java基础知识
概括
- 学前知识
- 岗位分析
- 合格的程序员素养:Do more,Do better,Do share!
- 软件开发流程(软件开发生命周期)
- 计算机常识
- Java语言发展史
- JDK:Java 语言的软件开发工具包
- jdk环境变量配置
- java基础
- 两大数据类型
- 基本类型:
- 引用类型:
- 标识符
- 关键字:在java语言中已经被赋予特定意义的一些单词。
- 运算符
- 运算顺序
- 泛型
- 注释
- 转义字符
- 变量概念:可以改变的数,称为变量。
- 包装类
- 数组
- 创建数组:
- 数组的遍历
- 二维数组:
- 数组工具:Arrays
- 面向对象(Object Oriented Programming)
- 封装概述:
- extends(继承)概述:代码复用,功能拓展
- (多态)概述:统一类型(当父类)行为的多态(所有抽象方法都是多态的),对象的多态(所有对象都是多态的)
- 类和对象
- 类
- 方法
- 内部类
- 对象
- 对象创建加载执行过程
- 对象在内存中的存储
- 构造方法(Constructor)
- this/super关键字
- final/static关键字
- 代码块
- 异常
- 抽象类(abstract) /接口(interface)/注解(@interface)
- 反射(reflect)
- 设计模式
- 设计模式六大原则
- 23种设计模式
- JVM内存
- 正则表达式:regular Expression
- 调试打桩
- Debug调试
- 打桩
- 引用关系
- 字符编码/解码
- 数据结构
- 算法
- 知识一眼穿
学前知识
岗位分析
初级程序员 中级程序员 高级程序员
系统分析师 架构师 技术总监 技术副总CTO
合格的程序员素养:Do more,Do better,Do share!
逻辑思维能力,把需求能描述清楚
找重点的能力,从琐碎的细节中找到核心,什么是重要的,什么是可以暂时忽略
总结能力 3w1h,Why? Where? When? How?
解决问题能力,面对未知能快速解决,分担领导的工作
汇报能力,给经理、高层、客户等汇报工作,word、ppt,用数据说话
团队精神,乐于分享
软件开发流程(软件开发生命周期)

意向 软件项目立项,立项报告,立项审批 需求调研,需求评审
概要设计,用例图,页面原型设计 数据库设计,表设计 详细设计,类设计
开发编码 需求变更 测试 试运行,bug满天飞(加班)
正式上线 维护期 项目完成
计算机常识
计算机(Computer)全称:电子计算机,俗称电脑。是一种能够按照程序运行,自动、高速处理数据的现代化智能电子设备。由硬件和软件所组成,没有安装任何软件的计算机称为裸机。常见的形式有台式计算机、笔记本计算机。按照规模分为微型机、小型机、大型机、巨型机(超级计算机)等。
- 硬件:算机系统中由电子,机械和光电元件等组成的各种物理装置的总称,CPU、主板、内存、电源、主机箱、硬盘、显卡、键盘、鼠标,显示器

- 软件:使计算机按照事先预定好的顺序完成特定的功能,计算机软件按照其功能划分为系统软件与应用软件统软件: DOS(Disk Operating System), Windows, Linux, Unix, Mac, Android, iOS,应用软件:office QQ 英雄联盟 王者荣耀
- 语言是人类进行沟通交流的各种表达符号,方便人与人之间进行通与信息交换。计算机语言则是人与计算机之间进行信息交流沟通的一种特殊语言,计算机语言中也有字符、符号等等,常见的计算机语言如C,C++,C#,JAVA,
- 人机交互:

- 进制
进制是一种记数方式,可以用有限的数字符号代表所有的值,由特定的值组成。

进制之间互相转换规则:
十进制转换成二进制:不断除以2取余

二进制转换成十进制:从低位次起,按位次乘以2的位次次幂,然后求和
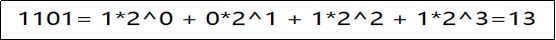
Java语言发展史
詹姆斯·高斯林1990开发的语言“oak”后改名java
Sun公司于1995年推出
1991年sun公司James Gosling等人开始开发Oak语言
1994年,将Oak语言更名为Java
1996年获得第一笔投资1亿元
1998年提出jdk1.2,更名为java2
之后推出jdk1.3 jdk1.4
2005年更名为jdk5.0,进行了大幅的版本改进
2006年sun公司宣布将Java作为免费软件对外发布
2007年3月起,全世界所有开发人员均可对Java源码进行修改
2007年推出jdk6.0
2009年4月Oracle以74亿美元收购了sun公司
2011年7月由Oracle正式发布jdk7
2014年3月正式发布了java8
各平台版本:
J2SE(Java 2 Platform Standard Edition)标准版
是为开发普通桌面和商务应用程序提供的解决方案,该技术体系是其他两者的基础,可以完成一些桌面应用程序的开发。
J2ME(Java 2 Platform Micro Edition)小型版
是为开发移动设备和嵌入式设备(电器、机器人、机顶盒…)提供的解决方案。
J2EE(Java 2 Platform Enterprise Edition)企业版
是为开发企业环境下的应用程序提供的一套解决方案,该技术体系中包含的技术如 Servlet、Jsp等,主要针对于Web应用程序开发。
java语言特征:简单、高性能、变异性、解释性、分布式处理、安全性、健壮性面向对象、跨平台
- java执行过程
- 编译过程:
IDE保存时会自动调用jdk目录下的/bin/javac.exe,会生成对应的.class文件

src/javase/base目录下的HelloWorld.java 编译成 HelloWorld.class 字节码文件,存放在 bin 目录下 - 执行过程:
先启动Java虚拟机(JVM)
JVM加载HelloWorld.class字节码文件
进入这个类的 main() 方法执行(入口函数,唯一的)

- java生态圈介绍:
Nginx实现负载均衡提高并发能力;Redis实现分布式缓存提高系统整体性能和并发能力;MyCat实现数据库代理,主从复制实现数据安全备份,读写分离实现性能提升;RabbitMQ消息队列实现削峰填谷,支持亿级并发;Lucene+Solr/ES实现数据的全文检索,亿级数据秒级返回查询结果;Docker容器化技术实现单机百万级进程服务,实现故障秒级切换;Dubbo阿里微服务RPC框架;SpringCloud微服务全家桶框架提升整个系统的健壮性,等等。这些技术不胜枚举,形成java生态链环境,支撑起java庞大的技术体系帝国;
JDK:Java 语言的软件开发工具包
在JDK的安装目录下有一个jre目录,里面有两个文件夹bin和lib,在这里可以认为bin里的就是jvm,lib中则是jvm工作所需要的类库,而jvm和 lib合起来就称为jre。它包含了:在目录下面有六个文件夹、一个src类库源码压缩包、和其他几个声明文件。其中,真正在运行java时起作用的 是以下四个文件夹:
bin:最主要的是编译器(javac.exe)
include:java和JVM交互用的头文件
lib:类库 jre:java运行环境
JRE(Java Runtime Environment,Java运行环境),包含JVM标准实现及Java核心类库。JRE是Java运行环境,并不是一个开发环境,所以没有包含任何开发工具(如编译器和调试器)
JVM是Java Virtual Machine(Java虚拟机)的缩写,JVM是一种用于计算设备的规范,它是一个虚构出来的计算机,是通过在实际的计算机上仿真模拟各种计算机功能来实现的。

所有的Java程序是运行在Java虚拟机上的,Java虚拟机屏蔽了不同操作系统之间的差异性,是的相同的Java程序能够在不同的操作系统上运行,从而实现了Java语言的跨平台;

注意:Java语言是跨平台的,但是Java虚拟机不是跨平台的
- JVM工作图:

jdk环境变量配置
操作系统通过配置的环境变量去定位需要的执行文件,例如:java程序都是通过java.exe来操作的。可到哪去找呢?我们就要设置系统环境变量,告诉操作系统去哪里找。
JAVA_HOME #配置Java的安装目录
PATH #执行可执行文件exe所在目录/bin,引入基础包的支持如rt.jar
CLASSPATH # (可选)不建议配置,对初学者太繁琐
配置JDK的安装目录路径,其他开发工具,或其他Java程序,运行时,通过JAVA_HOME变量,来找到JDK目录。
计算机-右键属性-高级系统设置-环境变量-添加(JAVA_HOME)属性,属性值指向JDK的安装目录;在path属性中用添加入jdk\bin的路径,以(;)结束。
path环境变量:用来指引计算机在电脑上找到需要执行的命令程序所在的包路径,不配置的话需要在cmd中切换到该命令程序的所在包,然后也可以运行;
配置成功后检测
>echo %JAVA_HOME% #通过操作系统windows提供echo命令,展示环境变量的值
>java -version #配置了JAVA_HOME环境变量就可以任意目录下执行java命令了,-version参数代表查看java的当前版本号
>exit #退出dos窗口
程序内获取JDK相关信息:
public class TestSystemEnv {
@Test
public void javaInfo() {
System.out.println("==java信息===========");
System.out.println("java的版本号:"+System.getProperty("java.version"));
System.out.println("java的所在目录:"+System.getProperty("java.home"));
}
@Test
public void userInfo() {
System.out.println("\n==用户信息===========");
System.out.println("所属的登录用户:"+System.getProperty("user.name"));
System.out.println("默认存储文件路径:"+System.getProperty("user.dir"));
}
@Test
public void dateTimeInfo() {
System.out.println("\n==时间信息===========");
System.out.println("当前毫秒数:" + System.currentTimeMillis());
System.out.println("当前纳秒数:" + System.nanoTime());
System.out.println("当前日期:" + new Date());
}
}
java基础

两大数据类型
基本数据类型变量存的是数据本身,而引用类型变量存的是保存数据的空间地址

基本类型:
基本数据类型相互赋值时,直接获得对方的值,修改其他变量的值,不会影响自身的值;

1. 整数字面值是int类型
int a = 999999999999999;//右面的数据太大,超出了int范围会报错。
2. byte,short,char可以用范围内的值直接赋值
byte b = 127;
byte b2 = 128;//报错,因为超出了byte取值范围
3. 浮点数的字面值是double类型
float f = 3.0; //报错,右面字面值是double类型,大类型,左面的小类型float放不开;
4. 字面值后缀符:LFD
long a = 999999999999L;//右侧的整数默认类型是int,已经超出int范围只能扩大范围保存需要加后缀L
float b = 3.0F;//右侧3.0默认double类型,加后缀L就强制转成了float类型
double d = 3D;//把右侧的3从默认值int类型,转成了double类型
5. 进制前缀
0x - 16进制
0 -8进制
\u -char类型,16进制
6 基本类型的类型转换
6.1: 小到大/隐式转换:double b = 5;
6.2: 大到小/显式/强制转换:int b = (int)1.2;
6.3: 浮点数转成整数,小数直接舍弃:(int)1.2 = 1;
6.4: 计算结果的数据类型,与最大类型一致:double b=1+1.1;
6.5: byte,short,char三种比int小的整数,运算时会先自动转换成int:如果继续用byte,short,char接收,需要强制转换;
6.6:整数运算可能会溢出:100万*100万>21亿多会溢出,运算中加L解决;
6.7:浮点数运算不精确:10进制转2进制除不尽;
解决方案:BigDecimal:常用来解决精确的浮点数运算。BigInteger:常用来解决超大的整数运算、
(BIgInteger类与BigDecimal的玩法一样)
创建对象:BigDecimal.valueOf(2);
add(BigDecimal bd): 做加法运算
substract(BigDecimal bd) : 做减法运算
multiply(BigDecimal bd) : 做乘法运算
divide(BigDecimal bd) : 做除法运算
divide(BigDecimal bd,保留位数,舍入方式):除不尽时使用
setScale(保留位数,舍入方式):同上 pow(int n):求数据的几次幂
6.8: 浮点数的特殊值
Infinity 无穷大 3.14/0
NaN not a number 0/0.0 Math.sqrt(-5)
引用类型:
(String,数组,自造类…)引用数据类型在赋值时,获得的是对方的引用,多个引用指向同一个对象时,修改一个引用的值,会影响其他引用的值;null是引用类型的默认值,指的时该引用没有指向任何对象,调用属性或者方法,会发生nullPointerException;
Java中的赋值都是值传递,基本类型直接获取对方的值,引用类型获得对方的地址引用;
值传递:值传递是指在调用方法时将实际参数复制一份传递到函数中,这样在函数中如果对形参数进行修改,将不会影响到实际参数,简单来说就是直接复制了一份数据过去,因为是直接复制,所以这种方式在传递时如果数据量非常大的话,运行效率自然就会变低了。
引用传递:引用传递就是将对象的地址值传递过去,方法接受的是数据的地址值。在方法的执行过程中,形参和实参的内容相同,指向同一块内存地址,也就是说操作的都是源数据,所以方法的执行将会影响到实际对象。
参数传递方式-值传递
值传递:方法参数传递时候将实际参数变量的值赋值一份给目标参数,出了该方法变量消失,不影响原来的值(除非做原引用指向该值操作)
如果面试官思想有误区!建议说法:
1.参数传递方式有只有一种
2.因为方法可以和被调用方法共享一个对象,所以有两种表现。
标识符
可以简单的理解为一个名字。在Java中,我们需要标识代码的很多元素,包括类名、方法、字段、变量、包名等。我们选择的名称就称为标识符,并且遵循以下规则:
A. 标识符可以由字母、数字、下划线(_)、美元符($)组成,但不能包含 @、%、空格等其它特殊字符。
B. 不能以数字开头。
C. 标识符是严格区分大小写的。
D. 标识符的命名最好能反映出其作用,做到见名知意。
关键字:在java语言中已经被赋予特定意义的一些单词。

一共有53个关键字。其中有两个保留字:const、goto。
关键字不能被用作标识符!!
特殊关键字:
别忘了java虽没有强调其是关键字,但也不许使用
native 即 JNI,Java平台有个用户和本地C代码进行互操作的API,称为Java Native Interface (Java本地接口)
strictfp,即 strict float point (精确浮点)
transient当串行化某个对象时,如果该对象的某个变量是transient,那么这个变量不会被串行化进去。
assert,断言是为了方便调试程序,并不是发布程序的组成部分。默认情况下,JVM是关闭断言的
volatile,多线程并发,变量可见

运算符

&与&&的区别:
&与&&都可以作为逻辑运算符,表示逻辑与。当运算符两边的表达式都为true时,结果才为true,否则结果为false;
另外&&还具有断流功能,也就是说,当&&左边的表达式结果为false时,将不再运行&&右边的表达,结果肯定为false;例如if(str!=null&&!str.equals(“”)),当str为null时,不会对&&右边表达式进行运算,否则会出现空指针异常;
&还可以当做运算符,当&两边的表达式不是boolean类型时,&表示按位与;
运算顺序
1 顺序结构:未添加任何分支或者循环结构代码,所有代码从上到下依次执行;
2 分支结构:按条件满足与否执行代码,可跳过未满足条件代码;
2.1:if else:
double price = new Scanner(System.in).nextDouble();
//分支结构:多个条件时用嵌套的分支结构
double now = price;//记录折后价
if(price >= 5000){//满5000
now = price*0.5 ;//打5折
}else if(price >= 2000){//满2000
now = price*0.8 ;//打8折
}else ({//低于2000不打折
now = price;
}
2.2:switch case:当一个case成立时,从这个case向后穿透所有case,包括default。直到程序结束 } 或者遇到break程序才结束。没有匹配则执行default;支持byte/short/char/int,jdk1.7之后支持String类型匹配;
int i = 2;
switch(i) {
case 0:System.out.println(0);break;
case 1:System.out.println(1);break;
case 2:System.out.println(2);break;
case 3:System.out.println(3);break;
case 4:System.out.println(4);break;
default:System.out.println("8");
3 循环结构:循环结构是指在程序中需要反复执行某个功能而设置的一种程序结构。
它由循环体中的条件,判断继续执行某个功能还是退出循环。
根据判断条件,循环结构又可细分为先判断后执行的循环结构和先执行后判断的循环结构;
3.1:for(开始条件;判断条件;更改条件){循环体;}
例如:下面是for循环写的冒泡排序
for(int i=0;i<a.length;i++){外层循环控制轮数
for(int j=a.length-1;j>i;j--){控制每一轮次数
if(a[j]<a[j-1]){//每次都和它上一个元素比
int t=a[j];
a[j]=a[j-1];
a[j-1]=t; }
3.2: while(执行条件(布尔值)){先判断执行}
3.3: do{先执行后判断}while(执行条件(布尔值))
3.4: for(数组/集合:元素){System.out.println(元素);}
总结:知道循环执行多少次用for循环,不知道循环运行多少次的情况下用while循环,不论结果真假都要运行一次优先选用do while循环。
循环结构中的关键字:
break:跳出当前循环/方法/switch;
Continue:跳过当前循环,进入下一次循环;
3.5 JDK5推出了增强型for循环(for each):用来遍历数组或者集合,JVM并不认可,编译器在编译的时候发觉用新循环时会将其更换成普通for循环遍历或者迭代器(Iterator)遍历;
for(string s : names){
System.out.println("取出名字:"+s);
}
泛型
JDK5推出的另一个特性:泛型 (参数化类型) :可以在使用一个类时指定其属性,方法的参数和返回值类型,这可以提高代码的灵活度。泛型在集合中广泛被使用,用来指定集合中元素的类型。
- 作用
通过泛型的语法定义,约束集合元素的类型,编译器可以在编译期提供一定的类型安全检查,避免运行时才暴露bug。
代码通用性更强,后面有案例
泛型可以提升程序代码的可读性,但它只是一个语法糖(编译后这样的东西就被删除,不出现在最终的源代码中),对于JVM运行时的性能是没有任何影响的。
泛型可以在接口、方法、返回值上使用:
java.util.List泛型接口:
public interface List<E> extends Collection<E> {}
泛型方法的声明:
public static <E> void print(E[] arr) {}
在方法返回值前声明了一个<E>表示后面出现的E是泛型,而不是普通的java变量。
public <T> T getBean(String beanName);
定义泛型方法,<T>标识后面出现的T是泛型的意思,后面的T标识是返回值通用。
- 泛型通配符:
?无界通配
?extends 类型(限定上界通配符)
?super 类型(限定下界通配符) - 常用泛型
E - Element (在集合中使用,因为集合中存放的是元素)
T - Type(Java 类)
K - Key(键)
V - Value(值)
N - Number(数值类型)
? - 表示不确定的java类型
public static <T extends Comparable<T>> T maximum(T x, T y, T z){}
- 泛型类型擦除:泛型在编译阶段有效,运行时无效,可通过反射获取List对象的add方法,通过invoke执行方法,可以放进List泛型外的参数
public class Hoo<T> {
private T t;
public void add(T t) { this.t = t; }
public T get() { return t; }
public static void main(String[] args) {
Hoo<Integer> intHoo = new Hoo<Integer>();
Hoo<String> strHoo = new Hoo<String>();
intBox.add(new Integer(10));
strHoo.add(new String("字符串"));
System.out.println("整型值泛型为 ", intHoo.get());
System.out.println("字符串泛型为 ", strHoo.get()); }}
注释
Java代码的解释说明。不影响程序的运行,用于辅助读程。
//单行注释
/* 多行注释 /
/* 文档注释 */
转义字符
一些字母前加""来表示常见的那些不能显示的ASCII字符,如\0,\t,\n等,就称为转义字符,因为后面的字符,都不是它本来的ASCII字符意思了。
常见的转义字符:

\n 换行(LF) ,将当前位置移到下一行开头
\t 水平制表(HT) (跳到下一个TAB位置)
\\ 代表一个反斜线字符''\'
\' 代表一个单引号(撇号)字符
\" 代表一个双引号字符
变量概念:可以改变的数,称为变量。
一般通过三部分来描述一个变量。变量类型,变量名,变量值。其中三部分都是可以改变的,根据需要来确定即可。
int a = 5;
变量的使用原则:就近原则。尽量控制到最小范围。
局部变量:定义在方法里,或者局部代码块中。
注意:必须手动初始化,来分配内存。如:int i=5; 或者 int i; i=5;
作用域也就是方法里或者局部代码块里,方法运行完内存就释放了。
1、 一般来讲局部变量存在栈中,方法执行完毕内存就被释放;
2、 对象(new出来的东西)存在堆中,对象不再被使用时,内存才会被释放;
3、 每个堆内存的元素都有地址值;字符串常量池也存在堆内存中;
4、 对象中的属性都是有默认值的;
成员变量:定义在类里,方法外。
注意:不用初始化,也会自动被初始化成默认值。
作用域是整个类中,类消失了,变量才释放。
反义词:常量:在程序运行过程中一直不会改变的量称为常量。用final修饰;
包装类
java是面向对象的语言,基本数据类型不是对象,所以提供了包装类用于将基本类型数据包装成对象使用,它相当于将基本类型包装起来,使得基本类型拥有对象的性质,为其添加了属性和方法,丰富了基本类型的操作。另外,像往ArrayList,HashMap中放元素时,基本类型是放不进去的,因为容器都是装Object;但是若只用于计算,基本类型计算的速度比包装类型计算更快;
number是数字包装类的抽象父类。提供了各种获取值的方式。
在方法体内部尽量使用基本类型,占空间小,用完就释放内存,节约内存
在pojo时尽量使用包装类型,例如mybatis持久层框架就必须使用包装类型,否则可能出错哦。
例如:intvalue(Integer),返回Int值,其余类推;
自动装箱和自动拆箱:jdk1.5后推出,编译器实现;
自动装箱:把基本类型包装成一包装类的对象
Integer a = 5;//a是引用类型,引用了包装对象的地址。
编译器会完成对象的自动装箱:Integer a = Integer.valueOf(5);
自动拆箱:从包装对象汇总,自动去除基本类型值
int i = a;//a现在是包装类型,没法给变量赋值,需要把5取出来。
编译器会完成自动拆箱:int i = a.intValue();
数组
数组Array,标志是[]。例如:int[]days,String[]args,byte[]data
是用于储存多个相同类型数据的集合。
想要获取数组中的元素值,可以通过脚标(下标)来获取,下标是从0开始的。
数组的长度为length属性,一旦创建,长度不可变,并且允许长度0的数组存在
- 变长参数:(参数类型…参数代词):
变长参数在一个方法中只能定义一个,并且只能作为方法的最后一个参数使用。变长参数本质就是一个数组,在调用方法时,可以传参数类型的参数0到多个,该参数可以调数组的.length()方法。
例如:public void count(int...numbers){
System.out.println(numbers.length());
};
创建数组:
动态初始化
int[] a = new int[10];
静态初始化
int[] b = new int[]{1,2,3,4,5};
int[] c = {1,2,3,4,5};
数组的遍历
从头到尾,依次访问数组的位置。
//静态创建数组
int[] a = {31,28,31,30,31,30,31,31,30,31,30,31};
//根据数组的每个下标来遍历,i表示下标
//int i = 0,从下标为0的元素开始依次向后遍历
//a.length是数组的长度
for( int i = 0 ; i < a.length ; i++ ) {
//a[i]是根据下标获取元素的值
System.out.println((i+1)+"月有"+a[i]+"天");
二维数组:
概念:存放数组的数组,也就是说数组里存的还是数组的数据形式。
1、静态初始化
int[][] a= {{1,2},{3,4},{5,6},{8,9}}
for(int i=0;i<a.length;i++){//遍历外部数组
for(int j=0;j<a[i].length;j++){//遍历内部数组
syso(a[i][j]);//根据外围数组下标和内部数组下标结合定位元素
} }
数组工具:Arrays
Arrays是操作数组的API,提供了一系列方法对数组进行操作。
1:Arrays.sort(数组)
对数组排序,对于基本类型的数组使用优化后的快速排序算法,效率高。
对引用类型数组,使用优化后的合并排序算法。
2:Arrays.toString(数组)
把数组里的数据,用逗号连接成一个字符串。【值1,值2】
3:Arrays.copyOf(原数组,新的长度)
把数组复制成一个指定长度的新数组。
新数组长度大于原数组,相当于复制,并增加位置(扩容)
新数组长度小于原数组,相当于截取前一部分数据(缩容) //以下方法不由Arrays提供(但是类似功能)
System.arraycopy(原数组,原数组开始复制下标,新数组,新数组开始复制下标,复制原数组中元素个数/新数组长度);
4:Arrays.asList(数组)
把当前数组以一个List集合形式返回,因为Set不可存重复元素,所以不能以set返回
List<T>list = Arrays.asList(array);
面向对象(Object Oriented Programming)
面向对象是一种编程思想,相对于面向过程来的。面向过程是每一步都要落在实处,而面向对象可以把面向过程的步骤进行封装保存为面向对象的对象的一个方法或者属性。
对于面向过程思想OPP,强调的是过程(动作)主要关注“怎么做”。C语言
对于面向对象思想OOP,强调的是对象(实体)主要关注“谁来做”。Java语言
三大特征:
1.封装(Encapsulation)隐藏对象的属性和实现细节,仅对外提供公共访问方式,将变化隔离,便于使用,提高复用性和安全性。
2.继承(Inheritance)提高代码复用性;继承是多态的前提。
3.多态(Polymorphism)父类或接口定义的引用变量可以指向子类或具体实现类的实例对象。提高了程序的拓展性。
封装概述:
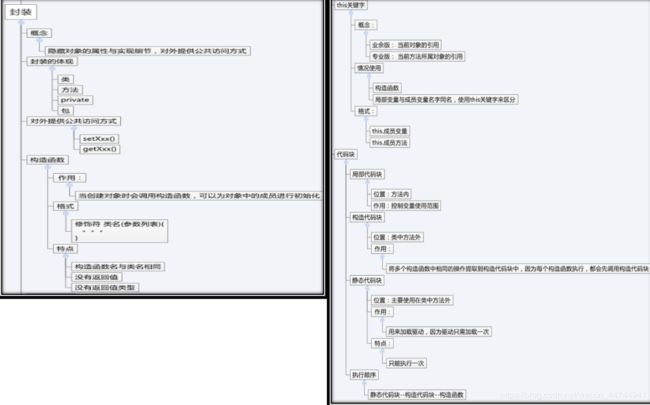
封装(Encapsulation)是面向对象方法的重要原则,就是把对象的属性和操作(或服务)结合为一个独立的整体,并尽可能隐藏对象的内部实现细节。
封装是把过程和数据包围起来,对数据的访问只能通过已定义的接口。面向对象设计始于这个基本概念,即现实世界可以被描绘成一系列完全自治、封装的对象,这些对象通过一个受保护的接口访问其他对象。封装可以让程序更容易理解和维护,也加强了程序的安全性。封装给对象赋予了“黑盒“特征,这是提高重用性和安全性的关键。让开发者关注结果而不用去关注每个细节。
减少代码的耦合
对外隐藏细节,暴露的越少,安全性越好
规定统一入口,控制数据访问
1.类封装的是对象的属性和行为;
2.方法封装的是特定的业务逻辑功能;
3.访问控制修饰符:封装的是具体的访问权限;
- private关键字
private是一个权限修饰符,用于修饰成员变量和成员函数/方法,被私有化的成员只能在本类中访问。
extends(继承)概述:代码复用,功能拓展
*1.继承使用extends关键字实现,用于子类对父类功能的拓展;
*2.子类与父类是is a的关系;
*3.是发生在两个类里,被继承的类叫超类/基类/父类/,实现继承的类叫派生类/子类;
*4. java是单继承关系,子类只能继承一个类,子类继承父类之后,可以使用父类非private修饰的成员方法和成员变量;
*5.继承具有传递性,子类不仅可以使用父类非私有的方法和属性,也可以使用父类的父类的非私有方法和属性;
*6.Object类是所有类的默认父类(所有类拥有它的方法);
坚持是否是继承或者实现关系:if(a instanceof b)
overload(重载):
- 在同一个类中,方法名相同,参数列表不同的多个方法;
- 在调用重载的方法时,编译器会自动绑定要调用的方法;
- 重载的好处:在程序中相似的业务不用记忆方法名对应的参数,直接使用同一的方法名,传入参数自动调用对应参数方法;
override(重写):
* 当父类的方法不能满足子类的需求时,就需要修改父类原有的功能,这就是重写方法;
* 方法的重写需满足:方法签名和父类完全一样,方法权限应大于或等于父类方法权限;
* 重写后并不会修改父类原有的方法,只是子类在调用该名称方法时会调用子类重写后的方法; - 重写返回值如果是void或者基本类型,必须完全相同;如果是引用数据类型,可以返回原返回值类型子类型的类型;

(多态)概述:统一类型(当父类)行为的多态(所有抽象方法都是多态的),对象的多态(所有对象都是多态的)
*1.多态前提:重写:根据对象的不同来表现多态,重载根据参数类型的不同来表现多态;
*2.多态又叫做向上造型:父类型的引用指向子类型的对象;
*3.编译看左边:父类类型的对象只能调用到父类的属性和方法
*运行看右边:运行结果看子类的实现,如果子类重写了方法就是重写后的方法;
*4.多态可以让我们不用关心某个对象到底是什么具体类型,就可以将不同的多个子类对象放入同一个父类类型数组中,提高了程序的扩展性和可维护性;
例如: [父类型对象] <变量名> = new [子类类型](参数列表);
1.2.3.1: 多态中的成员使用:
1、成员变量:使用的是父类的
2、成员方法:由于存在重写现象所以使用的是子类的
3、静态成员:随着对象而存在,谁调用的就返回谁的;
类和对象
- 类加载机制

java中所有的类,都需要由类加载器加载到JVM中才能运行。类加载器本身也是一个类,而它的工作就是把class文件从硬盘读取到内存中。在写程序的时候,我们几乎不关心类的加载,因为这都是隐式加载的,除非我们有特殊的用法,像是反射,就需要显示的加载所需要的类。
java类的加载是动态的,它不会一次性将所有类全部加载后在运行,而是保证程序运行的基础类(lang包下的)完全加载到jvm中,至于其他类,则是需要的时候才加载。当然是为了节省内存开销。


类
1、Java语言最基本单位就是类,类似于类型。
2、类是一类事物的抽象。
3、可以理解为模板或者设计图纸,一个.java文件中可以写多个类,但是只能有一个Public修饰的类
通过class关键字来定义类,抽象的规定了这一类事物的特性;
类设计原则:一个类常常就是一个小的功能模块,尽量让其功能单一,术有专攻。将必须外界知道的内容公开public,对外界不需要知道的内容隐藏private。避免一个模块直接操作另一个模块的数据,这样称之为耦合度高,如果我们想替换,换个模块就非常费事。所以设计时我们要遵循高内聚,低耦合的原则。
例如:我们的鼠标,就是非常典型的好产品。只有两个按钮一个滚轮。用户只能操作这么点东西,内部怎么实现的?不知道。例如:滑动滚轮,网页怎么就随之滚动了呢?用户无需知道,只需要滑动滚轮,网页随之上下翻滚就行了。
简单来说:少public,多private。

方法
Java方法是语句的集合,它们在一起执行一个功能。
- 方法优点:
- 使程序变得更简短而清晰。
- 有利于程序维护。
- 可以提高程序开发的效率。
- 提高了代码的重用性。
- 方法的定义
修饰符 返回值 方法名(参数类型 参数名){
方法体
return 返回值; // 当返回值为void时省略
}
public void println(String s){
Console.log(s);
}
//方法调用
System.out.println();
println() 是一个方法。 System 是系统类。 out是System类中的一个属性对象。
内部类

内部类就是一个类的内部 定义的另一个类,外部类我们称为outer,内部类称为inner;内部类都有单独的.class字节码文件;
1.成员内部类:就是在编写成员的位置编写内部类,当成类的成员使用(辅助一个复杂对象,对局部数据或逻辑进行封装);
1.1:可以使用所有四种访问修饰符(public,protected ,private ,default);
1.2:内部类可以有自己的属性和方法;
1.3:当内部类和外部类有成员重名时,内部类中药使用外部类的成员需要<外部类名>.this. <外部类成员名>;
1.4:私有属性内部类和外部类共享;
1.5:在其他类中实例化内部类的语法:
A.Outer.Inner i = new Outer().new Inner();
2.局部内部类:声明在方法里/局部代码块中的内部类,仅限于当前方法使用,跟局部变量一样仅限局部使用,但可通过return将该地址值传递给方法调用者,返回值类型只能指定为父类型。
2.1:不能使用修饰符;
2.2:局部内部类也可以通过<外部类名>.this获得外部类对象;
3.静态内部类:静态内部类就是使用了static关键字修饰的成员内部类,静态内部类与普通类作用相同。(关系紧密的类,可以选择嵌套定义,使用上与普通方法一样)
3.1:使用static修饰外,还可以使用所有的四种修饰符;
3.2:静态内部类不能获得外部类对象的实例属性或方法;
3.3:在其他类中实例化静态内部类的语法:
静态内部类可以直接new:Inner1 i1 = new Inner1();
4.匿名内部类:实际上匿名内部类是局部内部类的特殊形式,这个局部内部内在方法中使用,但是没有名字;匿名内部类的变量只执行一次,就会被堆内存释放;
4.1:必须使用一个类或者接口当做父类;
4.2:匿名内部类定义是在实例化对象后加{},在{}中编写匿名内部类的代码;
4.3:在匿名内部类中使用创建它的方法中的局部变量时要保证这个局部变量的值没有改变过;在jdk1.6之前,匿名内部类只能使用方法中被final修饰的局部变量;
对象
简单来说就是客观存在的事物,java中的对象就是按每个类生成个的个体(常见new),它拥有类的属性和方法。
通过new关键字来创建对象,是具体的个性
对象创建加载执行过程
对象创建加载执行过程:
- 第一次加载A和B类
- 加载父类,为父类静态变量分配内存
- 加载子类,为子类静态变量分配内存
- 执行父类静态变量的赋值运算,和静态初始化块
- 执行子类静态变量的赋值运算,和静态初始化块
- 创建对象
- 创建父类对象,为父类的实例变量分配内存
- 创建子类对象,为子类的实例变量分配内存
- 执行父类实例变量的赋值运算
- 执行父类的构造方法
- 执行子类实例变量的赋值运算
- 新建实例 new Person();第一次时,在“方法区”中保存类信息。在“堆内存”中新分配内存空间给这一个实例的成员变量、局部变量。把对象实例的引用对象压栈,并指向其在堆中分片的内存地址。如果未为引用变量设置对应的值,则默认为null空,不保存任何实例的地址。

对象在内存中的存储
Java把内存分成5大区域,我们重点关注栈和堆。
一般来讲局部变量存在栈中,方法执行完毕内存就被释放
对象(new出来的东西)存在堆中,对象不再被使用时,内存才会被释放
每个堆内存的元素都有地址值
对象中的属性都是有默认值的
- Person p = new Person(); 短短这行代码发生了很多事情
1.把Person.class文件加载进内存
2.在栈内存中,开辟空间,存放变量p
3.在堆内存中,开辟空间,存放Person对象
4.对成员变量进行默认的初始化
5.对成员变量进行显示初始化
6.执行构造方法(如果有构造代码块,就先执行构造代码块再执行构造方法)
7.堆内存完成
8.把堆内存的地址值赋值给变量p ,p就是一个引用变量,引用了Person对象的地址值
构造方法(Constructor)
在new对象时,自动调用,完成对象的创建和对象的初始化;
-
构造方法与类同名,返回值是当前类对象;
-
构造方法可以给成员变量赋值;
-
如果不写构造方法,类默认提供了一个无参的构造方法;
-
当只提供含参构造时,无参构造将不再默认提供;
-
如果需要使用到,必须再添加一个无参构造;
-
当有多个构造方法时,可以在类里方法外用{}包裹一段代码,这段代码就是构造代码块,所有的构造方法在执行前都会先执行构造代码块中的内容;
-
继承后子类的构造代码块中默认第一句就是super(),引用父类的构造方法,如果父类只有有参构造,则会报错。需手动写入super(参数)
-
Constructor不能被继承,因此不能重写,但可以被重载;
每一个类必须有自己的构造函数,负责构造自己这部分的构造,子类不会重写父类的构造函数,但会在自己的构造函数第一行调用父类的构造函数;父类只有有参构造时,会报错。需要在第一行写入代码:super(传入参数);
构造器如何工作?
1.分配对象空间,并将对象成员初始化为0为null,java不允许用户操作一个不定值的对象;
2.执行属性值的显示初始化;
3.如果有构造代码块,先执行构造代码块再执行构造器;
4.将变量关联到堆中的对象上;
this/super关键字
1:this引用当前实例的内存地址,用于区分同名的成员变量与局部变量;this()调用构造方法;例如:this.name/this()
2:super是指当前对象对父类成员的引用,super.属性(调用父类中的属性),super.方法(调用父类中的方法);例如:super.name/super()
相同点:super()与this()都必须在构造函数的第一行调用,否则报错;
区别:
1、 this代表本类对象的引用,super代表父类对象的引用。
2、 this用于区分局部变量和成员变量
3、 super用于区分本类变量和父类变量
4、 this.成员变量 this.成员方法() this(【参数】)代表调用本类内容
5、 super.成员变量 super.成员方法() super(【参数】),代表调用父类内容
6、 this和super不可以同时出现在同一个构造方法里,他们两个只要出现都得放在第一行,同时出现的话,就会报错;
final/static关键字
Final:最终
1.被final修饰的类,不能被继承
2.被final修饰的方法,不能被重写;
3.被final修饰的变量叫常量,不能被修改,必须声明时赋值
常量的定义形式:final 数据类型 常量名=值
Static:共享的数据/工具方法(类名调不用创建对象,方便)
1.静态资源用static关键字实现;静态资源被java保存到方法区中,在类加载时就已经出现在方法区中,只有一份,达到数据共享和节省内存的目的;
2.静态资源属于类,可以直接通过类名.访问;没有隐式this传递;
3.静态资源被所有对象共享(无论谁改了静态成员,任何对象访问的都是被修改后的值);
4.静态资源只能访问静态资源,非静态资源可以访问任何资源;
被static final共同修饰的叫静态常量。(属于类不可修改)
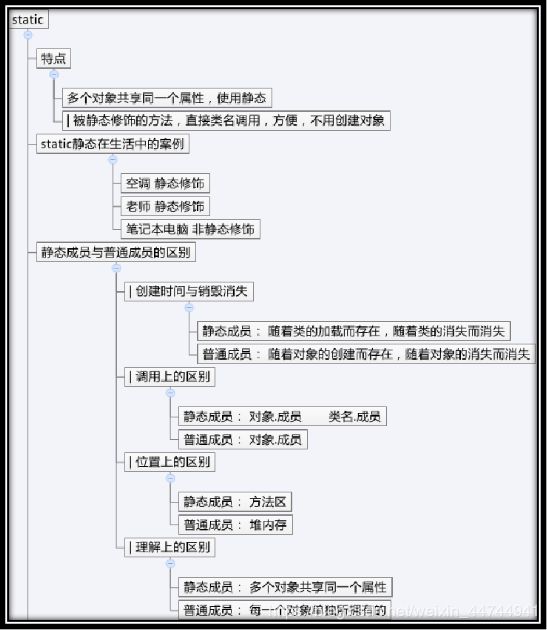
- 必须直接赋初始值,不能修改;
- 使用类名调用;
- 在编译时直接将常量的值替换到需要的位置,提高性能;
常量的命名必须所有字母均大写,使用_分割单词; - 静态变量是先于成员变量存在的
- 静态方法中可以定义静态变量吗?
不可以,静态方法加载到静态区知识存储在静态区,并没有执行,被调用的时候才会到栈内存执行,方法执行都会时候,才会给其中的变量分配内存空间。 - 静态方法里不能访问非静态成员,但非静态成员可以访问静态成员。子类不能重写父类的静态方法,但是子类中可以声明与父类静态方法相同的方法从而将父类的静态方法隐藏。此外,子类也不能把父类的非静态方法重写为静态的。
- 因为静态方法的调用不是通过实例对象进行的,所以在静态方法中没有this指针,不能访问所属类的非静态变量和方法(只能访问方法体内定义的局部变量、自己的参数和静态变量),另外static没有多态说法。
静态变量与成员变量的区别:
在语法定义上的区别:静态变量前要加static关键字,而实例变量前则不加。
在程序运行时的区别:实例变量属于某个对象的属性,必须创建了实例对象,其中的实例变量才会被分配空间,才能使用这个实例变量。静态变量不属于某个实例对象,而是属于类,所以也称为类变量,只要程序加载了类的字节码,不用创建任何实例对象,静态变量就会被分配空间,静态变量就可以被使用了。总之,实例变量必须创建对象后才可以通过这个对象来使用,静态变量则可以直接使用类名来引用。(静态变量是所有对象共有的,某一个对象将它的值改变了,其他对象再去访问,都是改变后的值;而实例变量是每个对象私有的,某一个对象将它的值改变了,不影响其他对象取值的结果,其他对象仍会得到实例变量一开始就被赋予的值)
为什么静态方法无法调用非静态方法呢?
原因很简单,静态方法是类未创建它就创建了,而此时类如果没有创建实例,类的方法是不能调用的。非静态方法都可能不存在,怎么能允许调用呢!
【了解】static很特殊,很有特点,它会在类加载时全部加载并放入内存中,专门有一块地方存放(方法区),和普通变量存放的位置不同(堆)。不论是否要用到都会加载。这样会消耗宝贵的、稀缺的内存资源,所以不要轻易使用static,尽量不使用static。通常都是工具类,反复使用的内容才使用static静态方式处理。
代码块
静态代码块:在类的内部,方法外部用static修饰的一对{},静态代码块只在类被加载时执行一次;一般用来初始化公用的成员属性(音频,视频,图片);
构造代码块:在类的内部,方法外部的代码块,用一对{}包起来,通常用于抽取构造方法中的共性代码,每次调用构造方法前都会调用构造代码块(new对象之前,优先于构 造方法加载(先执行构造代码块,再执行构造方法)
局部代码块:局部代码块是放在方法里的代码块,用一对{}包起来,局部代码块的作用范围就是附近的括号里,调用方法时,先调用执行局部代码块内的内容,再执行方法的内容;
三种代码块的执行顺序:
1.类最先被加载,所以先加载静态资源,静态资源只加载一次;
2创建对象时执行构造代码块,.构造代码块每次创建对象时都会被调用;
3.对象调用方法,每次调用包含局部代码块的方法时,都会执行局部代码块;
异常
- 检查性异常:最具代表的检查性异常是用户错误或问题引起的异常,这是程序员无法预见的。例如要打开一个不存在文件
时,一个异常就发生了,这些异常在编译时不能被简单地忽略。 - 运行时异常: 运行时异常是可能被程序员避免的异常。与检查性异常相反,运行时异常可以在编译时被忽略。
- 错误: 错误不是异常,而是脱离程序员控制的问题。错误在代码中通常被忽略。例如,当栈溢出时,一个错误就发生了,它们在编译也检查不到的。
Throwable - 顶级父类;
– Error:系统级别错误/代码无法处理,恢复困难,比如内存溢出;
– Exception:需要捕捉或者需要程序进行处理的异常,是一种设计或者实现问题,也就说,如果程序正常运行是不会发生的;
- 程序中遇到了异常,通常有两种处理方式:捕获或者向上抛出。
Exception异常的抛出和处理:当出现了异常时,JVM会实例化该异常的实例并将其抛出。
异常的抛出:
使用throw关键字可以将一个异常抛出。通常如下情况下我 们会主动对外抛出异常:
1:程序执行中发现一个满足语法要求,但是不满足业务逻辑要求的情况下可以对外抛出异常告知不应当这样做。(例如:age<0这种不合常理情况)
public void setAge(int age)throws illelageException {
if(age<0||age>100) {
throw new illelageException("年龄不合法!");}
this.age = age;}
2:程序确实出现了异常,但是该异常不应当在当前代码片 段中被解决时可以对外抛出给调用者解决(责任制问题)当一个方法使用throw抛出某个异常时,就要在这个方法声明的同时使用throws声明这个异常的抛 出,以通知调用者处理这个异常。只有抛出RuntimeException及其子类型异常时,编译器不强制要求必须使用throws,其他类型异常则是必须的。
- 当子类型重写父类型的带有异常方法时:
不允许抛出额外异常:与超类方法抛出的异常无继承关系的异常.
不允许抛出大于父类型异常,不允许抛出超类方法抛出异常的父类型异常;
异常处理机制中的try-catch语法:
try(可关闭的资源实例化){
可能抛出异常代码片段
}catch(xxxException e){
e.printStackTrace(); //输出错误堆栈信息,便于调试代码
String message = e.getMessage(); //获取错误消息,一般用于提示给用户
}finally{ 最后执行的代码片段};
- catch块是可以定义多个的,当针对不同的异常我们有不同的处理手段时,我们可以分别捕获这些异常并处理. 但应当有一个好习惯,在最后一个catch中捕获Exception,可以防止因为一个未处理的异常导致程序中断。
- finally块是异常处理机制的最后一块,可以直接跟在 try块之后或者最后一个catch之后。
- finally块可以确保只要代码执行到try当中,无论try 块当中的代码是否抛出异常,finally块中的代码都必定执行,通常我们将释放资源这样的操作放在finally中确保执行,比如IO中关闭流的操作。
- 声明自定义异常 在 Java 中你可以自定义异常。编写自己的异常类时需要记住下面的几点。
所有异常都必须是 Throwable 的子类。
如果希望写一个检查性异常类,则需要继承 Exception 类。
如果你想写一个运行时异常类,那么需要继承 RuntimeException 类。
public Class MyException extends RuntimeException{ }
- JDK7推出时,推出了一个特性:自动关闭AutoCloseable:(即在try后面{}前面在加一对小括号),注意,try后面小括号定义的内容都必须实现了AutoCloseable接口,一般流之类的都实现了这个接口,这个特性是编译器认可的,编译器在编译当前源代码时会将这里定义的内容最终改为在finally中关闭;
try代码块里有return语句,那么finally里的代码什么时候执行?
答:try代码块中的return执行后在没有返回数据时先去执行finally代码块中的代码,然后再返回;所以说finally代码块中的代码在return中间执行,但是return的值会保存,finally块再修改返回值不影响原返回值;
抽象类(abstract) /接口(interface)/注解(@interface)
Abstract:抽象类:
1.抽象类或者抽象方法通过abstract关键字实现;
2.抽象方法没有方法体,使用abstract修饰;
3.有抽象方法的类必须是抽象类,抽象类可以包含普通方法;
4.子类继承抽象类后必须重写所有抽象方法,不然还只能声明为抽象类;
5.多用于多态中,抽象类不可被实例化(可用匿名内部类new);
6.抽象类可以有构造方法,但是是给子类使用的;抽象类可以有变量和常量;
抽象类抽象方法作用:1:作为通用方法,在向上造型时统一调用,2:要求子类必须重写

Abstract方法注意事项:
抽象方法要求子类继承后必须重写。那么,abstract关键字不可以和哪些关键字一起使用呢?以下关键字,在抽象类中。用是可以用的,只是没有意义了。
1、 private:被私有化后,子类无法重写,与abstract相违背。
2、 static:静态的,优先于对象存在。而abstract是对象间的关系,存在加载顺序问题。
3、 final:被final修饰后,无法重写,与abstract相违背。
lambda表达式:

当需要创建匿名内部类时,该类只能包含一个抽象方法,可以使用更简洁的语法创建匿名内部类;
语法:(参数列表)->{方法体}:
2.使用lambda创建匿名内部类时,其实现的接口只能有一个抽象方法,如果只执行一条代码,可以连大括号都省略例如:
Runnable r1 = ()->{
System.out.println("Hello,我是lambda创建的匿名内部类!");};
Runnable r2 = new Runnable() {
public void run() {
System.out.println("Hello,我是普通的匿名内部类!");}};
3.如果可以忽略{},那么方法中若有return关键字也要一并忽略,例如:以下是一个比较器对象:
Comparator<String>c3=(o1,o2)->o1.length()-o2.length();
Interface:(接口)结构设计工具,用来解耦合,隔离实现;
- 1.通过interface关键字定义接口;
- 2.接口都是公开的抽象方法/* public abstract */(新版JDK允许方法默认实现),接口中定义都是公开的静态常量(不写默认加public static final);接口可定义公开内部类,内部接口
- 3.通过implements让子类来实现,可多实现;
- 6.类可以实现多个接口,接口可以继承多个接口;
- 7.接口是对外暴露的规则,是一套开发规范;
- 8.接口提高了程序的功能扩展,降低了耦合性。
- 接口中不能有构造方法/普通方法/普通变量;

接口和抽象类的区别?
1、抽象类和接口都不能直接实例化,如果要实例化,抽象类变量必须指向实现所有抽象方法的子类对象,接口变量必须指向实现所有接口方法的类对象。
2、抽象类要被子类继承,接口要被类实现。
3、接口只能做方法申明,抽象类中可以做方法申明,也可以做方法实现。
4、接口里定义的变量只能是公共的静态的常量,抽象类中的变量是普通变量。
5、抽象类里的抽象方法必须全部被子类所实现,如果子类不能全部实现父类抽象方法,那么该子类只能是抽象类。同样,一个实现接口的时候,如不能全部实现接口方法,那么该类也只能为抽象类。
6、抽象方法只能申明,不能实现,接口是设计的结果 ,抽象类是重构的结果。
7、抽象类里可以没有抽象方法。
8、如果一个类里有抽象方法,那么这个类只能是抽象类
9、抽象方法要被实现,所以不能是静态的,也不能是私有的。
10、接口可继承接口,并可多继承接口,但类只能单根继承。

- 拓展
- 继承的缺点
继承是实现类复用的重要手段,但继承带来了一个最大的坏处:破坏了父类的封装。
我们封装的要求是:类封装它内部的信息和实现细节,只暴露必要的方法给其他类来使用。口号:高内聚,低耦合,后期易维护。对外暴露内容越少,代码安全性也越好,外部根本不知道内部有什么东西,是如何实现的。
但在继承关系中,子类可以直接访问父类的成员变量(内部信息)和方法,从而造成子类和父类严重耦合。同时,子类可以访问父类的成员变量和方法,并可以改变父类方法的实现细节,如通过方法重写覆盖父类的方法实现,从而导致子类可以恶意篡改父类的方法。
相比之下组合方式来实现类的复用则实现更好的封装性。那什么是组合呢?我们赶快来了解一下。 - 组合
组合是 “父类”作为“子类”中的成员变量,同时这个成员变量为private私有的。这样用户只能看到“子类”的内容,不能看到组合对象“父类”的内容(属性和方法)。
不难发现这个设计非常巧妙,“父类”的功能等同于组合类,将自身的方法都提供给“子类”使用,但“子类”又不能去修改覆盖“父类”的方法,只用不改。“父类”的封装性得到保证,“父类”的方法只能使用不能覆盖也防止了恶意篡改。
组合也有缺点,会创建过多的类。但总的来说组合相比继承更具灵活、更安全、低耦合,所以复用代码实现时先考虑组合,再考虑继承。
public class UserServiceImpl implements UserService{
//在这个类之外,不暴露方法,这种方式优于继承,首选,这种方法称为组合
private SqlSession sqlSession = new SqlSessionImpl();
@Override
public User get(Integer id) {
return sqlSession.selectOne("");
}
}
@interface注解为其他开发工具或其他java程序提供代码的额外信息;所有的注解都继承自接口:Annotation
JDK自带注解 元注解 自定义注解(自己定义的注解)
8.3.1 JDK注解(JDK注解的注解,就5个):
@Override标记方法被重写:编译器会检验该方法与父类方法是否符合重写概念
@Deprecated标记就表明这个方法已经过时了,但我就要用,别提示我过期
@SuppressWarnings(“deprecation”) 忽略警告
@SafeVarargs jdk1.7出现,堆污染,不常用
@FunctionallInterface jdk1.8出现,配合函数式编程拉姆达表达式,不常用
8.3.2 元注解 (描述注解的注解,就5个):
@Target 注解用在哪里:类上、方法上、属性上...
@Retention 注解的声明周期:源文件中、class文件中、运行中
@Inherited 允许子注解继承
@Documented 生成javadoc时会包含注解,不常用
@Repeatable注解为可重复类型注解,可以在同一个地方多次使用,不常用
8.3.3 @Target描述注解的使用范围:
ElementType.ANNOTATION_TYPE 应用于注释类型
ElementType.CONSTRUCTOR 应用于构造函数
ElementType.FIELD 应用于字段或属性
ElementType.LOCAL_VARIABLE 应用于局部变量
ElementType.METHOD 应用于方法级
ElementType.PACKAGE 应用于包声明
ElementType.PARAMETER 应用于方法的参数
ElementType.TYPE 应用于类的任何元素
8.3.4 @Retention定义了该注解被保留的时间长短,某些注解仅出现在源代码中,而被编译器丢弃;而另一些却被编译在class文件中;编译在class文件中的注解可能会被虚拟机忽略,而另一些在class被装载时将被读取。(为何要分有没有呢?没有时,反射就拿不到,从而就无法去识别处理。)
SOURCE 在源文件中有效(即源文件.java保留:如@override)
CLASS 在class文件中有效(即class保留)
RUNTIME 在运行时有效(即运行时保留)
@Target(ElementType.METHOD)//该类注解只能在方法上调用
@Retention(RetentionPolicy.RUNTIME)//该注解会保存到运行期还存在
public @interface Test {//创建注解
// 如果没有默认值,使用注解时,就必须赋值(有默认值,可以不赋值)
int id() ;//没有默认值
String title() default “”;//有默认值空字符串
- 特殊的属性名 value:有特殊待遇,单独赋值时,可以不写value=,
可以作为一个有意义属性名的别名 - @Test(“sdfsdfs”)
- @Test(id=5, value=“dfgsdf”)
- @Test(id=5, title=“dfgsdf”)
String value() default “”; //title的别名}
//利用反射调用注解相关方法
public static void launch(Class c) throws Exception{
Object obj = c.newInstance();
Method[] a = c.getMethods();
for (Method m : a) {
if (m.isAnnotationPresent(Test.class)) {//判断方法是否加了test注解
Test t = m.getAnnotation(Test.class);//获取 Test 注解数据
System.out.println("id: "+t.id());
System.out.println("title: " +(t.title().length()!=0?t.title():t.value()));
m.invoke(obj); }
反射(reflect)
反射是一种动态机制,使用它可以在程序运行期间获取一个类的各项信息,调用方法,实例化等。使用反射可以提高代码灵活度,但是换来的是更多的性能开销,所以反射要适度使用,反射可以获取类对象,反射可以获取类的定义信息,反射创建实例,反射调用成员变量和成员方法
- Class类类对象
它的每一个实例用于表示JVM加载的一个类(.class)。并且在JVM内部,每个被加载的类有且只有一个类对象。通过类对象可以得知其表示的类的一切信息(类名,有哪些方法,属性,构造器等。)并且可以快速实例化该类的实例;
Field:代表属性的类
Method:代表方法的类
Constructor:代表构造方法的类
Annotation:代表注解的类
获取类对象的三种方法(通过三种方法获取的对象是同一个,因为JVM中只存在一份.class文件)
Class.forName("day1801.A"):Class类的静态方法,获得class对象
A.class:获得A类的class静态属性对象;
new a1().getClass():object类提供的方法(对象调获得class对象)
3.9.2 获得包名、类名
cls.getPackage().getName():获得包名
cls.getName():获得完整类名(包名+类名)
cls.getSimpleName():获得类名,不包含包名
3.9.3 成员变量定义信息
cls.getFields():获得所有公开的成员变量,包括继承的变量
cls.getDeclaredFields()获得本类定义的成员变量,包括私有(不包括继承的变量)
cls.getField(变量名):获得叫变量名的变量
cls.getDeclaredField(变量名):获得包括私有(不包含继承)的变量
3.9.4 反射调用成员变量
Field field = cls.getDeclaredField(变量名);
使私有成员允许访问
field.setAccessible(true);
反射给变量赋值(为指定实例的变量赋值,静态变量,第一参数给 null)
field.set(实例, 值);
反射访问变量的值(访问指定实例的变量的值,静态变量,第一参数给 null)
Object v = field.get(实例);
3.9.5 构造方法定义信息
Cls.getConstructors():获得所有公开的构造方法
Cls.getDeclaredConstructors():获得所有构造方法,包括私有
Cls.getConstructor(参数类型列表):获得参数类型列表的构造方法
getDeclaredConstructor(int.class, String.class):int,String参数构造
新建实例时,执行无参构造
Object obj = Cls..newInstance();
新建实例时,执行有参构造:需要传入参数的class对象
Constructor cons = Cls.getConstructor(int.class, String.class);
新建实例,并执行该构造方法
Object obj = cons.newInstance(6, "abc");
3.9.6 反射获得方法定义信息
Cls.getMethods():获得所有可见的方法,包括继承的方法
Cls.getDeclaredMethods():获得本类定义的方法,包括私有(不包括继承的方法)
Cls.getMethod(方法名,参数类型列表)
Cls.getDeclaredMethod(方法名, int.class, String.class)
3.9.7 反射调用成员方法
Method method = cls.getDeclaredMethod(方法名, 参数类型列表);
使私有方法允许被调用
method.setAccessible(true)
反射调用方法,让指定的实例来执行该方法
Object returnValue = method.invoke(实例, 参数数据)
for (String s : list) {
String[] a = s.split(";");//拆分字符串
Class<?> c = Class.forName(a[0]);//获取“类对象”
Object obj = c.newInstance();//新建实例执行无参构造
Method m = c.getMethod(a[1]);//获取方法
m.invoke(obj);//反射调用该方法}
设计模式
设计模式六大原则
开闭原则(Open Close Principle)
开闭原则的意思是:对扩展开放,对修改关闭。在程序需要进行拓展的时候,不能去修改原有的代码,实现一个热插拔的效果。简言之,是为了使程序的扩展性好,易于维护和升级。想要达到这样的效果,我们经常需要使用接口和抽象类。
例:
注:当软件需要修改时应尽量通过扩展的方式来实现,并不是说一定不能通过修改已有的代码来实现。具体是否使用应该由当前项目具体情况具体分析
里氏代换原则/里氏替换原则(Liskov Substitution Principle)
里氏代换原则是面向对象设计的基本原则之一。 里氏代换原则中说,任何基类可以出现的地方,子类一定可以出现。LSP 是继承复用的基石,只有当派生类可以替换掉基类,且软件单位的功能不受到影响时,基类才能真正被复用,而派生类也能够在基类的基础上增加新的行为。里氏代换原则是对开闭原则的补充。实现开闭原则的关键步骤就是抽象化,而基类与子类的继承关系就是抽象化的具体实现,所以里氏代换原则是对实现抽象化的具体步骤的规范。
依赖倒转原则/依赖倒置原则(Dependence Inversion Principle)
这个原则是开闭原则的基础,具体内容:程序要依赖于抽象接口,不要依赖于具体实现。简单的说就是要求对抽象进行编程,不要对实现进行编程,这样就降低了客户与实现模块间的耦合。
接口隔离原则(Interface Segregation Principle)
这个原则的意思是:客户端不应该依赖它不需要的接口;一个类对另一个类的依赖应该建立在最小的接口上。它还有另外一个意思是:降低类之间的耦合度。由此可见,其实设计模式就是从大型软件架构出发、便于升级和维护的软件设计思想,它强调降低依赖,降低耦合。
迪米特法则(Demeter Principle)
又叫作最少知识原则(Least Knowledge Principle 简写LKP),就是说一个对象应当对其他对象有尽可能少的了解,不和陌生人说话。英文简写为: LoD.
尽量降低一个类的访问权限。
合成复用原则(Composite Reuse Principle)
合成复用原则是指:尽量使用合成/聚合的方式,而不是使用继承。
- 设计模式(Design Pattern)是解决特点问题特定结构的代码实现,这些解决方案是众多软件开发人员经过相当长的一段时间的实践和错误总结出来的,它是处理指定问题的最佳实践。设计模式是软件开发中最难的,即使数十年的老程序员也都说不清其来龙去脉,一旦掌握受益无穷。它不仅是具体的代码实现,更是编程思想精髓的体现。需要不断反复研读,反复使用,慢慢消化其博大精深。
23种设计模式

创建型:单例、抽象工厂、建造者、工厂、原型
结构型:适配器、桥接、装饰、组合、外观、享元、代理
行为型:模板方法、命令、迭代器、观察者、中介者、备忘录、解释器、状态、策略、责任链、访问者
- 单例模式:同一类对象在内存中只有一个,优势:节约系统内存空间,控制资源的使用
//饿单:不管用不用都创建,不用也占用空间
public class Singleton1 {
//私有构造方法,外部无法访问
private Singleton1(){}
//创建私有静态对象
private static Singleton1 uniqueInstance = new Singleton1();
//定义公有静态方法访问
public static Singleton1 getInstance() {
return uniqueInstance;
}
}
//懒单:用时再创建对象,懒汉式非线程安全,多线程高并发时会出问题
//两次判断
//加锁 synchronized,
//静态变量使用volatile,JVM优化未创建完成会提前返回对象,为了追求性能,但就会造成风险,如nullpoint异常。加上volatile则JVM在写没有完成时不许读。
双重检查锁模式解决了单例、性能、线程安全问题,但是这种写法同样存在问题:在多线程的情况下,可能会出现空指针问题,出现问题的原因是JVM在实例化对象的时候会进行优化和指令重排序操作。
要解决双重检查锁模式带来空指针异常的问题,只需要使用volatile关键字,volatile关键字严格遵循happens-before原则,即:在读操作前,写操作必须全部完成。
public class Singleton3 {
private volatile static Singleton3 uniqueInstance = null;
private Singleton3() {}
public static Singleton3 getInstance() {
if(uniqueInstance == null) {
synchronized (Singleton3.class) {
if(uniqueInstance == null) {
uniqueInstance = new Singleton3();
}
}
}
return uniqueInstance;
}
- 装饰模式:利用一个统一的父类或者接口,将一个子类对象作为参数来构造另一个子类对象,对其中的方法做改变或者增强
- 观察者模式:将一个对象作为观察目标,当观察目标发生改变的时候,观察者在检测到改变信号之后采取响应的行为应对变化的过程
- 模板设计模式:改造代码形成模板,减少代码量
public abstract class ExecuteTime {//模板类
//执行程序耗时
public final long execute() {
long start = System.currentTimeMillis();
runCode();
long end = System.currentTimeMillis();
return (end-start);
}
//所要执行的代码放入其中
public abstract void runCode();
}
public class TestFileList extends ExecuteTime{//实现类
public static void main(String[] args) throws Exception {
TestFileList tf = new TestFileList();
long l = tf.execute();
System.out.println("耗时:"+l+"毫秒");
}
public static List<String> getFilename(String dir, List<String> fileList){
File file = new File(dir);
File[] files = file.listFiles();
for(File f : files) {
if(f.isDirectory()) {
getFilename(f.getAbsolutePath(), fileList);
}else {
fileList.add(f.getAbsolutePath());
}
}
return fileList;
}
@Override
public void runCode() {
List<String> fileList = new ArrayList<String>();
String dir = "D:\\java\\ws\\1908\\javabase\\src\\day07";
TestFileList.getFilename(dir, fileList);
for (String filename : fileList) {
System.out.println(filename);
}
}
}
JVM内存
![]()
HotSpot JVM虚拟机架构:


- 方法区:静态常量池、静态区,存储静态常量、常量、运行时常量池、存储类信息(.class文件),存储字面量,在方法去中只加载一次,一旦加载就不会移除(慎用),存储的是本身恒定不变的量"acx",当方法区
- 栈(stack)内存:基本数据类型分配在栈内存中,栈内存空间不需要开发者回收,系统会自动回收。栈空间占整个内存空间的比例较小。



- 堆:堆(heap)内存:引用数据类型分配在堆内存,堆内存一定要开发者通过new关键字来申请,开发者申请的内存使用完成后一定要回收。Jvm中有专门的垃圾回收机制(GC)回收使用完的堆内存。堆空间占整个内存空间的比例较大。一个对象的成员变量如果没有指定初始值,那么JVM会为他们分批额一个默认的初始值(boolean-false,引用变量null)

1)先将声明压栈arr
2)在堆中分配内存空间,位置假设为0x88开始
3)申请三个连续的内存地址,数组的空间是连续的,并设置各个元素初始值为0
4)然后在执行{1,2,3}进行数组的初始化,分别替换每个空间中的值
5)最后把栈中指向引用的地址0x88



- 对于基本类型来说,传值是传的实际的数据,对于引用类型来说,传值传的是地址

堆: 1.1:存储new出来的对象(包括实例对象)
1.2:垃圾:没有任何引用所指向的对象,垃圾回收器(GC)不定时到内存中清理垃圾,回收过程是透明的,不一定一发现垃圾就立刻回收,调用System.gc()可以建议虚拟一尽快调用GC回收;GC是一个单独的低优先级的线程运行,不可预知的情况下对内存中已经死亡的或长时间没有使用的对象进行清除和回收;
1.3:内存泄漏:。不再使用的对象因为存在引用,垃圾回收器无法回收,积累多了就会发生内存泄漏,有时会造成内存不足或系统崩溃;建议,对象不在使用时及时将引用设置为null;
1.4:实例变量的生命周期:在创建对象时存储在堆中,对象被回收时一并被回收;
栈:基本数据类型分配在栈内存中,栈内存空间不需要开发者回收,系统会自动回收。栈空间占整个内存空间的比例较小。
2.1:存储正在调用的方法中的所有局部变量(包括形参);
2.2:调用方法时,会在栈中为该方法分配一块对应的栈帧,栈帧中存储方法中的局部变量(包括参数)
2.3:方法调用结束时,栈帧被清除,局部变量一并被清除
2.4:局部变量的生命周期:方法被调用时存储在栈中,方法结束时与栈帧一并被清除;
方法区:
3.1:存储.class字节码文件(包括静态变量/方法)
3.2: 方法只有一份,通过this来区分具体的调用对象 - 说明什么情况下会产生堆溢出?栈溢出?常量池溢出?方法区溢出?
- 堆溢出:表示程序需要的内存超过了虚拟机分配的最大内存(可以通过配置中提高-Xmx来调节)
- 栈溢出:如果方法运行时需要的栈的深度超过了虚拟机所允许的最大的栈的深度,那么会出现栈内存溢出

- 常量池溢出:对象大于新生代剩余内存的时候,将直接放入老年代,老年代剩余内存还是无法放下的时候,触发垃圾回收,收集后还是不能放下就会抛出内存溢出异常了。
- 方法区溢出:持久代溢出有可能是运行时常量池溢出,也有可能是方法中保存的class对象没有被及时回收或者class信息占用的内存超过了我们的配置(热部署、常量过多、静态代理(CGLIB、Spring))
1热部署:用于版本的更新或软件的升级维护时候(每次热部署后,原来的class没有被卸掉。
2常量过多:通过-XX:PermSize和-XX:MaxPermSize来设置,应用程序本身比较大,涉及的类比较多,但是我们分配给持有代的内存比较小的时候。
3静态代理:CGLIB,产生代理类(放在方法区),从类的本质改变,当代理类过多,会加载到方法区,会生产方法区溢出的问题。
栈中数据的特点是用完就被释放,怎么知道用完呢?一般我们存放的都是局部变量,当方法或者代码块或者for循环等结束时,这些局部变量就被抛弃,就没有用了,就会被释放资源。所以它不需要GC。
那GC管谁呢?它管堆。堆中的数据为引用类型。如上面的代码,先在栈中分配user实例,然后在堆中分配内存空间,存储初始值,然后把地址值给栈中的user。这里注意,堆中的数据和栈中的数据可不同,它们不会随着程序的结束而释放资源。那就意味着内存空间未被释放。那内存一直申请,最终不就没有空间了。JVM是这样处理的,开始是可以随意申请空间,但当内存开始吃紧,达到警戒线(98%),那就开始执行GC来回收对象。
那GC又是怎么知道回收哪些对象呢?哪些对象没有了引用,哪些对象还在使用?使用的你要回收,不就乱套了。
通常有两种情况来设置对象是否被引用。
1)对象超过作用域后,JVM标记其没有引用,类似上面的图,栈中的user已经消失,JVM就会在一张表中记录0x88已经没人引用了。
2)我们也可以在方法中主动设置对象为user = null; 这样JVM也在表中标识没人引用了。
这样在执行GC时,其就可以收集这些未被引用的对象,从而释放内存空间,后续的程序就可以申请空间,顺畅执行。
- 垃圾回收期的基本原理:
对于GC来说,当程序员创建对象时,GC就开始监控这个对象的地址、大小以及使用情况。通常,GC采用有向图的方式记录和管理堆中的所有对象。通过这种方式确定哪些对象是 ‘可达的’,哪些对象是“不可达的”。当GC确定一些对象为“不可达”时,GC就有责任回收这些内存空间。需要注意:垃圾回收器不能马上回收内存。程序员可以手动执行System.gc(),通知GC运行,但是java语言规范不保证GC一定会执行。


- 字符串常量池位置:
jdk1.7之前HotSpot的字符串常量池是在方法区中(永久代不回收,会造成内存泄漏)。
jdk1.7将字符串常量池从永久代移除,在Java 堆(Heap)中开辟了一块区域存放运行时常量池。
jdk1.8,已经彻底没有了永久代,将方法区直接放在一个与堆不相连的本地内存区域,这个区域被叫做元空间。

public static void main(String[] args) {
//创建2个对象,字符串池中不存在,创建字符串"abc",然后将字符串"abc"对象的地址给s1对象
String s1 = "abc";
//创建1个对象,字符串池中判断依据存在"abc",不再创建,直接把"abc"对象的地址给s2对象
String s2 = "abc";
//既然两个对象地址一样,当然结果就为true
System.out.println("s1 == s2\t\t"+(s1 == s2));
//值相同
System.out.println("s1.equals(s2)\t"+s1.equals(s2));
//创建2个对象,new String开辟地址空间,指向常量池"abc"地址,s3栈中
String s3 = new String("abc");
//创建2个对象,new String开辟地址空间,指向常量池"abc"地址,s4栈中
String s4 = new String ("abc");
System.out.println("s3 == s4\t\t"+(s3 == s4));
//值相同
System.out.println("s3.equals(s4)\t"+s3.equals(s4));
}
}
- eclipse中修改参数


正则表达式:regular Expression
正则表达式本身就是一个字符串,是用于规定字符出现次序的规则(正确的字符串规则),正在表达式几乎被所有编程语言接受,用于检验字符串规则,编译语言都提供了API支持;
特殊字符:需要转义字符匹配
- java对正则的支持:
字符串.matches(正则):返回boolean值;
字符串.split(正则):拆分成数组;
字符串.contains(正则):返回boolean值;
字符串.replaceAll(String regex,String replacement):替换符合正则的内容为,过滤敏感字;
调试打桩
Debug调试
添加断点:在代码行左侧双击添加断点;
- 掌握4个键:
1)F5:单步调试(会进入到方法中)
2)F6:逐过程调试(不会进入到方法中)
3)F7:结束方法的调试
4)F8:直接进入下一个断点,后面无断点则结束调试 - 会看两个东西:
1)会看变量;
2)会添加监视(选中表达式,右键Watch);


- 小技巧
- Debug界面布局重置方式
Window–>Perspection–>Reset perspection;或者debug页面点小虫子-右键-reset; - 导出doc文档步骤:
–>Export–>搜索javadoc–>点击下一步即可 - eclipse清除缓存步骤:
project–>clean–>可全选/可以选中某个要清除的项目–>clean即可; - 添加jar文件方法:–build path–add external …
打桩
控制台输出对象
引用关系
强引用:默认的对象都是强引用,如:String s = “tony”; 由于对象被其他对象所调用,没设置为null,GC干不掉。
弱引用:弱引用生命周期很短,不论当前内存是否充足,都只能存活到下一次垃圾收集之前。也就是说GC时就会被干掉。

字符编码/解码
eclipse创建文件格式为ISO-8859-1,和默认我们网页的字符集是一样的,但它是英文的字符集,无法正确的展示中文?
例如如果里面有中文注释,会展示下面的样子
#\u6570\u636E\u5E93\u94FE\u63A5\u914D\u7F6E
怎么办呢?很简单,修改文件的字符集即可,选择文件,右键选择属性,弹出菜单选择UTF-8即可;
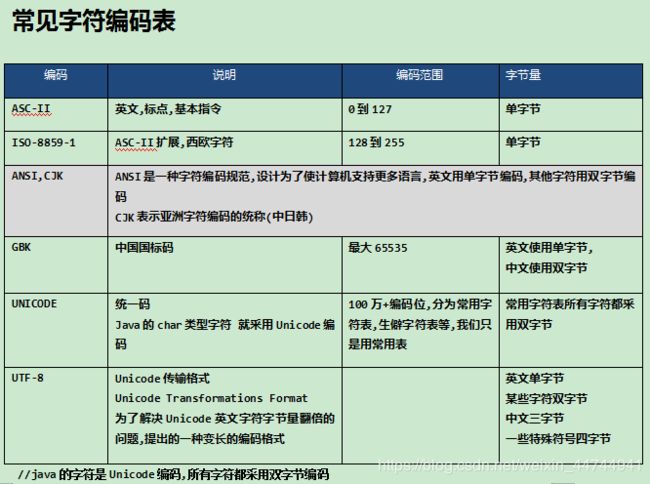
字符编码是什么?
我们知道,计算机数据只能是二进制的,数值类型的数据转换成二进制很简单,我们已经了解了,但字符类型如何转换成二进制呢?这就需要使用字符编码!
在编码表中,每个字符都有对应的编码,编码是整数,最终在计算机中存储的是字符的编码,而不是字符本身(因为计算机数据都是二进制数值,所以字符本身是无法存储的)。
当我们存储字符’A’时,其实是通过编码表找到’A’字符对应的编码,然后把编码存储在计算机中。即存储的是65。
当我们读取字符时,其实读取的也是字符的编码,然后使用编码再去编码表中查找对应的字符显示。

常见的字符编码
ASCII
在所有字符集中,最知名的可能要数被称为ASCII的7位字符集了。它是美国标准信息交换代码(American Standard Code for Information Interchange)的缩写, 为美国英语通信所设计。它由128个字符组成,包括大小写字母、数字0-9、标点符号、非打印字符(换行符、制表符等4个)以及控制字符(退格、响铃等)组成。
ISO-8859-1
由于ASCII是针对英语设计的,当处理带有音调标号(形如汉语的拼音)的欧洲文字时就会出现问题。因此,创建出了一些包括255个字符的由ASCII扩展的字符集。有一种8位字符集是ISO 8859-1Latin 1,也简称为ISO Latin-1。它把位于128-255之间的字符用于拉丁字母表中特殊语言字符的编码,也因此而得名。
GB2312
GB2312是一个简体中文字符集的中国国家标准,全称为《信息交换用汉字编码字符集•基本集》,又称为GB0,由中国国家标准总局发布,1981年5月1日实施。GB2312编码通行于中国大陆;新加坡等地也采用此编码。
GB2312标准共收录6763个汉字,其中一级汉字3755个,二级汉字3008个;同时,GB 2312收录了包括拉丁字母、希腊字母、日文平假名及片假名字母、俄语西里尔字母在内的682个全角字符。
对于人名、古汉语等方面出现的罕用字,GB2312不能完全包括,这导致了后来GBK及GB18030汉字字符集的出现。
GB2312兼容ASCII码,这部分还是每个字符占1个字节。每个汉字字符占2个字节。GB2312是中国自己的字符集,而其他国家也都有自己的字符集!!!
Unicode
Unicode(统一码、万国码、单一码)是一种在计算机上使用的字符编码。它为每种语言中的每个字符设定了统一并且唯一的编码,以满足跨语言、跨平台进行文本转换、处理的要求。它通过增加一个高字节(2个字节)对ISO Latin-1字符集进行扩展,当这些高字节位为0时,低字节就是ISO Latin-1字符。UNICODE支持欧洲、非洲、中东、亚洲(包括统一标准的东亚象形汉字和韩国象形文字)。但是,UNICODE并没有提供对诸如Braille, Cherokee, Ethiopic, Khmer, Mongolian, Hmong, Tai Lu, Tai Mau文字的支持。同时它也不支持如Ahom, Akkadian, Aramaic, Babylonian Cuneiform, Balti, Brahmi, Etruscan, Hittite, Javanese, Numidian, Old Persian Cuneiform, Syrian之类的古老文字。Unicode支持ISO Latin-1(ISO-8859-1),而Latin-1包含了ASCII编码表。
UTF-8
事实证明,对可以用ASCII表示的字符使用UNICODE并不高效,因为UNICODE比ASCII占用大一倍的空间,而对ASCII来说高字节的0对他毫无用处。为了解决这个问题,就出现了一些中间格式的字符集,他们被称为通用转换格式,即UTF(Universal Transformation Format)。目前存在的UTF格式有:UTF-7, UTF-7.5, UTF-8, UTF-16, 以及 UTF-32。
UTF-8只是Unicode编码的一种转换方式,这时因为Unicode问题占用两个字节的空间,而且最为常用的ASCII编码部分只需要一个字节就可以了,所以才会出现通用转换格式(UTF)。
UTF-8对不同范围的字符使用不同长度的编码,ASCII编码部分与ASCII一样,都是1个字节。而汉字部分都是3个字节。
Unicode转换到UTF-8规则如下:
1.如果Unicode编码的16位二进制数的前9位是0, 则UTF-8编码用一个字节来表示,这个字节的首位是0,剩下的7位与原二进制数据的后7位相同。例如:
Unicode编码:\u0061 = 00000000 01100001
UTF-8编码: 01100001 = 0x61
2.如果Unicode编码的16位二进制数的头5位是0,则UTF-8编码用2个字节来表示,首字节用110开头,后面的5位与原二进制数据去掉前5个零后的最高5位相同;第二个字节以10开头,后面的6位与原二进制数据的低6位数据相同。例如:
Unicode编码: \u00A9 = 00000000 10101001
UTF-8编码: 11000010 10101001 = 0xC2 0xA9
3.如果不符合上述两个规则,则用3个字节表示。第一个字节以1110开头,后四位为原二进制数据的高四位,第二个字节以10开头,后六位为原二进制数据的中间6位,第三个字节以10开头,后6位为原二进制数据的低6位。例如:
Unicode编码: \u4E2D = 01001110 00101101
UTF-8编码: 11100100 10111000 10101101 = 0xE4 0xB8 0xAD
把Unicode为 0101-1101 0001-0100 (5D14)
转换成UTF-8后为: 1110-0101 1011-0100 1001-0100 (E5B494)
汉字“崔”的编码:
GBK: 0xB4DE
Unicode: 0x5D14
UTF-8: 0xE5B494
- 获取字符串中所有字符的编码
String类的getBytes(String charName)方法可以用来获取当前字符串的据的字符的编码,返回值为字节数组。
byte[] getBytes():返回GBK编码的字节数组;
byte[] getBytes(String charsetName):返回指定编码的字节数组。该方法声明了UnsupportedEncodingException异常,该异常是IOException的子类,当Java不支持指定的编码时会抛出这个异常。
byte[] b1 = “崔”.getBytes();// [-76, -34]
byte[] b1 = “崔”.getBytes(“GBK”);// [-76, -34]
byte[] b2 = “崔”.getBytes(“UTF-8”);// [-27, -76, -108]
byte[] b3 = “崔”.getBytes(“Unicode”);// [-2, -1, 93, 20],-2和-1是没有意义的。
虽然上面使用的都是字符串“崔”,但获取的编码结果是不同的。这时因为Java使用相同的字符去查找不同的编码表得到的结果。
字符串类与字符编码
在Java中,字符都是使用Unicode编码(其实是UTF-16的一种方式),每个字符都占两个字节。而我们使用的OS都是使用GBK编码(当然,这需要你安装中文操作系统),也就是说文本文件中默认使用的都是GBK编码。
现在我们有一个字节数组,它表示的是GBK编码的汉字“崔”,例如:
byte[] buff = {-76, -34};
现在我们要把它转换成字符串,这需要使用String类的构造器:
String s = new String(buff, "GBK");
这个构造器需要指定字节数组,以及这个字节数组使用的编码表。其实,如果你不指定编码表,String类的构造器也会使用默认的编码表来把字节数组转换成字符串的。默认的编码表就是系统默认编码表,对中文操作系统来说就是GBK。
new String(buff, “GBK”)的意思是:拿着buff这个编码,去查找”GBK”编码表,找到我们想要的字符,构成一个字符串。
byte[] buff = {-76, -34};
String s = new String(buff);
System.out.println(s);
上面代码打印的还是汉字“崔”。但如果你使用其他的编码表,例如使用UTF-8,那么一定会出现乱码。因为你的字节数组本身是对应GBK编码表的,但非要告诉String构造器去对照UTF-8编码表,那查出来的字符当前是错误的了!
乱码:编码和解码使用了不同或者不兼容的字符集造成的;
如何将乱码的数据翻译成正确的数据:用解码时的字符集去转换乱码成二进制数据,用编码时字符集再去解析此段二进制数据;
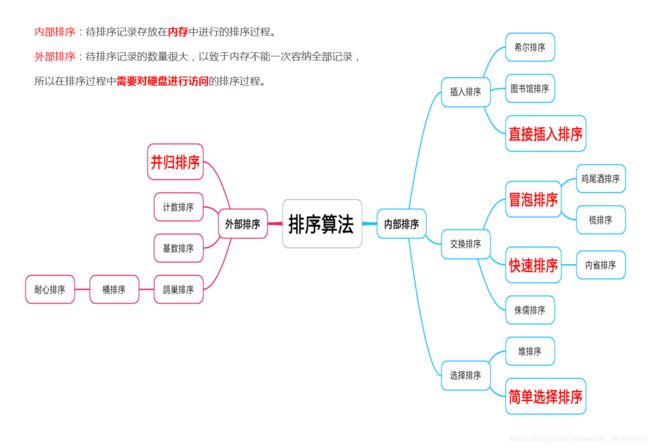
数据结构
概括:用来存放一组数据的工具
据结构是计算机存储、组织数据的方式,指相互之间存在一种或多种特定关系的数据元素的集合。精心选择的数据结构可以带来更高的运行或者存储效率。[算法+数据结构=程序]
- 数据结构的基本功能:
如何插入一条新的数据 如何寻找某一特定的数据
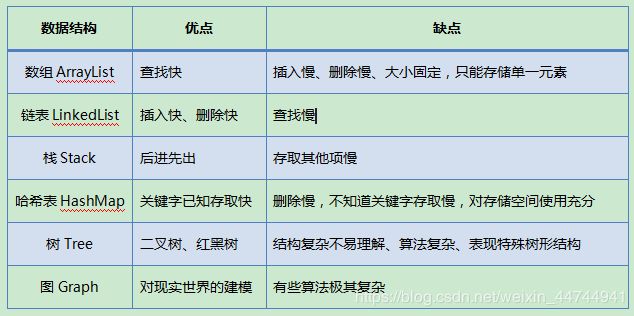
如何删除某一数据 如何迭代获取集合的所有数据 - 常用的数据结构有:
数组、链表、栈、队列、散列表、树、图。
树和图很少使用,晦涩难懂,同时java也没有提供直接的代码实现,初学者暂时不用触碰; - 数组的缺点:
长度固定
访问方式单一,下标
插入数据,删除数据,操作繁琐
插入数据,要向后移动数据
删除数据,要向前移动数据

集合的继承结构:
Collection 接口
|- List 接口
|- ArrayList
|- LinkedList
|- Set 接口
|- HashSet
|- TreeSet
Map 接口
|- HashMap
|- TreeMap
|- HashTable
|- Properties
Iterator 接口
Collections 工具类
- ArrayList:基于数组,默认初始容量为10,每次扩容都是在上次的基础上添加上次容量的一半。内存空间是连续的,是线程不安全的,增删较慢,查询比较块。
- LinkedList:是基于链表的,内存空间不连续,是线程不安全的,增删较快,不便于查询(用于实现栈和队列操作)
LinkedList 是一个继承于AbstractSequentialList的双向链表。它也可以被当作堆栈、队列或双向队列进行操作。该类调用ListIterator实现了元素的增删改查,在LinkedList被重写。
LinkedList 实现 List 接口,能对它进行队列操作。
LinkedList 实现 Deque 接口,即能将LinkedList当作双向队列使用。
LinkedList 实现了Cloneable 接口,即覆盖了函数clone(),能克隆。
LinkedList 实现Java.io.Serializable接口,这意味着LinkedList支持序列化,能通过序列化去网络传输。

- Vector:向量,最早期的集合。基于数组的,初始容量为10,每次扩容一倍,是线程安全的,内存空间是连续的
- stack:栈,遵循先进先出原则,最早放入栈内元素为栈底元素,最早放入的元素为栈顶元素。(stack类继承于vector,LinkedList)
- queue:队列,遵循先进先出原则。
- Set:元素不可重复集,set在存储元素的时候是基于对象的哈希吗存储的。set中元素存储是无序的,但是元素之间可能有序(当放入重复元素的时候,会在底层调用该对象的hashCode方法和已有的对象进行对比,一旦哈希吗一致,认为是同一个对象,覆盖原来的元素)
- Hashset:底层是HashMap的实例,是线程不安全的集合。默认初始容量是16,加载银子是0.75f(75%*16=12),单次扩容一倍。

- Collections:操作集合的工具类(不允许创建对象,提供了很多静态的方法)
- Map:Key、value映射,其中元素以键值对形式存储,不保证元素的存入顺序(键唯一,值可以重复)
- HashMap:允许一个键为null,允许多个值为null,默认初始容量是16,加载因子是0.75f,每次扩容一倍。是一个异步式线程不安全的映射。(key.hashCode计算下标)
- HashTable:键和值均不可为null,默认初始容量是11,加载因子是0.75f,是一个同步式线程安全的映射。
- ConcurrentHashMap:异步式线程安全的映射。

- Iterator:迭代器,用于迭代遍历集合。利用指针的指向位置来迭代 遍历元素。
Iterator it = list.iterator();
while(it.hasNext()){//判断是否有下一个元素
Object o = it.next();//判断有,获得下一个元素
if(o instanceof String){
it.remove();//移除当前迭代元素,会改变原集合
}
}
- 枚举(抛弃)
Enumeration接口中定义了一些方法,通过这些方法可以枚举(一次获得一个)对象集合中的元素。
枚举(Enumeration)接口虽然它本身不属于数据结构,但它在其他数据结构的范畴里应用很广。 枚举(The Enumeration)接口定义了一种从数据结构中取回连续元素的方式
//枚举运用一
import java.util.Vector;
import java.util.Enumeration;
public class EnumerationTester {
public static void main(String args[]) {
Enumeration<String> days;
Vector<String> dayNames = new Vector<String>();
dayNames.add("Sunday");
dayNames.add("Monday");
dayNames.add("Tuesday");
dayNames.add("Wednesday");
dayNames.add("Thursday");
dayNames.add("Friday");
dayNames.add("Saturday");
days = dayNames.elements();
while (days.hasMoreElements()){
System.out.println(days.nextElement());
}
}
}
//枚举运用二
package javase.base.enumc;
public enum Season {// season.Spring(简单优美)
SPRING, SUMMER, AUTUMN, WINTER
}
算法
算法的复杂性体运行该算法时的计算机所需资源的多少上,计算机资源最重要的是时间和空间(即寄存器)资源,因此复杂度分为时间和空间复杂度。
- 时间复杂度
时间复杂度是指执行算法所需要的计算工作量; - 空间复杂度
空间复杂度是指执行这个算法所需要的内存空间。 - 大O
大O描述的是算法的运行时间和输入数据之间的关系。





- 碰撞算法

知识一眼穿
数据类型
基本类型
引用类型
八种基本类型
byte 1 short 2 int 4 long 8
float 4 double 8
char 2
boolean 1
运算规则(5条)
3/2 得 1
byte,short,char运算时先变成int
byte a = 2
byte b = 2
byte c = a+b//错
整数运算溢出
Integer.MAX_VALUE+1 = Integ.min_VALUE;
浮点数运算不精确
2-1.9 得 0.10000000000009
4.35*100 得 434.99999999999999994
浮点数特殊值
Infinity(因飞尼提) - 无穷大
3.14/0
NaN - Not a Number
0.0/5
Math.sqrt(-5)
运算符
+-*/%
=‘转义’= != > >= < <=
&& || !
& | ^ ~
>> >>> <<
++, --
1 ? 2 : 3
() 强转符
=
+=, -=, /=....
instanceof
运行期识别,对真实类型及其父类型判断,都得到true
流程控制
if-else if-else
switch-case-default
switch只能判断:
byte,short,char,int
enum 枚举
jdk 1.7 String
for
while
do-while
break
continue
循环命名
在内层循环中控制外层循环,需要对外层循环命名
outer://外层命名
for() {
for() {
break outer;//跳出两次循环
continue outer;
}}
数组
创建
int[] a = new int[5];
int[] a = {5,3,67,8,4,1};
a = new int[]{5,9,6};
长度属性
a.length
数组一旦创建长度不可变
数组长度可以是0
最大下标 a.length-1
Arrays.toString(),Arrays.copyOf,Arrays.sort(),
Arrays.binarySearch(),System.arraycopy();
二维数组
数组中存放数组
什么是面向对象
封装,继承,多态
封装
类, 模板
对象, 实例
引用, 保存实例的内存地址, 遥控器
构造方法
新建实例时执行
不定义,有默认
构造方法可以重载
this
this.xxxx
this是特殊引用,引用当前实例的地址
this(...)
构造方法之间调用
必须是首行代码
方法重载 Overload
同名不同参
private
隐藏,方便维护修改,不影响其他代码
继承
作用: 代码重用,复用
单继承
子类的实例
先创建父类实例
再创建子类实例
两个实例绑定,整体作为一个实例
调用成员时,先找子类再找父类
方法重写 Override
继承的方法,在子类中重新定义重新编写
super
super.xxxx()
重写时,调用父类中同一个方法的代码
super(...)
调用父类的构造方法
默认 super()
手动 super(参数)
必须是首行代码
多态
作用: 一致的类型
所有子类型实例,都可以被当做一致的父类型来处理
向上转型,向下转型
instanceof
运行期类型识别
对真实类型及其父类型判断,都得到true;
抽象类
半成品,没有完成的类
抽象方法的作用:
作为通用方法在父类中定义
要求子类必须实现
final
常量,不可变
方法,不能重写
类,不能继承
static
静态属于类,而不属于实例
使用场景:
共享的数据
工具方法
Math.sqrt()
Integer.parseInt()
String.valueOf()
静态初始化块
class A {
static {
类加载时,只执行一次
}}
访问控制符
public, protected, [default], private
尽量使用小范围, 便于维护修改
接口
作用: 结构设计工具,用来解耦合,隔离实现
极端的抽象类
接口中只能定义:
公开的常量
公开的抽象方法
公开的内部类、内部接口
interface 代替 class
implements 代替 extends
类可以实现多个接口
接口之间继承
interface A extends X,Y,Z {
}
基础API
API - Application Programming Interface
应用编程接口,一切可以调用的东西
Object
toString() 默认格式"类型@地址"
equals(Object) 比较是否相等,默认==比地址
hashCode() 获得一个对象的哈希值
wait()
notify()
notifyAll()
String
封装 char[] 数组
常量池
不可变
加号连接效率低
String s1 = "aaa"
String s2 = "bbb"
String s3 = "ccc"
String s4 = s1+s2+s3
sb = new StringBuilder("aa");
sb.append("bb");
s = sb.toString();
String s4 = "aaa"+"bbb"+"ccc"
编译优化: String s4 = "aaabbbccc"
StringBuilder/StringBuffer
用来代替字符串,做高效率字符串连接运算
append()
内部char[]数组默认初始容量 16
翻倍增长 +2
正则表达式
百度"正则表达式大全", "用户名正则", "密码正则", "日期正则"
字符串的正则匹配运算方法:
s.matches(正则)
拆分: s.split(";")
替换: s.replaceAll(正则, 子串)
Integer
int的包装类
创建实例:
new Integer(6)
Integer.valueOf(6)
Integer类内部,存在一个Integer[]数组,其中缓存了256个Integer实例,
封装的数字范围:-128到127范围内的值,访问缓存对象,范围外的值,新建实例
Date/SimpleDateFormat
集合
ArrayList
数组
访问任意位置效率高
增删数据,效率可能降低
默认初始容量10
1.5倍增长
LinkedList
双向链表
两端效率高
HashMap:使用Entry[]数组存放数据,初始长度为16
哈希表,散列表
键:
不重复
无序
哈希运算过程:
Entry[]
初始容量16
key.hashCode()用哈希值计算下标i
键值对封装成Entry对象,放入i位置
HashMap
key.hashCode() 得到哈希值,用哈希值来计算下标 i
键值对封装成 Entry 实例放入 i 位置
空位置,直接放入
有数据,依次用key.equals()方法比较键是否相等
找到相等的键,覆盖值
没有相等的键,用链表连接在一起
负载率,加载因子到0.75 (数据量/容量)
新建翻倍容量的新数组 所有数据重新执行哈希运算放入新数组
jdk1.8
链表长度到8,把链表转成红黑树
树上的数据减少到6,转回成链表
io
File
文件目录操作的对象
FileInputStream/FileOutputStream
文件流
ObjectInputStream/ObjectOutputStream
对象序列化
被序列化的对象要实现Serializable
writeObject()
readObject()
InputStreamReader/OutputStreamWriter
编码转换流
java - Unicode
UTF-8
GBK
text - BufferedReader, PrintWriter
properties - Properties
xml - DOM4J
json - Jackson {“xxx”:“xxx”,“xxx”:“xxx”,“xxx”,{json}}
yaml - Jackson {xxx: //两个空格
xxx:
XXX:
XXX:}
线程
创建
继承Thread
实现Runnable
方法
Thread.currentThread()
Thread.sleep()
Thread.yield()
getName(),setName()
start()
interrupt()
join()
setDaemon(true)
setPriority(优先级)
同步 synchronized(解决并发安全问题)
步调一致地执行,不会引起数据混乱
synchronized(对象) {//指定对象的锁,共享数据的锁最合适
}
synchronized void f() {//抢当前实例的锁(this)
}
static synchronized void f() {//抢"类对象"的锁
}
生产者,消费者模型
中间用一个集合来传递数据
线程间通信,中间class传递数据,解耦
等待和通知
wait()
notify()
notifyAll()
必须在synchronized内调用
等待通知的对象,必须是加锁的对象
wait()外面总应该是一个循环
Lock
乐观锁:在自己的时间片上,在cpu上自旋,一次次重试抢锁
Lock
ReentrantLock
ReentrantReadWriteLock:读写锁
工具辅助创建,控制线程
线程池 ExecutorService/Executors
Executors.newFixedThreadPool(5)
Executors.newCachedThreadPool()
Executors.newSingleThreadExecutor()
pool.execute(Runnable任务)
Callable/Future
Future future = pool.submit(Callable任务)
Object r = future.get();
ThreadLocal
线程绑定
线程当做流水线,上游放入数据,下游访问数据
threadLocal.set(数据)
threadLocal.get()
threadLocal.remove()
乐观锁
ReentrentLock
ReentrentReadWriteLock 读写锁
sychronized:抢不到锁就放弃时间片,效率低。
Lock抢不到锁,会自旋再抢,重复尝试去抢锁.,效率高,CPU占用高。