KNN k临近算法
遍历所有训练样本,求距离最近的点的结论,作为最后的预测结果
MR版:map求样本距离(key:样本,value:距离),combine求的最小值,是过滤功能,reduce就有一个求得距离最小值
贝叶斯:
贝叶斯定理公式:P(A|B)=P(B|A)*P(A)/P(B)
贝叶斯将在属性条件下的结论的概率转为:在结论条件下属性的概率的乘积*结论的概率
求得样本属性的在结论上的出现次数,样本结论的次数,商就是P(B|A)
MR版:map求拼接keyvalue(key:属性-结论 |结论,value:1)
combine 求和(key:属性-结论 |结论,value:count)
reduce和combine相同
决策树:
id3
香农熵 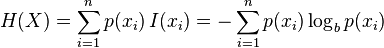
根据香农熵最大的来选择分裂特征,香农熵中的p(x)是在结论ci下xi的概率, 可以写成p(x,c|c);
c4.5
信息增益
p(c|c)-p(x,c|c)
信息增益率
p(c|c) - p(x,c|c) / p(x|x)
CART
cart的决策树是二叉树,每次取特征值得规则是使得信息杂质最少
方法一:GINI 1- pow(yi/y,2)-pow(yi/y,2)
方法二:方差 pow(e-yi,2)+pow(e-yi,2)
SVM:
SVM的原理是用超平面分割数据,不同分类在超平面的两侧;使得超平面离样本几何距离最大;
使用对偶和梯度上升,调整超平面的参数W向量,使得所有样本都满足kkt条件
wx+b = 0 为超平面,wx+b=1和wx+b=-1为两类边界
logistic回归分类
是将y = 0|x
使用坐标梯度上升求得参数w向量,求导后w := w + a(y-h(x))x ,其中a是每次梯度上升的步长,x是属性向量,h(x) = sigmod f(wx),不断循环进行梯队上升,知道w稳定或最大循环次数
数值预测
线性回归
回归函数的确定,y=f(x) , 使得y-h(x)最小
方法一:使用梯度下降,求得w,同上
方法二:使用最小二阶乘
bagging 是用多个独立的分类器
boosting 是用多个分类器,分类器之间会有影响,后面的分类器会加重对前面分类错误的样本进行分类
adaboost
是基于boosting,使用多个弱分类器,每个样本有权重D,每个弱分类器也有权重a
a = 正确分类的样本/所有样本
d = d*e^-a/sum(d) 正确的样本
d = d*e^a/sum(d) 错误的样本
随机森林:
进行行抽取,和列抽取
行抽取用可放回的抽取 m ,列抽数量是远远小于数据特征n< 聚类方法: kmeans 1.随机选择k个中心点 2.遍历所有训练样本,将样本分给距离最近的k点 3.遍历结束后更新k点,使其为所属样本的中心点 重复2,3步,知道k稳定,或循环次数到达阈值 二分kmeans 1.让所有样本属于一个集簇,求得中心点 2.用中心点二分所有样本,重新计算各自的中心点,选择误差最大的集簇作为下一个二分的数据集 重复 2操作,知道k点到达预期数,或误差到达阈值 canopy canopy不是硬分类器,他有t1,t2,detal三个值,t1>t2 随机取一个样本为canopy,当d 在mahout中,canopy不是删除样本这样实现的,mahout的mapper和reduce的操作一样,都是添加canopy中心点,当d mean shift 中心点漂移,有着梯度上升思想,不断优化中心点 mahout算法中用canopy修改,当d fp-growth: 求频繁集合的算法,只用遍历数据集两次,就可建立fp树 遍历集合,求最小项集的出现次数 给所有样本内部排序,并且过滤掉出现次数小于阈值的项集 用排序好的数据建立fp树,树是字典树,节点是频繁集合的路径,值是路径出现次数 fp树建好后,使用header链表,自底向上获得频繁项 mahout的分布式fp: 第一次遍历样本一样,求最小项集的出现次数 根据排序的最小项集,分割项集,如a,b,c,d,e,f,g, 分割数据a,b,c,d,e,f,g; c,d,e,f,g; e f g; 这样频繁集合不会应为分片而丢失(可以理解为fp树从顶向下分割数据) 基于项目的推荐算法: 计算人-物 计算物-物 获得物和物的相似矩阵 在用相似矩阵 * 人-物 ,就是人和其他物品的关联度