public void readFields(DataInput in) throws IOException {
// Read the data out in the order it is written,
// creating new Date objects from the UNIX timestamp
min = new Date(in.readLong());
max = new Date(in.readLong());
count = in.readLong();
}
public void write(DataOutput out) throws IOException {
// Write the data out in the order it is read,
// using the UNIX timestamp to represent the Date
out.writeLong(min.getTime());
out.writeLong(max.getTime());
out.writeLong(count);
}
public String toString() {
return frmt.format(min) + "\t" + frmt.format(max) + "\t" + count;
}
}public static class MinMaxCountMapper extends
Mapper {
// Our output key and value Writables
private Text outUserId = new Text();
private MinMaxCountTuple outTuple = new MinMaxCountTuple();
// This object will format the creation date string into a Date object
private final static SimpleDateFormat frmt =
new SimpleDateFormat("yyyy-MM-dd'T'HH:mm:ss.SSS");
public void map(Object key, Text value, Context context)
throws IOException, InterruptedException {
Map parsed = transformXmlToMap(value.toString());
// Grab the "CreationDate" field since it is what we are finding
// the min and max value of
String strDate = parsed.get("CreationDate");
// Grab the “UserID” since it is what we are grouping by
String userId = parsed.get("UserId");
// Parse the string into a Date object
Date creationDate = frmt.parse(strDate);
// Set the minimum and maximum date values to the creationDate
outTuple.setMin(creationDate);
outTuple.setMax(creationDate);
// Set the comment count to 1
outTuple.setCount(1);
// Set our user ID as the output key
outUserId.set(userId);
// Write out the hour and the average comment length
context.write(outUserId, outTuple);
}
} public static class MinMaxCountReducer extends
Reducer {
// Our output value Writable
private MinMaxCountTuple result = new MinMaxCountTuple();
public void reduce(Text key, Iterable values,
Context context) throws IOException, InterruptedException {
// Initialize our result
result.setMin(null);
result.setMax(null);
result.setCount(0);
int sum = 0;
// Iterate through all input values for this key
for (MinMaxCountTuple val : values) {
// If the value's min is less than the result's min
// Set the result's min to value's
if (result.getMin() == null ||
val.getMin().compareTo(result.getMin()) < 0) {
result.setMin(val.getMin());
}
// If the value's max is more than the result's max
// Set the result's max to value's
if (result.getMax() == null ||
val.getMax().compareTo(result.getMax()) > 0) {
result.setMax(val.getMax());
}
// Add to our sum the count for value
sum += val.getCount();
}
// Set our count to the number of input values
result.setCount(sum);
context.write(key, result);
}
} 
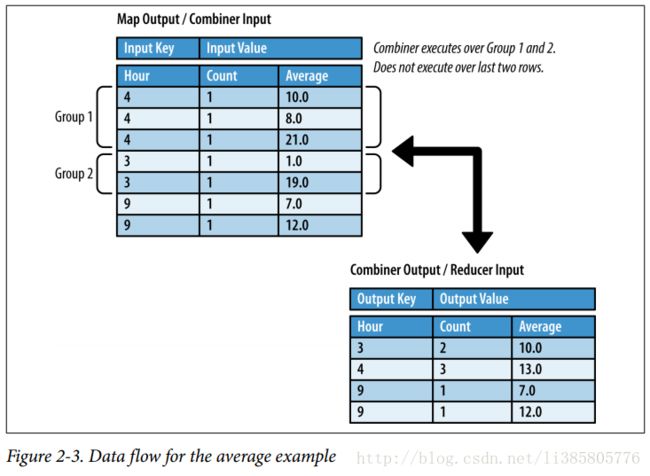
求各小时内评论类容长度的平均值
map的输出为 {小时-(数量,平均值)}
public static class AverageMapper extends
Mapper {
private IntWritable outHour = new IntWritable();
private CountAverageTuple outCountAverage = new CountAverageTuple();
private final static SimpleDateFormat frmt = new SimpleDateFormat(
"yyyy-MM-dd'T'HH:mm:ss.SSS");
public void map(Object key, Text value, Context context)
throws IOException, InterruptedException {
Map parsed = transformXmlToMap(value.toString());
// Grab the "CreationDate" field,
// since it is what we are grouping by
String strDate = parsed.get("CreationDate");
// Grab the comment to find the length
String text = parsed.get("Text");
// get the hour this comment was posted in
Date creationDate = frmt.parse(strDate);
outHour.set(creationDate.getHours());
// get the comment length
outCountAverage.setCount(1);
outCountAverage.setAverage(text.length());
// write out the hour with the comment length
context.write(outHour, outCountAverage);
}
} reduce中进行求整体平均
public static class AverageReducer extends
Reducer {
private CountAverageTuple result = new CountAverageTuple();
public void reduce(IntWritable key, Iterable values,
Context context) throws IOException, InterruptedException {
float sum = 0;
float count = 0;
// Iterate through all input values for this key
for (CountAverageTuple val : values) {
sum += val.getCount() * val.getAverage();
count += val.getCount();
}
result.setCount(count);
result.setAverage(sum / count);
context.write(key, result);
}
} combiner的内容与reduce一致
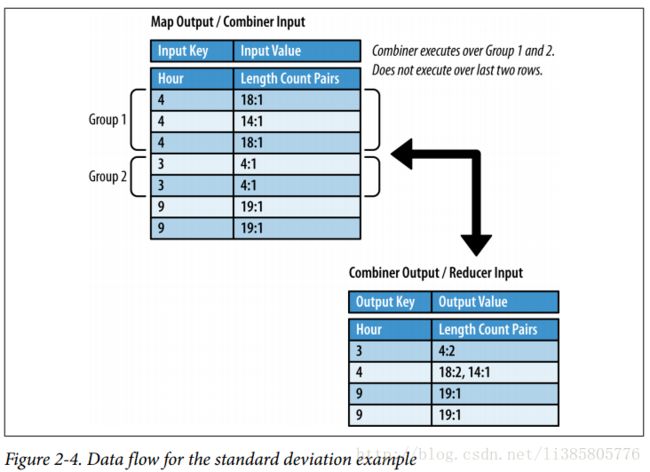
求个小时中评论长度的中位数与标准差
方法一:无法利用combiner
map的输出为时间和评论长度
public static class MedianStdDevMapper extends
Mapper {
private IntWritable outHour = new IntWritable();
private IntWritable outCommentLength = new IntWritable();
private final static SimpleDateFormat frmt = new SimpleDateFormat(
"yyyy-MM-dd'T'HH:mm:ss.SSS");
public void map(Object key, Text value, Context context)
throws IOException, InterruptedException {
Map parsed = transformXmlToMap(value.toString());
// Grab the "CreationDate" field,
// since it is what we are grouping by
String strDate = parsed.get("CreationDate");
// Grab the comment to find the length
String text = parsed.get("Text");
// get the hour this comment was posted in
Date creationDate = frmt.parse(strDate);
outHour.set(creationDate.getHours());
// set the comment length
outCommentLength.set(text.length());
// write out the user ID with min max dates and count
context.write(outHour, outCommentLength);
}
} redece求中位数和标准差
public static class MedianStdDevReducer extends
Reducer {
private MedianStdDevTuple result = new MedianStdDevTuple();
private ArrayList commentLengths = new ArrayList();
public void reduce(IntWritable key, Iterable values,
Context context) throws IOException, InterruptedException {
float sum = 0;
float count = 0;
commentLengths.clear();
result.setStdDev(0);
// Iterate through all input values for this key
for (IntWritable val : values) {
commentLengths.add((float) val.get());
sum += val.get();
++count;
}
// sort commentLengths to calculate median
Collections.sort(commentLengths);
// if commentLengths is an even value, average middle two elements
if (count % 2 == 0) {
result.setMedian((commentLengths.get((int) count / 2 - 1) +
commentLengths.get((int) count / 2)) / 2.0f);
} else {
// else, set median to middle value
result.setMedian(commentLengths.get((int) count / 2));
}
// calculate standard deviation
float mean = sum / count;
float sumOfSquares = 0.0f;
for (Float f : commentLengths) {
sumOfSquares += (f - mean) * (f - mean);
}
result.setStdDev((float) Math.sqrt(sumOfSquares / (count - 1)));
context.write(key, result);
}
} 方法二:可以利用combiner
map的输出为{小时-(长度,1)}
public static class MedianStdDevReducer extends
Reducer {
private MedianStdDevTuple result = new MedianStdDevTuple();
private TreeMap commentLengthCounts =
new TreeMap();
public void reduce(IntWritable key, Iterable values,
Context context) throws IOException, InterruptedException {
String strDate = parsed.get("CreationDate");
// Grab the comment to find the length
String text = parsed.get("Text");
// Get the hour this comment was posted in
Date creationDate = frmt.parse(strDate);
outHour.set(creationDate.getHours());
commentLength.set(text.length());
SortedMapWritable outCommentLength = new SortedMapWritable();
outCommentLength.put(commentLength, ONE);
// Write out the user ID with min max dates and count
context.write(outHour, outCommentLength);
}
} combiner后的结果为{小时-(长度,次数)}
reduce中求中位数和标准差
public static class MedianStdDevReducer extends
Reducer {
private MedianStdDevTuple result = new MedianStdDevTuple();
private TreeMap commentLengthCounts =
new TreeMap();
public void reduce(IntWritable key, Iterable values,
Context context) throws IOException, InterruptedException {
float sum = 0;
long totalComments = 0;
commentLengthCounts.clear();
result.setMedian(0);
result.setStdDev(0);
for (SortedMapWritable v : values) {
for (Entry entry : v.entrySet()) {
int length = ((IntWritable) entry.getKey()).get();
long count = ((LongWritable) entry.getValue()).get();
totalComments += count;
sum += length * count;
Long storedCount = commentLengthCounts.get(length);
if (storedCount == null) {
commentLengthCounts.put(length, count);
} else {
commentLengthCounts.put(length, storedCount + count);
}
}
}
long medianIndex = totalComments / 2L;
long previousComments = 0;
long comments = 0;
int prevKey = 0;
for (Entry entry : commentLengthCounts.entrySet()) {
comments = previousComments + entry.getValue();
if (previousComments ≤ medianIndex && medianIndex < comments) {
if (totalComments % 2 == 0 && previousComments == medianIndex) {
result.setMedian((float) (entry.getKey() + prevKey) / 2.0f);
} else {
result.setMedian(entry.getKey());
}
break;
}
previousComments = comments;
prevKey = entry.getKey();
}
// calculate standard deviation
float mean = sum / totalComments;
float sumOfSquares = 0.0f;
for (Entry entry : commentLengthCounts.entrySet()) {
sumOfSquares += (entry.getKey() - mean) * (entry.getKey() - mean) *
entry.getValue();
}
result.setStdDev((float) Math.sqrt(sumOfSquares / (totalComments - 1)));
context.write(key, result);
}
} 
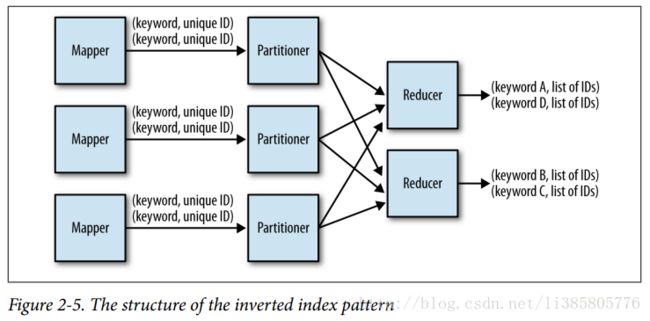
倒排索引
map的输出为{链接-文档}public static class WikipediaExtractor extends
Mapper {
private Text link = new Text();
private Text outkey = new Text();
public void map(Object key, Text value, Context context)
throws IOException, InterruptedException {
Map parsed = MRDPUtils.transformXmlToMap(value
.toString());
// Grab the necessary XML attributes
String txt = parsed.get("Body");
String posttype = parsed.get("PostTypeId");
String row_id = parsed.get("Id");
// if the body is null, or the post is a question (1), skip
if (txt == null || (posttype != null && posttype.equals("1"))) {
return;
}
// Unescape the HTML because the SO data is escaped.
txt = StringEscapeUtils.unescapeHtml(txt.toLowerCase());
link.set(getWikipediaURL(txt));
outkey.set(row_id);
context.write(link, outkey);
}
} reduce中执行文档串的append
public static class Concatenator extends Reducer {
private Text result = new Text();
public void reduce(Text key, Iterable values, Context context)
throws IOException, InterruptedException {
StringBuilder sb = new StringBuilder();
boolean first = true;
for (Text id : values) {
if (first) {
first = false;
} else {
sb.append(" ");
}
sb.append(id.toString());
}
result.set(sb.toString());
context.write(key, result);
}
} 
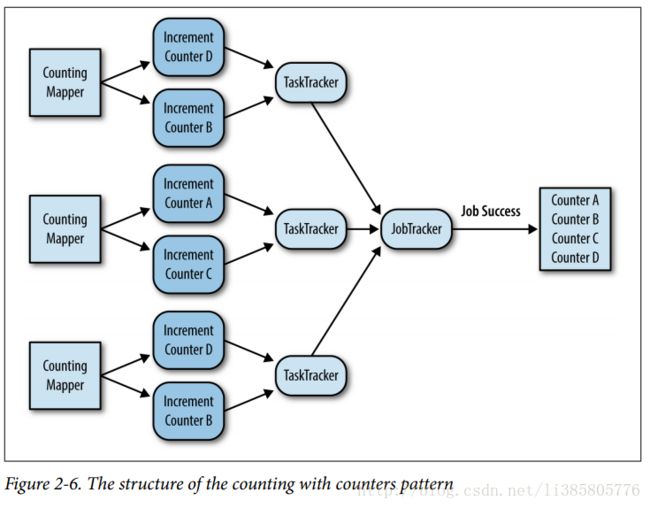
利用Counter执行计数,统计每个洲的人数
public static class CountNumUsersByStateMapper extends
Mapper {
public static final String STATE_COUNTER_GROUP = "State";
public static final String UNKNOWN_COUNTER = "Unknown";
public static final String NULL_OR_EMPTY_COUNTER = "Null or Empty";
private String[] statesArray = new String[] { "AL", "AK", "AZ", "AR",
"CA", "CO", "CT", "DE", "FL", "GA", "HI", "ID", "IL", "IN",
"IA", "KS", "KY", "LA", "ME", "MD", "MA", "MI", "MN", "MS",
"MO", "MT", "NE", "NV", "NH", "NJ", "NM", "NY", "NC", "ND",
"OH", "OK", "OR", "PA", "RI", "SC", "SF", "TN", "TX", "UT",
"VT", "VA", "WA", "WV", "WI", "WY" };
private HashSet states = new HashSet(
Arrays.asList(statesArray));
public void map(Object key, Text value, Context context)
throws IOException, InterruptedException {
Map parsed = MRDPUtils.transformXmlToMap(value
.toString());
// Get the value for the Location attribute
String location = parsed.get("Location");
// Look for a state abbreviation code if the
// location is not null or empty
if (location != null && !location.isEmpty()) {
// Make location uppercase and split on white space
String[] tokens = location.toUpperCase().split("\\s");
// For each token
boolean unknown = true;
for (String state : tokens) {
// Check if it is a state
if (states.contains(state)) {
// If so, increment the state's counter by 1
// and flag it as not unknown
context.getCounter(STATE_COUNTER_GROUP, state)
.increment(1);
unknown = false;
break;
}
}
// If the state is unknown, increment the UNKNOWN_COUNTER counter
if (unknown) {
context.getCounter(STATE_COUNTER_GROUP, UNKNOWN_COUNTER)
.increment(1);
}
} else {
// If it is empty or null, increment the
// NULL_OR_EMPTY_COUNTER counter by 1
context.getCounter(STATE_COUNTER_GROUP,
NULL_OR_EMPTY_COUNTER).increment(1);
}
}
} ...
int code = job.waitForCompletion(true) ? 0 : 1;
if (code == 0) {
for (Counter counter : job.getCounters().getGroup(
CountNumUsersByStateMapper.STATE_COUNTER_GROUP)) {
System.out.println(counter.getDisplayName() + "\t"
+ counter.getValue());
}
}
// Clean up empty output directory
FileSystem.get(conf).delete(outputDir, true);
System.exit(code);map没有输出,只是更新组中对应counter的计数值,在内部机制中Job-Tractor会将各个task-Tractor中的counter求和。不用reduce