街景字符识别3-字符模型识别
在前面的章节里,我们将街景字符识别问题定位成定长字符多分类问题,即针对各个字符训练分类器,进而进行字符串的识别。
1 学习目标
- 学习CNN基础和原理
- 了解迁移学习之微调(Fine Tuning)
- 使用Pytorch框架构建CNN模型,并完成训练
2 卷积神经网络(CNN)
-
入门资料推荐:卷积神经网络入门见《机器学习_ 学习笔记 (all in one)_V0.96.pdf》。
如果文字还是觉得抽象,那这个资源可视化形式解释卷积神经网络的每一个流程CNN Explainer:比如1个卷积核怎么讲RGB3个Channel的像素transform成一个feature map的;全连接层是怎么得到最终的分类结果的。 -
卷积神经网络(CNN)用于分类,主要是因为它能很好地自动提取图像特征。其中卷积核是单一特征提取器,下图是单一特征提取示例。
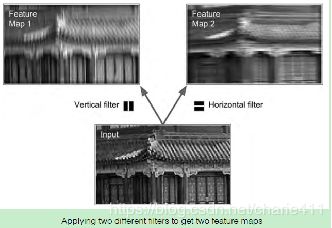
我觉得最有意思的是经多层卷积和池化后,简单特征逐步升级到复杂特征提取。
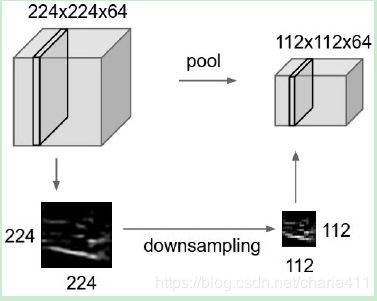
 3. 最大池化层的作用是downsizing.卷积层的多个卷积核处理得到不同的特征,而最大池化缩小尺寸的同时尽可能保留特征。
3. 最大池化层的作用是downsizing.卷积层的多个卷积核处理得到不同的特征,而最大池化缩小尺寸的同时尽可能保留特征。
-
Feature Map感觉像是下一层的输入,详见关于feature map是什么的介绍
3 反向传播
Michael Nielsen的《Neural Network and Deep Learning神经网络与深度学习》
4 迁移学习之微调
4.1 目的
迁移学习的目的是充分利用已经过大规模数据训练成熟的复杂模型。因为这些复杂模型可以抽取较通用的图像特征,从而能够帮助识别边缘、纹理、形状和物体组成等特征。通过将从源数据集(如ImageNet)学到的知识迁移到目标数据集上提取特征,比自行利用小数据集训练精度高,而且省时。
4.2 微调fine tuning
4.2.1 流程
微调是迁移学习中的一种常用技术,当目标数据集远小于源数据集时,微调有利于提升模型的泛化能力。主要步骤是:
- 选择与当前应用相似的神经网络模型,即源模型
【0527补充】关于“与当前应用相似”,CNNTricks中提到最重要的因素是目标数据集的大小以及与源数据集的相似程度。这两个因素参数组合成不同场景,需要相应选用不同的策略。例如,当目标数据集与源数据集相似时,如果目标数据集很小,可以根据源模型中 top layers提取出来的特征训练一个线性分类器;如果手头有大量数据,可以以较小的学习速率微调源模型中的 top layers。当目标数据集与源数据集存在较大差异时,如果数据量足够,可以以较小的学习速率微调源模型中的layers;如果数据量少,经神经网络训练出来的线性分类器精度不够,建议选用SVM进行分类。
Fine-tune on pre-trained models. Nowadays, many state-of-the-arts deep networks are released by famous research groups, i.e., Caffe Model Zoo and VGG Group. Thanks to the wonderful generalization abilities of pre-trained deep models, you could employ these pre-trained models for your own applications directly. For further improving the classification performance on your data set, a very simple yet effective approach is to fine-tune the pre-trained models on your own data. As shown in following table, the two most important factors are the size of the new data set (small or big), and its similarity to the original data set. Different strategies of fine-tuning can be utilized in different situations. For instance, a good case is that your new data set is very similar to the data used for training pre-trained models. In that case, if you have very little data, you can just train a linear classifier on the features extracted from the top layers of pre-trained models. If your have quite a lot of data at hand, please fine-tune a few top layers of pre-trained models with a small learning rate. However, if your own data set is quite different from the data used in pre-trained models but with enough training images, a large number of layers should be fine-tuned on your data also with a small learning rate for improving performance. However, if your data set not only contains little data, but is very different from the data used in pre-trained models, you will be in trouble. Since the data is limited, it seems better to only train a linear classifier. Since the data set is very different, it might not be best to train the classifier from the top of the network, which contains more dataset-specific features. Instead, it might work better to train the SVM classifier on activations/features from somewhere earlier in the network.
- 复制源模型上除输出层外的所有层及参数【因为源模型的输出层与源数据集标签相关,故排除】,得到目标模型;
- 为目标模型添加一个输出大小为目标数据集类别个数的输出层,并随机初始化该层的模型参数;
- 在目标数据集上训练目标模型。训练方法是输出层从头训练,其余各层基于源模型参数微调。
4.2.2 pytorch实现例子
- 我们使用ImageNet数据集上预训练的ResNet-18作为源模型pretrained_net。指定 pretrained=True 来自动下载并加载预训练的模型参数。
- 源模型中全连接层将ResNet最终的全局平均池化层输出变换成1000类的输出。去掉源模型输出层为目标模型model_conv,其中model_conv只包含特征提取部分,并不包括分类器。
- model_conv后加为定长字符多分类模型需要的多个多分类层fc1,fc2,fc3,fc4,fc5。
- 然后将目标数据集的样本依次传入特征提取模型model_conv、多个分类层的输出结果拼起来即可得到定长字符串结果。
在pytorch中定义模型的操作包含建立神经网络结构和返回输出的前向传播方法forward。其中model_conv返回每个batch样本image的形状为(batch_size,channel,W,H),所以我们要用view()将image的形状转换成(batch_size,W*H)才送入全连接层。
class SVHN_Model2(nn.Module):
def __init__(self):
super(SVHN_Model1, self).__init__()
pretrained_net = models.resnet18(pretrained=True)
pretrained_net.avgpool = nn.AdaptiveAvgPool2d(1)
self.model_conv = nn.Sequential(*list(pretrained_net .children())
[:-1])
self.fc1 = nn.Linear(512, 11)
self.fc2 = nn.Linear(512, 11)
self.fc3 = nn.Linear(512, 11)
self.fc4 = nn.Linear(512, 11)
self.fc5 = nn.Linear(512, 11)
def forward(self,image):
feature = self.model_conv(image)
feature = feature.view(feature.shape[0], -1)#数据Shape转换
c1 = self.fc1(feature)
c2 = self.fc2(feature)
c3 = self.fc3(feature)
c4 = self.fc4(feature)
c5 = self.fc5(feature)
return c1, c2, c3, c4, c5
5 参考资料
《动手学深度学习》
《机器学习_ 学习笔记 (all in one)_V0.96.pdf》