逻辑回归实验
逻辑回归实验
文章目录
- 逻辑回归实验
- 实验说明
- 实验步骤
- 参数优化
实验说明
虽然模型名字叫做逻辑回归,实际上我们经常用它来做分类任务。这次的数据集我们使用的是 sklearn 包中自带的红酒数据集。
- 实验环境:Pycharm
- Python版本:3.6
- 需要的第三方库:sklearn
实验步骤
一个简单的机器学习实验基本就是那六个步骤,这里不再提及了。
关于训练集和测试集的划分我们使用的是留出法,最后的结果我们使用准确率来进行评估。
代码如下:
# 逻辑回归,红酒数据集
from sklearn.datasets import load_wine
from sklearn.linear_model import LogisticRegression
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
# 加载数据集
wind_data = load_wine()
x = wind_data.data
y = wind_data.target
# 拆分数据集
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.2, random_state=10)
# 创建模型
lr = LogisticRegression(
solver='saga',
multi_class='ovr',
penalty='l2',
max_iter=10000,
random_state=10
)
# 训练模型
lr.fit(x_train, y_train)
# 模型预测
lr_predict = lr.predict(x_test)
# 模型评价
a_score = accuracy_score(y_test, lr_predict)
print("accuracy_score: ", a_score)
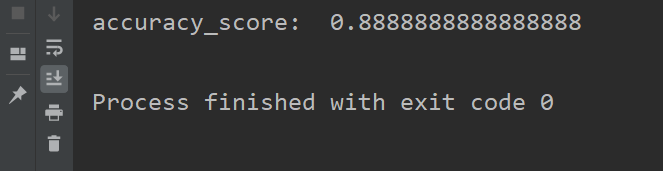
此时的模型预测准确率为0.89
参数优化
虽然模型的准确率已经很不错了,但是我们仍然可以对其进行优化。
正则化选择参数 penalty 我们考虑使用 L1 正则化,优化算法选择参数 solver 使用 liblinear,分类方式选择参数 multi_class 使用 ovr,类型权重参数 class_weight 使用 balanced,随机种子为200。
如果想要知道具体怎么进行优化,可以参考这一篇博客 sklearn逻辑回归(Logistic Regression,LR)类库使用小结
# 逻辑回归,红酒数据集
from sklearn.datasets import load_wine
from sklearn.linear_model import LogisticRegression
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
# 加载数据集
wind_data = load_wine()
x = wind_data.data
y = wind_data.target
# 拆分数据集
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.2, random_state=200)
# 创建模型
lr = LogisticRegression(
solver='liblinear',
multi_class='ovr',
penalty='l1',
max_iter=10000,
class_weight='balanced',
random_state=200
)
# 训练模型
lr.fit(x_train, y_train)
# 模型预测
lr_predict = lr.predict(x_test)
# 模型评价
a_score = accuracy_score(y_test, lr_predict)
print("accuracy_score: ", a_score)
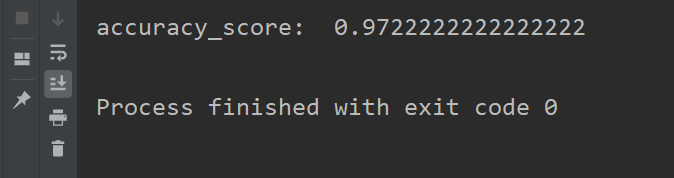
可以看到,模型预测的准确率达到了 0.97,非常棒了。