MySQL之SELECT,WHERE,GROUP BY及聚合函数详解
第一部分讲述了关于MySQL以及HeidiSQL软件的安装,不熟悉的朋友可以参考一些 ,—>>传送门,那么本部分开始SQL语句的学习。为了方便讲解,本部分利用MySQL的实例数据库,下载地址,下载完以后解压在你熟悉的文件夹即可。
1. 导入数据库
如果你喜欢在终端进行SQL操作,那么只需要打开MySQL终端,就着这样的样子
接下来我演示一下怎么将数据库导入我们的MySQL终端。
第一步:建立数据库(数据库的名字随便起);第二步:导入实例数据库
语句如下:
CREATE DATEBASE IF NOT EXISTS yiibaidb DEFAULT CHARSET utf8 COLLATE utf8_general_ci;
use yiibaidb;
source C:/Users/Administrator/Desktop/yiibaidb.sql;
注:SQL语句末端以“;”结束。以上语句完成以后回车就会陆续读取SQL语句,这个过程稍长,语句比较多,稍等片刻即可。读取完成以后,我们可以简单的测试一下结果,可以输入以下语句
select city,phone,country from `offices`;
最后的结果显示为

同理,若是其他操作,完全可以类似以上进行操作,前提是你的SQL语言是对的。由于个人比较喜欢在HeidiSQL软件上操作,所以后续的讲解依然采取HeidiSQL,只是界面发生变化,SQL语言完全一样,就看各位看官喜欢哪个版本的了。下面介绍一下如何用HeidiSQL来录入实例数据库了。
2. HeidiSQL录入数据库
首先依然是打开你的软件,这里假如你会了,不会的请看基础一,进入界面以后点击文件 -> 加载SQL文件,然后将你的实例数据库打开就ok了,将界面刷新一下,就加载上了,如图所示

类似在终端上的操作,依然将表offices的数据提取出来,之前也说了SQL语句是完全一样的,so。。。
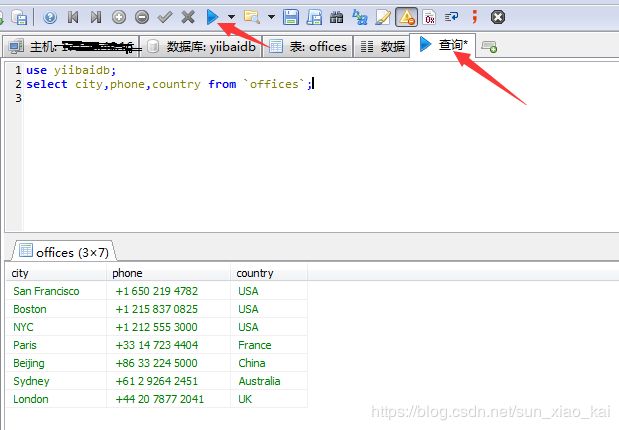
上面的斜三角是执行语句,下面的斜三角是书写SQL语句。可以发现出现了和终端一样的效果,但是样子是不是好看很多啊,哈哈哈。下面将重点介绍SQL语言。
3. SQL语言
SQL语言对于代码的注释一一般单行注释用–,例如
SELECT * FROM DATABASE --在这里加注释即可
若是多行注释,采用以下形式
/*注释
注释*/
SELECT * FROM DATABASE
3.1 查询语句 SELECT…FROM…
这个语句从意思上就可以直接看出,表示的意思就是从二维表中选择一些列,例如select city,phone,country from offices;这句话,表示的就是从offices中选择city,phone,country
需求1:提取重复值
语法SELECT DISTINCT 列名称 FROM 表名称,返回的就是唯一不同的值
需求2:提取前N条记录
语句(基于SQL):SELECT TOP N条* FROM 表名称
尤其:select top X * from table_name order by colum_name desc语句可以达到按colum_name属性降序排序查询前X条记录,“order by” 后紧跟要排序的属性列名,其中desc表示降序,asc表示升序(默认也是升序方式),综合上面,select top n * from (select top m * from table_name order by column_name ) a order by column_name desc可以达到查询第N到M条记录。常用的分页也是这种方式
语句(基于MySQL):select * from 表名称 limit 0,N,通常0是可以省略的,直接写成 limit N。0代表从第0条记录后面开始,也就是从第一条开始
需求3:进行语句的判断
需要用到CASE语句,一般有两种表示方式为:
----case表达式1
select ID,TestType,
CASE TestType WHEN '主体结构' then '1'
WHEN '钢结构' then '2'
WHEN '建筑幕墙' then '3'
ELSE '0'
end as '类型'
from LbtTestTypes
----case表达式2
select ID,TestType,
CASE WHEN TestType='主体结构' then '1'
WHEN TestType='钢结构' then '2'
WHEN TestType='建筑幕墙' then '3'
ELSE '0'
end as '类型'
from LbtTestTypes
3.2 WHERE判断语句
在SELECT的时候通常会添加WHERE判断语句进行筛选,例如对于商业存放的数据,我们需要特定的数据的时候,就需要添加WHERE进行筛选。下面我将利用实例数据库为大家演示一下如何运用,假如我们只想从employees表中获取销售代表员工,那么就有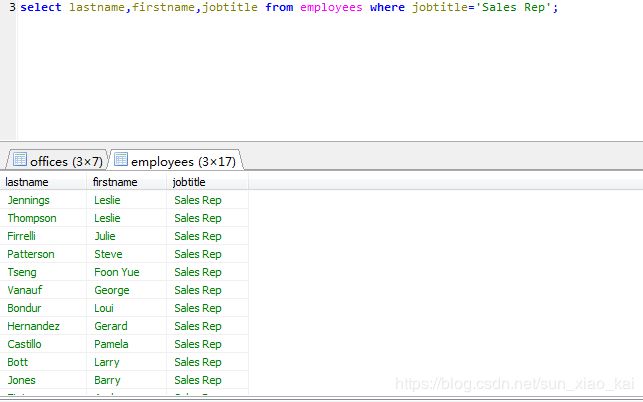
相同的道理,对于相应的添加判断语句,会得到我们所需要的结果。除此之外,用在判断语句里面的一些常用运算符有
| 运算符 | 描述 |
|---|---|
| = | 等于号,几乎任何数据类型都可以使用它 |
| <>或!= | 不等号 |
| < | 小于号,通常使用数字和日期/时间数据类型。 |
| > | 大于号 |
| <= | 小于或等于号 |
| >= | 大于或等于 |
例如我们要使用不等于(!=或者<>)运算符来获取不是销售代表的其它所有员工:
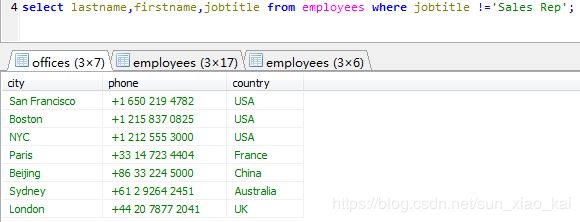
大家可以根据我的操作自己改动一些条件,进行偏判断。
3.3 分组数据GROUP BY
语法:
SELECT column_name, function(column_name)
FROM table_name
WHERE column_name operator value
GROUP BY column_name;
GROUP BY 句法解析,group by语法可以根据给定数据列的每个成员对查询结果进行分组统计,最终得到一个分组汇总表。SELECT子句中的列名必须为分组列或列函数。列函数对于GROUP BY子句定义的每个组各返回一个结果。简而言之就是根据某个类进行重新分组成型的表,例如

那这个结果与3.2中的图片结果比较一下,就会发现该sql首先会按照class进行去重查询,并分组新的表,然后输出的时候将每一个分组的第一个记录组合在一起形成了最终的结果。我们还可以发现,最终的记录是按照class进行排序的。这样的顺序并不可靠,具体形成的原因恐怕需要在Mysql的底层原理中找到答案。
GROUP BY 与HAVING 一起使用
首先HACING作为一个判断条件,用于二次筛选。例如
 第一次是以group by筛选类lastname进行去重排序,形成新的表,加入having条件进行二次筛选,例子是名字为Tom的信息,此例子仅作为大家对二者运用的理解。
第一次是以group by筛选类lastname进行去重排序,形成新的表,加入having条件进行二次筛选,例子是名字为Tom的信息,此例子仅作为大家对二者运用的理解。
3.4 ORDER BY 排序查询语句
ASE升序、DESE降序
示例:
select * from 学生表 order by 年龄 查询学生表信息、按年龄的升序(默认、可缺省、从低到高)排列显示,也可以多条件排序、 比如 order by 年龄,成绩 desc,按年龄升序排列后、再按成绩降序排列。大家不妨自己联系一下,group by和order by连用的效果。
4.MySQL函数
4.1 聚合函数
MySQL聚合函数 - 提供最常用的MySQL聚合函数的简要概述。
avg()函数 - 计算一组值或表达式的平均值。
count()函数 - 计算表中的行数。
instr()函数 - 返回子字符串在字符串中第一次出现的位置。
sum()函数 - 计算一组值或表达式的总和。
min()函数 - 在一组值中找到最小值。
max()函数 - 在一组值中找到最大值。
group_concat()函数 - 将字符串从分组中连接成具有各种选项(如DISTINCT,ORDER BY和SEPARATOR)的字符串。
MySQL标准偏差函数 - 显示如何计算人口标准偏差和样本标准偏差。
4.2 字符串函数
()函数 - 将两个或多个字符串组合成一个字符串。
length()函数&char_length()函数 - 以字节和字符获取字符串的长度。
left()函数 - 获取指定长度的字符串的左边部分。
replace()函数 - 搜索并替换字符串中的子字符串。
()函数 - 从具有特定长度的位置开始提取一个子字符串。
trim()函数 - 从字符串中删除不需要的字符。
find_in_set()函数 - 在逗号分隔的字符串列表中找到一个字符串。
format()函数 - 格式化具有特定区域设置的数字,舍入到小数位数。
4.3 时间函数
()函数 - 返回当前日期。
()函数 - 计算两个DATE值之间的天数。
day()函数 - 获取指定日期月份的天(日)。
date_add()函数 - 将时间值添加到日期值。
date_sub()函数 - 从日期值中减去时间值。
date_format()函数 - 根据指定的日期格式格式化日期值。
()函数 - 获取指定日期的工作日的名称。
()函数 - 返回日期的工作日索引。
extract()函数 - 提取日期的一部分。
now()函数 - 返回当前日期和时间。
month()函数 - 返回一个表示指定日期的月份的整数。
_to_date()函数 - 将字符串转换为基于指定格式的日期和时间值。
()函数 - 返回当前日期。
()函数 - 计算两个TIME或DATETIME值之间的差值。
()函数 - 计算两个DATE或DATETIME值之间的差值。
week()函数 - 返回一个日期的星期数值。
weekday()函数 - 返回一个日期表示为工作日/星期几的索引。
year()函数 - 返回日期值的年份部分。