GO语言实现爬虫(实现文字和图片爬取)
代码:
package main
import (
"./goquery"
"errors"
"fmt"
"io"
"io/ioutil"
"log"
"net/http"
"net/url"
"os"
"path/filepath"
"strings"
)
func GetNews(s string) {
file := "news.txt"
fout, err := os.Create(file)
defer fout.Close()
if err != nil {
fmt.Println(file, err)
return
}
// str := os.Args[1]
str := s
//doc, err := goquery.NewDocument("http://news.qq.com")
doc, err := goquery.NewDocument(str)
if err != nil {
log.Fatal(err)
}
doc.Find(".content").Each(func(i int, s *goquery.Selection) {
html, _ := s.Html()
fout.WriteString(s.Text())
fout.WriteString(html)
fout.WriteString("\n")
})
}
func downloadPic(urls []string, dir string) error {//xiazai tupian
for _, link := range urls {
resp, err := http.Get(link)
if err != nil {
log.Fatal(err)
}
defer resp.Body.Close()
if resp.StatusCode != http.StatusOK {
log.Fatal(resp.Status)
}
FileName := filepath.Base(link)//创建一个文件名
FullName := filepath.Join(dir, FileName)//创建一个存放文件的文件名
f, err := os.Create(FullName)
if err != nil {
log.Panic("文件创建失败")
}
io.Copy(f, resp.Body)
}
return nil
}
func fetch(url string) ([]string, error) {//分析出图片的下载路径
var urls []string
resp, err := http.Get(url)
if err != nil {
log.Fatal(err)
}
defer resp.Body.Close()
if resp.StatusCode != http.StatusOK {
return nil, errors.New(resp.Status)
}
doc, err := goquery.NewDocumentFromResponse(resp)//传入 HTTP 响应,内部拿到res.Body(实现了 io.Reader) 后的处理方式类似 NewDocumentFromReader.
if err != nil {
log.Fatal(err)
}
doc.Find("img").Each(func(i int, s *goquery.Selection) {//迭代查询
link, ok := s.Attr("src")
if ok {
urls = append(urls, link)
} else {
fmt.Println("no find addr")
}
})
return urls, nil
}
func CleanUrls(RootPath string, PicPath []string) []string {
var AbsolutePath []string
UrlInfo, err := url.Parse(RootPath)
if err != nil {
log.Fatal(err)
}
Scheme := UrlInfo.Scheme //获取链接协议
Host := UrlInfo.Host//获取链接主机名
for _, SoucePath := range PicPath {//处理得到绝对路径
if strings.HasPrefix(SoucePath, "http") {
} else if strings.HasPrefix(SoucePath, "//") {
SoucePath = Scheme + ":" + SoucePath
} else if strings.HasPrefix(SoucePath, "/") {
SoucePath = Scheme + "://" + Host + SoucePath
} else {
SoucePath = filepath.Dir(RootPath) + SoucePath
}
AbsolutePath = append(AbsolutePath, SoucePath)
}
return AbsolutePath//返回绝对路径
}
func GetPicture(str string) {
//RootPath :="http://www.youzu.com"
// RootPath := os.Args[1]
RootPath := str
PicPath, err := fetch(RootPath)
if err != nil {
log.Fatal(err)
}
AbsolutePath := CleanUrls(RootPath, PicPath)
picture := "/home/sgc/go/src/pachong/pachong/"//制定下载地址
tmpdir, err := ioutil.TempDir(picture, "sanyue")//制定文件夹前缀,后面不知道为什么乱加一堆数
fmt.Println(tmpdir)
err = downloadPic(AbsolutePath, tmpdir)
if err != nil {
log.Panic(err)
}
}
func main() {
if len(os.Args) != 2 {//根据传入的指令,选择要做的事情
fmt.Println("Usage :./pachong |-p|-picture|-n|-news|")
os.Exit(1)
}
options := os.Args[1]
if options == "-n" || options == "-news" {
fmt.Println("please input addr:like http://example.com")
var str string
fmt.Scan(&str)
fmt.Println("pa qu news")
GetNews(str)
} else if options == "-p" || options == "-picture" {
fmt.Println("please input addr:like http://example.com")
var str string
fmt.Scan(&str)
fmt.Println("pa qu picture")
GetPicture(str)
}else{
fmt.Println("are you kidding me")
fmt.Println("Usage :./pachong |-p|-picture|-n|-news|")
}
//GetNews()
//GetPicture()
}参考文献:
https://www.itlipeng.cn/2017/04/25/goquery-%E6%96%87%E6%A1%A3/
http://www.cnblogs.com/yinzhengjie/p/7210850.html
http://coolaf.com/article/25.html
运行方式
go build pachong.go
./pachong -p 或-picture 进入爬图片选项
./pachong -n或-news进入爬新闻选项
示例
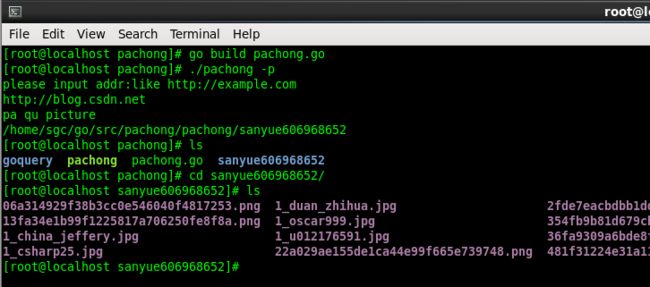
然后eog 图片名 就可以查看下载的图片

爬取新闻
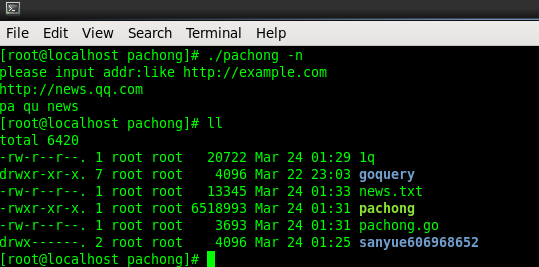
vim news.txt 打开
