Redis cluster集群模式详解
Redis Cluster 介绍
Redis Cluster是Redis的分布式解决方案,在Redis 3.0版本正式推出的,集群通过分片(sharding)来进行数据共享,并提供复制和故障转移功能,能有效解决了Redis分布式方面的需求。当遇到单机内存、并发、流量等瓶颈时,都可以采用Cluster架构达到负载均衡的目的。
在redis cluster架构下,每个redis要放开两个端口号,比如一个是6379,另外一个就是加10000的端口号,比如16379
16379端口号是用来进行节点间通信的,也就是cluster bus的东西,集群总线。cluster bus的通信,用来进行故障检测,配置更新,故障转移授权 gossip 协议
cluster bus用了另外一种二进制的协议,主要用于节点间进行高效的数据交换,占用更少的网络带宽和处理时间
集群组成
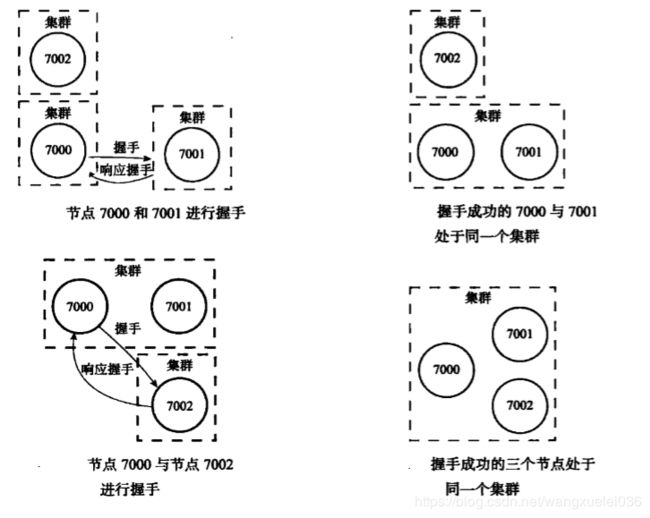
一个Redis集群通常由多个节点(node)组成,刚开始的时候,每隔节点都是相互独立的,他们都处于一个只包含自己的集群当中,要组件一个真正可工作的集群,我们必须将各个独立的节点连接起来,构成一个包含多个节点的集群。
命令如下:CLUSTER MEET
向一个节点node发送CLUSTER MEET命令,让node节点与指定的
注:
- clusterNode:clusterNode结构保存了一个节点的当前状态(注:包含节点的创建时间、节点名字、IP、port等信息),每个节点都使用一个clusterNode来记录自己的状态,并为集群中的所有节点(包括主节点和从节点)都创建一个相应的clusterNode结构,来记录其他节点信息
- clusterState:每个节点node都保存着一个clusterState结构,这个结构记录了在当前节点的视角下,集群目前所处的状态(clusteState中存储了所有slusterNode信息)
思考:集群有了,节点也有了,那数据怎么分布呢?
槽指派(数据分布)
Redis集群通过分片的方式来保存数据库中的键值对,集群的整个数据库被分为16384个槽(slot),数据库中的每个键都属于这16384个槽的其中一个,集群中的每个节点可以处理0个或最多16384个槽。每一个节点负责维护一部分槽以及槽所映射的键值数据。
下图展示某个包含5个节点的示意图:
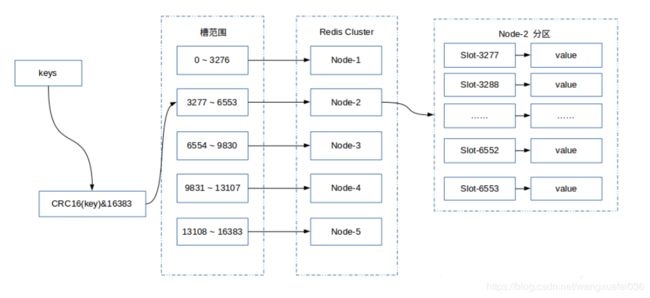
注:槽指派可以不均匀分布,计算公式CRC16(KEY)&16383 计算key所属的槽位
指派槽分布命令:CLUSTER ADDSLOTS 10001 10002 10003 ... 16383
详解可见官网命令介绍:https://redis.io/commands/cluster-addslots
当数据库中的16384个槽都有节点在处理时,集群处于上线状态(ok);相反地,如果数据库中有任何一个槽没有得到处理,那么集群处于下线状态(fail)
注:集群中每个节点都会传播槽归属信息(传播当前节点处理哪些槽),让集群中每个节点都持有槽指派的元信息,知道槽位分派在哪个节点
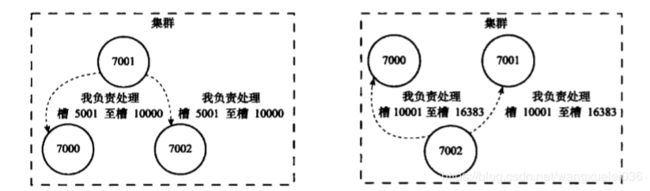
注:为了能快速知道某个槽在哪个节点node上,redis维护了一个槽指派信息在clusterstate.slots数组中
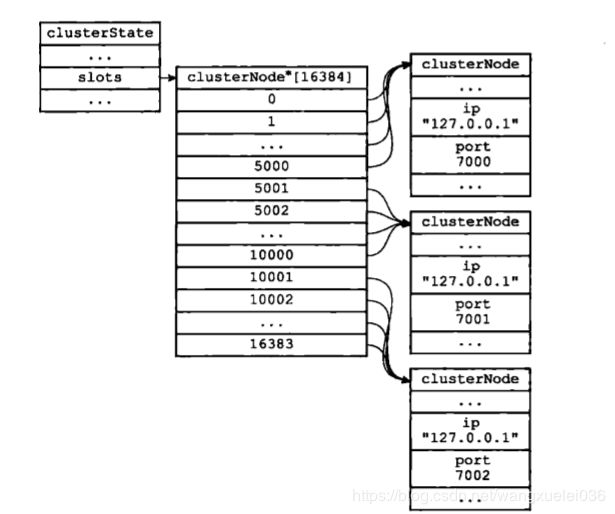
集群中命令执行流程
(1)计算键属于哪个slot
(2)如果在当前节点,便执行该命令,如果不是,则返回MOVED错误
(3)前提是返回MOVED错误,客户端收到MOVED错误并根据提供的信息转向正确的节点进行访问(该节点会再次执行以上流程)
如下图:
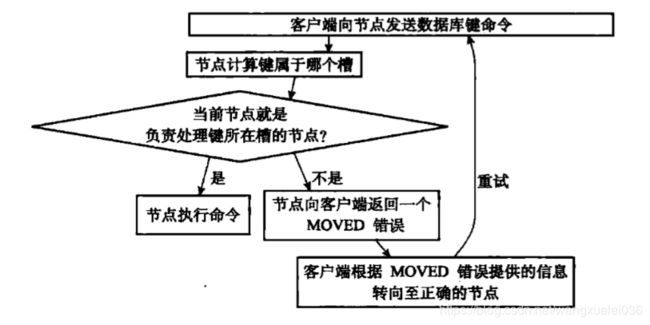
注:这也是为什么有时候客户端需要访问两次redis服务器
详解参考:Redis cluster 集群模式 请求重定向 客户端为什么有时会访问两次?
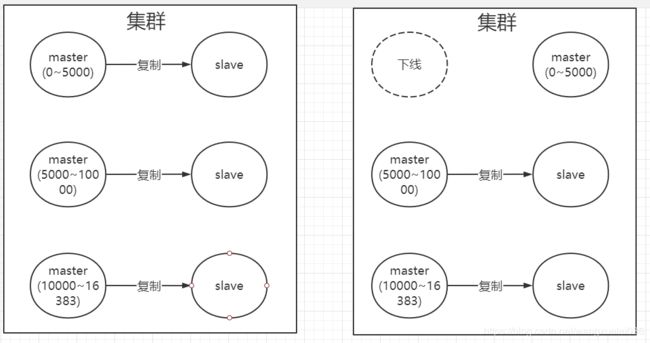
复制和故障转移
Redis集群中的节点分为主节点(master)和从节点(slave),其中主节点用于处理槽,从节点则用于复制某个主节点,并在主节点下线时,代替下线主节点继续处理命令。
如下图,若主节点挂掉,会在从节点中选出一个节点作为新的主节点并客户端发来的命令(可以有多个从机)
Redis cluster集群模式功能限制
- key批量操作支持有限。如:MSET``MGET,目前只支持具有相同slot值的key执行批量操作。
- key事务操作支持有限。支持多key在同一节点上的事务操作,不支持分布在多个节点的事务功能。
- key作为数据分区的最小粒度,因此不能将一个大的键值对象映射到不同的节点。如:hash、list。
- 不支持多数据库空间。单机下Redis支持16个数据库,集群模式下只能使用一个数据库空间,即db 0。
- 复制结构只支持一层,不支持嵌套树状复制结构。