AI studio 训练分享之Python小白逆袭大神课程
缘由
最近,百度在推广自家的paddlepaddle框架,这同时就是在疯狂的送GPU资源,(真香)开了很多七日培训班,之前参加了一项cv的课程,感觉很不错,尤其是hub库和lite库的压缩和部署功能,还是相当给力,而且社区给了很多开源项目。但当时没有开通博客,所以,就着这次新的课程,一起扒一下这次课程一些可收获的点,具体的课程链接可见:百度 aistudio实训平台–Python小白逆袭大神课程.
第一课
这其实就是在介绍一些studio的相关基本操作(基于jupyter),下面列举一些比较重要的点:
1.几个基本的shell命令:
查看当前挂载的数据集目录
!ls /home/aistudio/data/
输出:data269
显示当前路径
!pwd
输出:/home/aistudio
如果需要进行持久化安装, 需要使用持久化路径, 如下方代码示例:
!mkdir /home/aistudio/external-libraries#建立文件夹
!pip install beautifulsoup4 -t /home/aistudio/external-libraries #安装到文件夹
同时添加如下代码, 这样每次环境(kernel)启动的时候只要运行下方代码即可:
import sys
sys.path.append('/home/aistudio/external-libraries')
git的应用:
!git clone https://github.com/PaddlePaddle/Paddle.git #Paddle官方模型
这里提供了一个非常好的插件工具:注意: Paddle的Git体积过大, 同步会非常迟缓. 建议使用浏览器插件, 对指定目录进行下载, 然后上传至AI Studio的项目空间中. gitzip
2.关于调试
Notebook执行Python代码的原理和传统IDE略有不同.
传统IDE, 当点击Run按钮时, 编译器/解释器开始构建一个进程. 用户通过单步执行/设置断点进行代码调试和变量监控. 当代码出错, 或用户点击Stop按钮时, 进程被杀死, 资源回收.
而Notebook, 一旦启动, 就是开始创建一个"进程"(kernel). 每一个Cell, 都是一个天然的断点. 当代码出错, 或用户点击Stop按钮时, “进程"通常也不会被杀死.因此如果代码陷入死循环等情况, 需要用户手动关闭并重启该"进程”.**此外, Notebook的Cell是可以随意颠倒顺序来执行的. 这点和传统IDE有很大不同.
作为前端的Notebook, 与后端的进程(kernel), 建立有一个Session. 未来本平台将支持terminal功能. 也就可以同时支持多个Session来控制kernel.
关于调试,可以去看一个包:PDB来进行代码调试, 可以打印变量和单步执行 PDB
3.关于上传大文件

4. Magic命令(简易版的终端)
Magic命令是Notebook的高级用法了. 可以运行一些特殊的指令. Magic 命令的前面带有一个或两个百分号(% 或 %%),分别代表行 Magic 命令和单元格 Magic 命令。行 Magic 命令仅应用于编写 Magic 命令时所在的行,而单元格 Magic 命令应用于整个单元格。
Magic命令查询
举个例子:
显示全部可用的Magic命令 %lsmagic
%lsmagic
Available line magics:
%alias %alias_magic %autoawait %autocall %automagic %autosave %bookmark %cat %cd %clear %colors %config %connect_info %cp %debug %dhist %dirs %doctest_mode %ed %edit %env %gui %hist %history %killbgscripts %ldir %less %lf %lk %ll %load %load_ext %loadpy %logoff %logon %logstart %logstate %logstop %ls %lsmagic %lx %macro %magic %man %matplotlib %mkdir %more %mv %notebook %page %pastebin %pdb %pdef %pdoc %pfile %pinfo %pinfo2 %popd %pprint %precision %prun %psearch %psource %pushd %pwd %pycat %pylab %qtconsole %quickref %recall %rehashx %reload_ext %rep %rerun %reset %reset_selective %rm %rmdir %run %save %sc %set_env %store %sx %system %tb %time %timeit %unalias %unload_ext %who %who_ls %whos %xdel %xmode
Available cell magics:
%%! %%HTML %%SVG %%bash %%capture %%debug %%file %%html %%javascript %%js %%latex %%markdown %%perl %%prun %%pypy %%python %%python2 %%python3 %%ruby %%script %%sh %%svg %%sx %%system %%time %%timeit %%writefile
Automagic is ON, % prefix IS NOT needed for line magics.
列举几个常用的:
%run: 运行python代码
%run work/SampleOfRun.py
%%writefile magic可以把cell的内容保存到外部文件里。 而%pycat则可把外部文件展示在Cell中
%env:设置环境变量 使用该命令, 可以在不必重启Kernel的情况下管理notebook的环境变量
第二课
这一课是python基础课,这我还是推荐去B站学习,这个得练习,不断去用才行。
列举几个重要的:
break语句可以跳出 for 和 while 的循环体
n = 1
while n <= 100:
if n > 10:
break
print(n)
n += 1
continue语句跳过当前循环,直接进行下一轮循环
n = 1
while n < 10:
n = n + 1
if n % 2 == 0:
continue
print(n)
pass是空语句,一般用做占位语句,不做任何事情
for letter in 'Room':
if letter == 'o':
pass
print('pass')
print(letter)
Tuple(元组)
tuple与list类似,不同之处在于tuple的元素不能修改。tuple写在小括号里,元素之间用逗号隔开。
元组的元素不可变,但可以包含可变对象,如list。
t1 = ('abcd', 786 , 2.23, 'runoob', 70.2)
t2 = (1, )
t3 = ('a', 'b', ['A', 'B'])
t3[2][0] = 'X' #将第二个元组项的第一个改为X
print(t3)
输出:('a', 'b', ['X', 'B'])
dict(字典)字典是无序的对象集合,使用键-值(key-value)存储,具有极快的查找速度。
键(key)必须使用不可变类型。同一个字典中,键(key)必须是唯一的。
d = {'Michael': 95, 'Bob': 75, 'Tracy': 85}
print(d['Michael'])
输出:95
set(集合)
set和dict类似,也是一组key的集合,但不存储value。由于key不能重复,所以,在set中,没有重复的key。set是无序的,重复元素在set中自动被过滤。
s = set([1, 1, 2, 2, 3, 3])
print(s)
输出:{1, 2, 3}
这里再总结一些自己之前没有注意到的点:
种子数:调用 random.random() 生成随机数时,每一次生成的数都是随机的。但是,当预先使用 random.seed(x) 设定好种子之后,其中的 x 可以是任意数字,此时使用 random() 生成的随机数将会是同一个。种子一样,生成的radom一样
import random
ran = random.random()
print(ran) #输出0.3009718634018812
print ("------- 设置种子 seed -------")
random.seed(10)
print ("Random number with seed 10 : ", random.random())
# 生成同一个随机数
random.seed(10)
print ("Random number with seed 10 : ", random.random())
输出:------- 设置种子 seed -------
Random number with seed 10 : 0.5714025946899135
Random number with seed 10 : 0.5714025946899135
ran = random.randint(1,20)用作生成指定范围内的随机数
针对list的操作
join():以字符作为分隔符,将字符串中所有的元素合并为一个新的字符串
new_str = '-'.join('Hello')
print(new_str)
输出:H-e-l-l-o
insert():指定位置添加到一个列表中
girls.insert(1,'虞书欣')
print(girls)
输出:['杨超越', '虞书欣', '刘雯', '奚梦瑶']
原先:['杨超越', '刘雯', '奚梦瑶']
del 删除
words = ['cat','hello','pen','pencil','ruler']
del words[1] #或者 words.remove('cat') 再或者 words.pop(1)
print(words)
['cat', 'pen', 'pencil', 'ruler']
关于切片

nimals = ['cat','dog','tiger','snake','mouse','bird']
print(animals[2:5]) #总共三个 左开右闭
print(animals[-1:]) #最后一个
print(animals[-3:-1])#总共两个 左开右闭,所以最后一个没有
print(animals[-5:-1:2])#-5到-1(-1不取)每隔2个取
print(animals[::2]) #从头开始,每隔两个
输出:
['tiger', 'snake', 'mouse']
['bird']
['snake', 'mouse']
['dog', 'snake']
['cat', 'tiger', 'mouse']
关于排序
#默认升序
new_list = sorted(random_list)
print(new_list)
#降序
new_list = sorted(random_list,reverse =True)
print(new_list)
#逆序
原先:(14, 10, 9, 15, 6, 10, 12, 5, 15, 8)
print(random_tuple[::-1])
现在:(8, 15, 5, 12, 10, 6, 15, 9, 10, 14)
针对元组的操作
元组中只有一个元素时,需要在后面加逗号
tuple3 = ('hello',)
print(type(tuple3))
输出:<class 'tuple'>
元组不能修改,所以不存在往元组里加入元素
t1 = (1,2,3)+(4,5)
print(t1)
(1, 2, 3, 4, 5)
解释对元组中*的操作:
#当元组中元素个数与变量个数不一致时
#定义一个元组,包含5个元素
t4 = (1,2,3,4,5)
#将t4[0],t4[1]分别赋值给a,b;其余的元素装包后赋值给c
a,b,*c = t4
print(a,b,c)
print(c)
print(*c)
输出:
1 2 [3, 4, 5]
[3, 4, 5]
3 4 5
针对字典的操作
list可以转成字典,但前提是列表中元素都要成对出现
dict3 = dict([('name','杨超越'),('weight',45)])
print(dict3)
输出:{'name': '杨超越', 'weight': 45}
dict4 = {}
dict4['name'] = '虞书欣'
dict4['weight'] = 43
print(dict4)
输出:{'name': '虞书欣', 'weight': 43}
字典中item的是干啥的:可以理解为列表的实例化,为读取和调用做准备
#字典里的函数 items() keys() values()
dict5 = {'杨超越':165,'虞书欣':166,'上官喜爱':164}
print(dict5.items())
for key,value in dict5.items():
if value > 165:
print(key)
输出:
dict_items([('杨超越', 165), ('虞书欣', 166), ('上官喜爱', 164)])
虞书欣
#values() 取出字典中所有的值,保存到列表中
results = dict5.values()
print(results)
结果:dict_values([165, 166, 164])
字典中的get函数:
print(dict5.get(‘赵小棠’,170)) #如果能够取到值,则返回字典中的值,否则返回默认值170
针对类
定义一个类Animals:
(1)init()定义构造函数,与其他面向对象语言不同的是,Python语言中,会明确地把代表自身实例的self作为第一个参数传入
(2)创建一个实例化对象 cat,init()方法接收参数
(3)使用点号 . 来访问对象的属性。
class Animal:
def __init__(self,name):
self.name = name
print('动物名称实例化')
def eat(self):
print(self.name +'要吃东西啦!')
def drink(self):
print(self.name +'要喝水啦!')
cat = Animal('miaomiao')
print(cat.name)
cat.eat()
cat.drink()
输出:
动物名称实例化
miaomiao
miaomiao要吃东西啦!
miaomiao要喝水啦!
针对JSON
JSON(JavaScript Object Notation) 是一种轻量级的数据交换格式,易于人阅读和编写。
json.dumps 用于将 Python 对象编码成 JSON 字符串。
import json
data = [ { 'b' : 2, 'd' : 4, 'a' : 1, 'c' : 3, 'e' : 5 } ]
json = json.dumps(data)
print(json)
输出:[{"b": 2, "d": 4, "a": 1, "c": 3, "e": 5}]
为了提高可读性,dumps方法提供了一些可选的参数。
sort_keys=True表示按照字典排序(a到z)输出。
indent参数,代表缩进的位数
separators参数的作用是去掉,和:后面的空格,传输过程中数据越精简越好
json = json.dumps(data, sort_keys=True, indent=4,separators=(',', ':'))
输出:{
"a":1,
"b":2,
"c":3,
"d":4,
"e":5
}
json.loads 用于解码 JSON 数据。该函数返回 Python 字段的数据类型。
import json
jsonData = '{"a":1,"b":2,"c":3,"d":4,"e":5}'
text = json.loads(jsonData) #将string转换为dict
print(text)
输出:{'a': 1, 'b': 2, 'c': 3, 'd': 4, 'e': 5}
try/except语句用来检测try语句块中的错误,从而让except语句捕获异常信息并处理。finally中的内容,退出try时总会执行
常见linux命令
!ls /home ls 命令显示当前目录的内容 常见linux命令大全
!ls ./ 上一节目录
ls -l -l:以长格式显示目录下的内容列表。
!pwd 以绝对路径的方式显示用户当前工作目录
cp 复制文件或目录
将文件file复制到目录/usr/men/tmp下,并改名为file1
cp file /usr/men/tmp/file1
mv 移动文件与目录,或修改文件与目录的名称
!mv /home/aistudio/work/test_copy.txt /home/aistudio/data/ #将txt文件移动到data文件夹里
mv ex3 new1 #将文件ex3改名为new1
rm 移除文件或目录
!rm /home/aistudio/data/test_copy.txt
很多大型文件或者数据从服务器上传或者下载的时候都需要打包和压缩解压,这时候知道压缩和解压的各种命令是很有必要的。
常见的压缩文件后缀名有.tar.gz,.gz,和.zip,下面来看看在Linux上它们分别的解压和压缩命令。
gzip:
linux压缩文件中最常见的后缀名即为.gz,gzip是用来压缩和解压.gz文件的命令。
常用参数:
-d或–decompress或–uncompress:解压文件;
-r或–recursive:递归压缩指定文件夹下的文件(该文件夹下的所有文件被压缩成单独的.gz文件);
-v或–verbose:显示指令执行过程。
注:gzip命令只能压缩单个文件,而不能把一个文件夹压缩成一个文件(与打包命令的区别)。
#会将文件压缩为文件 test.txt.gz,原来的文件则没有了,解压缩也一样
!gzip /home/aistudio/work/test.txt
解压:
!gzip -d /home/aistudio/test.gz
tar:
tar本身是一个打包命令,用来打包或者解包后缀名为.tar。配合参数可同时实现打包和压缩。
常用参数:
-c或–create:建立新的备份文件;
-x或–extract或–get:从备份文件中还原文件;
-v:显示指令执行过程;
-f或–file:指定备份文件;
-C:指定目的目录;
-z:通过gzip指令处理备份文件;
-j:通过bzip2指令处理备份文件。
最常用的是将tar命令与gzip命令组合起来,直接对文件夹先打包后压缩:
!tar -zcvf /home/aistudio/work/test.tar.gz /home/aistudio/work/test.txt
!tar -zxvf /home/aistudio/work/test.tar.gz
zip和unzip
zip命令和unzip命令用在在Linux上处理.zip的压缩文件。
常用参数
zip:
-v:显示指令执行过程;
-m:不保留原文件;
-r:递归处理。
unzip:
-v:显示指令执行过程;
-d:解压到指定目录。
!zip -r /home/aistudio/work/test.zip /home/aistudio/work/test.txt
!unzip /home/aistudio/work/test.zip
第三课
第三课即爬虫,爬虫的过程,就是模仿浏览器的行为,往目标站点发送请求,接收服务器的响应数据,提取需要的信息,并进行保存的过程。 Python为爬虫的实现提供了工具:requests模块、BeautifulSoup库
上网的全过程:
普通用户:
打开浏览器 --> 往目标站点发送请求 --> 接收响应数据 --> 渲染到页面上。
爬虫程序:
模拟浏览器 --> 往目标站点发送请求 --> 接收响应数据 --> 提取有用的数据 --> 保存到本地/数据库。
爬虫的过程:
1.发送请求(requests模块)requests.get(url)可以发送一个http get请求,返回服务器响应内容
2.获取响应数据(服务器返回)
3.解析并提取数据(BeautifulSoup查找或者re正则)
BeautifulSoup 是一个可以从HTML或XML文件中提取数据的Python库。BeautifulSoup官网网址BeautifulSoup支持Python标准库中的HTML解析器,还支持一些第三方的解析器,其中一个是 lxml。
BeautifulSoup(markup, “html.parser”)或者BeautifulSoup(markup, “lxml”),推荐使用lxml作为解析器,因为效率更高。
4.保存数据
安装如下:
#!pip install beautifulsoup4 -t /home/aistudio/external-libraries
#!pip install lxml -t /home/aistudio/external-libraries
# 同时添加如下代码, 这样每次环境(kernel)启动的时候只要运行下方代码即可:
import sys
sys.path.append('/home/aistudio/external-libraries')
备注:以下的信息不是完整的程序,完整程序可参照链接link
本次主要是爬取百度百科中《青春有你2》中参赛选手信息,返回html
具体流程:先requests.get得到response(http请求)->BeautifulSoup解析
import json
import re
import requests
import datetime
from bs4 import BeautifulSoup
import os
#获取当天的日期,并进行格式化,用于后面文件命名,格式:20200420
today = datetime.date.today().strftime('%Y%m%d')
def crawl_wiki_data():
"""
爬取百度百科中《青春有你2》中参赛选手信息,返回html
"""
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/67.0.3396.99 Safari/537.36'
} #目的是预防反爬虫程序,模仿浏览器的请求行为
url='https://baike.baidu.com/item/青春有你第二季'
try:
response = requests.get(url,headers=headers)
print(response.status_code)
#将一段文档传入BeautifulSoup的构造方法,就能得到一个文档的对象, 可以传入一段字符串
soup = BeautifulSoup(response.text,'lxml') #lxml解析器解析
#返回的是class为table-view log-set-param的所有标签
tables = soup.find_all('table',{'class':'table-view log-set-param'})
crawl_table_title = "参赛学员"
for table in tables:
#对当前节点前面的标签和字符串进行查找
table_titles = table.find_previous('div').find_all('h3')
for title in table_titles:
if(crawl_table_title in title):
return table
except Exception as e:
print(e)
网页的前端内容如下:

需要爬取的信息位置即下图的tbody下的各个tr ,但有很多

解析的内容:
def parse_wiki_data(table_html):
'''
从百度百科返回的html中解析得到选手信息,以当前日期作为文件名,存JSON文件,保存到work目录下
'''
bs = BeautifulSoup(str(table_html),'lxml') #先解析
all_trs = bs.find_all('tr') #是一个列表
error_list = ['\'','\"'] #引号和单引号
stars = []
for tr in all_trs[1:]: #爬回来的第一行是标题,所以从第二行开始
all_tds = tr.find_all('td') #td代表每个单元格
star = {}
#姓名
star["name"]=all_tds[0].text
#个人百度百科链接
star["link"]= 'https://baike.baidu.com' + all_tds[0].find('a').get('href')
#籍贯
star["zone"]=all_tds[1].text
#星座
star["constellation"]=all_tds[2].text
#身高
star["height"]=all_tds[3].text
#体重
star["weight"]= all_tds[4].text
#花语,去除掉花语中的单引号或双引号
flower_word = all_tds[5].text
for c in flower_word:
if c in error_list:
flower_word=flower_word.replace(c,'') #将引号和单引号替换 为空格
star["flower_word"]=flower_word
#公司
if not all_tds[6].find('a') is None:
star["company"]= all_tds[6].find('a').text #有链接的取链接
else:
star["company"]= all_tds[6].text #没链接的取值
stars.append(star)
json_data = json.loads(str(stars).replace("\'","\""))
with open('work/' + today + '.json', 'w', encoding='UTF-8') as f:
json.dump(json_data, f, ensure_ascii=False) #汉字形式存储

存储的结果:

def crawl_pic_urls():
'''
爬取每个选手的百度百科图片,并保存
'''
with open('work/'+ today + '.json', 'r', encoding='UTF-8') as file:
json_array = json.loads(file.read())
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/67.0.3396.99 Safari/537.36'
}
for star in json_array:
name = star['name']
link = star['link']
#请在以下完成对每个选手图片的爬取,将所有图片url存储在一个列表pic_urls中
#为了获取选手的图像,从个人的百度百科发送get请求
response = requests.get(link ,headers=headers)
#将文档传入BeautifulSoup,得到一个文档的对象
bs = BeautifulSoup(response.text,'lxml')
#从页面中选择链接,链接指向图片
pic_list_url = bs.select('.summary-pic a')[0].get('href')
pic_list_url = 'https://baike.baidu.com'+pic_list_url
#向链接发送get请求
pic_list_response = requests.get(pic_list_url,headers=headers)
#图片列表解析并获得所有图片链接
bs = BeautifulSoup(pic_list_response.text,'lxml')
pic_list_html = bs.select('.pic-list img')
pic_urls =[]
for pic_html in pic_list_html:
pic_url = pic_html.get('src')
pic_urls.append(pic_url)
#图片链接列表pic_urls,下载图片,保存在name文件夹
down_pic(name,pic_urls)
#!!!根据图片链接列表pic_urls, 下载所有图片,保存在以name命名的文件夹中!!!
down_pic(name,pic_urls)

下载(f.write(pic.content))指定文件到指定路径下
def down_pic(name,pic_urls):
'''
根据图片链接列表pic_urls, 下载所有图片,保存在以name命名的文件夹中,
'''
path = 'work/'+'pics/'+name+'/'
if not os.path.exists(path):
os.makedirs(path)
for i, pic_url in enumerate(pic_urls):
try:
pic = requests.get(pic_url, timeout=15)
string = str(i + 1) + '.jpg'
with open(path+string, 'wb') as f:
f.write(pic.content)
print('成功下载第%s张图片: %s' % (str(i + 1), str(pic_url)))
except Exception as e:
print('下载第%s张图片时失败: %s' % (str(i + 1), str(pic_url)))
print(e)
continue
然后可以在如下文件夹中得到以名字命名的文件,里面放置爬到的图片

最后再加一个打印信息的功能:
def show_pic_path(path):
'''
遍历所爬取的每张图片,并打印所有图片的绝对路径
'''
pic_num = 0
for (dirpath,dirnames,filenames) in os.walk(path):
for filename in filenames:
pic_num += 1
print("第%d张照片:%s" % (pic_num,os.path.join(dirpath,filename)))
print("共爬取《青春有你2》选手的%d照片" % pic_num)
所以,爬取指定文件的具体流程(前向)放在main下:
if __name__ == '__main__':
#爬取百度百科中《青春有你2》中参赛选手信息,返回html
html = crawl_wiki_data()
#解析html,得到选手信息,保存为json文件
parse_wiki_data(html)
#从每个选手的百度百科页面上爬取图片,并保存
crawl_pic_urls()
#打印所爬取的选手图片路径
show_pic_path('/home/aistudio/work/pics/')
print("所有信息爬取完成!")
总结:主要还是熟悉:requests模块、BeautifulSoup库的调用和解析过程,同时去网站的源码页面自己找找需要的关键字很重要,一定要找准确,最后就是返回html,保存为json文件,爬取图片,并保存,打印所爬取的选手图片路径的过程
第四天
主要是介绍一些深度学习常用的库,这个我确实经常在用,所以只总结自己之前忽略的
numpy是Python科学计算库的基础。包含了强大的N维数组对象和向量运算。
pandas是建立在numpy基础上的高效数据分析处理库,是Python的重要数据分析库。
Matplotlib是一个主要用于绘制二维图形的Python库。用途:绘图、可视化
PIL库是一个具有强大图像处理能力的第三方库。用途:图像处理
DataFrame是一个表格型的数据结构,类似于Excel或sql表
它含有一组有序的列,每列可以是不同的值类型(数值、字符串、布尔值等)
DataFrame既有行索引也有列索引,它可以被看做由Series组成的字典(共用同一个索引)
data = {'state': ['Ohio', 'Ohio', 'Ohio', 'Nevada', 'Nevada'], 'year': [2000, 2001, 2002, 2001, 2002], 'pop': [1.5, 1.7, 3.6, 2.4, 2.9]}
frame = pd.DataFrame(data)
print(frame)
输出:
state year pop
0 Ohio 2000 1.5
1 Ohio 2001 1.7
2 Ohio 2002 3.6
3 Nevada 2001 2.4
4 Nevada 2002 2.9
d = {'one': pd.Series([1., 2., 3.], index=['a', 'b', 'c']),
'two': pd.Series([1., 2., 3., 4.], index=['a', 'b', 'c', 'd'])}
print(pd.DataFrame(d))
结果:
one two
a 1.0 1.0
b 2.0 2.0
c 3.0 3.0
d NaN 4.0
PIL库图片增强的操作:
from PIL import Image
import matplotlib.pyplot as plt
#显示matplotlib生成的图形
%matplotlib inline
#读取图片
img = Image.open('/home/aistudio/street.jpg')
#显示图片
#img.show() #自动调用计算机上显示图片的工具,aistudio没有直接相连windows的图片工具,所以不能直接show()
plt.imshow(img)
plt.show(img)
#获得图像的模式
img_mode = img.mode
print(img_mode)
width,height = img.size
print(width,height)
图片旋转:img_rotate = img.rotate(45)
剪切:
#打开图片
img1 = Image.open('/home/aistudio/work/yushuxin.jpg')
#剪切 crop()四个参数分别是:(左上角点的x坐标,左上角点的y坐标,右下角点的x坐标,右下角点的y坐标)
img1_crop_result = img1.crop((126,0,381,249))
#保存图片
img1_crop_result.save('/home/aistudio/work/yushuxin_crop_result.jpg')
缩放:
img2 = Image.open('/home/aistudio/work/yushuxin.jpg')
width,height = img2.size
#缩放
img2_resize_result = img2.resize((int(width*0.6),int(height*0.6)),Image.ANTIALIAS)
print(img2_resize_result.size)
#保存图片
img2_resize_result.save('/home/aistudio/work/yushuxin_resize_result.jpg')
镜像效果:左右旋转、上下旋转:
#打开图片
img3 = Image.open('/home/aistudio/work/yushuxin.jpg')
#左右镜像
img3_lr = img3.transpose(Image.FLIP_LEFT_RIGHT)
#展示左右镜像图片
plt.imshow(img3_lr)
plt.show(img3_lr)
#上下镜像
img3_bt = img3.transpose(Image.FLIP_TOP_BOTTOM)
#展示上下镜像图片
plt.imshow(img3_bt)
plt.show(img3_bt)
Matplotlib库绘图
import matplotlib.pyplot as plt
import numpy as np
#显示matplotlib生成的图形
%matplotlib inline
x = np.linspace(-1,1,50) #等差数列
y = 2*x + 1
#传入x,y,通过plot()绘制出折线图
plt.plot(x,y)
#显示图形
plt.show()
折线图:
l1, = plt.plot(x,y1,color='red',linewidth=1)
l2, = plt.plot(x,y2,color='blue',linewidth=5)
plt.legend(handles=[l1,l2],labels=['aa','bb'],loc='best')
plt.xlabel('x')
plt.ylabel('y')
#plt.xlim((0,1)) #x轴只截取一段进行显示
#plt.ylim((0,1)) #y轴只截取一段进行显示
plt.show()
柱状图:
x = np.arange(10)
y = 2**x+10
plt.bar(x,y,facecolor='#9999ff',edgecolor='white')
for ax,ay in zip(x,y):
plt.text(ax,ay,'%.1f' % ay,ha='center',va='bottom')
plt.show()
散点图:
#dots1 = np.array([2,3,4,5,6])
#dots2 = np.array([2,3,4,5,6])
dots1 =np.random.rand(50)
dots2 =np.random.rand(50)
plt.scatter(dots1,dots2,c='red',alpha=0.5) #c表示颜色,alpha表示透明度
plt.show()
下面是本次课程一些作业的中需要注意的点,我这里总结的更加注重数据清洗这里,具体画饼图的操作我之前在cv的课程里已经掌握
matplotlib绘图时需要下载中文的字体:
#下载中文字体
!wget https://mydueros.cdn.bcebos.com/font/simhei.ttf
#将字体文件复制到matplotlib字体路径
!cp simhei.ttf /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/matplotlib/mpl-data/fonts/ttf/
#一般只需要将字体文件复制到系统字体目录下即可,但是在aistudio上该路径没有写权限,所以此方法不能用
#!cp simhei.ttf /usr/share/fonts/
#创建系统字体文件路径
!mkdir .fonts
#复制文件到该路径
!cp simhei.ttf .fonts/
!rm -rf .cache/matplotlib
import matplotlib.pyplot as plt
import numpy as np
import json
import matplotlib.font_manager as font_manager
#显示matplotlib生成的图形
%matplotlib inline
with open('data/data31557/20200422.json', 'r', encoding='UTF-8') as file:
json_array = json.loads(file.read())
#绘制小姐姐区域分布柱状图,x轴为地区,y轴为该区域的小姐姐数量
zones = []
for star in json_array:
zone = star['zone']
zones.append(zone)
print(len(zones))
print(zones)
zone_list = []
count_list = []
for zone in zones:
if zone not in zone_list:
count = zones.count(zone)
zone_list.append(zone)
count_list.append(count)
print(zone_list)
print(count_list)
#设置显示中文
plt.rcParams['font.sans-serif'] = ['SimHei'] # 指定默认字体
plt.figure(figsize=(20,15))
plt.bar(range(len(count_list)), count_list,color='r',tick_label=zone_list,facecolor='#9999ff',edgecolor='white')
#这里是调节横坐标的倾斜度,rotation是度数,以及设置刻度字体大小
plt.xticks(rotation=45,fontsize=20)
plt.yticks(fontsize=20)
plt.legend()
plt.title('''《青春有你2》参赛选手''',fontsize = 24)
plt.savefig('/home/aistudio/work/result/bar_result.jpg')
plt.show()
结果:
['中国湖北', '中国四川', '中国山东', '中国浙江', '中国山东', '中国台湾', '中国陕西', '中国广东', '中国黑龙江', '中国上海', '中国四川', '中国山东', '中国安徽', '中国安徽', '中国安徽', '中国北京', '中国贵州', '中国吉林', '中国四川', '中国四川', '中国江苏', '中国山东', '中国山东', '中国山东', '中国山东', '中国江苏', '中国四川', '中国山东', '中国山东', '中国广东', '中国浙江', '中国河南', '中国安徽', '中国河南', '中国北京', '中国北京', '马来西亚', '中国湖北', '中国四川', '中国天津', '中国黑龙江', '中国四川', '中国陕西', '中国辽宁', '中国湖南', '中国上海', '中国贵州', '中国山东', '中国湖北', '中国黑龙江', '中国黑龙江', '中国上海', '中国浙江', '中国湖南', '中国台湾', '中国台湾', '中国台湾', '中国台湾', '中国山东', '中国北京', '中国北京', '中国浙江', '中国河南', '中国河南', '中国福建', '中国河南', '中国北京', '中国山东', '中国四川', '中国安徽', '中国河南', '中国四川', '中国湖北', '中国四川', '中国陕西', '中国湖南', '中国四川', '中国台湾', '中国湖北', '中国广西', '中国江西', '中国湖南', '中国湖北', '中国北京', '中国陕西', '中国上海', '中国四川', '中国山东', '中国辽宁', '中国辽宁', '中国台湾', '中国浙江', '中国北京', '中国黑龙江', '中国北京', '中国安徽', '中国河北', '马来西亚', '中国四川', '中国湖南', '中国台湾', '中国广东', '中国上海', '中国四川', '日本', '中国辽宁', '中国黑龙江', '中国浙江', '中国台湾']
['中国湖北', '中国四川', '中国山东', '中国浙江', '中国台湾', '中国陕西', '中国广东', '中国黑龙江', '中国上海', '中国安徽', '中国北京', '中国贵州', '中国吉林', '中国江苏', '中国河南', '马来西亚', '中国天津', '中国辽宁', '中国湖南', '中国福建', '中国广西', '中国江西', '中国河北', '日本']
[6, 14, 13, 6, 9, 4, 3, 6, 5, 6, 9, 2, 1, 2, 6, 2, 1, 4, 5, 1, 1, 1, 1, 1]

第五天
今晚主要讲的是PaddleHub就是为了解决对深度学习模型的需求而开发的工具。基于飞桨领先的核心框架,精选效果优秀的算法,提供了百亿级大数据训练的预训练模型,方便用户不用花费大量精力从头开始训练一个模型。说白了就是更加集成和高级的深度学习API.
最主要的优势下面两个ppt很明了:


然后本节课给了几个案例,可以记录一下
情感分析
情感倾向分析(Sentiment Classification,简称Senta)针对带有主观描述的中文文本,可自动判断该文本的情感极性类别并给出相应的置信度,能够帮助企业理解用户消费习惯、分析热点话题和危机舆情监控,为企业提供有利的决策支持。
#安装情感分析模型
!hub install senta_lstm==1.1.0
可以得到如下的结果:

口罩检测
PyramidBox-Lite是基于2018年百度发表于计算机视觉顶级会议ECCV 2018的论文PyramidBox而研发的轻量级模型,模型基于主干网络FaceBoxes,对于光照、口罩遮挡、表情变化、尺度变化等常见问题具有很强的鲁棒性。该PaddleHub Module基于WIDER FACE数据集和百度自采人脸数据集进行训练,支持预测,可用于检测人脸是否佩戴口罩。
#安装口罩检测模型
!hub install pyramidbox_lite_mobile_mask==1.1.0
对这个图像检测:

!hub run pyramidbox_lite_mobile_mask --input_path "data/data31681/test.jpeg"

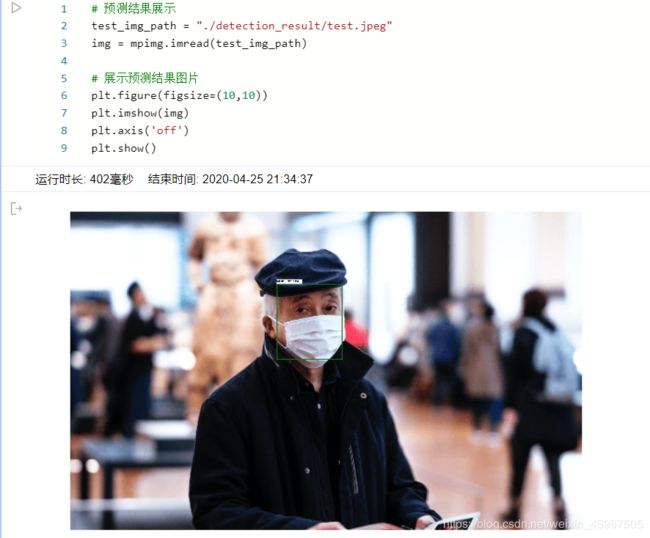

其他cv方面的举例
#人像抠图
import paddlehub as hub
humanseg = hub.Module(name="deeplabv3p_xception65_humanseg")
import matplotlib.pyplot as plt
import matplotlib.image as mpimg
path = ["data/data31681/test.jpeg"]
results = humanseg.segmentation(data={"image":path})
#预测结果展示
test_img_path = result["processed"]
img = mpimg.imread(test_img_path)
#展示预测结果图片
plt.figure(figsize=(10,10))
plt.imshow(img)
plt.axis('off')
plt.show()

#风格迁移
import paddlehub as hub
import cv2
stylepro_artistic = hub.Module(name="stylepro_artistic")
results = stylepro_artistic.style_transfer(images=[{
'content': cv2.imread("data/data31681/main.png"),
'styles': [cv2.imread("data/data31681/style1.png")]}],
alpha = 1.0,
visualization = True)
# 原图展示
test_img_path = "data/data31681/main.png"
img = mpimg.imread(test_img_path)
plt.figure(figsize=(10,10))
plt.imshow(img)
plt.axis('off')
plt.show()
#原图展示
test_img_path = "data/data31681/style1.png"
img = mpimg.imread(test_img_path)
plt.figure(figsize=(10,10))
plt.imshow(img)
plt.axis('off')
plt.show()
#预测结果展示
test_img_path = "transfer_result/ndarray_1587809892.1425676.jpg"
img = mpimg.imread(test_img_path)
#展示预测结果图片
plt.figure(figsize=(10,10))
plt.imshow(img)
plt.axis('off')
plt.show()

其他NLP方面的举例

总结:现拿现用,开箱即用,直接出结果,毕设和作业利器
涉及到本次的作业,是个图像分类的任务
下面列举关键步骤:
加载预训练模型
接下来我们要在PaddleHub中选择合适的预训练模型来Finetune,由于是图像分类任务,因此我们使用经典的ResNet-50作为预训练模型。PaddleHub提供了丰富的图像分类预训练模型,包括了最新的神经网络架构搜索类的PNASNet,我们推荐您尝试不同的预训练模型来获得更好的性能。
module = hub.Module(name="resnet_v2_50_imagenet")
然后做了一个很简单的二分类任务:
加载数据 这里要着重说明下,利用PaddleHub提供的预训练模型进行具体任务的Fine-tune。您只需要对自定义数据进行相应的预处理,随后输入预训练模型中,即可得到相应的结果。
那么他的结构如下:
├─data: 数据目录
├─train_list.txt:训练集数据列表
├─test_list.txt:测试集数据列表
├─validate_list.txt:验证集数据列表
├─label_list.txt:标签列表
└─……
具体需要在微调时需要遵循的树形结构参见链接: 预训练结构demo.
本例中,二分类问题,结构如下:

from paddlehub.dataset.base_cv_dataset import BaseCVDataset
class DemoDataset(BaseCVDataset):
def __init__(self):
# 数据集存放位置
self.dataset_dir = "data"
super(DemoDataset, self).__init__(
base_path=self.dataset_dir,
train_list_file="train_list.txt",
validate_list_file="validate_list.txt",
test_list_file="test_list.txt",
#predict_file="predict_list.txt",
label_list_file="label_list.txt",
)
dataset = DemoDataset()
生成数据读取器
接着生成一个图像分类的reader,reader负责将dataset的数据进行预处理,接着以特定格式组织并输入给模型进行训练。
当我们生成一个图像分类的reader时,需要指定输入图片的大小
data_reader = hub.reader.ImageClassificationReader(
image_width=module.get_expected_image_width(),
image_height=module.get_expected_image_height(),
images_mean=module.get_pretrained_images_mean(),
images_std=module.get_pretrained_images_std(),
dataset=dataset)
输出:
[2020-04-19 22:38:30,752] [ INFO] - Dataset label map = {'许佳琪': 0, '虞书欣': 1}
配置参数
配置策略
在进行Finetune前,我们可以设置一些运行时的配置,例如如下代码中的配置,表示:
use_cuda:设置为False表示使用CPU进行训练。如果您本机支持GPU,且安装的是GPU版本的PaddlePaddle,我们建议您将这个选项设置为True;
epoch:迭代轮数;
batch_size:每次训练的时候,给模型输入的每批数据大小为32,模型训练时能够并行处理批数据,因此batch_size越大,训练的效率越高,但是同时带来了内存的负荷,过大的batch_size可能导致内存不足而无法训练,因此选择一个合适的batch_size是很重要的一步;
log_interval:每隔10 step打印一次训练日志;
eval_interval:每隔50 step在验证集上进行一次性能评估;
checkpoint_dir:将训练的参数和数据保存到cv_finetune_turtorial_demo目录中;
strategy:使用DefaultFinetuneStrategy策略进行finetune;
同时PaddleHub提供了许多优化策略,如AdamWeightDecayStrategy、ULMFiTStrategy、DefaultFinetuneStrategy等,详细信息:Strategy类封装了一系列适用于迁移学习的Fine-tuning策略。Strategy包含了对预训练参数使用什么学习率变化策略,使用哪种类型的优化器,使用什么类型的正则化等。
config = hub.RunConfig(
use_cuda=True, #是否使用GPU训练,默认为False;
num_epoch=3, #Fine-tune的轮数;
checkpoint_dir="cv_finetune_turtorial_demo",#模型checkpoint保存路径, 若用户没有指定,程序会自动生成;
batch_size=3, #训练的批大小,如果使用GPU,请根据实际情况调整batch_size;
eval_interval=10, #模型评估的间隔,默认每100个step评估一次验证集;
strategy=hub.finetune.strategy.DefaultFinetuneStrategy()) #Fine-tune优化策略;
组建Finetune Task
其实就是由于该数据设置是一个二分类的任务,而我们下载的分类module是在ImageNet数据集上训练的千分类模型,所以我们需要对模型进行简单的微调,把模型改造为一个二分类模型:
获取module的上下文环境,包括输入和输出的变量,以及Paddle Program;
从输出变量中找到特征图提取层feature_map;
在feature_map后面接入一个全连接层,生成Task;
input_dict, output_dict, program = module.context(trainable=True)
img = input_dict["image"]
feature_map = output_dict["feature_map"]
feed_list = [img.name]
task = hub.ImageClassifierTask(
data_reader=data_reader,
feed_list=feed_list,
feature=feature_map,
num_classes=dataset.num_labels,
config=config)
开始Finetune
我们选择finetune_and_eval接口来进行模型训练,这个接口在finetune的过程中,会周期性的进行模型效果的评估,以便我们了解整个训练过程的性能变化
run_states = task.finetune_and_eval()
预测
当Finetune完成后,我们使用模型来进行预测,先通过以下命令来获取测试的图片
import numpy as np
import matplotlib.pyplot as plt
import matplotlib.image as mpimg
data = ["data/xu/16.jpg","data/yu/16.jpg"]
label_map = dataset.label_dict()
index = 0
run_states = task.predict(data=data) #得到预测结果
results = [run_state.run_results for run_state in run_states]
for batch_result in results:
print(batch_result)
batch_result = np.argmax(batch_result, axis=2)[0]
print(batch_result)
for result in batch_result:
index += 1
result = label_map[result]
print("input %i is %s, and the predict result is %s" %
(index, data[index - 1], result))
img = mpimg.imread(data[0])
img1 = mpimg.imread(data[1])
plt.figure(figsize=(10,10))
plt.subplot(1,2,1)
plt.imshow(img)
plt.axis('off')
plt.subplot(1,2,2)
plt.imshow(img1)
plt.axis('off')
plt.show()
print(" input1 许佳琪 input2 虞书欣")
结果;

当然作为另一个作业,主要还是其实是如何按照
├─data: 数据目录
├─train_list.txt:训练集数据列表
├─test_list.txt:测试集数据列表
├─validate_list.txt:验证集数据列表
├─label_list.txt:标签列表
└─……
这个结构来制作自己的数据集,然后大的话又涉及如何上传等等
在最终的预测结果显示和上述例子不同,其余一模一样
import numpy as np
import matplotlib.pyplot as plt
import matplotlib.image as mpimg
with open("dataset/test_list.txt","r") as f:
filepath = f.readlines()
data = [filepath[0].split(" ")[0],filepath[1].split(" ")[0],filepath[2].split(" ")[0],filepath[3].split(" ")[0],filepath[4].split(" ")[0]]
label_map = dataset.label_dict()
index = 0
run_states = task.predict(data=data)
results = [run_state.run_results for run_state in run_states]
for batch_result in results:
print(batch_result)
batch_result = np.argmax(batch_result, axis=2)[0]
print(batch_result)
for result in batch_result:
index += 1
result = label_map[result]
print("input %i is %s, and the predict result is %s" %
(index, data[index - 1], result))
结果如下:

总结
主要还是了解hub在预训练到微调这期间的步骤和一些集成 的API ,然后NLP方面的还需去社区去逛一逛,有时间去用一下
最后一天及大作业
这次的课我是补的录播。通过本次课程,主要了解的一下方面,首先就是Esaydl,在视屏的讲解中这个开发平台追求的是傻瓜式开发,可能需要做的就是标注少量数据集,根据官方文档,智能标注的模式下只要标注30%左右就可以保证精度,但目前大部分还是在cv领域,这个平台也是刚开放,相信后面会有更多的补充和优化。老师在视屏中搭建了一个3分类目标检测的全部过程包括云端的部署和调用,我去官方的文档也去看了看,直接的云部署的demo示例是有的,但感觉还是处于学生试验显示利器的阶段。直到看到下面的工业部署,感觉以后结合自己的课题在金属瑕疵检测方面可能要采取这个方案,又刚好是cv检测(现在发现aistudio中的项目对cv模型的搭建和复现很多)所以先在这里码着,回所可能要用到(当然是收费的 )
在线调用API、离线SDK方式参考.


这次的大作业
这次的大作业我并没有尝试去去复现,主要还是在视屏中参照老师的demo着重去理解了下爬取网站评论的过程(这次的爬虫我觉得学会了里面的数据清理的过程,文本类的爬虫和清洗就么得问题了)
首先按照老师所说,找到类似这种不能一次性爬取很多需要点击查看的过程,通过在Network里实时观察发现是根据将last id不断更新再当做请求的过程访问新的评论,即get_commend_action的操作,得到的头文件如下:
Request URL: https://sns-comment.iqiyi.com/v3/comment/get_comments.action?agent_type=118&agent_version=9.11.5&authcookie=null&business_type=17&content_id=15068699100&hot_size=0&last_id=240780654021&page=&page_size=20&types=time&callback=jsonp_1587976708193_50432
再依据群里讨论所示,把请求url最后的callback参数去掉,就得到标准的json数据了

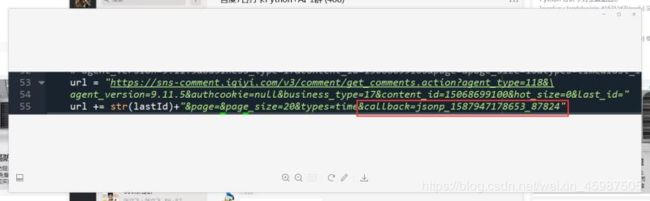

得到json文件对其进行解析,这里的url+=str(lastId)就是之前所说的循环将last id不断更新再当做请求的过程,分开data下的conments字段,如果key是content字段的就是评论保留下来。

def saveMovieInfoToFile(lastId,arr):
'''
解析json数据,获取评论
参数 lastId:最后一条评论ID arr:存放文本的list
:return: 新的lastId
'''
url ="https://sns-comment.iqiyi.com/v3/comment/get_comments.action?agent_type=118&agent_version=9.11.5&business_type=17&content_id=15068699100&page=&page_size=10&types=time&last_id="
url += str(lastId)
responesTxt = getMovieinfo(url)
responesJson = json.loads(responesTxt)
comments = responesJson['data']['comments']
for val in comments:
if 'content' in val.keys():
print(val['content'])
arr.append(val['content'])
lastId = str(val['id'])
return lastId
然后很多特殊字符,比如什么表情或者颜文字什么的需要去除,这里借鉴了一位大佬写的(参考:https://blog.csdn.net/yinyiyu/article/details/105778673)
(其实可以在网上查)用的是正则的规则,re模块

s = re.sub(r"| |\t|\r","",content)
s = re.sub(r"\n","",s)
s = re.sub(r"\*","\\*",s)
s = re.sub("[^\u4e00-\u9fa5^a-z^A-Z^0-9]","",s)
s = re.sub("[\001\002\003\004\005\006\007\x08\x09\x0a\x0b\x0c\x0d\x0e\x0f\x10\x11\x12\x13\x14\x15\x16\x17\x18\x19\x1a]+","", s)
s = re.sub("[a-zA-Z]","",s)
s = re.sub("^d+(\.\d+)?$","",s)
然后就是对评论进行分词,用的是jieba分词,因为后面要做一个词云,还要做次频统计,和我想研究的不太相关,所以这里就大致的了解下即可:

这里的add_text是自定义的,也可以没有,网上也可以下载,目的是将一些网络新词加到分词的规则里面,刚开始觉得不重要,后来发现在群里有人反映了这么一个问题,所以还是有作用的


再接着这一步的数据清洗还是可以学习的,就是在词频统计的时候,一些,的,了,哈。。。这样类似的词在评论中很多,但我们的关注点又不是这里,所以设置停用词:根据自己设置的一个txt文件设置为列表。去除停用词的方法很简单if word not in stopwords,就.get()

然后进行词频的topk统计和画图:

这里涉及到中文字体在matlib中的显示,里面有些坑,可以参加这个博客:
https://blog.csdn.net/qinqinbaobei23344/article/details/105783127
字体下载相关问题,报403错误,可以自己手动下载相关字体,然后进行上传
#!wget https://mydueros.cdn.bcebos.com/font/simhei.ttf # 下载中文字体
##创建字体目录fonts
!mkdir .fonts
##复制字体文件到该路径
!cp simhei.ttf .fonts/
这里包括路径的设置和查看隐藏文件 !ls -a等注意事项可以看这个;
https://blog.csdn.net/yinyiyu/article/details/105778673
#设置显示中文
matplotlib.rcParams['font.sans-serif']=['simhei']
matplotlib.rcParams['axes.unicode_minus']=False
然后就是一个词云的显示和保存图片,这里不是太感兴趣,就略过不做分析:

可以大概看看结果的样子:

最后这个老师又一次调用了hub里的敏感词分析模型porn_detection_lstm对评论做了分析:

porn_detection_lstm = hub.Module(name="porn_detection_lstm")
f = open('aqy.txt','r',encoding='UTF-8')
for line in f:
if len(line.strip()) == 1: #判断评论长度是否为1
continue
else:
test_text.append(line)
f.close()
显示的结果类似下图:

最后将前面的类放在main函数里顺序调用;

总结
至此,这次课程所有我想来接的学习的就结束了,收获还是颇丰,后来的目标还是多在paddle的官网上多看看教程和示例项目,收获会很多。
你可能感兴趣的:(平台实操)