python排序
一、冒泡排序
冒泡排序(Bubble Sort),是一种计算机科学领域的较简单的排序算法。
它重复地走访过要排序的数列,一次比较两个元素,如果他们的顺序错误就把他们交换过来。走访数列的工作是重复地进行直到没有再需要交换,也就是说该数列已经排序完成。
这个算法的名字由来是因为越大的元素会经由交换慢慢“浮”到数列的顶端,故名。
data_set = [ 9,1,22,31,45,3,6,2,11 ]
loop_count = 0
for j in range(len(data_set)):
for i in range(len(data_set) - j- 1): # -1 是因为每次比对的都 是i 与i +1,不减1的话,最后一次对比会超出list 获取范围,-j是因为,每一次大loop就代表排序好了一个最大值,放在了列表最后面,下次loop就不用再运算已经排序好了的值 了
if data_set[i] > data_set[i+1]: #switch
tmp = data_set[i]
data_set[i] = data_set[i+1]
data_set[i+1] = tmp
loop_count +=1
print(data_set)
print(data_set)
print("loop times", loop_count)
二、选择排序
选择排序(Selection sort)是一种简单直观的排序算法。它的工作原理是每一次从待排序的数据元素中选出最小(或最大)的一个元素,存放在序列的起始位置,直到全部待排序的数据元素排完。
选择排序是不稳定的排序方法(比如序列[5, 5, 3]第一次就将第一个[5]与[3]交换,导致第一个5挪动到第二个5后面)。
data_set = [ 9,1,22,31,45,3,6,2,11 ]
smallest_num_index = 0 #初始列表最小值,默认为第一个
loop_count = 0
for j in range(len(data_set)):
for i in range(j,len(data_set)):
if data_set[i] < data_set[smallest_num_index]: #当前值 比之前选出来的最小值 还要小,那就把它换成最小值
smallest_num_index = i
loop_count +=1
else:
print("smallest num is ",data_set[smallest_num_index])
tmp = data_set[smallest_num_index]
data_set[smallest_num_index] = data_set[j]
data_set[j] = tmp
print(data_set)
print("loop times", loop_count)
三、插入排序
插入排序(Insertion Sort)的基本思想是:将列表分为2部分,左边为排序好的部分,右边为未排序的部分,循环整个列表,每次将一个待排序的记录,按其关键字大小插入到前面已经排好序的子序列中的适当位置,直到全部记录插入完成为止。

- 插入排序非常类似于整扑克牌。
-
在开始摸牌时,左手是空的,牌面朝下放在桌上。接着,一次从桌上摸起一张牌,并将它插入到左手一把牌中的正确位置上。为了找到这张牌的正确位置,要将它与手中已有的牌从右到左地进行比较。无论什么时候,左手中的牌都是排好序的。
也许你没有意识到,但其实你的思考过程是这样的:现在抓到一张7,把它和手里的牌从右到左依次比较,7比10小,应该再往左插,7比5大,好,就插这里。为什么比较了10和5就可以确定7的位置?为什么不用再比较左边的4和2呢?因为这里有一个重要的前提:手里的牌已经是排好序的。现在我插了7之后,手里的牌仍然是排好序的,下次再抓到的牌还可以用这个方法插入。编程对一个数组进行插入排序也是同样道理,但和插入扑克牌有一点不同,不可能在两个相邻的存储单元之间再插入一个单元,因此要将插入点之后的数据依次往后移动一个单元。
source = [92, 77, 67, 8, 6, 84, 55, 85, 43, 67]
for index in range(1,len(source)):
current_val = source[index] #先记下来每次大循环走到的第几个元素的值
position = index
while position > 0 and source[position-1] > current_val: #当前元素的左边的紧靠的元素比它大,要把左边的元素一个一个的往右移一位,给当前这个值插入到左边挪一个位置出来
source[position] = source[position-1] #把左边的一个元素往右移一位
position -= 1 #只一次左移只能把当前元素一个位置 ,还得继续左移只到此元素放到排序好的列表的适当位置 为止
source[position] = current_val #已经找到了左边排序好的列表里不小于current_val的元素的位置,把current_val放在这里
print(source)
结果:
[77, 92, 67, 8, 6, 84, 55, 85, 43, 67]
[67, 77, 92, 8, 6, 84, 55, 85, 43, 67]
[8, 67, 77, 92, 6, 84, 55, 85, 43, 67]
[6, 8, 67, 77, 92, 84, 55, 85, 43, 67]
[6, 8, 67, 77, 84, 92, 55, 85, 43, 67]
[6, 8, 55, 67, 77, 84, 92, 85, 43, 67]
[6, 8, 55, 67, 77, 84, 85, 92, 43, 67]
[6, 8, 43, 55, 67, 77, 84, 85, 92, 67]
[6, 8, 43, 55, 67, 67, 77, 84, 85, 92]
#更容易理解的版本
data_set = [ 9,1,22,9,31,-5,45,3,6,2,11 ]
for i in range(len(data_set)):
#position = i
while i > 0 and data_set[i] < data_set[i-1]:# 右边小于左边相邻的值
tmp = data_set[i]
data_set[i] = data_set[i-1]
data_set[i-1] = tmp
i -= 1
# position = i
# while position > 0 and data_set[position] < data_set[position-1]:# 右边小于左边相邻的值
# tmp = data_set[position]
# data_set[position] = data_set[position-1]
# data_set[position-1] = tmp
# position -= 1
四、快速排序

#_*_coding:utf-8_*_
__author__ = 'Alex Li'
def quick_sort(array,left,right):
'''
:param array:
:param left: 列表的第一个索引
:param right: 列表最后一个元素的索引
:return:
'''
if left >=right:
return
low = left
high = right
key = array[low] #第一个值
while low < high:#只要左右未遇见
while low < high and array[high] > key: #找到列表右边比key大的值 为止
high -= 1
#此时直接 把key(array[low]) 跟 比它大的array[high]进行交换
array[low] = array[high]
array[high] = key
while low < high and array[low] <= key : #找到key左边比key大的值,这里为何是<=而不是<呢?你要思考。。。
low += 1
#array[low] =
#找到了左边比k大的值 ,把array[high](此时应该刚存成了key) 跟这个比key大的array[low]进行调换
array[high] = array[low]
array[low] = key
quick_sort(array,left,low-1) #最后用同样的方式对分出来的左边的小组进行同上的做法
quick_sort(array,low+1, right)#用同样的方式对分出来的右边的小组进行同上的做法
if __name__ == '__main__':
array = [96,14,10,9,6,99,16,5,1,3,2,4,1,13,26,18,2,45,34,23,1,7,3,22,19,2]
#array = [8,4,1, 14, 6, 2, 3, 9,5, 13, 7,1, 8,10, 12]
print("before sort:", array)
quick_sort(array,0,len(array)-1)
print("-------final -------")
print(array)
五、希尔排序
希尔排序介绍
希尔排序(Shell Sort)是插入排序的一种。也称缩小增量排序,是直接插入排序算法的一种更高效的改进版本,该方法的基本思想是:先将整个待排元素序列分割成若干个子序列(由相隔某个“增量”的元素组成的)分别进行直接插入排序,然后依次缩减增量再进行排序,待整个序列中的元素基本有序(增量足够小)时,再对全体元素进行一次直接插入排序。因为直接插入排序在元素基本有序的情况下(接近最好情况),效率是很高的,因此希尔排序在时间效率比直接插入排序有较大提高。

- 首先要明确一下增量的取法:
-
第一次增量的取法为: d=count/2;
第二次增量的取法为: d=(count/2)/2;
最后一直到: d=1; - 看上图观测的现象为:
-
d=3时:将40跟50比,因50大,不交换。
将20跟30比,因30大,不交换。
将80跟60比,因60小,交换。
d=2时:将40跟60比,不交换,拿60跟30比交换,此时交换后的30又比前面的40小,又要将40和30交换,如上图。
将20跟50比,不交换,继续将50跟80比,不交换。
d=1时:这时就是前面讲的插入排序了,不过此时的序列已经差不多有序了,所以给插入排序带来了很大的性能提高。
代码实例:
import time,random
#source = [8, 6, 4, 9, 7, 3, 2, -4, 0, -100, 99]
#source = [92, 77, 8,67, 6, 84, 55, 85, 43, 67]
source = [ random.randrange(10000+i) for i in range(10000)]
#print(source)
step = int(len(source)/2) #分组步长
t_start = time.time()
while step >0:
print("---step ---", step)
#对分组数据进行插入排序
for index in range(0,len(source)):
if index + step < len(source):
current_val = source[index] #先记下来每次大循环走到的第几个元素的值
if current_val > source[index+step]: #switch
source[index], source[index+step] = source[index+step], source[index]
step = int(step/2)
else: #把基本排序好的数据再进行一次插入排序就好了
for index in range(1, len(source)):
current_val = source[index] # 先记下来每次大循环走到的第几个元素的值
position = index
while position > 0 and source[
position - 1] > current_val: # 当前元素的左边的紧靠的元素比它大,要把左边的元素一个一个的往右移一位,给当前这个值插入到左边挪一个位置出来
source[position] = source[position - 1] # 把左边的一个元素往右移一位
position -= 1 # 只一次左移只能把当前元素一个位置 ,还得继续左移只到此元素放到排序好的列表的适当位置 为止
source[position] = current_val # 已经找到了左边排序好的列表里不小于current_val的元素的位置,把current_val放在这里
print(source)
t_end = time.time() - t_start
print("cost:",t_end)
六、堆排序
堆排序介绍
堆排序,顾名思义,就是基于堆。因此先来介绍一下堆的概念。
堆分为最大堆和最小堆,其实就是完全二叉树。最大堆要求节点的元素都要大于其孩子,最小堆要求节点元素都小于其左右孩子,两者对左右孩子的大小关系不做任何要求,其实很好理解。有了上面的定义,我们可以得知,处于最大堆的根节点的元素一定是这个堆中的最大值。其实我们的堆排序算法就是抓住了堆的这一特点,每次都取堆顶的元素,将其放在序列最后面,然后将剩余的元素重新调整为最大堆,依次类推,最终得到排序的序列。
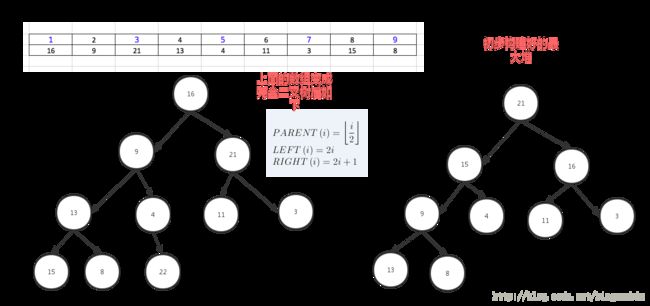
- 步骤:
-
堆排序就是把堆顶的最大数取出,
将剩余的堆继续调整为最大堆,具体过程在第二块有介绍,以递归实现
剩余部分调整为最大堆后,再次将堆顶的最大数取出,再将剩余部分调整为最大堆,这个过程持续到剩余数只有一个时结束
#_*_coding:utf-8_*_
__author__ = 'Alex Li'
import time,random
def sift_down(arr, node, end):
root = node
#print(root,2*root+1,end)
while True:
# 从root开始对最大堆调整
child = 2 * root +1 #left child
if child > end:
#print('break',)
break
print("v:",root,arr[root],child,arr[child])
print(arr)
# 找出两个child中交大的一个
if child + 1 <= end and arr[child] < arr[child + 1]: #如果左边小于右边
child += 1 #设置右边为大
if arr[root] < arr[child]:
# 最大堆小于较大的child, 交换顺序
tmp = arr[root]
arr[root] = arr[child]
arr[child]= tmp
# 正在调整的节点设置为root
#print("less1:", arr[root],arr[child],root,child)
root = child #
#[3, 4, 7, 8, 9, 11, 13, 15, 16, 21, 22, 29]
#print("less2:", arr[root],arr[child],root,child)
else:
# 无需调整的时候, 退出
break
#print(arr)
print('-------------')
def heap_sort(arr):
# 从最后一个有子节点的孩子还是调整最大堆
first = len(arr) // 2 -1
for i in range(first, -1, -1):
sift_down(arr, i, len(arr) - 1)
#[29, 22, 16, 9, 15, 21, 3, 13, 8, 7, 4, 11]
print('--------end---',arr)
# 将最大的放到堆的最后一个, 堆-1, 继续调整排序
for end in range(len(arr) -1, 0, -1):
arr[0], arr[end] = arr[end], arr[0]
sift_down(arr, 0, end - 1)
#print(arr)
def main():
# [7, 95, 73, 65, 60, 77, 28, 62, 43]
# [3, 1, 4, 9, 6, 7, 5, 8, 2, 10]
#l = [3, 1, 4, 9, 6, 7, 5, 8, 2, 10]
#l = [16,9,21,13,4,11,3,22,8,7,15,27,0]
array = [16,9,21,13,4,11,3,22,8,7,15,29]
#array = []
#for i in range(2,5000):
# #print(i)
# array.append(random.randrange(1,i))
print(array)
start_t = time.time()
heap_sort(array)
end_t = time.time()
print("cost:",end_t -start_t)
print(array)
#print(l)
#heap_sort(l)
#print(l)
if __name__ == "__main__":
main()
dataset = [16,9,21,3,13,14,23,6,4,11,3,15,99,8,22]
for i in range(len(dataset)-1,0,-1):
print("-------",dataset[0:i+1],len(dataset),i)
#for index in range(int(len(dataset)/2),0,-1):
for index in range(int((i+1)/2),0,-1):
print(index)
p_index = index
l_child_index = p_index *2 - 1
r_child_index = p_index *2
print("l index",l_child_index,'r index',r_child_index)
p_node = dataset[p_index-1]
left_child = dataset[l_child_index]
if p_node < left_child: # switch p_node with left child
dataset[p_index - 1], dataset[l_child_index] = left_child, p_node
# redefine p_node after the switch ,need call this val below
p_node = dataset[p_index - 1]
if r_child_index < len(dataset[0:i+1]): #avoid right out of list index range
#if r_child_index < len(dataset[0:i]): #avoid right out of list index range
#print(left_child)
right_child = dataset[r_child_index]
print(p_index,p_node,left_child,right_child)
# if p_node < left_child: #switch p_node with left child
# dataset[p_index - 1] , dataset[l_child_index] = left_child,p_node
# # redefine p_node after the switch ,need call this val below
# p_node = dataset[p_index - 1]
#
if p_node < right_child: #swith p_node with right child
dataset[p_index - 1] , dataset[r_child_index] = right_child,p_node
# redefine p_node after the switch ,need call this val below
p_node = dataset[p_index - 1]
else:
print("p node [%s] has no right child" % p_node)
#最后这个列表的第一值就是最大堆的值,把这个最大值放到列表最后一个, 把神剩余的列表再调整为最大堆
print("switch i index", i, dataset[0], dataset[i] )
print("before switch",dataset[0:i+1])
dataset[0],dataset[i] = dataset[i],dataset[0]
print(dataset)