简单的数据可视化
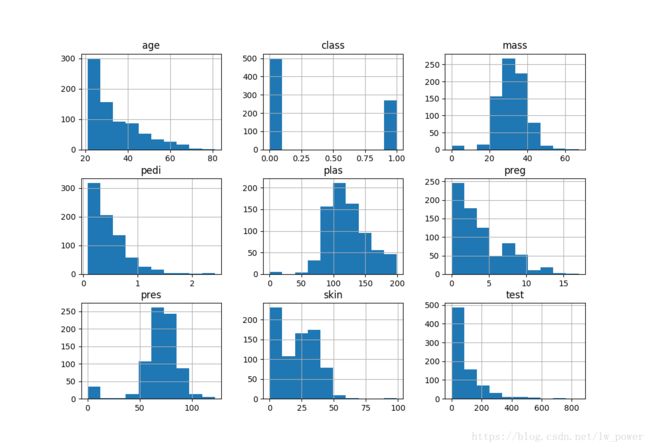
直方图(Histogram)
- 又称质量分布图,可以直观地展示每个属性的分布情况;
- 一般用横轴表示数据类型,纵轴表示分布情况;
- 可以很直观看到数据是高斯分布、指数分布还是偏态分布。
下面使用 Pandas 的 DataFrame 对象的 hist() 方法就可以直接得到直方图。
import pandas as pd
import matplotlib.pyplot as plt
filename = 'pima_data.csv'
names = ['preg', 'plas', 'pres', 'skin', 'test', 'mass', 'pedi', 'age', 'class']
data = pd.read_csv(filename, names=names)
data.hist()
plt.show()
显示如下:
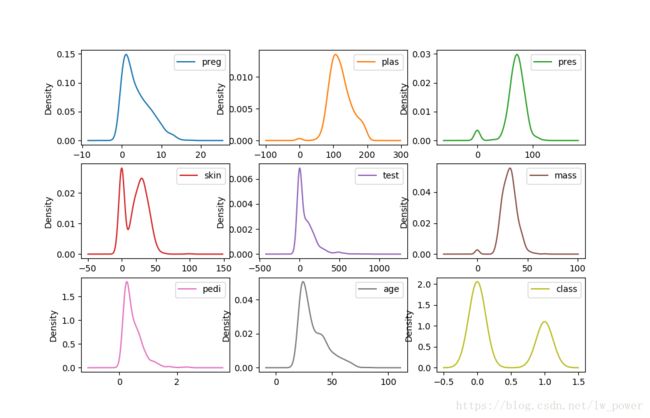
密度图(density)
- 密度图类似于直方图,它用平滑的曲线来描述数据的分布。
import pandas as pd
import matplotlib.pyplot as plt
filename = 'pima_data.csv'
names = ['preg', 'plas', 'pres', 'skin', 'test', 'mass', 'pedi', 'age', 'class']
data = pd.read_csv(filename, names=names)
data.plot(kind='density', subplots=True, layout=(3, 3), sharex=False)
plt.show()
显示如下:
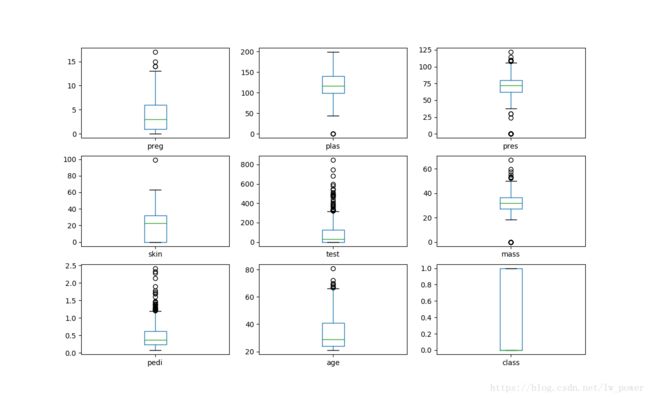
箱线图
- 首先画一条中位数线;
- 然后以下四分位数和上四分位数画一个盒子;
- 上下各有一条横线,表示上边缘和下边缘,通过横线来显示数据的伸展状况;
- 游离在边缘之外的点为异常值。
import pandas as pd
import matplotlib.pyplot as plt
filename = 'pima_data.csv'
names = ['preg', 'plas', 'pres', 'skin', 'test', 'mass', 'pedi', 'age', 'class']
data = pd.read_csv(filename, names=names)
data.plot(kind='box', subplots=True, layout=(3, 3), sharex=False)
plt.show()
相关矩阵图
- 把所有属性两两影响的关系展示出来的图表就叫相关矩阵图。
import pandas as pd
import matplotlib.pyplot as plt
import numpy as np
filename = 'pima_data.csv'
names = ['preg', 'plas', 'pres', 'skin', 'test', 'mass', 'pedi', 'age', 'class']
data = pd.read_csv(filename, names=names)
correlations = data.corr()
fig = plt.figure()
ax = fig.add_subplot(111)
cax = ax.matshow(correlations, vmin=-1, vmax=1)
fig.colorbar(cax) # 显示右边的图例
ticks = np.arange(0, 9, 1)
ax.set_xticks(ticks)
ax.set_yticks(ticks)
ax.set_xticklabels(names)
ax.set_yticklabels(names)
plt.show()
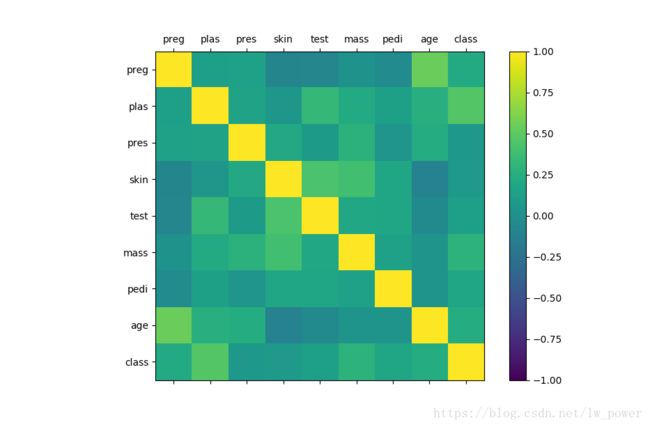
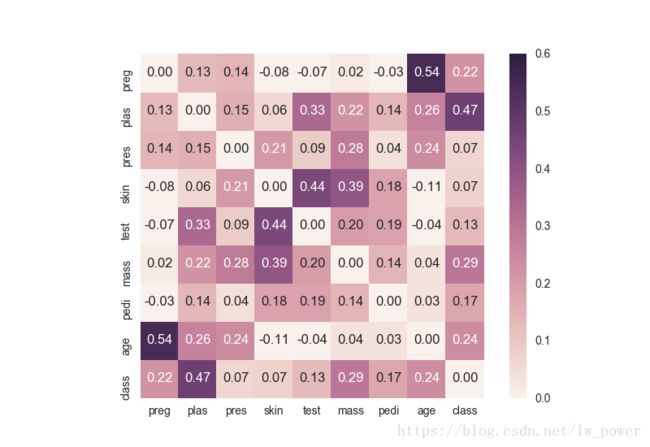
使用 Seaborn 绘制更直观的相关矩阵热力图
import seaborn as sns
import matplotlib.pyplot as plt
import pandas as pd
import numpy as np
filename = 'pima_data.csv'
names = ['preg', 'plas', 'pres', 'skin', 'test', 'mass', 'pedi', 'age', 'class']
data = pd.read_csv(filename, names=names)
correlations = data.corr(method='pearson')
print(correlations.shape)
# 把主对角线上相关系数为 1 的干扰去掉
correlations = correlations - np.eye(*correlations.shape)
print(correlations.max())
ax = sns.heatmap(correlations,
vmin=0, # 矩阵的最小值,相关系数的最小值是 0
vmax=.6, # 矩阵的最大值,相关系数的最大值是 1
annot=True, # 是否把数值标注在矩阵上
fmt=".2f", # 显示数值的格式,如果是整数,填 "d"
square=True) # 矩阵的单元格显示成正方形
plt.show()
参考资料:
http://seaborn.pydata.org/generated/seaborn.heatmap.html?highlight=heatmap#seaborn.heatmap
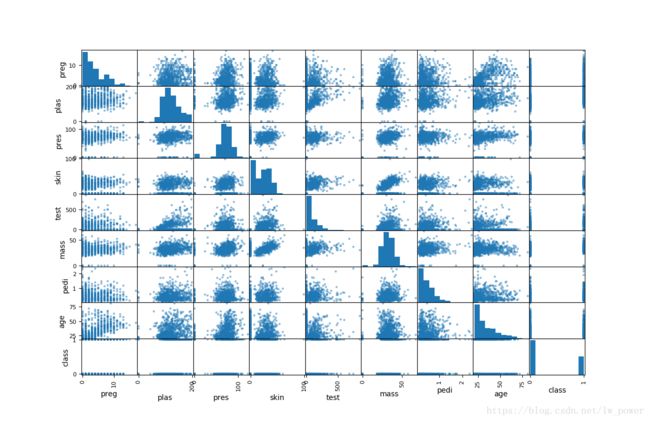
散点矩阵图
import pandas as pd
import matplotlib.pyplot as plt
from pandas.plotting import scatter_matrix
filename = 'pima_data.csv'
names = ['preg', 'plas', 'pres', 'skin', 'test', 'mass', 'pedi', 'age', 'class']
data = pd.read_csv(filename, names=names)
scatter_matrix(data)
plt.show()