Graph Convolution Network图卷积网络(二)数据加载与网络结构定义
背景 : 弄懂Graph Convolution Network的pytorch代码如何加载数据并且如何定义网络结构的。
代码地址:https://github.com/tkipf/pygcn
论文地址:https://arxiv.org/abs/1609.02907 Semi-Supervised Classification with Graph Convolutional Networks,ICLR 2017
目录
一、模型结构定义
1.1 调用位置
1.2 输入参数
1.3 GCN定义
1.4 网络结构(核心)
二、图卷积层Graph convolution
2.1 层初始化定义
2.2 初始化权重
2.3 前馈运算
三、加载数据
3.1 数据格式
content file
cites file
3.2 content file的读取
3.3 cites的读取
3.4 运算symmetric adjacency matrix
3.5 数据集分割
一、模型结构定义
1.1 调用位置
train.py之中,调用模型
# Model and optimizer
model = GCN(nfeat=features.shape[1],
nhid=args.hidden,
nclass=labels.max().item() + 1,
dropout=args.dropout)
optimizer = optim.Adam(model.parameters(),
lr=args.lr, weight_decay=args.weight_decay)1.2 输入参数
代码models.py之中,
- 第一个参数为底层节点的参数,feature的个数
- nhid,隐层节点个数
- nclass,最终的分类数
- dropout
class GCN(nn.Module):
def __init__(self, nfeat, nhid, nclass, dropout):
super(GCN, self).__init__()
self.gc1 = GraphConvolution(nfeat, nhid)
self.gc2 = GraphConvolution(nhid, nclass)
self.dropout = dropout1.3 GCN定义
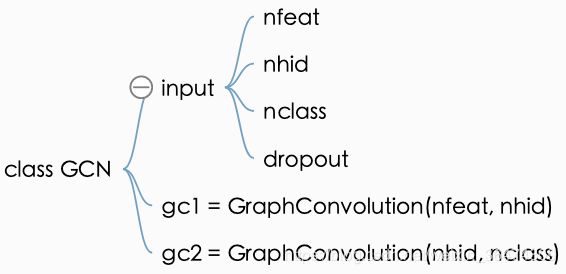
- gc1输入尺寸nfeat,输出尺寸nhid
- gc2输入尺寸nhid,输出尺寸ncalss
1.4 网络结构(核心)
此部分,需要结合论文与代码一同理解其结构,此部分也是论文和代码关于网络结构的核心。需要详细查阅pytorch的函数才能弄懂,后续再来查。
结合论文,此公式为:


- 隐层的feature maps的数量为H,输入层数量为C,输出层为F
- 其中A为下面3.4中提到的symmetric adjacency matrix,

- 权重
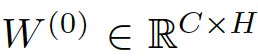 为输入层到隐层的权值矩阵
为输入层到隐层的权值矩阵 - 同理,权重
 为隐层到输出层的权值矩阵
为隐层到输出层的权值矩阵 - 这个公式跟BP有点像,只不过比BP多了一个稀疏的adj matrix A
代码之中就是这样:
def forward(self, x, adj):
x = F.relu(self.gc1(x, adj))
x = F.dropout(x, self.dropout, training=self.training)
x = self.gc2(x, adj)
return F.log_softmax(x, dim=1)- gc1后接一个relu激活
- x进行dropout
- 然后x与adj通过gc2
- 通过softmax回归得到最终的输出
二、图卷积层Graph convolution
2.1 层初始化定义
输入feature,输出feature,权重,偏移。
依然存在一个问题,不太熟悉pytorch的架构及代码,后续一个一个查阅。

def __init__(self, in_features, out_features, bias=True):
super(GraphConvolution, self).__init__()
self.in_features = in_features
self.out_features = out_features
self.weight = Parameter(torch.FloatTensor(in_features, out_features))
if bias:
self.bias = Parameter(torch.FloatTensor(out_features))
else:
self.register_parameter('bias', None)
self.reset_parameters()2.2 初始化权重
初始化为均匀分布。

def reset_parameters(self):
stdv = 1. / math.sqrt(self.weight.size(1))
self.weight.data.uniform_(-stdv, stdv)
if self.bias is not None:
self.bias.data.uniform_(-stdv, stdv)2.3 前馈运算
论文之中,就是三个矩阵相乘
input X与权重W相乘,然后adj矩阵与 他们的积稀疏乘。

- 直接输入与权重之间进行torch.mm操作,得到support,即XW
- support与adj进行torch.spmm操作,得到output,即AXW
- 选择是否加bias
def forward(self, input, adj):
support = torch.mm(input, self.weight)
output = torch.spmm(adj, support)
if self.bias is not None:
return output + self.bias
else:
return output三、加载数据

3.1 数据格式
这是我们第一次面对图结构的数据,因此需要弄懂图结构的数据如何读出,如何进入网络之中的。关于数据集的数据的格式,我们前面有看过数据集的格式。
https://github.com/tkipf/pygcn/tree/master/data/cora
Graph Convolution Network图卷积网络PyTorch代码(一)概览与训练运行
content file
每行包含下面几项:
+ 第一列为paper ID,后面几列为每个单词出现与否,用0与1表示,最后一列为类别标签。


cites file
表示论文之间的引用关系(由此看来这个图是有向图)
前面为被引论文的ID,后面为引用前面的论文的ID
887 6215
887 64519
887 87363
887 976334
906 1103979
906 1105344
906 1114352
906 11363973.2 content file的读取
content file的每一行的格式为 :
feature为第二列到倒数第二列,labels为最后一列。

idx_features_labels = np.genfromtxt("{}{}.content".format(path, dataset),
dtype=np.dtype(str))
features = sp.csr_matrix(idx_features_labels[:, 1:-1], dtype=np.float32)
labels = encode_onehot(idx_features_labels[:, -1])3.3 cites的读取
cites file的每一行格式为:
根据前面的contents与这里的cites创建图,算出edges矩阵与adj 矩阵。
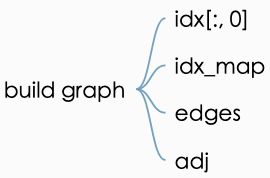
# build graph
idx = np.array(idx_features_labels[:, 0], dtype=np.int32)
idx_map = {j: i for i, j in enumerate(idx)}
edges_unordered = np.genfromtxt("{}{}.cites".format(path, dataset),
dtype=np.int32)
edges = np.array(list(map(idx_map.get, edges_unordered.flatten())),
dtype=np.int32).reshape(edges_unordered.shape)
adj = sp.coo_matrix((np.ones(edges.shape[0]), (edges[:, 0], edges[:, 1])),
shape=(labels.shape[0], labels.shape[0]),
dtype=np.float32)矩阵的定义如下:

3.4 运算symmetric adjacency matrix
运算为 symmetric adjacency matrix的格式,具体需要参阅原论文与代码搞懂此矩阵到底如何得来的。
论文之中对symmetric adjacency matrix的描述为:
# build symmetric adjacency matrix
adj = adj + adj.T.multiply(adj.T > adj) - adj.multiply(adj.T > adj)
features = normalize(features)
adj = normalize(adj + sp.eye(adj.shape[0]))3.5 数据集分割
分割为train,val,test三个集
最终数据加载为torch的格式并且分成三个数据集
idx_train = range(140)
idx_val = range(200, 500)
idx_test = range(500, 1500)
features = torch.FloatTensor(np.array(features.todense()))
labels = torch.LongTensor(np.where(labels)[1])
adj = sparse_mx_to_torch_sparse_tensor(adj)
idx_train = torch.LongTensor(idx_train)
idx_val = torch.LongTensor(idx_val)
idx_test = torch.LongTensor(idx_test)